Relational databases, as we already know, are made up of tables. Each table consists of columns (they are called
fields or attributes ) and rows (they are called
records or tuples ). Tables in relational databases have a number of properties. The main ones are as follows:
- A table cannot have two identical rows. In mathematics, tables that have this property are called relations - in English relation, hence the name - relational.
- The columns are arranged in a specific order, which is created when the table is created. There may not be a single row in the table, but there must be at least one column.
- Each column has a unique name (within the table), and all values in one column have one type (number, text, date ...).
- At the intersection of each column and row can only be an atomic value (one value that does not consist of a group of values). Tables that satisfy this condition are called normalized .
Everything will be clearer by example. Suppose we want to create a database for the forum. The forum has registered users who create topics and leave messages in these topics. This information should be stored in the database.
Theoretically (on paper) we can arrange all this in one table, for example, like this:
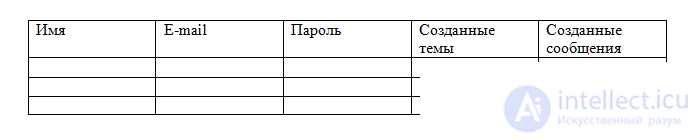
But this contradicts the property of atomicity (one value in one cell), and in the Topics and Messages columns we assume an unlimited number of values. This means that our table should be divided into three: Users, Topics and Messages.
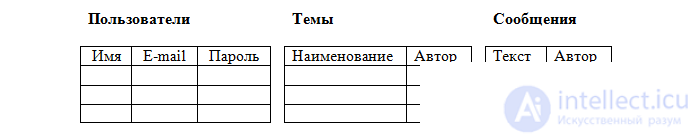
Our table Users satisfies all conditions. But the table of topics and messages - no. After all, the table cannot have two identical lines, and where is the guarantee that one user will not leave two identical messages, for example:

In addition, we know that every message necessarily refers to a topic. And how can you find out from our tables? No To solve these problems, there are
keys in relational databases.
Primary key (abbreviated as RK, primary key) is a column whose values are different in all rows. Primary keys can be logical (natural) and surrogate (artificial). So, for our table Users, the primary key can be an e-mail column (after all, theoretically, there cannot be two users with the same e-mail). In practice, it is better to use surrogate keys, since their use allows you to abstract the keys from real data. In addition, the primary keys cannot be changed, but what if the user changes the e-mail?
The surrogate key is an additional field in the database. As a rule, this is the sequence number of the record (although you can set them at your discretion, making sure that they are unique). Let's enter the primary key fields in our tables:



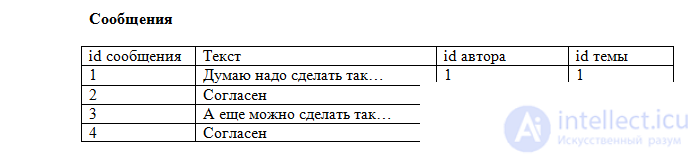
Now each entry in our tables is unique. It remains for us to establish a correspondence between the topics and the messages in them. This is also done using primary keys. We will add another field to the message table:

Now it is clear that the message with id = 2 belongs to the topic "About fishing" (theme id = 4) created by Vasya, and the rest of the messages belong to the topic "About fishing" (theme id = 1) created by Kirill. Such a field is called a
foreign key (abbreviated FK - foreign key). Each value of this field corresponds to a primary key from the "Themes" table. This establishes a unique correspondence between the messages and the topics to which they relate.
The last nuance. Suppose we have added a new user, and his name is also Vasya:

How do we know which Vasya left messages? For this field, the author in the "Subjects" and "Messages" tables will be made also by foreign keys:

Our database is ready. Schematically it can be represented as follows:
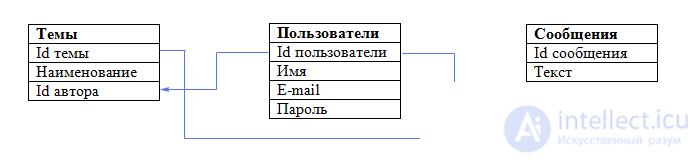
There are only three tablets in our small database, and what if there were 10 or 100? It is clear that at once it is impossible to provide all the tables, fields and relationships that we may need. That is why database design begins with its conceptual model, which we will consider in the next lesson.

Comments
To leave a comment
Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL
Terms: Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL