Approaches to processing big data in QlikView
QlikView Large Data Sets - This article describes the main approaches to handling big data in a QlikView application (this article does not apply to Big Data). This article describes only three main approaches. There are other approaches, but they will be discussed later. Qlik can handle very large data sets. However, to optimize the user experience and use the equipment resources that are required for QlikView, you can perform several job options.
Suppose you have a large data set of orders in the amount of 1 billion lines. You need to provide high-level indicators for senior management, develop trend analysis tools for business analysts, and provide detailed information for employees who process operational order information. There are several approaches to displaying data. Consider three approaches.
Only a detailed fact table
Using only a detailed fact table allows QlikView to do all the work in order to display detailed information and totals from the lowest level of detail to the highly aggregated level. The advantages are simplicity. This is the easiest solution to implement code. You simply connect to the lowest level of the Orders table (possibly at the SKU level) in the data model, and then design all high-level metrics, trend charts, and detailed tables, and set up samples (filters) in a QVW document. Disadvantages - QlikView will need to aggregate 1 billion lines of detailed information with each click on the filters. QlikView can do this, but application performance will not be very good, and the required resources will be significant.
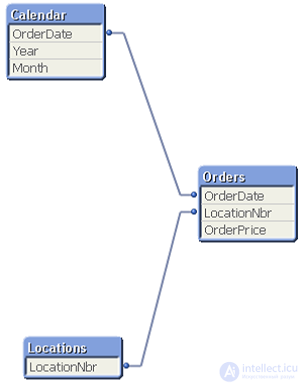

QlikView Document Chaining - what is it?
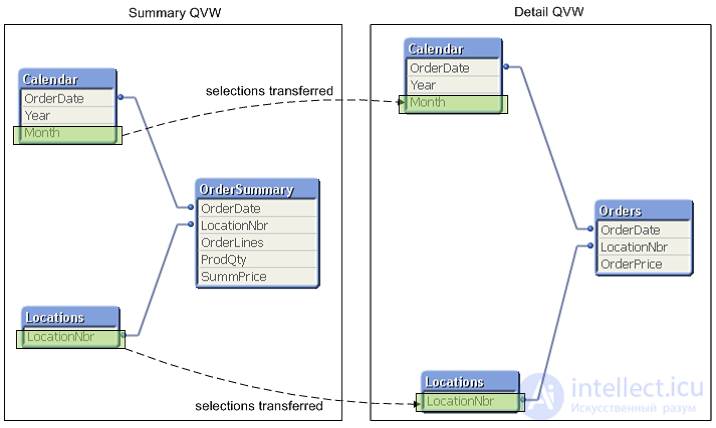
Document Chaining ( document chaining method) is an approach to building the interaction of two QVW documents. The first document has the Orders table with detailed data (this is the main fact table), another document has a pre-aggregated Orders table (the fact table for the second document). Suppose we have only two of these QVW documents. Below is a diagram that shows the data model from “Summary QVW” and the data model from “Detail QVW”. Note that the measurement values are the same in these two models. The main difference between documents is in the fact table. Users can start working with an aggregated document that shows high-level information.
If users want to “drill through” into detailed data , you can use the Document Chaining approach in QlikView to move samples (filters) from one QVW document to another QVW document, and then open the second document. The user will see the new charts, tabs, and he will not need to know how the filters move from one QVW document to another. This means that you will use a fact table with 1 billion rows when users need it. The rest of the data processing work will be carried out on a pre-aggregated version of the order table, which may be significantly less than 100 million lines. Document Chaining is described in detail in the QlikView Reference Manual and in a number of other QlikView documents.
Advantages - this approach optimizes the use of hardware resources and the speed of response to user requests for navigation and QlikView diagrams. Because user and navigation samples are provided for specific needs, you do not need to waste processor and RAM resources to continuously process 1 billion lines of detailed data when the user does not need it.
Disadvantages - tables (QVDs) need to be pre-aggregated and provide maintenance for this approach. This approach is much more complicated than developing an application with a single fact table Orders.
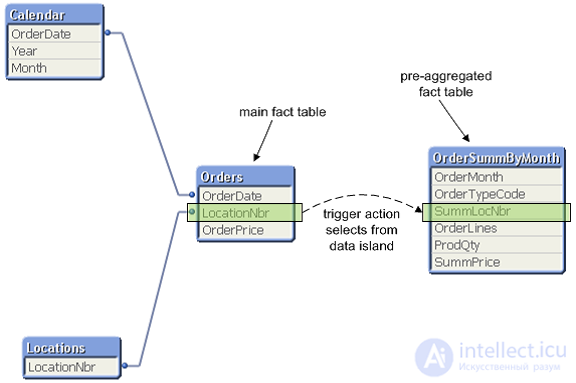
Triggered Action - Table Interrelationship via Triggers
The “Triggered Action” approach is to use a pre-aggregated summary table in addition to a detailed table in one data model of a QVW document. The diagram below shows one way to use pre-aggregated information in the same data model (next to a detailed table). A pre-aggregated table is loaded into the data model as a data island (this table does not have relationships with other data model tables). Then, the corresponding samples in the detailed fact table are transferred to the pre-aggregated fact table with triggers (Triggers Action).
Advantages - this option does not require a second QVW document and does not require document chaining in order to use both versions (detailed and total) of a large data table.
Disadvantages - this option will require some settings in QVW to trigger actions that will pass samples from one table to another. Since the QVW document changes over time, you have to keep track of where and when trigger actions should be sent.
Please note: There are even more options with which you can meet these needs described in this article. These are just 3 methods that demonstrate the features and capabilities of QlikView for managing very large data sets.
Key factors that influence the model:
- Unique data columns;
- Unique entries in the key fields.
Both of the latter methods can affect the memory size in the data model and the use of applications by users.

Comments
To leave a comment
Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL
Terms: Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL