Lecture
Hi! We continue our series of articles on data analysis tools and methods. The following 2 articles in our series will be devoted to Hive, a tool for SQL lovers. In previous articles we looked at the MapReduce paradigm, and the techniques and strategies for working with it. Perhaps many readers some of the problem solving with MapReduce seemed somewhat cumbersome. Indeed, almost 50 years after the invention of SQL, it seems rather strange to write more than one line of code to solve problems like “count me the amount of transactions broken down by region”.
On the other hand, classical DBMS, such as Postgres, MySQL or Oracle, do not have such flexibility in scaling when processing large data arrays and, when reaching a larger volume, further support becomes a big headache.
Actually, Apache Hive was coined to combine these two advantages:
Under the cat, we will explain how this is achieved, how to start working with Hive, and what are the restrictions on its use.
Hive appeared in the depths of Facebook in 2007, and a year later, the hive sources were opened and brought under the control of the apache software foundation. Initially, hive was a set of scripts over hadoop streaming (see the 2nd article of our cycle), later it developed into a full-fledged framework for querying data over MapReduce.
The current version of apache hive (2.0) is an advanced framework that can work not only on top of the Map / Reduce framework, but also on top of Spark (about Spark, we will have separate articles in the cycle), as well as Apache Tez.
Apache hive is used in production by companies such as Facebook, Grooveshark, Last.Fm, and many others. We at Data-Centric alliance use HIve as the main repository of logs for our advertising platform.
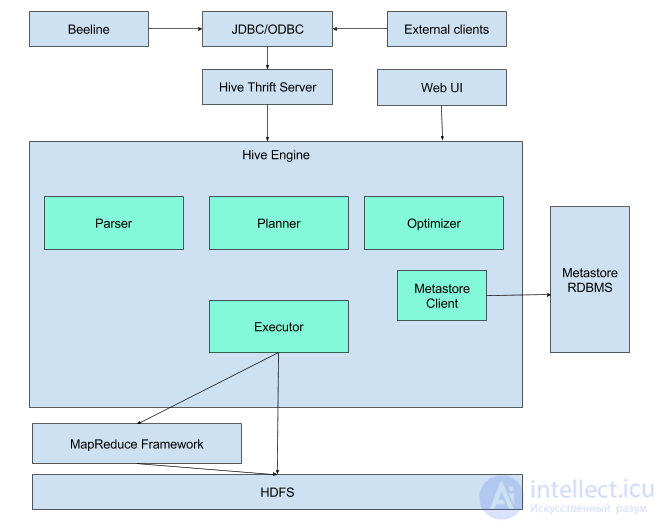
Hive is an engine that turns SQL queries into chains of map-reduce tasks. The engine includes components such as Parser (parses incoming SQL queries), Optimimer (optimizes the query for greater efficiency), Planner (schedules tasks for execution) Executor (runs tasks on the MapReduce framework.
Hive also requires a metadata repository. The fact is that SQL assumes work with such objects as a database, a table, columns, lines, cells, and so on. Since the data itself that is used by hive is simply stored as files in hdfs, it is necessary to store somewhere the correspondence between the hive objects and the actual files.
As metastorage, a regular relational DBMS is used, such as MySQL, PostgreSQL or Oracle.
In order to try working with hive, the easiest way is to use its command line. A modern utility for working with hive is called beeline (this is not a mobile operator). To do this, on any machine in the hadoop cluster (see our description hadoop
in the 2nd article of our cycle) with the hive installed, it’s enough to type a command.
$ beeline
Next, you need to establish a connection with the hive-server:
beeline>! connect jdbc: hive2: // localhost: 10000 / default root Connecting to jdbc: hive2: // localhost: 10000 / default Connected to: Apache Hive (version 1.1.0-cdh5.7.0) Driver: Hive JDBC (version 1.1.0-cdh5.7.0) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc: hive2: // localhost: 10000 / default>
root root is the username and password in this context. After that, you will receive a command prompt in which you can enter the commands hive.
Also, sometimes it is convenient not to enter sql queries in the beeline command line, but to save and edit them in a file, and then execute all the queries from the file. To do this, run beeline with the database connection parameters and the -f parameter indicating the name of the file containing the requests:
beeline -u jdbc: hive2: // localhost: 10000 / default -n root -p root -f sorted.sql
When working with hive, you can select the following objects with which hive operates:
Let us examine each of them in more detail:
The database represents an analogue of the database in relational DBMS. The database is a namespace containing tables. The command to create a new database looks like this:
CREATE DATABASE | SCHEMA [IF NOT EXISTS]
Database and Schema in this context is the same. The optional IF NOT EXISTS additive, as it is not difficult to guess, creates the database only if it does not already exist.
An example of creating a database:
CREATE DATABASE userdb;
To switch to the appropriate database, use the USE command:
USE userdb;
A table in hive is an analogue of a table in a classical relational database. The main difference - that the data hive'ovskih tables are kept simple in the form of regular files on hdfs. These can be plain text csv files, binary sequence files, more complex column paruqet files and other formats. But in any case, the data over which the hive table is configured is very easy to read and not from the hive.
Tables in hive are of two types:
A classic table, to which data is added using hive. Here is an example of creating such a table (source of example):
CREATE TABLE IF NOT EXISTS employee (eid int, name String, salary String, destination String) COMMENT 'Employee details' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\ t' LINES TERMINATED BY '\ n' STORED AS TEXTFILE;
Here we have created a table, the data in which will be stored in the form of ordinary csv-files, the columns of which are separated by tabs. After that, the data in the table can be downloaded. Let our user in the home folder on hdfs have (I remind you that you can upload the file using hadoop fs -put) sample.txt file of the form:
1201 Gopal 45000 Technical manager 1202 Manisha 45000 Proof reader 1203 Masthanvali 40000 Technical writer 1204 Kiran 40000 Hr Admin 1205 Kranthi 30000 Op Admin
We can upload data using the following command:
LOAD DATA INPATH '/user/root/sample.txt' OVERWRITE INTO TABLE employee;
After hive will move the data stored in our file to the hive storage. You can verify this by reading the data directly from the file in the hive repository in hdfs:
[root @ quickstart ~] # hadoop fs -text /user/hive/warehouse/userdb.db/employee/* 1201 Gopal 45000 Technical manager 1202 Manisha 45000 Proof reader 1203 Masthanvali 40000 Technical writer 1204 Kiran 40000 Hr Admin 1205 Kranthi 30000 Op Admin
Classic tables can also be created as a result of a select query to other tables:
0: jdbc: hive2: // localhost: 10000 / default> CREATE TABLE big_salary as SELECT * FROM employee WHERE salary> 40000; 0: jdbc: hive2: // localhost: 10000 / default> SELECT * FROM big_salary; + ----------------- + ------------------ + ------------ -------- + ------------------------- + - + | big_salary.eid | big_salary.name | big_salary.salary | big_salary.destination | + ----------------- + ------------------ + ------------ -------- + ------------------------- + - + | 1201 | Gopal | 45000 | Technical manager | | 1202 | Manisha | 45000 | Proof reader | + ----------------- + ------------------ + ------------ -------- + ------------------------- + - +
By the way, SELECT to create a table in this case already starts the mapreduce task.
External table, the data in which is loaded by external systems, without the participation of hive. To work with external tables when creating a table, you need to specify the EXTERNAL keyword, and also specify the path to the folder where the files are stored:
CREATE EXTERNAL TABLE IF NOT EXISTS employee_external (eid int, name String, salary String, destination String) COMMENT 'Employee details' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\ t' LINES TERMINATED BY '\ n' STORED AS TEXTFILE LOCATION '/ user / root / external_files /';
After that, the table can be used in the same way as regular hive tables. The most convenient thing about this is that you can simply copy the file to the correct daddy in hdfs, and hive will automatically pick up new files when querying the corresponding table. This is very convenient when working with logs for example.
Since hive is an engine for translating SQL queries into mapreduce tasks, usually even the simplest queries to the table lead to a complete scan of the data in this table. In order to avoid complete scanning of data on some of the columns of the table, it is possible to partition this table. This means that data relating to different values will be physically stored in different folders on HDFS.
To create a partitioned table, you must specify which columns will be used for partitioning:
CREATE TABLE IF NOT EXISTS employee_partitioned (eid int, name String, salary String, destination String) COMMENT 'Employee details' PARTITIONED BY (birth_year int, birth_month string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\ t' LINES TERMINATED BY '\ n' STORED AS TEXTFILE;
When pouring data into such a table, you must explicitly indicate in which partition we fill the data:
LOAD DATA INPATH '/user/root/sample.txt' OVERWRITE INTO TABLE employee_partitioned PARTITION (birth_year = 1998, birth_month = 'May');
Now let's see how the directory structure looks like:
[root @ quickstart ~] # hadoop fs -ls / user / hive / warehouse / employee_partitioned / Found 1 items drwxrwxrwx - root supergroup 0 2016-05-08 15:03 / user / hive / warehouse / employee_partitioned / birth_year = 1998 [root @ quickstart ~] # hadoop fs -ls -R / user / hive / warehouse / employee_partitioned / drwxrwxrwx - root supergroup 0 2016-05-08 15:03 / user / hive / warehouse / employee_partitioned / birth_year = 1998 drwxrwxrwx - root supergroup 0 2016-05-08 15:03 / user / hive / warehouse / employee_partitioned / birth_year = 1998 / birth_month = May -rwxrwxrwx 1 root supergroup 161 2016-05-08 15:03 /user/hive/warehouse/employee_partitioned/birth_year=1998/birth_month=May/sample.txt
It is seen that the directory structure looks like this, that each partition corresponds to a separate folder in hdfs. Now, if we run any queries, in WHERE clauses, the constraints on partition values - mapreduce will only take input data from the corresponding folders.
In the case of External tables, partitioning works in a similar way, but a similar directory structure will have to be created manually.
Partitioning is very convenient, for example, to separate logs by dates, as a rule, any requests for statistics contain a restriction on dates. This can significantly reduce the time of the request.
Partitioning helps to reduce processing time, if usually when queries are known restrictions on the values of a column. However, it is not always applicable. For example, if the number of values in a column is very large. For example, it can be a user ID in a system containing several million users.
In this case, the division of the table into buckets will help us. The rows of the table for which the value matches the hash function calculated by a specific column fall into one batch.
For any work with baketated tables, you must not forget to include support for buckets in the hive (otherwise, hive will work with them as with ordinary tables):
set hive.enforce.bucketing = true;
CLUSTERED BY is used to create a table broken into buckets.
set hive.enforce.bucketing = true; CREATE TABLE employee_bucketed (eid int, name String, salary String, destination String) CLUSTERED BY (eid) INTO 10 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY '\ t' LINES TERMINATED BY '\ n' STORED AS TEXTFILE;
Since the Load command is used to simply transfer data to the hive storage - in this case it is not suitable for loading, since the data must be preprocessed, properly breaking them into buckets. Therefore, they need to be loaded using the INSERT command from another table (for example, from an external table):
set hive.enforce.bucketing = true; FROM employee_external INSERT OVERWRITE TABLE employee_bucketed SELECT *;
After executing the command, make sure that the data is really broken into 10 parts:
[root @ quickstart ~] # hadoop fs -ls / user / hive / warehouse / employee_bucketed Found 10 items -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 / user / hive / warehouse / employee_bucketed / 000000_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 / user / hive / warehouse / employee_bucketed / 000001_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 / user / hive / warehouse / employee_bucketed / 000002_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 / user / hive / warehouse / employee_bucketed / 000003_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 / user / hive / warehouse / employee_bucketed / 000004_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 / user / hive / warehouse / employee_bucketed / 000005_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 / user / hive / warehouse / employee_bucketed / 000006_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 / user / hive / warehouse / employee_bucketed / 000007_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 / user / hive / warehouse / employee_bucketed / 000008_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 / user / hive / warehouse / employee_bucketed / 000009_0
Now, when querying for data related to a specific user, we will not need to scan the entire table, but only 1/10 of this table.
Now we have disassembled all the objects that hive operates on. Once the tables are created - you can work with them, since with the usual database tables. However, one should not forget that hive is still the engine for launching mapreduce tasks over regular files, and it is not a complete replacement for a classic DBMS. Reckless use of such heavy commands as a JOIN can lead to very long tasks. Therefore, before building your architecture based on hive, you need to think a few times. Here is a small checklist for using hive:
In this article, we sorted out the architecture of hive, the data units that operate on hive, and gave examples on how to create and populate hive tables. In the next article of the cycle, we will look at the advanced features of hive, including:
Links to previous articles in the cycle:
»Big Data from A to Z. Part 1: Principles of working with big data, the MapReduce paradigm
»Big Data from A to Z. Part 2: Hadoop
»Big Data from A to Z. Part 3: Techniques and strategies for developing MapReduce-applications
»Big Data from A to Z. Part 4: Hbase

Comments