Lecture
The article covers only the main issues of using locks in MySQL. Not covered transactions, isolation levels, advisory lock, etc. Write in the comments which of the questions you are interested in.
The title "banner banner on MySQL" is entitled a note on examples of incorrect and inefficient use of the MySQL server. A typical example of a system that often works inefficiently with MySQL is the banner ad manager.
As an example, the PHP Ad Manager program was analyzed. The program was chosen randomly from dozens like her on sourceforge.net.
The main features of the program are listed below:
Below is an abbreviated and simplified list of requests that is performed by the PHP Ad Manager system at each banner display.
Get the domain for which the banner is scrolling
select * from domains where ...
Getting a list of ad units that a user can show on this domain
select * from ads where active = 'Y' and expiredate > 'ТЕКУЩЕЕ-ВРЕМЯ' and domains LIKE '%ДОМЕН%' order by lastdisplay;
Updating the last time this ad was shown:
update ads set lastdisplay = 'ТЕКУЩЕЕ-ВРЕМЯ', hits='КОЛИЧЕСТВО ХИТОВ' WHERE adid = 'ИДЕНТИФИКАТОР'
Logging information
insert into adlog SET adid = 'ИД-БАННЕРА', type = 'hit', remotehost = '....', remoteaddr = '....', site = '.....', entrydate = '....';
In order to deal with the causes of possible problems, it is necessary to shed some more detail on the issue of working with table locks in MySQL.
According to the MySQL documentation, MySQL uses table-level locks for MyISAM, and row-level locks for InnoDB tables. MySQL supports two types of locks: write and read. Write locks take precedence over read locks. This, on the one hand, leads to the fact that data insertion / update requests do not “hang” with a large number of read requests. On the other hand, with a large number of data update requests, read requests can wait their turn for a very long time.
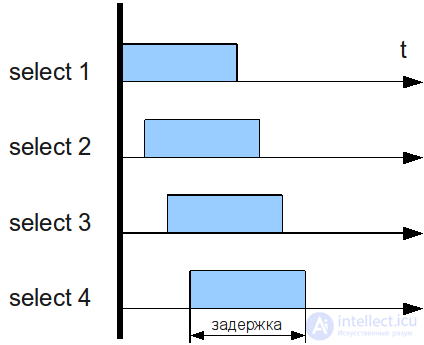
To demonstrate the problem, consider two examples. The first example is shown in the figure below. In this case, four queries per sample (SELECT) come to the MySQL server almost simultaneously. It can be seen that since SELECT queries have the ability to execute simultaneously, the wait time for the result of each query depends only on the execution time of the query itself.
In the second case, a situation is schematically presented, in which the same MySQL table is almost simultaneously addressed by 4 queries, of which two queries are sampling requests, and the other two are data refresh requests. Due to the fact that update requests are queued for execution before sampling requests, and also because they cannot be executed simultaneously with other requests in the MyISAM table, the waiting time for the SELECT result is significantly increased.
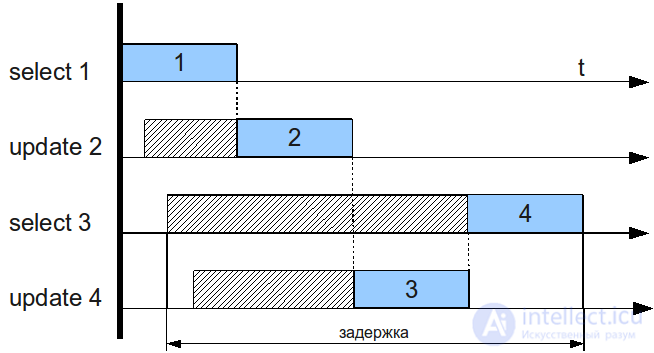
Additionally, it should be noted that if the first request turned out to be “heavy” (with a long execution time), this would further aggravate the situation of the second case. If neither UPDATE, all SELECTs would be executed at the same time, however, the presence of one UPDATE causes it to split the request queue into two: before and after, and the SELECTs in the third stage will not be executed until the first two stages are completed.
An estimate of the number of blocked requests can be performed as follows:
mysql> SHOW STATUS LIKE 'Table%'; +-----------------------+---------+ | Variable_name | Value | +-----------------------+---------+ | Table_locks_immediate | 1151552 | | Table_locks_waited | 15324 | +-----------------------+---------+
The first row of the table displays the number of lock requests that were satisfied immediately, and the second row shows the number of queries that had to be expected before obtaining the required access to the table.
For performance testing, you can use the program mysqlslap, which is part of MySQL 5.1.4 and higher (for lenny is available in the dotdeb repository).
It can be seen from the above description that problems arise, among other things, because the priority of UPDATE operations is higher than the priority of operations on data sampling. A simple solution that is likely to temporarily help alleviate the problem is to use the UPDATE LOW_PRIORITY query instead of an UPDATE query. A detailed description of the command syntax is available in the official documentation.
In the situation of a large number of INSERT queries that can block SELECT queries, MySQL developers recommend using a temporary table, the data from which can be transferred to the main table with a certain periodicity:
mysql> LOCK TABLES real_table WRITE, temp_table WRITE; mysql> INSERT INTO real_table SELECT * FROM temp_table; mysql> DELETE FROM temp_table; mysql> UNLOCK TABLES;
Non-relational databases (at least according to the statements of their developers) are more suitable for working with information in the "number of updates is comparable to the number of samples" than MySQL. As an example, mongodb may be suitable for such use.
mongodb is able to perform cheap "in-place" update operations (incrementing counters, etc.) without actually transferring data over the network, and also has an insert mode "upsert" (update an object, or create it if such an object is not found yet). For details on the use of these commands, it is best to refer to the documentation.
Below are two links to articles on the MongoDB blog (in English):
When developing new systems, try to avoid an architecture in which the number of data update requests is comparable to the number of SELECT requests. If this is not possible, try as much as possible to spread these operations over time, or use other techniques described above.

Comments
To leave a comment
Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL
Terms: Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL