Lecture
| Character encodings | ||
|---|---|---|
| The basics | alphabet • text (file • data) • character set • conversion | |
| Historical encodings | Dokomp: | Semaphore (Makarova) • Morse • Bodo • MTK-2 |
| Comp .: | 6-bit • UPP • RADIX-50 • EBCDIC (DKOI-8) • KOI-7 • ISO 646 | |
| modern 8-bit representation | characters | ASCII (control printers) • non-ASCII (pseudographic) |
| 8-bit code. | Cyrillic: KOI-8 • Basic encoding • MacCyrillic | |
| ISO 8859 | 1 (Lat.) • 2 • 3 • 4 • 5 (Kir.) • 6 • 7 • 8 • 9 • 10 • 11 • 12 • 13 • 14 • 15 (€) • 16 | |
| Windows | 1250 • 1251 (Kir.) • 1252 • 1253 • 1254 • 1255 • 1256 • 1257 • 1258 • WGL4 | |
| IBM & DOS | 437 • 850 • 852 • 855 • 866 "alt." • MIK • RI COMPUTER | |
| Multibyte | Traditional | DBCS (GB2312) • HTML |
| Unicode | UTF-32 • UTF-16 • UTF-8 • list of characters (Cyrillic) | |
| Related Topics | user interface • keyboard layout • locale • line feed • font • translit • non-standard fonts | |
| Utilities | iconv • recode | |
UTF-8 (from English Unicode Transformation Format, 8-bit - “ Unicode Transformation Format, 8- bit”) is one of the generally accepted and standardized text encodings that allows you to store Unicode characters using a variable number of bytes (from 1 to 6).
The UTF-8 standard is officially enshrined in RFC 3629 and ISO / IEC 10646 Annex D. The coding has found wide application in UNIX-like operating systems and web space [1] . The very same UTF-8 format was invented on September 2, 1992 by Ken Thompson and Rob Pike and implemented in Plan 9. [2] For BOM, it uses the byte sequence EF 16 , BB 16 , BF 16 (which is itself a three-byte implementation of the FEFF 16 character ).
One of the advantages is compatibility with ASCII - any of their 7-bit characters are displayed as they are, and the rest give the user garbage (noise). Therefore, if the Latin letters and the simplest punctuation marks (including the space) occupy a significant amount of text, UTF-8 gives a gain in volume compared to UTF-16. [3] [4]
For numbers from U + 0000 to U + 007F, the UTF-8 encoding fully corresponds to the 7-bit US-ASCII c 0 in the high bit and occupies one byte.
The coding algorithm in UTF-8 is standardized in RFC 3629 and consists of 3 points:
1. Determine the number of octets (bytes) required for the encoded character number in accordance with the table:
| Character range | Number of bytes |
|---|---|
00000000-0000007F | one |
00000080-000007FF | 2 |
00000800-0000FFFF | 3 |
00010000-001FFFFF | four |
00200000-03FFFFFF | five |
04000000-7FFFFFFF | 6 |
2. Prepare the high-order bits of the first octet (0xxxxxx for one octet, 110xxxxx - two, 1110xxxxx - three, etc.). For the remaining octets, the two most significant bits are 10 (10xxxxxx).
| Number of bytes | Significant bits | First byte | Template completely |
|---|---|---|---|
| one | 7 | 0xxxxxxx | 0xxxxxxx |
| 2 | eleven | 110xxxxx | 110xxxxx 10xxxxxx |
| 3 | sixteen | 1110xxxx | 1110xxxx 10xxxxxx 10xxxxxx |
| four | 21 | 11110xxx | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| five | 26 | 111110xx | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 6 | 31 | 1111110x | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
3. Fill the remaining bits (in clause 2 are marked with x) in octets by the number of the Unicode character expressed in binary. Start with the low-order bits of the character number, putting them in the low-order bits of the last octet of the code. And so on, until all the bits of the character number are transferred to the free bits of the octets.
Example
BOM code for UTF-8 = EF BB BF (16) = 1110 1111 1011 1011 1011 1111 (2)
| 1 byte | 2 bytes | 3 bytes | |
|---|---|---|---|
| Template | 1110 xxxx | 10xx xxxx | 10xx xxxx |
| Bin | 1110 1111 | 1011 1011 | 1011 1111 |
| HEX | EF | BB | BF |
The table below presents the values in hexadecimal notation. In practice, for each value, the only correct representation is selected according to the algorithm standardized in RFC 3629 (with a minimum length of bytes, large ones are not allowed; and presented for clarity and tests by encoders).
| Character code | Symbol name | 1 byte | 2 bytes | 3 bytes | 4 bytes | 5 bytes | 6 bytes |
|---|---|---|---|---|---|---|---|
0000 | Nul | 00 | C0 80 | E0 80 80 | F0 80 80 80 | F8 80 80 80 80 | FC 80 80 80 80 80 |
0073 | Small latin s | 73 | C1 B3 | E0 81 B3 | F0 80 81 B3 | F8 80 80 81 B3 | FC 80 80 80 81 B3 |
041A | Great Cyrillic K | D0 9A | E0 90 9A | F0 80 90 9A | F8 80 80 90 9A | FC 80 80 80 90 9A | |
0BF5 | Symbol of the year in Tamil ௵ | E0 AF B5 | F0 80 AF B5 | F8 80 80 AF B5 | FC 80 80 80 AF B5 | ||
26218 | Chinese character |
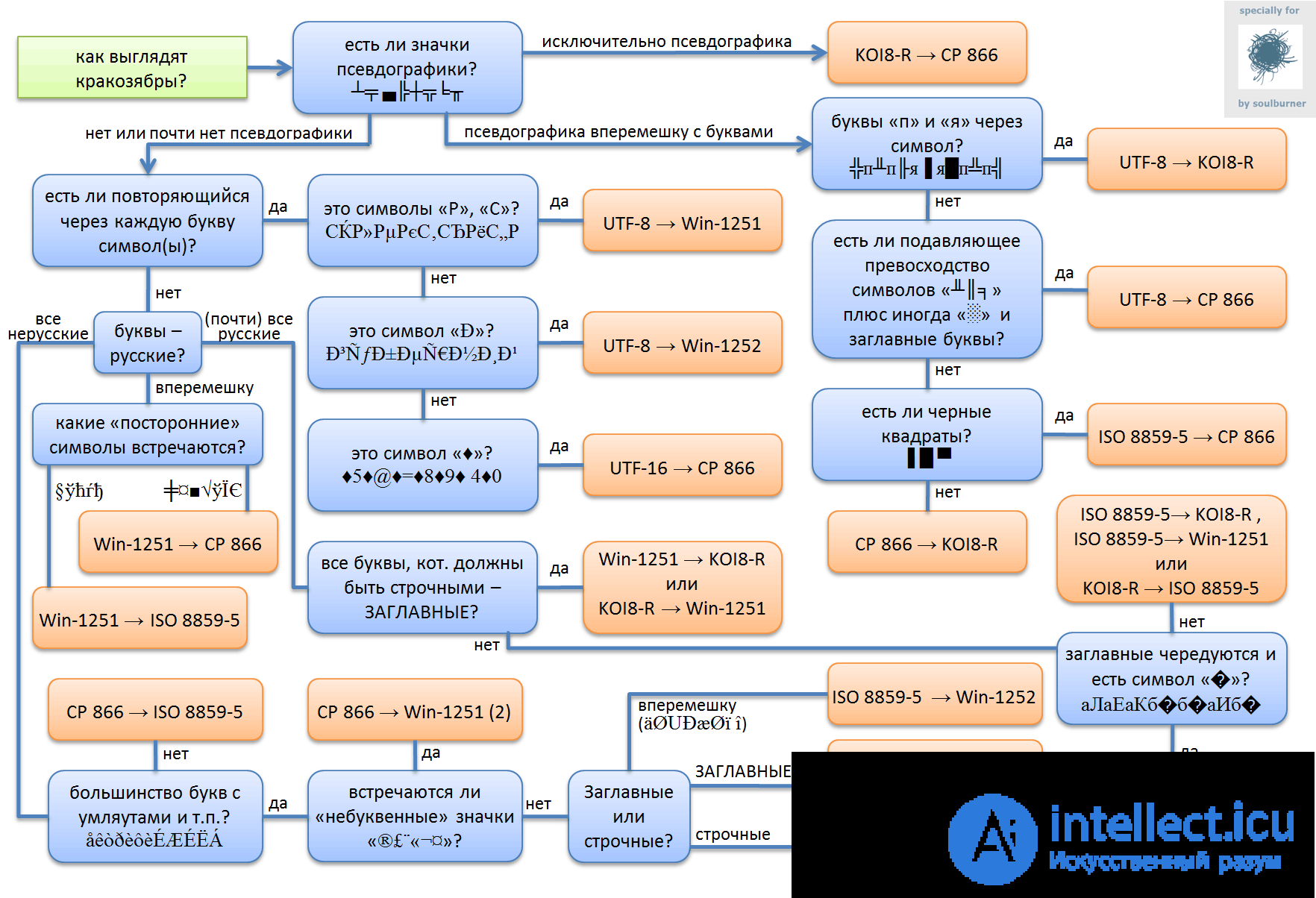
The examples below are for quick orientation in cases of incorrect decoding of the text (the so-called krakozyabry [en] ).
This is how the phrase “A person will now see only what he expects to see.” If it is perceived by a decoder in Windows-1251 encoding, and not UTF-8:
ЧеР"овек СЃРµР№С ‡ Р ° СЃ СѓРІРёРґРЁС‚ Р "РОС € СЊ то, С З СРР РРРРРРРРРРС Ñ СРРРРРРРС With.
The phrase “A person will now see only what he expects to see.” When double encoding UTF-8 to UTF-8:
ЧеР"Р С • Р Р † РµРС" СЃРµРв "-РЎвЂРР В ° РЎРѓ РЎС" Р Р † Р С'Р Т'Р С'С‚ Р В "Р С'С€ РЎРЉ РЎвЂљР С •, РЎвЂЎРЎвЂљР С • Р С • Р¶РС'Р Т'Р В ° Р ВµРЎвЂ РЎС "Р Р † Р С'Р Т'РµСвЂРРРР.
Self-synchronization in UTF-8 can be considered when random bytes are fed to your program and you need to determine the beginning of the first character. The primary sign is a flush high bit of a byte - this is an ASCII character. If it is set, then skip those bytes that have the bit cleared before the most significant one. In other cases, you can continue character-by-character decoding.
UTF-8 has the property of self-synchronization when processing 8-bit bytes. An alternative to UTF-8 is UTF-16 encoding, which is already processed in 16-bit words. There may be a doubt that UTF-16 is not self-synchronizing. At the moment, the overwhelming majority of data is transmitted in integral octets - 8 bits or nothing (see IPv4, IPv6, SATA for modern hardware and ATA with PATA for the recent one). Under these conditions, UTF-8 has the advantage of characterizing self-synchronization over UTF-16 when it comes to hardware data transfer or byte stream operation (reading Unicode data from an arbitrary position). If the work is carried out in the RAM of one machine, then UTF-16 is also self-synchronizing (if the equipment is capable of delivering whole 16-bit words).
Windows-1251 - character set and encoding, which is a standard 8-bit encoding for Russian versions of Microsoft Windows up to version 10. In the past, enjoyed quite great popularity. It was created on the basis of the encodings used in the early "self-made" crack Windows in 1990-1991. together with representatives of Paragraph, Dialogue, and the Russian branch of Microsoft. The original version of the encoding was very different from the one presented in the table below (in particular, there were a significant number of “white spots”).
In modern applications, Unicode (UTF-8) is preferred. Only 1.9% of all web pages use Windows-1251 for February 2016. [1]
Windows-1251, like KOI8-R, compares favorably with other 8-bit Cyrillic encodings (such as CP866 and ISO 8859-5) in the presence of almost all the characters used in Russian typography for plain text (only the accent mark is missing); It also contains all the characters for other Slavic languages: Ukrainian, Belarusian, Serbian, Macedonian and Bulgarian.
Windows-1251 has two drawbacks:
-1 , in the additional code 8 bits long, which is 255 , is often used in programming as a special value. 
Comments
To leave a comment
Informatics
Terms: Informatics