Lecture
This chapter and the following chapters explore the fundamental concept of a transaction. This concept is not included in the relational data model, since transactions are considered not only in relational DBMS, but also in other types of DBMS, as well as in other types of information systems.
A transaction is an indivisible, in terms of impact on the DBMS, the sequence of data manipulation operations. For the user, the transaction is performed on an " all or nothing " principle, i.e. either the transaction is executed entirely and transfers the database from one integral state to another integral state , or, for some reason, one of the transaction’s actions is impossible, or any system malfunction occurred, the database returns to its original state before the transaction begins (the transaction is rolled back). From this point of view, transactions are important in both multi-user and single-user systems. In single-user systems, transactions are logical units of work, after which the database remains in a consistent state . Transactions are also units of data recovery after failures - when recovering, the system eliminates the traces of transactions that did not succeed in completing successfully as a result of software or hardware failure. These two transaction properties determine the atomicity (indivisibility) of a transaction. In multi-user systems, in addition, transactions are used to ensure the isolated work of individual users - users who simultaneously work with one database, it seems that they work as if in a single-user system and do not interfere with each other.
To illustrate a possible violation of the integrity of the database, consider the following example:
Example 1 Suppose there is a system in which data are stored on the units and employees working in them. The list of divisions is stored in the DEPART table (Dep_Id, Dep_Name, Dept_Kol), where Dept_Id is the division identifier, Dept_Name is the name of the division, Dept_Kol is the number of employees in the division. The list of employees is stored in the PERSON table (Pers_Id, Pers_Name, Dept_Id), where Pers_Id is the employee identifier, Pers_Name is the name of the employee, Dept_Id is the identifier of the division in which the employee works:
| Dept_Id | Dept_Name | Dept_Kol |
|---|---|---|
| one | Department of Algebra | 3 |
| 2 | Department of Programming | 2 |
Table 1 DEPART
| Pers_Id | Pers_Name | Dept_Id |
|---|---|---|
| one | Ivanov | one |
| 2 | Petrov | 2 |
| 3 | Sidorov | one |
| four | Furs | 2 |
| five | Sharipov | one |
Table 2 PERSON
The integrity constraint of this database is that the Dept_Kol field cannot be filled with arbitrary values — this field must contain the number of employees actually registered in the unit.
Given this limitation, we can conclude that inserting a new employee into a table cannot be performed in a single operation . When inserting a new employee, you must simultaneously increase the value of the Dept_Kol field:
If after the first operation and before the second, the system fails, then only the first operation will be performed and the database will remain in a non-integral state.
Definition 1 . A transaction is a sequence of data manipulation statements that executes as a whole (all or nothing) and translates a database from one integral state to another integral state .
A transaction has four important properties known as ASID properties :
A transaction usually starts automatically when the user joins the DBMS and continues until one of the following events occurs:
COMMIT WORK ends the current transaction and automatically starts a new transaction. At the same time it is guaranteed that the results of the work of the completed transaction are recorded, i.e. stored in the database.
Remark Some systems (for example, Visual FoxPro) require that you give the explicit BEGIN TRANSACTION command in order to start a new transaction.
The ROLLBACK WORK command causes all changes made by the current transaction to be rolled back, i.e. canceled as if they were not there at all . This automatically starts a new transaction.
When a user disconnects from the DBMS, transactions are automatically committed.
In the event of a system failure, more complex processes occur. Briefly, their essence boils down to the fact that the next time the system is started, an analysis of the transactions that were running until the moment of failure occurs. Those transactions for which the COMMIT WORK command was submitted, but the results of which have not been entered into the database, are executed again (are rolled). Those transactions for which the COMMIT WORK command was not submitted are rolled back. Crash recovery is discussed in more detail below.
The properties of ASID transactions are not always fully implemented. This especially applies to the property And (isolation). Ideally, transactions of different users should not interfere with each other, i.e. they must be executed so that the user has the illusion that he is alone in the system. The simplest way to ensure absolute isolation is to line up transactions in a queue and execute them strictly one by one. Obviously, while losing the effectiveness of the system. Therefore, at the same time, several transactions are executed simultaneously (a mixture of transactions). There are several levels of transaction isolation. At the lowest isolation level, transactions can really interfere with each other, at the highest level they are completely isolated. For large transaction isolation, one has to pay large system overhead and slow down. Users or the system administrator can, at their discretion, set different levels for all or individual transactions. Transaction isolation is discussed in more detail in the next chapter.
Property D (durability) is also not an absolute property, since some systems allow nested transactions. If transaction B is running inside transaction A, and for transaction B a COMMIT WORK command is issued, then the commit of transaction B data is conditional, since external transaction A may roll back. The results of the operation of the internal transaction B will be finally recorded only if the external transaction A is recorded.
Property (C) - the consistency of transactions is determined by the presence of the concept of consistency of the database.
Definition 2 . Integrity constraint is a statement that can be true or false depending on the state of the database.
Examples of integrity constraints include the following:
Example 2 The employee’s age cannot be less than 18 and more than 65 years old.
Example 3 Each employee has a unique personnel number.
Example 4 Employee must be registered in the same department.
Example 5 The invoice amount must be equal to the sum of the product price of goods for the quantity of goods for all goods included in the invoice.
As you can see from these examples, some of the integrity constraints are constraints of the relational data model (see Chapter 3). Example 3 is a constraint that implements entity integrity. Example 4 is a constraint implementing referential integrity. Other restrictions are fairly arbitrary statements (examples 2 and 5). Any integrity constraint is a semantic concept, i.e. appears as a consequence of certain properties of objects in the domain and / or their interrelations.
Definition 3 . The database is in a consistent (holistic) state if all integrity constraints defined for the database are met (satisfied).
In this definition, it is important to emphasize that not all general domain restrictions should be met, but only those defined in the database. For this, it is necessary for the DBMS to have advanced tools for maintaining integrity constraints. If any DBMS cannot display all the necessary restrictions of the subject area, then such a database will be in a complete state from the point of view of the DBMS, but this state will not be correct from the point of view of the user.
Thus, database consistency is a formal property of the database. The database does not understand the "meaning" of the stored data. The "meaning" of data for a DBMS is the entire set of integrity constraints. If all restrictions are met, the DBMS assumes that the data is correct.
Together with the notion of database integrity, the notion of a system’s response to an integrity violation attempt arises. The system should not only check if the restrictions are violated during the execution of various operations, but also respond properly if the operation results in a violation of integrity. There are two types of response to an attempted integrity violation:
For example, if the system knows that there should be integers in the field "Employee_Estay" in the range from 18 to 65, then the system rejects an attempt to enter an age value of 66. Some message for the user can be generated.
In contrast, in example 1, the system allows the insertion of a record about a new employee (which leads to a breach of the database integrity), but automatically performs compensating actions by changing the value of the Dept_Kol field in the DEPART table.
The system for checking constraints can be represented in the following figure:
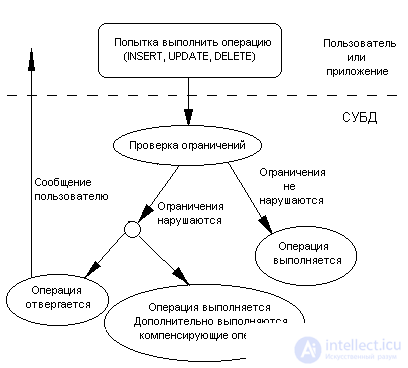
Picture 1
In some cases, the system may not perform a check for violation of restrictions, and immediately perform compensating operations. Indeed, in Example 1, when inserting or deleting an employee, verification is not necessary , since Its results are known in advance - the restriction will necessarily be violated. In this case, you must immediately begin to compensate for the violation.
Integrity constraints can be classified in several ways:
Each system has its own means of maintaining integrity constraints. There are two ways to implement:
Definition 4 . The declarative support for integrity constraints is to define constraints using the Data Definition Language (DDL). Typically, the means of declarative integrity support (if they are in the DBMS) define restrictions on the values of domains and attributes, entity integrity (potential relationship keys), and referential integrity (foreign key integrity). Declarative integrity constraints can be used to create and modify tables with DDL or as separate statements (ASSERTION).
For example, the following statement creates the PERSON table and defines some integrity constraints for it:
CREATE TABLE PERSON (Pers_Id INTEGER PRIMARY KEY, Pers_Name CHAR (30) NOT NULL, Dept_Id REFERENCES DEPART (Dept_Id) ON UPDATE CASCADE ON DELETE CASCADE);
After the statement is executed, the following integrity constraints will be declared for the PERSON table:
The means of declarative constraint support are described in the SQL standard and are discussed in more detail below.
Definition 5 . Procedural support for integrity constraints is the use of triggers and stored procedures.
Not all integrity constraints can be implemented declaratively. An example of such a restriction is the requirement from Example 1, which states that the Dept_Kol field of the DEPART table must contain the number of employees actually registered in the division. To implement this restriction, it is necessary to create a trigger that starts when inserting, modifying and deleting records in the PERSON table, which correctly changes the value of the Dept_Kol field. For example, when a new row is inserted into the PERSON table, the trigger increases by one the value of the Dept_Kol field, and when the row is deleted, it decreases. Note that the modification of records in the PERSON table may require even more complex actions. Indeed, the modification of an entry in the PERSON table may consist in the fact that we are transferring an employee from one department to another, changing the value in the Dept_Id field. At the same time, it is necessary to reduce the number of employees in the old division, and to increase in the new one.
In addition, it is necessary to protect against improper modification of the rows of the DEPART table. Indeed, a user can try to modify a department record by entering the wrong value for the Dept_Kol field. To prevent such actions, you must also create triggers that run when inserting and modifying records in the DEPART table. A trigger that starts when deleting records from the DEPART table is not needed, because there is already a referential integrity constraint that cascadely deletes records from the PERSON table when deleting a record from the DEPART table.
In fact, the presence of integrity constraints (both declarative and procedural) always leads to the creation or use of some program code that implements this restriction. The difference lies in where such code is stored and how it is created.
If the integrity constraint is implemented as triggers, then this program code is simply the body of the trigger. If a declarative integrity constraint is used, then two approaches are possible:
An example of using kernel functions to check declarative constraints is the automatic verification of the uniqueness of indexes corresponding to potential relationship keys. As another example, reference integrity can be supported using ORACLE DBMS. A referential integrity constraint is a database object in ORACLE storing the statement of this constraint. The constraint check is performed by the ORACLE kernel functions with reference to this object. In this case, integrity constraint cannot be modified otherwise than using declarative statements for creating and modifying constraints.
An example of generating new triggers for implementing declarative constraints is Visual FoxPro. Triggers automatically generated by Visual FoxPro when declaring referential integrity constraints can be viewed and even modified, so that they can perform some additional actions.
If the system does not support either declarative support for referential integrity, or triggers (like, for example, FoxPro 2.5), then the program code that monitors the correctness of the database has to be placed in the user application (such code is still needed!). This greatly complicates the development of programs and does not protect users from attempts to directly enter incorrect data into the database. It becomes especially difficult when there is a complex database and many different applications that work with it (for example, several applications can access the database of a commercial enterprise, such as Warehouse Accounting, Order Acceptance, Chief Accountant and etc.). Each of these applications must contain the same code responsible for maintaining the integrity of the database. It becomes especially fun for the developer when it is necessary to make changes to the logic of maintaining integrity. It is necessary to replace the same places in all programs, recompile all applications and distribute new versions to the workplaces.
By the time of check, restrictions are divided into:
Definition 6 . Immediately verifiable constraints are checked immediately at the time of the operation that might violate the constraint. Например, проверка уникальности потенциального ключа проверяется в момент вставки записи в таблицу. Если ограничение нарушается, то такая операция отвергается. Транзакция, внутри которой произошло нарушение немедленно проверяемого утверждения целостности, обычно откатывается.
Определение 7 . Ограничения с отложенной проверкой проверяется в момент фиксации транзакции оператором COMMIT WORK. Внутри транзакции ограничение может не выполняться. Если в момент фиксации транзакции обнаруживается нарушение ограничения с отложенной проверкой, то транзакция откатывается. Примером ограничения, которое не может быть проверено немедленно является ограничение из примера 1. Это происходит оттого, что транзакция, заключающаяся во вставке нового сотрудника в таблицу PERSON, состоит не менее чем из двух операций - вставки строки в таблицу PERSON и обновления строки в таблице DEPART. Ограничение, безусловно, неверно после первой операции и становится верным после второй операции.
По области действия ограничения делятся на:
Определение 8 . Ограничения целостности домена представляют собой ограничения, накладываемые только на допустимые значения домена. Фактически, ограничения домена обязаны являться частью определения домена (см. определение домена в гл. 2).
Например, ограничением домена "Возраст сотрудника" может быть условие "Возраст сотрудника не менее 18 и не более 65".
Проверка ограничения . Ограничения домена сами по себе не проверяются. Если на каком-либо домене основан атрибут, то ограничение соответствующего домена становится ограничением этого атрибута.
Определение 9 . Ограничение целостности атрибута представляют собой ограничения, накладываемые на допустимые значения атрибута вследствие того, что атрибут основан на каком-либо домене. Ограничение атрибута в точности совпадают с ограничениями соответствующего домена. Отличие ограничений атрибута от ограничений домена в том, что ограничения атрибута проверяются .
Если логика предметной области такова, что на значения атрибута необходимо наложить дополнительные ограничения, помимо ограничений домена, то такие ограничения переходят в следующую категорию.
Проверка ограничения . Ограничение атрибута является немедленно проверяемым ограничением. Действительно, ограничение атрибута не зависит ни от каких других объектов базы данных, кроме домена, на котором основан атрибут. Поэтому никакие изменения в других объектах не могут повлиять на истинность ограничения.
Определение 10 . Ограничения целостности кортежа представляют собой ограничения, накладываемые на допустимые значения отдельного кортежа отношения, и не являющиеся ограничением целостности атрибута. Требование, что ограничение относится к отдельному кортежу отношения, означает, что для его проверки не требуется никакой информации о других кортежах отношения.
Example 6 Атрибут "Возраст сотрудника" в таблице "Спецподразделение", может иметь дополнительное ограничение "Возраст сотрудника не менее 25 и не более 45", помимо того, что этот атрибут уже имеет ограничение, определяемое доменом - "Возраст сотрудника не менее 18 и не более 65".
Приведенное ограничение кортежа, по сути, является дополнительным ограничением на значения одного атрибута. В этом случае допустимы два решения. Можно объявить новый домен "Возраст сотрудника спецподразделения" и тогда ограничение кортежа становится ограничением домена и атрибута, либо рассматривать это ограничение именно как ограничение кортежа. Оба решения имеют свои положительные и отрицательные стороны.
Remark Тут имеются некоторые возможности для оптимизации. Формально, при изменении значения данного атрибута необходимо проверить два ограничения - ограничение атрибута и ограничение кортежа. Но в данном случае ограничение кортежа сильнее ограничения атрибута и достаточно проверить только ограничение кортежа. Разумно построенная СУБД могла бы выявлять такие случаи и уменьшать лишнюю работу.
Example 7 Для отношения "Сотрудники" можно сформулировать следующее ограничение: если атрибут "Должность" принимает значение "Директор", то атрибут "Зарплата" содержит значение не менее 1000$.
Это ограничение связывает два атрибута одного кортежа.
Пример 8 . В накладной можно установить следующую взаимосвязь атрибутов - "Цена*Количество=Сумма", связывающую атрибуты "Цена", "Количество", "Сумма".
Данный пример кажется неестественным, т.к. сумма является явно избыточным атрибутом, значение которого просто выводятся из значений других атрибутов. Поэтому кажется, что лучше хранить только два базовых атрибута "Цена" и "Количество", а сумму вычислять во время выполнения запросов по мере необходимости. Так, собственно, требует реляционная теория, стремящаяся свести избыточность к минимуму. В практике, однако, дело обстоит сложнее. Например, каждая строка реальной накладной может содержать следующие данные о товаре:
| Наиме-нование атрибута | Описание атрибута | Базовый ли атрибут | Формула для вычислимого атрибута |
|---|---|---|---|
| Name | Name of product | Yes | |
| N | amount | Yes | |
| P1 | Учетная цена товара | Yes | |
| S1 | Учетная сумма на все количество | S1 = N*P1 | |
| PerSent | Процент наценки на единицу товара | Yes | |
| P2 | Наценка на единицу товара | P2 = P1*PerSent/100 | |
| S2 | Сумму наценки на все количество | S2 = N*P2 | |
| P3 | Цену товара с учетом наценки | P3 = P1+P2 | |
| S3 | Сумму на все количество с учетом наценки | S3 = N*P3 | |
| NDS | Процент НДС | Yes | |
| P4 | Сумма НДС на единицу товара | P4 = P2*NDS/100 | |
| S4 | Сумма НДС на все количество | S4 = N*P4 | |
| P5 | Цена товара с НДС | P5 = P3+P4 | |
| S5 | Сумма на все количество с НДС | S5 = N*P5 |
Таблица 3 Атрибуты товара
Базовыми, т.е. требующими ввода данных являются всего 5 атрибутов (выделены серым цветом). Все остальные атрибуты вычисляются по базовым. Нужно ли хранить в отношении только базовые атрибуты, или желательно хранить все атрибуты, пересчитывая значения вычислимых атрибутов каждый раз при изменении базовых?
Решение 1 . Пусть в отношении решено хранить только базовые атрибуты .
Достоинства решения:
Недостатки решения:
Решение 2 . Предположим, что в отношении решено хранить все атрибуты , в том числе и вычислимые.
Достоинства решения:
Недостатки решения:
Как видим, оба решения имеют свои достоинства и недостатки. Важно то, что программный код, содержащий эти формулы, не исчезает ни в каком из этих решений (да и куда он денется, раз такова предметная область!). Только в одном случае код хранится в одном месте, а в другом может быть "размазан" по всему приложению.
На самом деле данный пример сильно упрощен, т.к. еще одной неприятной особенностью наших бухгалтерий является то, что все расчеты должны вестись с определенной точностью, а именно - до копеек. Возникает проблема округления, а это еще более усложняет формулы для расчетов цен. Простой пример - вычисление НДС содержит операцию деления, следовательно может приводить к бесконечным дробям типа 15,519999… Такую дробь необходимо округлить до 15.52. Если продается одна единица товара, то это не страшно, но если продается несколько единиц товара, то сумму НДС на все количество можно считать по разным формулам:
Лирическое отступление . Автор, как математик по образованию (к.ф.-м.н.), считает, что верной, безусловно, является первая формула. Действительно, вычисляя по первой формуле, мы получим одну и ту же сумму НДС независимо от того, продали мы одну партию товара, содержащую 50 единиц, или продали 50 партий по одной единице в каждой. При вычислениях по второй формуле сумма НДС в партии, состоящий из 50 единиц товара отличается от суммы НДС по 50 партиям по одной единице товара в каждой. Разработав несколько складских программ, автор получал разные ответы на этот вопрос в разных бухгалтерия, разные ответы на этот вопрос в одной бухгалтерии в разное время, и разные ответы на этот вопрос в разных налоговых инспекциях. В конечном итоге, автор пришел к грустному выводу, что для того, чтобы стать бухгалтером, его способностей и образования недостаточно.
Другие решения . Можно попытаться использовать и другие решения, для облегчения разработки и сопровождения в данном случае. Например, можно хранить в базовом отношении только базовые атрибуты, а для работы бухгалтерии использовать заранее подготовленные представления (динамические отношения, задаваемые оператором SQL). Тогда логика расчетов будет храниться в одном SQL-операторе, определяющем это представление. Другим вариантом может быть сохранение формул в виде хранимых процедур и функций базы данных.
Проверка ограничения . К моменту проверки ограничения кортежа должны быть проверены ограничения целостности атрибутов, входящих в этот кортеж.
Ограничение кортежа является немедленно проверяемым ограничением. Действительно, ограничение кортежа не зависит ни от каких других объектов базы данных, кроме атрибутов, входящих в состав кортежа. Поэтому никакие изменения в других объектах не могут повлиять на истинность ограничения.
