In the previous article, we looked at the MapReduce parallel computing paradigm. In this article, we will move from theory to practice and consider Hadoop, the powerful tool for working with big data from the Apache foundation.
The article describes what tools and tools Hadoop includes, how to install Hadoop in yourself, provides instructions and examples for developing MapReduce-programs for Hadoop.

General information about Hadoop
As you know, the MapReduce paradigm was proposed by Google in its 2004 MapReduce article: Simplified Data Processing on Large Clusters. Since the proposed article contained a description of the paradigm, but the implementation was absent - several programmers from Yahoo offered their implementation as part of the work on the web-crawler nutch. You can read more about Hadoop history in The history of Hadoop article: From 4 nodes to the future of data
Initially, Hadoop was, first of all, a tool for storing data and running MapReduce-tasks, but now Hadoop is a large stack of technologies that are somehow related to processing big data (not only using MapReduce).
The core (core) components of Hadoop are:
- Hadoop Distributed File System (HDFS) is a distributed file system that allows you to store information of almost unlimited size.
- Hadoop YARN is a framework for managing cluster resources and task management, including the MapReduce framework.
- Hadoop common
There are also a large number of projects directly related to Hadoop, but not included in the Hadoop core:
- Hive is a tool for SQL-like queries on large data (turns SQL queries into a series of MapReduce – tasks);
- Pig is a high-level data analysis programming language. One line of code in this language can turn into a sequence of MapReduce-tasks;
- Hbase - column database that implements the BigTable paradigm;
- Cassandra - high-performance distributed key-value database;
- ZooKeeper is a service for distributed configuration storage and synchronization of changes to this configuration;
- Mahout is a library and machine for learning big data.
Separately, I would like to mention the Apache Spark project, which is a distributed data processing engine. Apache Spark usually uses Hadoop components such as HDFS and YARN for its work, while it has recently become more popular than Hadoop:
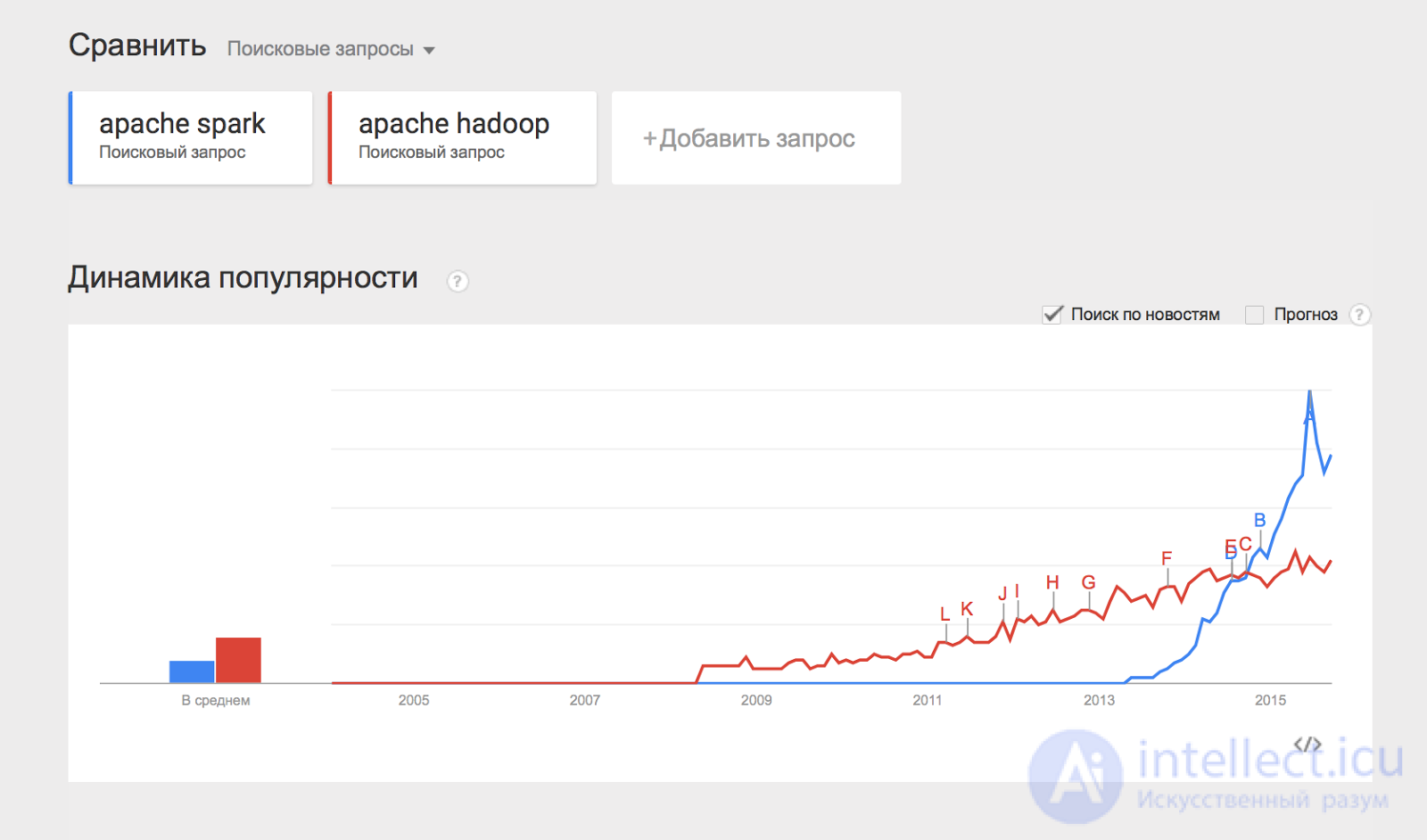
Some of the listed components will be devoted to individual articles in this series of materials, but for now let's analyze how you can start working with Hadoop and apply it in practice.
Installing Hadoop on a cluster using Cloudera Manager
Previously, the installation of Hadoop was a rather difficult exercise — you had to individually configure each machine in the cluster, make sure that nothing was forgotten, and carefully set up monitoring. With the growing popularity of Hadoop, companies have emerged (such as Cloudera, Hortonworks, MapR), which provide their own Hadoop assemblies and powerful tools for managing the Hadoop cluster. In our series of materials, we will use the Hadoop assembly from Cloudera.
In order to install Hadoop on your cluster, you need to do a few simple steps:
- Download Cloudera Manager Express to one of your cluster machines from here;
- Assign rights to execute and run;
- Follow the installation instructions.
The cluster should work on one of the supported operating systems of the linux family: RHEL, Oracle Enterprise linux, SLES, Debian, Ubuntu.
After installation, you will receive a cluster management console, where you can view installed services, add / remove services, monitor the cluster status, edit the cluster configuration:
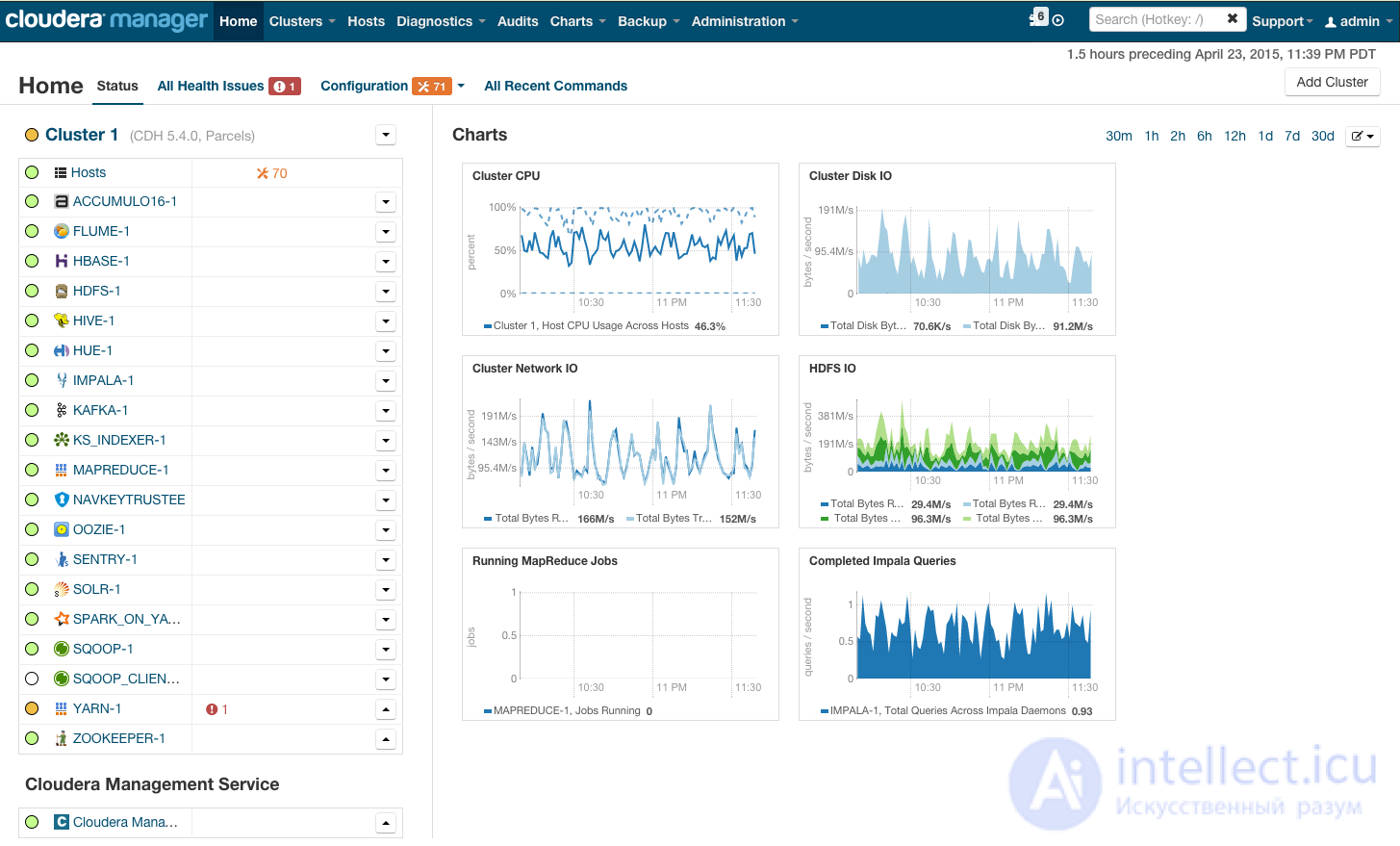
For more information on installing Hadoop on a cluster using the cloudera manager, see the link in the Quick Start section.
If you plan to use Hadoop to "try" - you can not bother with purchasing expensive hardware and setting up Hadoop on it, but simply download the pre-configured virtual machine from the link and use the configured hadoop.
Running MapReduce programs on Hadoop
Now we will show how to run the MapReduce task on Hadoop. As a task, we will use the classic WordCount example, which was analyzed in the previous article of the cycle. In order to experiment on real data, I prepared an archive of random news from the site lenta.ru. Download the archive by the link.
Let me remind the wording of the problem: there is a set of documents. It is necessary for each word found in a set of documents to count how many times a word occurs in a set.
Decision:
Map breaks a document into words and returns a set of pairs (word, 1).
Reduce summarizes the occurrences of each word:
def map(doc): for word in doc.split(): yield word, 1
|
def reduce(word, values): yield word, sum(values)
|
Now the task is to program this solution in the form of code that can be executed on Hadoop and run.
Method number 1. Hadoop streaming
The easiest way to run a Hadoop MapReduce program is to use the Hadoop streaming interface. The streaming interface assumes that map and reduce are implemented as programs that accept data from stdin and return the result to stdout.
The program that performs the map function is called mapper. A program that performs reduce is called a reducer, respectively.
The streaming interface assumes, by default, that one incoming line in a mapper or reducer corresponds to one incoming record for a map.
The mapper output goes to the input of the reducer in the form of pairs (key, value), with all the pairs corresponding to the same key:
- Guaranteed to be processed by a single launch of a reducer;
- They will be served at the entrance in a row (that is, if one reducer processes several different keys, the input will be grouped by key).
So, we implement mapper and reducer in python:
#mapper.py import sys def do_map(doc): for word in doc.split(): yield word.lower(), 1 for line in sys.stdin: for key, value in do_map(line): print(key + "\t" + str(value))
#reducer.py import sys def do_reduce(word, values): return word, sum(values) prev_key = None values = [] for line in sys.stdin: key, value = line.split("\t") if key != prev_key and prev_key is not None: result_key, result_value = do_reduce(prev_key, values) print(result_key + "\t" + str(result_value)) values = [] prev_key = key values.append(int(value)) if prev_key is not None: result_key, result_value = do_reduce(prev_key, values) print(result_key + "\t" + str(result_value))
The data that Hadoop will process must be stored on HDFS. Download our articles and put on HDFS. To do this, use the hadoop fs command:
wget https://www.dropbox.com/s/opp5psid1x3jt41/lenta_articles.tar.gz tar xzvf lenta_articles.tar.gz hadoop fs -put lenta_articles
The hadoop fs utility supports a large number of methods for manipulating the file system, many of which repeat the standard linux utilities one-on-one. More information about its capabilities can be found at the link.
Now run the streaming task:
yarn jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar\ -input lenta_articles\ -output lenta_wordcount\ -file mapper.py\ -file reducer.py\ -mapper "python mapper.py"\ -reducer "python reducer.py"
The yarn utility is used to launch and manage various applications (including map-reduce based) on a cluster. Hadoop-streaming.jar is just one example of such a yarn application.
Next are the launch options:
- input - source data folder in hdfs;
- output - folder on hdfs, where you need to put the result;
- file - files that are needed during the work of map-reduce tasks;
- mapper is a console command that will be used for the map stage;
- reduce - the console command to be used for the reduce-stage.
After running in the console, you will see the progress of the task and the URL to view more detailed information about the task.
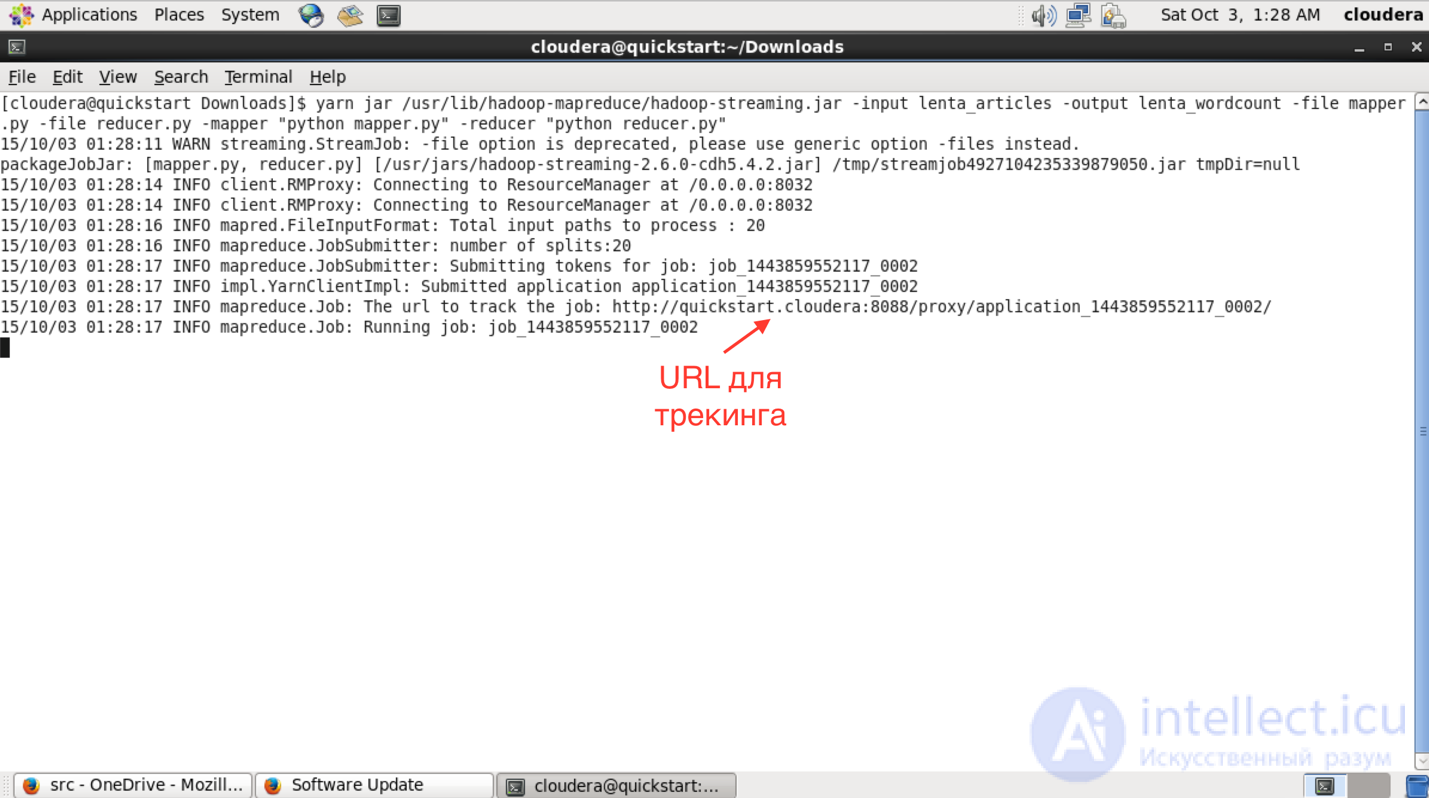
In the interface available at this URL, you can find out more detailed status of the task, see the logs of each mapper and reducer (which is very useful in case of dropped tasks).
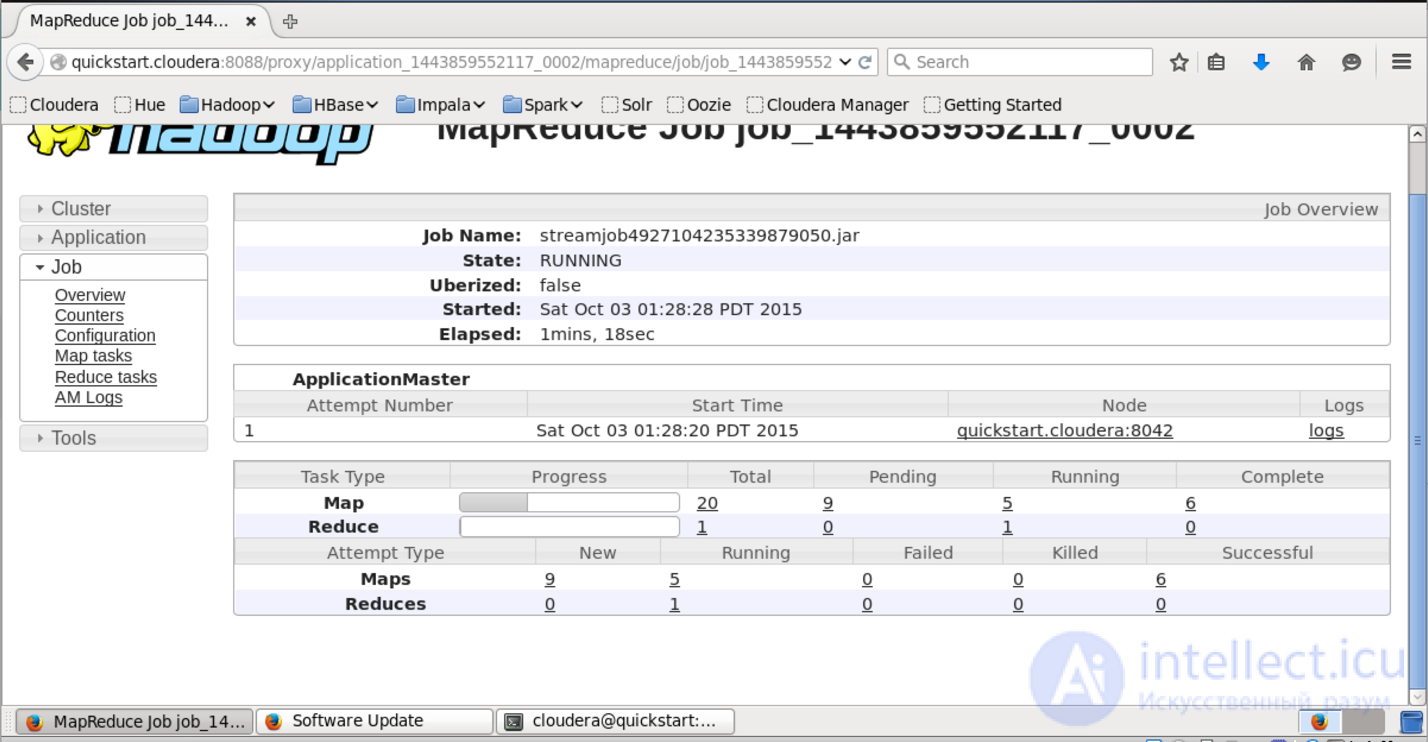
The result of the work after successful execution is added to HDFS in the folder that we specified in the output field. You can view its contents using the “hadoop fs -ls lenta_wordcount” command.
The result itself can be obtained as follows:
hadoop fs -text lenta_wordcount/* | sort -n -k2,2 | tail -n5 с 41 что 43 на 82 и 111 в 194
The "hadoop fs -text" command displays the contents of the folder in text form. I sorted the result by the number of occurrences of words. As expected, the most frequent words in the language are prepositions.
Method number 2
By itself, hadoop was written in java, and hadoop's native interface is also java-based. Let's show how the native java application for wordcount looks like:
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper extends Mapper{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path("hdfs://localhost/user/cloudera/lenta_articles")); FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost/user/cloudera/lenta_wordcount")); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
This class does exactly the same thing as our Python example. We create the TokenizerMapper and IntSumReducer classes, inheriting them from the Mapper and Reducer classes, respectively. Classes that are passed as template parameters indicate the types of input and output values. The native API implies that the key functions are supplied to the map functions. Since in our case the key is empty, we simply define Object as the key type.
In the Main method, we start the mapreduce task and define its parameters - the name, mapper and reducer, the path in HDFS, where the input data are and where to put the result.
For compilation we will need hadoop libraries. I use to build Maven, for which cloudera has a repository. Instructions for setting it up can be found at the link. As a result, the pom.xmp file (which is used by maven to describe the project build) I got the following):
4.0.0 cloudera https://repository.cloudera.com/artifactory/cloudera-repos/ org.apache.hadoop hadoop-common 2.6.0-cdh5.4.2 org.apache.hadoop hadoop-auth 2.6.0-cdh5.4.2 org.apache.hadoop hadoop-hdfs 2.6.0-cdh5.4.2 org.apache.hadoop hadoop-mapreduce-client-app 2.6.0-cdh5.4.2 org.dca.examples wordcount 1.0-SNAPSHOT
Let's assemble the project in jar-package:
mvn clean package
After building the project into a jar file, the launch takes place in a similar way, as in the case of the streaming interface:
yarn jar wordcount-1.0-SNAPSHOT.jar WordCount
We wait for execution and check the result:
hadoop fs -text lenta_wordcount/* | sort -n -k2,2 | tail -n5 с 41 что 43 на 82 и 111 в 194
As you might guess, the result of executing our native application is the same as the result of the streaming application that we launched in the previous way.
Summary
In this article, we looked at Hadoop, a software stack for working with big data, described the installation process for Hadoop using the example of the cloudera distribution, showed how to write mapreduce programs using the streaming interface and the Hadoop native API.
In the next articles of the series, we will take a closer look at the architecture of the individual components of Hadoop and Hadoop-related software, show more complex versions of MapReduce programs, analyze ways to simplify working with MapReduce, as well as the limitations of MapReduce and how to circumvent these restrictions.
Thank you for your attention, we are ready to answer your questions.
Links to other articles of the cycle:
Part 1: Principles of working with big data, the paradigm of MapReduce
Part 3: Techniques and strategies for developing MapReduce applications
Part 4: Hbase

Comments
To leave a comment
Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL
Terms: Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL