Lecture
A new feature has been added to the Google Webmaster Tools in the Site Configuration Settings section. This setting, called Parameter Handling, allows a site owner to define up to 15 parameters that Googlebot will ignore when indexing a site .
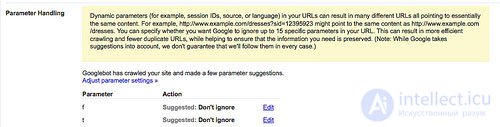
Google makes a list of the parameters that it found in the URLs of your site, which of them, according to the search engine, is unnecessary (with the suggestion “Ignore” or “Do not ignore.” You can confirm or cancel these offers, or add parameters that are not in the list.
The main advantage of the new feature is that it improves the canonization of the site in the Google index , protecting against the problem of duplicate content. The problem of canonization occurs when the same content is downloaded to several URLs.
Such a situation on your site can lead to a large number of negative consequences (well, for example, you will receive inaccurate analytical information), but from the point of view of search engines, problems with the canonization of the site are:
There are many solutions to the problem of canonization, including several specifically for Google, then why was it necessary to create a new feature for this in Google Webmaster Tools?
After the Yahoo! I added a similar tool to my webmaster product “Site Explorer”, Google was asked to do something similar on my own (at least while I was working at Webmaster Central I often had to read such messages).
Below I will give different ways of canonizing URLs, and briefly describe their main differences.
The new option helps to solve the problem of canonization when additional parameters of addresses in the key-value pair are specified . In other words, this sheet consists of exceptions (do not index the x, y, and z parameters) and not the list of inclusions (only index a and b).
Can you know all the possible parameters of addresses? I think no. But sometimes there is a problem of canonization when the URL address does not contain any parameters at all.
Ideally, your server should not be configured in this way, but if such a configuration was needed (for example, another development team or some external company wanted the tracking code to be added to the address and the corresponding server settings were changed), in such situations it is best for you use the "canonical" meta tag .
The two most common reasons for setting parameters and for which this function would be a very good solution are:
The biggest advantage is the increase in the effectiveness of site indexing by the bot. When Google finds a new URL, before indexing, they can verify the parameters of the addresses with the parameters listed in the list, if necessary, remove the optional parameters and only after that begin indexing (despite this, the entire reference weight is transmitted to the final page).

This significantly reduces the load on the bot, and the bot can index a larger site.
Another advantage is that this feature is very easy to use. Review the list of proposed exceptions and use the mouse click to select unnecessary ones.
In some companies it may be difficult to edit the code of the site pages, in order to insert a meta tag where you canonical , in addition, it takes extra time.
To use this feature, you don’t even need to seek help from IT specialists, this can easily be done by a regular user, the only thing you need is to have access to Google webmaster tools.
The biggest disadvantage is that this option only works with Google search engine . In the past, it was possible to use a similar tool in another search engine - Yahoo! which was available in their webmaster toolkit "Site Explorer".
In principle, this was quite enough. But with the advent of Microsoft Bing, which is likely to replace the Yahoo index and so far Microsoft does not offer anything like that, you can expect 25% + of the search audience to see the wrong version of your site’s address.
Figuratively speaking, you yourself can make the bandwagon. If you accidentally tell Google to ignore some very important parameter, if it does not get into the index, most of your site will be invisible to the search engine.
The more Google adds new options to its set of tools for webmasters, the more professionalism is required from whoever will work with it, otherwise there may be very bad consequences.
In fact, Google has provided such an opportunity, so there is some protection against errors that can lead to disastrous consequences for your site.
This is one of the reasons why we say " If we wanted something that Google would do, there is no guarantee that it will always do it ." But I think the reason for such care in the other, they simply do not want that because of some stupid mistakes sites fall out of their index.
Unlike random indexing blocking using a robots.txt file, in which everything specified by search engines is perceived in an orderly manner, this option (as well as many others) is of a signal nature for search engines.
If there are already other conflicting "signals" (for example, very diverse content), then most likely this action will not be accepted for execution.
But even knowing that Google uses such an error protection system, it’s unlikely anyone will want to tempt fate and randomly turn off URL parameters that may not seem very important at first glance ( always remember that you could cause harm to your site ).
This option will not work if your canonicalization problems are not related to URL parameters or if the parameters are not in the standard format of the key-value pair.
The meta tag "canonical" is another method of canonization that operates at the page level and points to the canonical version of the page.
It can be very useful in terms of the fact that the page’s URL parameters are no longer relevant, seeing this search engine meta tag will surely know that this particular page is canonical.
You just once indicated which page should be canonical and it does not matter what parameters are added to the URL address, the search engines will always define this page as canonical.
As soon as this meta tag appears on the page, all search engines: Google, Yahoo !, and Microsoft (at least they said they support the canonical tag) treat it as canonical.
Unlike the corresponding option from "Google Webmaster Tools", before this tag will be used, search engines must first read the page, so the indexing efficiency is somewhat lost.

If the search bot hit a non-canonical page after reading it, it found this tag, it starts indexing it again . Thus, the indexing process is delayed.
As you have already noticed using this method, it requires making changes to the page code , which is not always possible to do in an organization if there is no IT specialist in the staff.
As with all other tags, when writing this tag to the page code, you can also make an error . For example, I found some sites in which the canonical tag that installed the main page of the site for all pages with a canonical version.
Like the above described function from the webmaster toolkit, canonical tags are perceived by search engines in a “recommendation form”, i.e. as non-binding, and if there are other signs indicating that the page is not canonical, search engines may ignore it.
Perhaps Google trusts him more than others , and in most cases perceives the canonical page on which it has indicated this tag.
Probably everyone agrees that the best way to canonize URLs is to make 301 redirects of all "extra" addresses to the canonical address (naturally, ideally, it is better not to have other page addresses than the canonical one).
When using this method, all visitors as well as search engine robots are redirected to the canonical address, and with it the entire reference weight is also accumulated on the desired page. Only one canonical page gets into the index.
It is understandable and processed by all major search engines. Also, visitors are satisfied (one URL to enter the page, to add to favorites, to send by e-mail, etc.).
In most cases, when using 301 redirects, search engines consolidate the entire reference weight on the canonical address .
This option is ideal when you are moving content (for example, changing the URL structure of your site or moving to another domain) also to tell the search engine which version of the domain to index, from www or without www.
Also, do not forget that if you redirect to the canonical version, then you will receive subsequent links to it, because most visitors simply copy what they have in the address bar of the browser.
When you use URL parameters to sort orders or track purchases, redirects can simply turn them off. Naturally, you can set up an analytical program for these purposes, but it is unlikely to be so easy to do.
Another problem is that they do not always skillfully use the redirect. For example, many webmasters of toli unknowingly either use 302 redirect by mistake (or even worse, redirect through JavaScript or meta update).
Or create endless chains of redirects. In such cases, search engine robots stop clicking on links inside the site and leave it without having indexed (if you use webmaster tools from Google and Microsoft, you can get a list of URLs of your site that were not indexed because of this).
Another dark side of the redirect is that it reduces the effectiveness of indexing a site by a bot, especially if there is a chain of several redirects.
Ideally, a bot should go through all these redirects until it indexes the final page, but if the bot encounters links to the original version of the address, both versions get into the index (or even more if the page has changed its address several times).
This option lets you tell Google that you are going to change the domain. But first you need to confirm your rights to own the old and new domains, and only then you can already change all the necessary settings for such a transition. For more information on how to do this correctly, see the Help section on Google ..
The biggest advantage of this tool over other methods of canonization is that you can tell Google about moving your site from one domain to another. (a very common problem for those who have websites on blogspot.com) You cannot use the 301 redirect to redirect from the old domain to the new one. Even if you somehow managed to make a redirect between two domains, there is nothing wrong with informing Google about it!
You can use this option only when switching from one domain to another. And just like with other tools from the set of "Google webmaster tools", it works only for the Google search engine.
The option "preferred domain" from "Google webmaster tools" allows you to tell Google if you want your domain to be indexed with the www subdomain or without it. If you do not canonize the site with www / non-www, then you risk running into the problem of duplicate content.
By and large, there is no problem, search engines work correctly with such sites (without canonization). But often search engines find links to both versions of the site (with www, and without) and index them separately from each other. As a result, two separate sites fall into the index, with all the ensuing consequences.
Why use this option? You can always use this option, but also do not forget to make 301 redirect between addresses with www, and without. Both of these canonization tools complement each other and there is no conflict between them. Sometimes Google independently applies this function in those cases where it considers it necessary.
Like all the others, this option only works for Google. And it is not as effective as 301 redirects.
Probably the best way to deal with duplicate content is to block it in robots.txt (or using the meta tag "robots"), then you can be sure that the canonical version of the site is indexed. This is especially true for sites where there are pages in the version "for printing".
Generally speaking, with the advent of the meta tag "canonical" is no longer. Situations in which you do not want to use a redirect (such as the presence of pages "for printing") can be much faster and easier to solve using the "canonical" tag. And the problems of indexing can be easily solved using the corresponding functions in the "Google webmaster tools" (of course this is only relevant for the Google search engine).
The main problem is the loss of reference mass. Links to blocked pages simply go nowhere, instead of being redirected to the canonical version of the page, as is done when other options are used.
For a long time, Google has been trying to solve the problem of canonization on its own, so that only canonical page addresses could be in the sickle, even if the webmasters did not take any measures to canonize.
The principle is that Google sees pages with the same content, automatically determines which of them should be canonical (which it does according to its internal algorithms) and only that canonical in Google’s opinion appears in the SERPA. Perhaps they simply select the shortest URL with the fewest parameters included.
Since last year, Google informs webmasters in the event that non-canonical addresses are found on the site that there may be problems with indexing. It seems that Google has its own list of parameters to be ignored.
In this way, the settings tool tells you how Google sees your site. If you see in the list a lot of parameters that are not indicated by choice, then you should check the content and URLs that use these parameters.
The problem may be even deeper. Perhaps on these pages, Google does not see enough unique content (this can happen, for example, with pages where there are a lot of graphics, a lot of integrated content, digital tables or lists, etc.). You should make these pages more "unique." Having diversified content.

Comments
To leave a comment
seo, smo, monetization, basics of internet marketing
Terms: seo, smo, monetization, basics of internet marketing