Lecture
From time to time, the developer needs to pass a set of parameters to the request or even a whole selection of “input”. Very strange solutions to this problem sometimes come across.
Let’s go “from the opposite” and see how it’s not worth doing, why, and how you can do better.
It usually looks something like this:
query = "SELECT * FROM tbl WHERE id = " + value
... or so:
query = "SELECT * FROM tbl WHERE id = :param".format(param=value)
About this method it has been said, written and even drawn abundantly:
Almost always, it is a direct path to SQL injections and an extra load on business logic, which is forced to “glue” your query string.
Such an approach can be partially justified only if it is necessary to use sectioning in versions of PostgreSQL 10 and lower to obtain a more efficient plan. In these versions, the list of scanned sections is determined even without taking into account the transmitted parameters, only on the basis of the request body.
Using parameter placeholders is good, it allows you to use PREPARED STATEMENTS , reducing the load on both business logic (a query string is generated and transmitted only once) and the database server (no repeated parsing and scheduling for each request instance).
Variable number of arguments
Problems will wait for us when we want to pass in advance an unknown number of arguments:
... id IN ($1, $2, $3, ...) -- $1 : 2, $2 : 3, $3 : 5, ...
If you leave the request in this form, then although it will save us from potential injections, it will nevertheless lead to the need for gluing / parsing the request for each option from the number of arguments . Already better than doing it every time, but you can do without it.
It is enough to pass only one parameter containing the serialized representation of the array :
... id = ANY($1::integer[]) -- $1 : '{2,3,5,8,13}'
The only difference is the need to explicitly convert the argument to the desired array type. But this does not cause problems, since we already know in advance where we are addressing.
Sample transfer (matrices)
Usually these are all sorts of options for transferring data sets for insertion into the database “in one request”:
INSERT INTO tbl(k, v) VALUES($1,$2),($3,$4),...
In addition to the problems described above with the “re-sticking” of the request, this can also lead to out of memory and server crash. The reason is simple - for arguments, PG reserves additional memory, and the number of records in the set is limited only by the applied Wishlist business logic. In especially clinical cases, one had to see "numbered" arguments greater than $ 9,000 - no need to.
We rewrite the request, applying the “two-level” serialization :
INSERT INTO tbl
SELECT
unnest[1]::text k
, unnest[2]::integer v
FROM (
SELECT
unnest($1::text[])::text[] -- $1 : '{"{a,1}","{b,2}","{c,3}","{d,4}"}'
) T;
Yes, in the case of "complex" values inside the array, they need to be enclosed in quotation marks.
It is clear that in this way you can "expand" the selection with an arbitrary number of fields.
unnest, unnest, ...
Periodically, there are transmission options instead of an “array of arrays” of several “column arrays”, which I mentioned in a previous article :
SELECT unnest($1::text[]) k , unnest($2::integer[]) v;
With this method, making a mistake when generating lists of values for different columns, it is very simple to get completely unexpected results , which also depend on the version of the server:
-- $1 : '{a,b,c}', $2 : '{1,2}'
-- PostgreSQL 9.4
k | v
-----
a | 1
b | 2
c | 1
a | 2
b | 1
c | 2
-- PostgreSQL 11
k | v
-----
a | 1
b | 2
c |
Starting with version 9.3, PostgreSQL introduced full-fledged functions for working with the json type. Therefore, if the definition of input parameters in your browser takes place, you can create a json object for the SQL query right there :
SELECT
key k
, value v
FROM
json_each($1::json); -- '{"a":1,"b":2,"c":3,"d":4}'
For previous versions, the same method can be used for each (hstore) , but the correct "convolution" with escaping complex objects in hstore can cause problems.
json_populate_recordset
If you know in advance that the data from the “input” json array will go to fill some kind of table, you can save a lot in “dereferencing” the fields and casting to the necessary types using the json_populate_recordset function:
SELECT
*
FROM
json_populate_recordset(
NULL::pg_class
, $1::json -- $1 : '[{"relname":"pg_class","oid":1262},{"relname":"pg_namespace","oid":2615}]'
);
json_to_recordset
And this function simply “expands” the transferred array of objects into the selection, without relying on the table format:
SELECT
*
FROM
json_to_recordset($1::json) T(k text, v integer);
-- $1 : '[{"k":"a","v":1},{"k":"b","v":2}]'
k | v
-----
a | 1
b | 2
But if the amount of data in the transmitted sample is very large, then throwing it into one serialized parameter is difficult, and sometimes impossible, because it requires a one-time allocation of a large amount of memory . For example, you need to collect a large packet of data on events from an external system for a long, long time, and then you want to process it once on the database side.
In this case, the best solution would be to use temporary tables :
CREATE TEMPORARY TABLE tbl(k text, v integer); ... INSERT INTO tbl(k, v) VALUES($1, $2); -- повторить много-много раз ... -- тут делаем что-то полезное со всей этой таблицей целиком
The method is good for rare transmission of large amounts of data.
From the point of view of describing the structure of its data, the temporary table differs from the “usual” one only by one feature in the pg_class system table , and in pg_type, pg_depend, pg_attribute, pg_attrdef, ... - nothing at all.
Therefore, in web-systems with a large number of short-lived connections for each of them, such a table will generate new system records each time, which are deleted with the connection to the database closed. As a result, the uncontrolled use of TEMP TABLE leads to the "swelling" of tables in pg_catalog and slows down many operations that use them.
Of course, this can be fought withperiodically pass VACUUM FULL through the system catalog tables.
Suppose the processing of data from the previous case is quite complicated for a single SQL query, but you want to do it often enough. That is, we want to use procedural processing in the DO-block , but using data transfer through temporary tables will be too expensive.
We will not be able to use $ n-parameters for transfer to the anonymous block either. The session variables and the current_setting function will help us to get out of this situation .
Prior to version 9.2, you had to preconfigure a custom_variable_classes namespace for “your” session variables. On current versions, you can write something like this:
SET my.val = '{1,2,3}';
DO $$
DECLARE
id integer;
BEGIN
FOR id IN (SELECT unnest(current_setting('my.val')::integer[])) LOOP
RAISE NOTICE 'id : %', id;
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- NOTICE: id : 1
-- NOTICE: id : 2
-- NOTICE: id : 3
Other supported procedural languages can find other solutions.
Today there will be no complicated cases and sophisticated SQL algorithms. Everything will be very simple, at Captain's level. Obviousness - we do a review of the event register with sorting by time.
That is, there is a plate in the database events, and its field tsis exactly the same time by which we want to display these records in an orderly manner:
CREATE TABLE events(
id
serial
PRIMARY KEY
, ts
timestamp
, data
json
);
CREATE INDEX ON events(ts DESC);
It is clear that we will have not a dozen entries there, so we will need some kind of page navigation .
cur.execute("SELECT * FROM events;")
rows = cur.fetchall();
rows.sort(key=lambda row: row.ts, reverse=True);
limit = 26
print(rows[offset:offset+limit]);
It’s almost no joke - rarely, but found in the wild. Sometimes after working with ORM it can be difficult to switch to a “direct” work with SQL.
But let's move on to more common and less obvious problems.
SELECT ... FROM events ORDER BY ts DESC LIMIT 26 OFFSET $1; -- 26 - записей на странице, $1 - начало страницы
Where did the number 26 come from? This is the approximate number of entries to fill one screen. More precisely, 25 displayed records, plus 1, indicating that there is at least something else in the sample and it makes sense to move on.
Of course, this value can not be “sewn” into the request body, but passed through a parameter. But in this case, the PostgreSQL scheduler will not be able to rely on the knowledge that there should be relatively few records - and it will easily choose an ineffective plan.
And while viewing the registry in the application’s interface is implemented as switching between visual “pages”, nobody for a long time notices anything suspicious. Exactly until the moment when, in the struggle for convenience, UI / UX does not decide to remake the interface to “endless scroll” - that is, all registry entries are drawn in a single list that the user can twist up and down.
And now, during the next test, you are caught duplicating registry entries . Why, because the table has a normal index (ts)on which your query is based?
Exactly because you did not consider what is tsnot a unique key in this table. Actually, his meanings are not unique, like any “time” in real conditions - that’s why the same record in two neighboring queries easily “jumps” from page to page due to a different final order within the framework of sorting the same key value.
In fact, the second problem is also hidden here, which is much more difficult to notice - some entries will not be shown at all! After all, "duplicated" records took someone's place. A detailed explanation with beautiful pictures can be found here .
Expanding the Index
The cunning developer understands that you need to make the index key unique, and the easiest way is to expand it with a deliberately unique field, which PK is perfect for:
CREATE UNIQUE INDEX ON events(ts DESC, id DESC);
And the request mutates:
SELECT ... ORDER BY ts DESC, id DESC LIMIT 26 OFFSET $1;
Some time later, the DBA comes to you and is “happy” that your requests are hellishly loading the server with their horse OFFSETs , and in general, it is time to switch to navigation from the last value shown . Your request mutates again:
SELECT ... WHERE (ts, id) < ($1, $2) -- последние полученные на предыдущем шаге значения ORDER BY ts DESC, id DESC LIMIT 26;
You breathed a sigh of relief before it came ...
Because one day your DBA read an article about finding inefficient indexes and realized that the “last but not the least” timestamp is not good . And he came to you again - now with the thought that this index should nevertheless turn back into (ts DESC).
But what to do with the initial problem of “jumping” records between pages? .. And everything is simple - you need to choose blocks with an unlimited number of records!
In general, who forbids us to read not “exactly 26”, but “not less than 26”? For example, so that in the next block there are records with obviously different valuests - then there will be no problems with “jumping” between the blocks!
Here's how to achieve this:
SELECT
...
WHERE
ts < $1 AND
ts >= coalesce((
SELECT
ts
FROM
events
WHERE
ts < $1
ORDER BY
ts DESC
LIMIT 1 OFFSET 25
), '-infinity')
ORDER BY
ts DESC;
What is going on here?
Or the same picture:
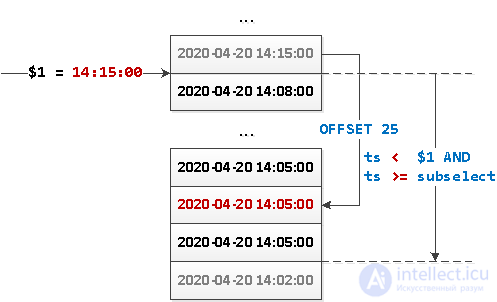
Since now our sample does not have any definite “beginning” , nothing prevents us from “reversing” this query in the opposite direction and implementing dynamic loading of data blocks from the “reference point” in both directions - both down and up.
Comment
SQL is not C ++, nor JavaScript. Therefore, the calculation of logical expressions is different, and this is not the same thing:
WHERE fncondX() AND fncondY()
= fncondX() && fncondY()
In the process of optimizing the query execution plan, PostgreSQL can arbitrarily “rearrange” the equivalent conditions , not calculate any of them for individual records, assign them to the condition of the applicable index ... In short, it’s easiest to assume that you cannot control in what order equal conditions will be calculated (and whether at all) .
Therefore, if you still want to control the priority, you need to structurally make these conditions unequal using conditional expressions and operators .
Data and working with them is the basis of our VLSI complex , so it is very important for us that operations on them are performed not only correctly, but also efficiently. Let's look at specific examples where expression errors can be made, and where it is worth improving their effectiveness.
Starting example from the documentation :
When the calculation order is important, it can be fixed using the construction CASE. For example, such a way to avoid dividing by zero in a sentence is WHEREunreliable:SELECT ... WHERE x > 0 AND y/x > 1.5;
Safe option:SELECT ... WHERE CASE WHEN x > 0 THEN y/x > 1.5 ELSE false END;
The construction used in this way CASEprotects the expression from optimization, therefore it should only be used if necessary.
BEGIN
IF cond(NEW.fld) AND EXISTS(SELECT ...) THEN
...
END IF;
RETURN NEW;
END;
It seems that everything looks good, but ... No one promises that the enclosed SELECTwill not be executed if the first condition is false. Correct using nestedIF :
BEGIN
IF cond(NEW.fld) THEN
IF EXISTS(SELECT ...) THEN
...
END IF;
END IF;
RETURN NEW;
END;
Now let's look carefully - the whole body of the trigger function turned out to be “wrapped” in IF. And this means that nothing prevents us from removing this condition from the procedure using the WHEN-condition :
BEGIN
IF EXISTS(SELECT ...) THEN
...
END IF;
RETURN NEW;
END;
...
CREATE TRIGGER ...
WHEN cond(NEW.fld);
This approach allows guaranteed saving of server resources under false conditions.
SELECT ... WHERE EXISTS(... A) OR EXISTS(... B)
Otherwise, you can get that both EXISTSwill be "true", but both will be fulfilled .
But if we know for sure that one of them is “true” much more often (or “false” for the ANDchain), is it possible to somehow “increase its priority” so that the second is not performed once again?
It turns out that it is possible - the algorithm approach is close to the topic of the PostgreSQL Antipatterns article : a rare record will reach the middle of the JOIN .
Let's just put both of these conditions under CASE:
SELECT ...
WHERE
CASE
WHEN EXISTS(... A) THEN TRUE
WHEN EXISTS(... B) THEN TRUE
END
In this case, we did not determine the ELSE-value, that is, if both conditions are false , it CASEwill return NULL, which is interpreted as FALSEin the WHERE-condition.
This example can be combined in another way - to taste and color:
SELECT ...
WHERE
CASE
WHEN NOT EXISTS(... A) THEN EXISTS(... B)
ELSE TRUE
END
We spent two days analyzing the reasons for the “strange” trigger of this trigger — let's see why.
Source:
IF( NEW."Документ_" is null or NEW."Документ_" = (select '"Комплект"'::regclass::oid) or NEW."Документ_" = (select to_regclass('"ДокументПоЗарплате"')::oid)
AND ( OLD."ДокументНашаОрганизация" <> NEW."ДокументНашаОрганизация"
OR OLD."Удален" <> NEW."Удален"
OR OLD."Дата" <> NEW."Дата"
OR OLD."Время" <> NEW."Время"
OR OLD."ЛицоСоздал" <> NEW."ЛицоСоздал" ) ) THEN ...
Problem # 1: Inequality Does Not Consider NULL
Imagine that all OLD-fields matter NULL. What will happen?
SELECT NULL <> 1 OR NULL <> 2; -- NULL
And from the point of view of working out the conditions is NULLequivalent FALSE, as mentioned above.
Solution : use the operator IS DISTINCT FROMfrom the ROW-operator, comparing whole records at once:
SELECT (NULL, NULL) IS DISTINCT FROM (1, 2); -- TRUE
Problem number 2: different implementation of the same functionality
Compare:
NEW."Документ_" = (select '"Комплект"'::regclass::oid)
NEW."Документ_" = (select to_regclass('"ДокументПоЗарплате"')::oid)
Why are there extra nesting SELECT? What about the function to_regclass? And in different ways, why? ..
Fix:
NEW."Документ_" = '"Комплект"'::regclass::oid NEW."Документ_" = '"ДокументПоЗарплате"'::regclass::oid
Problem # 3: bool operations priority
Format the source:
{... IS NULL} OR
{... Комплект} OR
{... ДокументПоЗарплате} AND
( {... неравенства} )
Oops ... In fact, it turned out that in the case of the truth of any of the first two conditions, the whole condition turns into TRUE, without taking into account inequalities. And this is not at all what we wanted.
Fix:
(
{... IS NULL} OR
{... Комплект} OR
{... ДокументПоЗарплате}
) AND
( {... неравенства} )
Problem 4 (small): complex OR condition for one field
Actually, problems in No. 3 arose precisely because there were three conditions. But instead of them, you can do one, using the mechanism coalesce ... IN:
coalesce(NEW."Документ_"::text, '') IN ('', '"Комплект"', '"ДокументПоЗарплате"')
So we NULL“catch”, and complex ORwith brackets do not have to fence.
Total
We fix what we got:
IF (
coalesce(NEW."Документ_"::text, '') IN ('', '"Комплект"', '"ДокументПоЗарплате"') AND
(
OLD."ДокументНашаОрганизация"
, OLD."Удален"
, OLD."Дата"
, OLD."Время"
, OLD."ЛицоСоздал"
) IS DISTINCT FROM (
NEW."ДокументНашаОрганизация"
, NEW."Удален"
, NEW."Дата"
, NEW."Время"
, NEW."ЛицоСоздал"
)
) THEN ...
And if we take into account that this trigger function can be used only in the UPDATE-trigger due to the presence of OLD/NEWa top level in the condition, then this condition can generally be put into the WHEN-condition, as was shown in # 1 ...

Comments