Finally, the long-awaited fourth article in our cycle about big data. In this article we will talk about such a wonderful tool like Hbase, which has recently gained great popularity: for example, Facebook uses it as the basis of its messaging system, and we use hbase as the main raw data storage for our platform in the data-centric alliance Data Management Facetz.DCA
The article will cover the Big Table concept and its free implementation, features and difference from both classical relational databases (such as MySQL and Oracle), and key-value repositories, such as Redis, Aerospike, and memcached.
Interested? Welcome under cat.
Who and why came up with Hbase
As usual - let's start with the background. Like many other projects from the BigData field, Hbase originated from a concept that was developed by Google. The principles underlying Hbase were described in the article “Bigtable: A Distributed Storage System for Structured Data”.
As we have seen in previous articles, regular files are quite good for batch processing using the MapReduce paradigm.
On the other hand, the information stored in files is rather inconvenient to update; Files are also deprived of random access. For fast and convenient random access, there is a class of nosql-systems such as key-value storage, such as Aerospike, Redis, Couchbase, Memcached. However, usually in these systems batch processing is very inconvenient. Hbase is an attempt to combine the convenience of batch processing and the convenience of updating and random access.
Data model
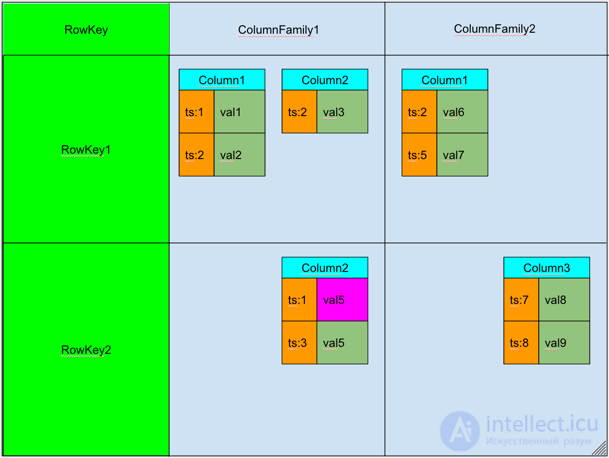
Hbase is a distributed, column-oriented, multi-version key-value database.
The data is organized into
tables indexed by the primary key, which in Hbase is called
RowKey .
For each
RowKey key, an unlimited set of
attributes (or columns) can be stored.
Columns are organized into
groups of columns called
Column Family . As a rule, columns that have the same usage and storage pattern are combined into one
Column Family .
For each
attribute can be stored several different
versions . Different versions have different
timestamp .
Records are physically stored in the order sorted by
RowKey . In this case, the data corresponding to different
Column Family are stored separately, which allows, if necessary, to read data only from the desired column family.
When you physically delete a certain
attribute, it is not immediately removed physically, but is only marked with a special
tombstone flag. Physical deletion of data will occur later when performing a Major Compaction operation.
Attributes belonging to the same
column group and corresponding to the same
key are physically stored as a sorted list. Any
attribute may be missing or present for each key, while if the
attribute is missing, it does not cause the overhead of storing null values.
The list and names
of the column groups are fixed and have a clear outline. At the column group level, parameters such as time to live (TTL) and the maximum number of stored
versions are set . If the difference between the
timestamp for a specific
version and the current time is greater than the TTL - the record is marked
for deletion . If the number of
versions for a particular
attribute has exceeded the maximum number of versions - the entry is also marked
for deletion .
Hbase data model can be remembered as matching key value:
< table , RowKey , Column Family , Column , timestamp > -> Value
Supported operations
The list of supported operations in hbase is quite simple. 4 basic operations are supported:
- Put: add a new entry to hbase. The timestamp of this record can be set manually, otherwise it will be set automatically as the current time.
- Get: get data on a specific RowKey. You can specify the Column Family, from which we will take the data and the number of versions that we want to read.
- Scan: read records one by one. You can specify the record with which we start reading, the record before which to read, the number of records that must be read, the Column Family from which reading will be made, and the maximum number of versions for each record.
- Delete: mark a specific version for deletion. There will be no physical deletion; it will be delayed until the next Major Compaction (see below).
Architecture
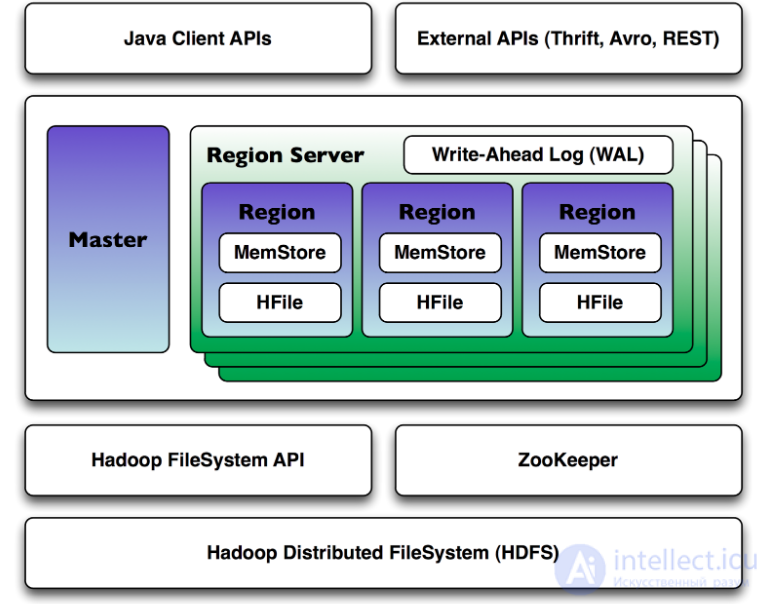
Hbase is a distributed database that can work on dozens and hundreds of physical servers, ensuring uninterrupted operation even if some of them fail. Therefore, the hbase architecture is quite complex compared to classic relational databases.
Hbase uses two main processes for its work:
1. Region Server - serves one or more regions. A region is a range of records corresponding to a specific range of consecutive RowKey. Each region contains:
- Persistent Storage - the main data storage in Hbase. Data is physically stored on HDFS, in a special HFile format. The data in HFile is stored in an order sorted by RowKey. One pair (region, column family) corresponds to at least one HFIle.
- MemStore - write buffer. Since the data is stored in HFile d in a sorted order, it is quite expensive to update HFile for each record. Instead, the data when recording falls into a special memory area MemStore, where they accumulate for some time. When filling MemStore to some critical value, the data is written to the new HFile.
- BlockCache - read cache. Allows you to significantly save time on data that is read frequently.
- Write Ahead Log (WAL). Since the data when recording falls into the memstore, there is some risk of data loss due to failure. In order for this not to happen, all operations before the actual implementation of the manipulations get into a special log file. This allows you to recover data after any failure.
2. Master Server - the main server in the hbase cluster. The master manages the distribution of regions across Region Servers, keeps a register of regions, manages the launch of regular tasks and does other useful work.
To coordinate actions between services, Hbase uses Apache ZooKeeper, a special service for managing configurations and synchronization of services.
As the amount of data in a region increases and it reaches a certain size, Hbase starts split, the operation that divides the region by 2. In order to avoid permanent divisions of the regions, you can pre-set the boundaries of the regions and increase their maximum size.
Since data for one region can be stored in several HFiles, Hbase periodically merges them together to speed up the work. This operation in Hbase is called compaction. Compactions are of two types:
- Minor Compaction. Runs automatically, runs in the background. It has a low priority compared to other Hbase operations.
- Major Compaction. It is launched by hand or upon the occurrence of certain triggers (for example, by timer). It has a high priority and can significantly slow down the cluster. Major Compactions are best done during a time when the cluster load is low. During Major Compaction, there is also the physical deletion of data labeled with tombstone marks.
Ways to work with Hbase
Hbase shell
The easiest way to get started with Hbase is to use the hbase shell utility. It is available immediately after installing hbase on any hbase cluster node.
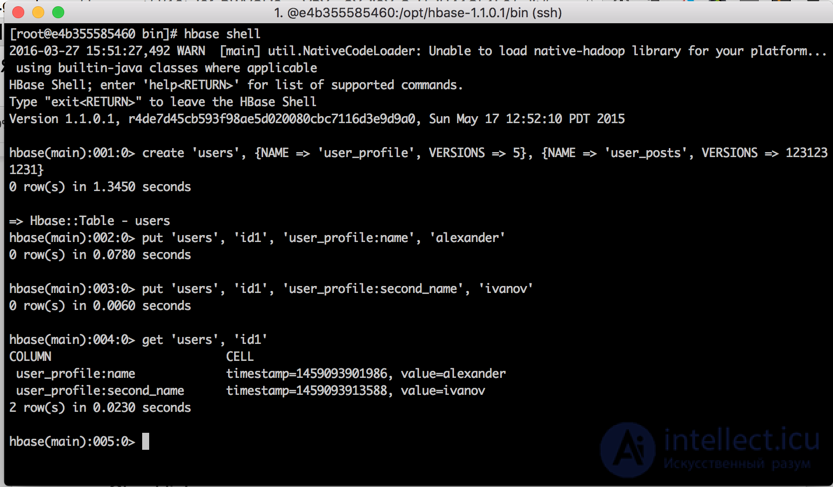
Hbase shell is a jruby console with built-in support for all major Hbase operations. Below is an example of creating a users table with two column families, performing some manipulations with it and deleting the table at the end in the hbase shell language:
Code sheet
create 'users', {NAME => 'user_profile', VERSIONS => 5}, {NAME => 'user_posts', VERSIONS => 1231231231} put 'users', 'id1', 'user_profile:name', 'alexander' put 'users', 'id1', 'user_profile:second_name', 'alexander' get 'users', 'id1' put 'users', 'id1', 'user_profile:second_name', 'kuznetsov' get 'users', 'id1' get 'users', 'id1', {COLUMN => 'user_profile:second_name', VERSIONS => 5} put 'users', 'id2', 'user_profile:name', 'vasiliy' put 'users', 'id2', 'user_profile:second_name', 'ivanov' scan 'users', {COLUMN => 'user_profile:second_name', VERSIONS => 5} delete 'users', 'id1', 'user_profile:second_name' get 'users', 'id1' disable 'users' drop 'users'
Native api
Like most other hadoop-related projects, hbase is implemented in the java language, therefore the native api is available for the java language. Native API is pretty well documented on the official site. Here is an example of using the Hbase API taken from the same place:
Code sheet
import java.io.IOException; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Get; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.ResultScanner; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.util.Bytes; // Class that has nothing but a main. // Does a Put, Get and a Scan against an hbase table. // The API described here is since HBase 1.0. public class MyLittleHBaseClient { public static void main(String[] args) throws IOException { // You need a configuration object to tell the client where to connect. // When you create a HBaseConfiguration, it reads in whatever you've set // into your hbase-site.xml and in hbase-default.xml, as long as these can // be found on the CLASSPATH Configuration config = HBaseConfiguration.create(); // Next you need a Connection to the cluster. Create one. When done with it, // close it. A try/finally is a good way to ensure it gets closed or use // the jdk7 idiom, try-with-resources: see // https://docs.oracle.com/javase/tutorial/essential/exceptions/tryResourceClose.html // // Connections are heavyweight. Create one once and keep it around. From a Connection // you get a Table instance to access Tables, an Admin instance to administer the cluster, // and RegionLocator to find where regions are out on the cluster. As opposed to Connections, // Table, Admin and RegionLocator instances are lightweight; create as you need them and then // close when done. // Connection connection = ConnectionFactory.createConnection(config); try { // The below instantiates a Table object that connects you to the "myLittleHBaseTable" table // (TableName.valueOf turns String into a TableName instance). // When done with it, close it (Should start a try/finally after this creation so it gets // closed for sure the jdk7 idiom, try-with-resources: see // https://docs.oracle.com/javase/tutorial/essential/exceptions/tryResourceClose.html) Table table = connection.getTable(TableName.valueOf("myLittleHBaseTable")); try { // To add to a row, use Put. A Put constructor takes the name of the row // you want to insert into as a byte array. In HBase, the Bytes class has // utility for converting all kinds of java types to byte arrays. In the // below, we are converting the String "myLittleRow" into a byte array to // use as a row key for our update. Once you have a Put instance, you can // adorn it by setting the names of columns you want to update on the row, // the timestamp to use in your update, etc. If no timestamp, the server // applies current time to the edits. Put p = new Put(Bytes.toBytes("myLittleRow")); // To set the value you'd like to update in the row 'myLittleRow', specify // the column family, column qualifier, and value of the table cell you'd // like to update. The column family must already exist in your table // schema. The qualifier can be anything. All must be specified as byte // arrays as hbase is all about byte arrays. Lets pretend the table // 'myLittleHBaseTable' was created with a family 'myLittleFamily'. p.add(Bytes.toBytes("myLittleFamily"), Bytes.toBytes("someQualifier"), Bytes.toBytes("Some Value")); // Once you've adorned your Put instance with all the updates you want to // make, to commit it do the following (The HTable#put method takes the // Put instance you've been building and pushes the changes you made into // hbase) table.put(p); // Now, to retrieve the data we just wrote. The values that come back are // Result instances. Generally, a Result is an object that will package up // the hbase return into the form you find most palatable. Get g = new Get(Bytes.toBytes("myLittleRow")); Result r = table.get(g); byte [] value = r.getValue(Bytes.toBytes("myLittleFamily"), Bytes.toBytes("someQualifier")); // If we convert the value bytes, we should get back 'Some Value', the // value we inserted at this location. String valueStr = Bytes.toString(value); System.out.println("GET: " + valueStr); // Sometimes, you won't know the row you're looking for. In this case, you // use a Scanner. This will give you cursor-like interface to the contents // of the table. To set up a Scanner, do like you did above making a Put // and a Get, create a Scan. Adorn it with column names, etc. Scan s = new Scan(); s.addColumn(Bytes.toBytes("myLittleFamily"), Bytes.toBytes("someQualifier")); ResultScanner scanner = table.getScanner(s); try { // Scanners return Result instances. // Now, for the actual iteration. One way is to use a while loop like so: for (Result rr = scanner.next(); rr != null; rr = scanner.next()) { // print out the row we found and the columns we were looking for System.out.println("Found row: " + rr); } // The other approach is to use a foreach loop. Scanners are iterable! // for (Result rr : scanner) { // System.out.println("Found row: " + rr); // } } finally { // Make sure you close your scanners when you are done! // Thats why we have it inside a try/finally clause scanner.close(); } // Close your table and cluster connection. } finally { if (table != null) table.close(); } } finally { connection.close(); } } }
Thrift, REST and support for other programming languages.
To work from other programming languages, Hbase provides the Thrift API and Rest API. Based on them, clients for all major programming languages are built: python, PHP, Java Script, and so on.
Some features of working with HBase
1. Hbase out of the box is integrated with MapReduce, and can be used as input and output data with the help of special TableInputFormat and TableOutputFormat.
2. It is very important to choose the right RowKey. RowKey should provide a good even distribution across regions, otherwise there is a risk of so-called “hot regions” - regions that are used much more often than others, which leads to inefficient use of system resources.
3. If data is not uploaded singlely, but immediately in large batches - Hbase supports a special BulkLoad mechanism that allows you to fill in data much faster than using single Put'y. BulkLoad is essentially a two-step operation:
- Formation of HFile without the participation of put'ov using a special MapReduce job'a
- Putting these files directly in Hbase.
4. Hbase supports the output of its metrics to the monitoring server Ganglia. This can be very useful when administering Hbase to understand the nature of the problems with hbase.
Example
As an example, we can consider the main data table that we use in Data-Centric Aliance to store information about user behavior on the Internet.
Rowkey
As the RowKey, the user ID is used, which is the GUUID, a string specially generated to be unique throughout the world. GUUIDs are evenly distributed, which gives a good distribution of data across servers.
Column family
Our repository uses two column families:
- Data. This column group stores data that is no longer relevant for advertising purposes, such as the fact that a user visits a specific URL. The TTL for this Column Family is set at 2 months, the limit on the number of versions is 2000.
- LongData. This column group stores data that does not lose its relevance for a long time, such as gender, date of birth, and other “eternal” user characteristics.
Columns
Each type of user fact is stored in a separate column. For example, in the Data: _v column, the URLs visited by the user are stored, and in the LongData: gender column — the gender of the user.
The timestamp of the registration of this fact is stored as the timestamp. For example, in the Data column: _v - as the timestamp, the time the user uses to access a specific URL is used.
This user data storage structure fits our usage pattern very well and allows you to quickly update user data, quickly retrieve all the necessary information about users, and, using MapReduce, quickly process data about all users at once.
Alternatives
Hbase is quite complicated to administer and use, so before using hbase it makes sense to pay attention to alternatives:
- Relational databases. Very good alternative, especially in the case when the data fit on one machine. Also, first of all, relational databases should be considered in the case when transaction indices other than the primary one are important.
- Key-Value Storage. Repositories such as Redis and Aerospike are better suited when minimizing latency is needed and batch processing is less important.
- Files and their processing using MapReduce. If the data is only added, and rarely updated / changed, then it is better not to use Hbase, but simply to store the data in files. To simplify work with files, you can use tools such as Hive, Pig and Impala, which will be discussed in the following articles.
Hbase checklist
Using Hbase is justified when:
- There is a lot of data and they do not fit on one computer
- Data is frequently updated and deleted.
- In the data there is an obvious "key" for which it is convenient to tie everything else
- Need batch processing
- We need random access to data on certain keys
Conclusion
In this article, we looked at Hbase - a powerful tool for storing and updating data in the hadoop ecosystem; we showed the Hbase data model, its architecture, and the peculiarities of working with it.
The following articles will discuss tools that simplify working with MapReduce, such as Apache Hive and Apache Pig.



Comments
To leave a comment
Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL
Terms: Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL