Lecture
| Binary search tree | ||
|---|---|---|
| Type of | Tree | |
| Time complexity in O-symbolism |
||
| Average | At worst | |
| Memory consumption | O (n) | O (n) |
| Search | O (log n) | O (n) |
| Insert | O (log n) | O (n) |
| Deletion | O (log n) | O (n) |

Sample binary search tree
A binary search tree (born binary search tree , BST) is a binary tree for which the following additional conditions are met ( properties of the search tree ):
Obviously, the data in each node must have keys that have a smaller comparison operation.
Typically, the information representing each node is a record, not a single data field. However, this concerns the implementation, not the nature of the binary search tree.
For the purposes of implementation, a binary search tree can be defined as:
A binary search tree should not be confused with a binary heap built by different rules.
The main advantage of a binary search tree over other data structures is the possible high efficiency of the implementation of search and sort algorithms based on it.
The binary search tree is used to build more abstract structures, such as sets, multisets, associative arrays.
The basic interface of the binary search tree consists of three operations:
This abstract interface is a common case, for example, of such interfaces taken from applied tasks:
In essence, a binary search tree is a data structure capable of storing a table of pairs (key, value) and supporting three operations: FIND, INSERT, REMOVE.
In addition, the binary tree interface includes three additional operations to traverse the tree nodes: INFIX_TRAVERSE, PREFIX_TRAVERSE, and POSTFIX_TRAVERSE. The first of them allows you to bypass the nodes of the tree in the order of non-decreasing keys.
Given : tree T and key K.
Task : check whether there is a node with key K in the T tree, and if so, return a link to this node.
Algorithm :
Given : tree T and a pair (K, V).
Task : insert a pair (K, V) into the tree T (if K coincides, replace V).
Algorithm :
Given : tree T with root n and key K.
Task : remove the node with the key K from the tree T (if there is one).
Algorithm :
There are three tree traversal operations that differ in the traversal order of the nodes.
The first operation, INFIX_TRAVERSE, allows you to bypass all the nodes of the tree in ascending order of keys and apply a user-defined callback function f, the operand of which is the node address, to each node. This function usually works only with a pair (K, V) stored in a node. The INFIX_TRAVERSE operation can be implemented in a recursive manner: first, it starts itself for the left subtree, then it starts this function for the root, then it starts it for the right subtree.
In other sources, these functions are named inorder, preorder, postorder, respectively [1]
INFIX_TRAVERSE
Given : tree T and function f
Task : apply f to all nodes of tree T in ascending order of keys
Algorithm :
In the simplest case, the function f can output the value of a pair (K, V). When using the INFIX_TRAVERSE operation, all pairs will be displayed in ascending order of keys. If you use PREFIX_TRAVERSE, the pairs will be displayed in the order corresponding to the description of the tree given at the beginning of the article.
The “split tree by key” operation allows splitting one search tree into two: with keys < K 0 and ≥ K 0 .
Reverse operation: there are two search trees, one has < K 0 keys, the other has ≥ K 0 . Combine them into one tree.
We have two trees: T 1 (smaller) and T 2 (larger). First you need to decide where to get the root: from T 1 or T 2 . There is no standard method, possible options:
alg Merging Trees (T1, T2) if T1 is empty, return T2 if T2 is empty, return T1 if you decide to make a T1 root, then T = Merging Trees (T1.right, T2) T1. right = T return t1 otherwise T = Merging Trees (T1, T2.left) T2.left = T return t2
It is always desirable that all paths in the tree from root to leaf be approximately the same length, that is, the depth of both the left and right subtrees is approximately the same in any node. Otherwise, performance is lost.
In a degenerate case, it may turn out that the entire left tree is empty at each level, there are only right trees, and in this case the tree degenerates into a list (going to the right). Search (and, therefore, deletion and addition) in such a tree is equal in speed to a search in the list and much slower than a search in a balanced tree.
For tree balancing, the operation “tree rotation” is used. Turning to the left looks like this:
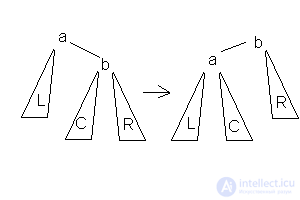
Turning to the right looks the same; it is enough to replace everything in the above example with Left to Right and back.
It is quite obvious that the rotation does not violate the orderliness of the tree, and has a predictable (+1 or −1) effect on the depths of all affected subtrees.
For deciding what kind of turns you need to make after adding or removing, use algorithms such as "red-ebony" and AVL.
Both of them require additional information in the nodes - 1 bit in red-black or a significant number in AVL.
A red-ebony tree requires <= 2 turns after adding and <= 3 after deletion, but the worst imbalance can be up to 2 times (the longest way is 2 times longer than the shortest one).
AVL-tree requires <= 2 turns after adding and to the depth of the tree after removal, but it is perfectly balanced (imbalance is not more than 1).
Balanced trees:

Comments