Определение 11 . Ограничения целостности отношения представляют ограничения, накладываемые только на допустимые значения отдельного отношения, и не являющиеся ограничением целостности кортежа. Требование, что ограничение относится к отдельному отношению, означает, что для его проверки не требуется информации о других отношениях (в том числе не требуется ссылок по внешнему ключу на кортежи этого же отношения).
Example 9 Ограничение целостности сущности (см. гл. 3), задаваемое потенциальным ключом отношения, является ограничением отношения, т.к. для его проверки необходимо иметь информацию обо всех кортежах отношения (более точно, обо всех занятых в данный момент значениях потенциального ключа).
Пример 10 . Ограничение целостности, определяемые наличием функциональных, многозначных зависимостей и зависимостей соединения, являются ограничениями отношения.
Example 11 Предположим, что в отношении PERSON (см. пример 1) задано следующее ограничение - в каждом отделе должно быть не менее двух сотрудников. Это ограничение можно сформулировать так - количество строк с одинаковым значением Dept_Id должно быть не меньше 2.
Remark Для того чтобы ввести в действие (объявить) это ограничение, необходимо, чтобы в отношение уже были вставлены некоторые кортежи.
Example 12 Ограничение целостности, определяемое требованием, что некоторая таблица должна быть не пуста, являются ограничениями отношения.
Проверка ограничения . К моменту проверки ограничения отношения должны быть проверены ограничения целостности кортежей этого отношения.
Ограничение отношения может быть как немедленно проверяемым ограничением, так и ограничением с отложенной проверкой .
Ограничение отношения, являющееся ограничением потенциального ключа (пример 9) является немедленно проверяемым ограничением.
Ограничение, определенное наличием функциональной зависимости атрибутов также является немедленно проверяемым ограничением.
Ограничения же, определенные многозначной зависимостью или зависимостью соединения являются ограничениями с отложенной проверкой. Действительно, эти ограничения требуют, чтобы кортежи вставлялись и удалялись целыми группами (см. гл. 7). Это невозможно сделать, если выполнять проверку после каждой одиночной вставки или удаления кортежа.
The constraint in Example 11 seems immediately verifiable. Indeed, it is possible immediately after inserting or deleting a tuple to check whether the constraint is being fulfilled, and, if it is not performed, then roll back the operation. But, however, in this case, it is impossible to insert any new tuple for the new department. At least two employees must be inserted into the new department at once. Thus, this limitation is deferred.
The limitation from Example 12 makes sense to check only when removing tuples from a relation. This restriction can be either immediately verifiable or deferred.
Definition 12 . Database integrity constraints are restrictions imposed on the values of two or more related relationships (including the relationship may be self-related).
Example 13 The link integrity constraint (see Chapter 3), specified by the relation's foreign key, is a database constraint.
Example 14 The constraint on the DEPART and PERSON tables from Example 1 is the database relation, since it links data located in different tables.
Check constraints . By the time the database constraints are checked, the integrity constraints of the relationships should be checked.
A database constraint can be either an immediately verifiable constraint or a deferred check constraint.
A relationship constraint, which is a foreign key constraint, can be either an immediately verifiable constraint or a deferred constraint. Indeed, in the simplest case, if the tuple 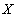 relations
relations 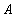 must refer to a tuple
must refer to a tuple 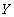 relations
relations 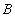 then the referential integrity constraint can be checked immediately after any of the insert, update or delete operations in any of the relations
then the referential integrity constraint can be checked immediately after any of the insert, update or delete operations in any of the relations 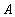 or
or  . In a more complicated case, suppose the tuple relations must refer to a tuple relations and tuple relations must in turn refer to a tuple relations (circular reference). Obviously, immediately after inserting a tuple an attitude referential integrity is necessarily broken, since tuple not yet in relation . Reference integrity can be checked only after the completion of a transaction consisting of a sequence of operations:
. In a more complicated case, suppose the tuple relations must refer to a tuple relations and tuple relations must in turn refer to a tuple relations (circular reference). Obviously, immediately after inserting a tuple an attitude referential integrity is necessarily broken, since tuple not yet in relation . Reference integrity can be checked only after the completion of a transaction consisting of a sequence of operations:
regarding with zero reference to relationship , an attitude with reference to a tuple relations , NULL to tuple link .The constraint given in Example 1 can only be a deferred check constraint.
The SQL standard does not provide for procedural integrity constraints implemented with triggers and stored procedures. The SQL 92 standard lacks the notion of "trigger", although there are triggers in all industrial SQL-type DBMSs. Thus, the implementation of restrictions by means of a specific DBMS is more flexible than using only standard SQL tools.
The SQL standard allows you to set declarative constraints in the following ways:
Both immediately checked and deferred check restrictions are allowed. The mode of checking pending constraints can be changed at any time so that the constraint is checked:
When defining a constraint, the type of constraint check is indicated - whether this constraint is non-deferrable ( NOT DEFERRED ) or can be deferred ( DEFERRED ). In the second case, you can set the default procedure: check immediately or check upon completion of the transaction . Thus, you can define a potentially deferred constraint, which by default is checked immediately. At any time, the verification mode of such a restriction can be changed to pending and vice versa. The verification mode can be changed for one constraint or for all potentially delayed constraints at once. If the constraint is defined as non-deferrable, the type of such constraint cannot be changed and the constraint is always checked immediately.
The procedural elements are still present in the SQL standard in the form of so-called actions executed by reference ( referential triggered actions ). These actions determine what happens when the value of the parent key that is referenced by a foreign key changes. These actions can be set independently for update operations (ON UPDATE) or for delete operations (ON DELETE) of records in the parent relation. The SQL standard defines 4 types of actions performed by reference:
As you can see, the actions executed by reference are in fact triggers built into the DBMS. Actions like CASCADE, SET NULL and SET DEFAULT are compensating operations that are invoked when attempting to violate referential integrity.
The term restriction is used in many data definition statements (DDL).
Check restriction :: =
CHECK Predicate
Table Restrictions :: =
[ CONSTRAINT Name of Restriction ]
{
{ PRIMARY KEY ( Column Name ., ..)}
| { UNIQUE ( Column Name ., ..)}
| { FOREIGN KEY ( Column name ., ..) REFERENCES Table name [( Column name ., ..)] [ Reference Specification ]}
| { Check limit }
}
[ Attributes restrictions ]
Column constraints :: =
[ CONSTRAINT Name of Restriction ]
{
{ NOT NULL }
| { PRIMARY KEY }
| { UNIQUE }
| { REFERENCES Table Name [( Column Name )] [ Reference Specification ]}
| { Check limit }
}
[ Attributes restrictions ]
Reference Specification :: =
[ MATCH { FULL | PARTIAL }]
[ ON UPDATE { CASCADE | SET NULL | SET DEFAULT | NO ACTION }]
[ ON DELETE { CASCADE | SET NULL | SET DEFAULT | NO ACTION }]
Restriction Attributes :: =
{ DEFERRABLE [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]}
| { NOT DEFERRABLE }
CHECK type constraint . The type constraint CHECK contains a predicate that can be TRUE, FALSE, and UNKNOWN (NULL). Examples of different types of predicates are given in Chapter 5. A CHECK type constraint can be used as part of a domain description, a table, a table column, or a separate integrity constraint — ASSERTION. A constraint is considered violated if the predicate constraint is FALSE.
Example 15 An example of a CHECK type constraint:
CHECK (Salespeaple.Salary IS NOT NULL) OR (Salespeaple.Commission IS NOT NULL)
This restriction states that each seller must have either a non-zero salary or a non-zero commission.
Example 16 Another example of a CHECK constraint:
CHECK EXIST (SELECT * FROM Salespeaple)
This restriction states that the list of sellers cannot be empty.
Table constraints and column constraints . Table constraints and table column constraints are included as part of the description, respectively, of the table or table column. A table constraint can refer to multiple columns in a table. A column constraint applies to only one table column. Any column constraint can be described as a table constraint, but not vice versa.
Restrictions of a table or column can have names, with the help of which you can further cancel this restriction or change the time for checking it.
PRIMARY KEY LIMIT . A PRIMARY KEY constraint for a table or column means that a group of one or more columns forms a potential table key. This means that the combination of values
продолжение следует...
Часть 1 9. Transactions and database integrity
Часть 2 Syntax of SQL statements using constraints - 9. Transactions and

Comments