For a long time there was a strong belief that search engines - in particular Google - apply sanctions to sites that contain non-original content , or have content that is very common (popular) on the web.
And now I want to declare to you that sanctions for duplicated (that is, not unique) content are a myth .
Regarding the " myth " that there is no sanction for duplicate content, as the author writes - here I fundamentally disagree, today - duplicate content is the scourge of modern SEO and the main cause of many problems. And with reference to this, not only to Google, but also to Yandex in particular.
Let's look at this problem more widely. If a content page has 5 inbound links and this page is located only under one URL , then the entire reference weight is transferred to only one URL.
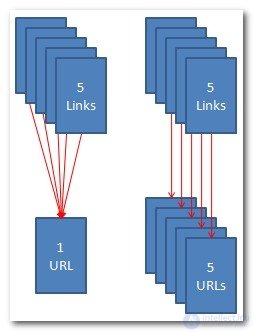
Now imagine that this page with content and links to it hangs on 5 different URLs , now each of these duplicate URLs will receive only 1/5 of the reference weight .
All these pages only together have the same reference weight as only the original one.
The myth of search engine sanctions for non-original content stems from a misunderstanding of the very causes of this phenomenon, the distribution of reference weight.
The ideal situation for promotion is when one URL is for one page with content and one set of keywords. I would advise internet marketers to focus their efforts on optimizing content more than trying to avoid its uniqueness.
The reasons for the appearance of duplicate content
Many different circumstances may result in the appearance of duplicate content, but one thing unites them: There is no duplicate content as long as there is no link to it .
If a problem does not arise for the site of the original content, it means that this content has appeared somewhere but under a different URL and there is at least one inbound link to it.
Links to the URLs of pages with duplicated content may appear if tracking parameters are added to the page address, if the site with the subdomain is not relinked correctly, when filtering and sorting parameters are added to the URL, when the print version of the page creates a new URL, and many more options.
Even worse, each of them can generate other sources of duplicate content, produce hundreds of URL variations for the same page with original content.
The main page (muzzle) can be one example. Sometimes it happens that the default domain is a link to the main page, but clicking on the navigation links that should lead to the main page you get to it but from a different URL, i.e. As a result, you get a page with duplicated content.
And each of these URLs has at least one inbound link.
Think how much more weight there would be to the muzzles of this site if all incoming links led to one real homepage, instead of a dozen of its clones.
Types of dual content
Bad canonization
The lack of canonization is the most common cause of duplicate content. Canonization means eliminating copies of pages, and in SEO, it’s also the concentration of all inbound links at one URL address, for each page with content. Below are 10 examples of URLs to the same page:
- Canonical URL: http://www.example.com/directory1/index.html
- Protocol clone: https://www.example.com/directory1/index.html
- IP clone: http://1.2.3.4/directory1/index.html
- Subdomain clone: http://example.com/directory1/index.html
- Clone file path: http://www.example.com/site/directory1/index.html
- File clone: http://www.example.com/directory1/
- Register clone: http://www.example.com/Directory1/Index.html
- Special characters clone: http://www.example.com/directory%201/index.html
- Tracking clone: http://www.example.com/directory1/index.html?tracking=true
- Ancestral URL clone: http://www.example.com/site/directory.aspx?directory=1&stuff=more
Although in the example and not real addresses, but in my practice I have seen enough sites that have had a huge number of such cloned URL addresses inside. Even there were cases when the reference weight was distributed between the same 1000 URLs. The original (original) page would be much stronger if the entire link weight was directed to only one URL.
The most effective way of canonizing dual content is to concentrate all incoming links to the original page through 301 redirect of its clones.
Cannibalization
Cannibalization is when two or more pages of a site are optimized for the same set of keywords.
Online stores get into this loop very often when, for reasons of improving website usability: filtering goods, sorting goods, the number of units shown on a page, recommending to a friend via e-mail, etc. Duplicate pages are generated, completely or partially similar to the original page.
Technically, they are not 100% duplicates. We cannot do without these pages, they are necessary for the usability of the site, so we make them 301 redirects to the original page.
In this case, site owners have only two choices:
- Make a variety of content with different sets of keywords.
- Use the canonical tag () to collect reference weight without redirecting visitors.
Solution to the problem
Remember that a 301 redirect is a SEO friend's best friend when it comes to dual content or canonization.
If you cannot use a redirect because this page is necessary for people, then your second friend is a canonical tag to accumulate the link mass.
There are other ways to retain content - the meta tag noindex, the robots.txt file, the disallow tag, and 404 errors - but they only close the content from being indexed, but do not prevent it from leaking link weight.
I think it would be useful to read the previous blog post: "Tell Google to ignore URL parameters."

Comments
To leave a comment
seo, smo, monetization, basics of internet marketing
Terms: seo, smo, monetization, basics of internet marketing