Lecture
Synchronization (from other Greek σύγχρονος - simultaneous) in computer science means one of two things: synchronization of processes , or synchronization of data .
Synchronization of processes - bringing of two or several processes to such their occurrence, when certain stages of different processes are performed in a certain order, or simultaneously.
Synchronization is necessary in all cases when parallel processes are necessary to interact. For its organization, interprocess communication tools are used. Among the most commonly used tools are signals and messages, semaphores and mutexes, pipes (English pipe ), shared memory.
Data synchronization - eliminating the differences between two copies of data. It is assumed that previously these copies were the same, and then one of them, or both, were independently modified.
The way data is synchronized depends on additional assumptions being made. The main problem here is that independently made changes may be incompatible with each other (the so-called “conflict of edits”), and even theoretically there is no general way to resolve such situations.
Nevertheless, there are a number of private methods that are applicable in certain cases:
One of the mechanisms for data synchronization is replication, which in particular is used to synchronize the contents of databases.
 timely receipt of relevant information is a prerequisite for making informed decisions. Naturally, being in the office in front of a computer screen, getting the necessary information is not a problem. But everything becomes much more complicated if you have a computer, not one, but at least two; if you went on a business trip or affairs require your intervention, even on vacation; if you regularly have to download updated versions of files from the company's server; if you are working on one project with a group of employees and are forced to regularly look at the latest versions of documents from a common folder of this project stored on a remote server, etc.
timely receipt of relevant information is a prerequisite for making informed decisions. Naturally, being in the office in front of a computer screen, getting the necessary information is not a problem. But everything becomes much more complicated if you have a computer, not one, but at least two; if you went on a business trip or affairs require your intervention, even on vacation; if you regularly have to download updated versions of files from the company's server; if you are working on one project with a group of employees and are forced to regularly look at the latest versions of documents from a common folder of this project stored on a remote server, etc.
In all these cases we are talking about the same thing - data synchronization. This term refers to synchronization of related folders with files and nested subfolders located on the same or on different computers. During synchronization, specialized programs scan files with the same name in related folders and compare them on several grounds: by file date — this is usually the main criterion, as well as by size and checksum — these are additional criteria that are not supported by all synchronization programs. The latest copies of files found in this way are sent to a relative folder for updating old copies. The same thing happens with newly appeared files that were not originally in the related folder. The result of synchronization is the complete identity of the related folders - in other words, after synchronization, all files and subfolders in them will be the same.
 it is usually synchronized between related folders located on different computers. Computers can be connected to each other directly via a local area network, infrared port or the Internet. This is the fastest and most convenient option, since the data is synchronized in one step - as a rule, it’s enough to press a single button in the program window.
it is usually synchronized between related folders located on different computers. Computers can be connected to each other directly via a local area network, infrared port or the Internet. This is the fastest and most convenient option, since the data is synchronized in one step - as a rule, it’s enough to press a single button in the program window.
If there is no direct connection, the data can be synchronized using an intermediate device (ISD), which is used to transfer information between two computers during the synchronization procedure. Such a device can be a floppy disk, a removable hard disk, a folder on an FTP server, a USB flash drive, etc. In this case, the data is synchronized in several stages: first, files are packed from one computer and sent to an intermediary device, and then on another computer they accepted, due to which synchronization is carried out. This is what unidirectional synchronization looks like. If it is necessary to perform bidirectional synchronization, then the operations mentioned above are repeated, but in a reverse order.
If necessary, for example, synchronization of large amounts of data, part of the files can be ignored - in this case, for each local folder, the file filtering condition is specified, which is specified as a file mask in general. When synchronizing, you can ignore not only files, but also subfolders — all as well as some selected ones.
The synchronization process, given the periodic nature of this operation, is more convenient to automate using the built-in scheduler, usually supported by appropriate programs. You can, for example, perform regular file synchronization at the scheduled time, on certain days of the week, when Windows starts, when updates appear in synchronized folders, etc.
 |
|
data synchronization is a task that quite often rises to both ordinary users and system administrators, project managers, managers and other company employees.
Many users today have to work not on one, but on two, and even on more computers. It is clear that, going from one computer to another, I don’t want to think every time what files and folders have been changed and copy them from one computer to another. It is much easier to create corresponding synchronization tasks for the main folders and run them automatically, for example, when you turn on the computer.
For mobile users, the actual task is to synchronize laptop data with a working computer, for example, before, after and during a trip. Stationary users absolutely need data synchronization between work and home computers. And it will be useful to both of them to synchronize the data of your computer with the company's server, etc. at any time.
Today, almost all companies use computers. Usually they are integrated into a local network, although it is possible that there are remote computers connected via the Internet. In any case, quite often there is a need for centralized updating of information on all computers (or on computers of a specific department, etc.). So, from time to time on each of computers it is necessary to copy new versions of some documents. Typically, this operation is carried out either by sending them to all employees by e-mail, or by manually copying files to the public folders of each computer. However, there is a better way - you can create the corresponding synchronization tasks, which will update the data on all computers, for example, from the company's server. The advantages of this approach are obvious: the intervention of the employee responsible for this operation will not be required, since everything will happen automatically, and situations where an employee does not receive the necessary information will be completely excluded. The same technique can be used for centralized software updates on all computers, in particular, for updating anti-virus databases, etc.
The presence of regular updates, for example, on the company's website, is a clear indication that it is supported and developed and that it always contains relevant information. Despite the huge number of very different software designed to host and update data on the site (usually using an FTP client or file manager for this purpose), synchronization of the Web server with working folders on the local computer is the fastest update method, since the synchronization program It determines the changed files and copies only their files to the site.
In addition, the update operation in this case occurs completely unnoticed by site visitors and, if properly configured, eliminates the possibility of losing files. The fact is that usually with this synchronization option, files are transferred with false names and renamed after synchronization is completed, therefore, visitors who entered the site at the time of the update will not notice any failures. For greater reliability, files are locked during synchronization, which allows you to avoid possible data loss when a file is changed by another company employee who has access to editing the site.
In addition, such synchronization is usually carried out automatically, which saves the performers from time-consuming, lengthy and of the same type of work.
Backing up data implies periodic, as a rule, daily creation of copies of necessary information, which are usually stored on any removable media and regularly overwritten. There are various specialized software for backing up data; The backup capability is also provided by most programs for data synchronization.
At the same time, unidirectional synchronization can also be used to create backups, in which the updated files are copied in one direction only. This is very convenient because it allows you to avoid duplicating unchanged files automatically, while a regular backup creates a compressed copy of all (both changed and unchanged) folders and files. As a result, backup in the form of unidirectional synchronization takes much less time, which is especially important in cases when data is backed up not only to external media — to another hard disk, CD or DVD, etc., but also to a remote server. via FTP. Duplication to external media and to a remote server increases the reliability of data storage by an order of magnitude, since even in critical cases, when a working hard disk and an external storage medium fail at the same time, the data can still be recovered due to the backup copy on the Internet.
It is very often necessary to compare various modifications of files. Some users are forced to compare regular Word documents, for example, supposedly different versions of a contract for changes, others — price lists or other Excel documents in order to find out if any amendments have been made there. Many people have to look for changes in the images prepared for a particular project, made by other employees working on the project, etc. If there are many such documents, then manually comparing the dates of the corresponding files is a long time, and the synchronization programs will scan hundreds of files in a matter of seconds and let you know which of them have changes.
Comparing files is also necessary in various emergency situations. For example, if at the moment of copying a large amount of data the electricity unexpectedly turned off or simply due to some circumstances the user had to interrupt the process, then by comparing the source folder and the destination folder using the synchronization program, you can quickly copy the missing data.
Synchronization of personal information: address books, mail databases, favorites, ICQ databases, etc. - no less relevant. All this, and first of all postal databases, has to be regularly transferred, for example, from a working computer to a home or from a stationary to a laptop (personal information must be synchronized with various mobile devices, primarily with a mobile phone, but this is a topic for a separate article ). Manually copying and transferring files of several hundred megabytes is not a pleasant experience. In addition, the overwhelming part of the information does not change, so copying it from one computer to another is completely pointless. Can help programs to synchronize data. Of course, the main purpose of this class of programs is to synchronize folders and files, but some of them also support the synchronization of personal information. If the program does not explicitly have such an opportunity, then in most cases it will still be easy to set up to carry out this operation, specifying the appropriate data folders, and then synchronization will be carried out clearly and accurately. But it should be borne in mind that not all programs perceive files received in this way favorably, and it is possible that after synchronization the corresponding file, for example, the mail database, will have to be connected by import. But it's still an order of magnitude faster and easier.
With the development of the information technology industry, a growing number of types of electronic helpers for humans. Nowadays, electronic assistants include: desktops, laptops, pocket assistants, mobile phones and other portable electronic devices.
Every year the number of electronic assistants belonging to one user is growing. In connection with which there is a problem synchronizing devices with each other. Which in turn sets the task of creating software that could provide:
In this paper, we will propose solutions for the problems listed above, by using a software solution for data synchronization and remote computer control based on web technologies.
Architecture of a software solution for data synchronization and control of a remote computer based on web technologies
Software solution for data synchronization and control of remote computers based on web technologies consists of several software solutions:
1. The software solution “Basic” combines the capabilities of a server and a client and is a complete operating system built on the basis of the ReactOS project.
It is based on the modified ReactOS operating system. When launched, after loading the main modules of the operating system, the Apache server is started, followed by the shell loading using the WebKit framework to display the interface of the data synchronization software and control the remote computer based on web technologies. Figure 1 shows the architecture of the “Basic” software solution.
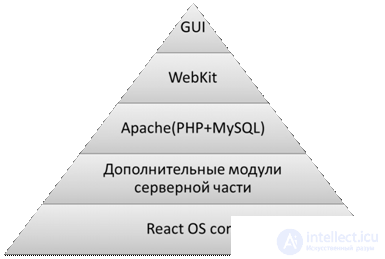
Fig.1. The architecture of the software solution "Basic"
2. The software solution “Addition”, similar to the software solution “Basic”, removed the ReactOS project from the architecture of a software solution for data synchronization and control of a remote computer based on web technologies.The architecture of the Add-on software solution is based on a module consisting of applications and drivers for the operating system pre-installed on the user's device, which allows the Add-on software solution to be installed on top of the pre-installed operating system. Figure 2 shows the architecture of the “Add-on” software solution.

Fig. 2. Architecture of the software solution “Addition”
3. The “Client” software solution differs from the “Basic” software solution and the “Add-on” software solution. It consists of a native client application allowing the client device to receive information from the device with the pre-installed software solution “Basic” and “Addition”.
Web-based remote computer control
В настоящее время для управления удаленным компьютером, применяются системы удаленного доступа, в большинстве построенные на базе протокола RFB (“remote framebuffer”) или аналогичном.
При применении систем удаленного доступа возникают следующие проблемы, которые пытается решить разработанное программное решение.
Клиенты систем удаленного доступа, передают данные несущие в себе всю информацию, выводящуюся на экран компьютера-сервера, что не позволяет использовать данные приложения при низкой скорости соединении и на устройствах с маленьким экраном и не адаптированным интерфейсами управления (Например, управление оконным интерфейсом Windows, используя планшетный компьютер). Как следствие неудобство управления удаленным ЭВМ с помощью мобильного устройства.
When developing a software solution for data synchronization and control of a remote computer based on web technologies, two methods have been developed for transferring information from the server screen.
1. On the server side, a screenshot of the contents of the working window is created and transferred to the client device. On the client device, all received graphic information is embedded in the interface window of the graphical shell of the remote computer control management solution. It is also possible to completely replace the interface of the data synchronization software solution and remote computer management based on web technologies and graphic information obtained from the server. This method allows you to reduce the size of the transmitted graphic information, due to the size of the transmitted image.
2. On the server side, as directed by the client, a console application is launched that receives information from the client and sends text information back. Further, in the client program, text information is embedded in the window.
This method allows you to reduce the size of the transmitted information, due to the refusal to transmit unnecessary graphic information, and allows you to adapt the interface of the broadcast application to the device on which the program will be displayed. Figures 3 and 4 show the difference of one application running on the desktop and on the mobile phone.
Distinctly different (but related) is the notion of data synchronization. This refers to the need to keep multiple copies of a dataset coherent with each other or to maintain data integrity, Figure 3. For example, database replication is used to keep multiple copies of data synchronized with database servers that store data in different places,
Examples include:
Some of the problems that a user may encounter in data synchronization: [8]
When we start doing something, the data that we have is usually in a very simple format. It changes over time as the organization grows and develops, and the results not only create a simple interface between two applications (source and target), but also the need to transform data when switching them to the target application. ETL (extraction load conversion) tools can be very useful at this stage for managing the complexity of the data format.
This is the era of real-time systems. Customers want to see the current status of their order in the online store, the current status of the delivery-parcel, the real-time parcel Tracking-, the current balance on their account, etc. This indicates the need for a real-time system that is updated, as well as to ensure a smooth production process in real time, for example, ordering materials when the company is working out of stock, synchronizing customer orders from the production process, etc. from real life, there are many examples where real-time processing gives a successful and competitive advantage.
There are no fixed rules and policies to ensure data security. It may vary depending on the system you are using. Even if the security is correctly stored in the source system, which captures the data, the privileges of access to security and information must be enforced on the target systems, as well as in order to prevent possible misuse of information. This is a serious problem, and especially when it comes to handling sensitive, confidential and personal information. Thus, due to sensitivity and confidentiality, data transmissions and everything in the gaps of information must be encrypted.
Data quality is another major deterrent. For better management and to maintain good data quality, it is common practice to store data in one place and with different people and different systems and / or applications from different places. This helps in preventing data inconsistencies.
There are five different phases involved in the data synchronization process:
Each of these stages is very important. In the case of large amounts of data, the synchronization process should be carefully planned and carried out to avoid negative impact on performance.
Synchronization was originally a concept based process whereby a lock can be obtained at the facility. Its main purpose was in databases. There are two types (file) of the lock ; read-only and read-write. Read-only locks can be obtained in various ways, which are either threads. Readers-writer locks are exceptional, since they can be used by only one process / thread at a time.
Although locks were obtained for file databases, data is also shared in memory between processes and threads. Sometimes more than one object (or file) is locked at a time. If they are not blocked at the same time, they can overlap, causing a deadlock exception.
Java and Ada have exclusive locks only, because they are thread based and rely on comparison with the exchange instructions of the processor.
The abstract mathematical basis for synchronization primitives is given by the history of the monoid . There are also many higher-level theoretical devices, such as the process of calculus and Petri nets , which can be built on top of the monoid history.

Comments