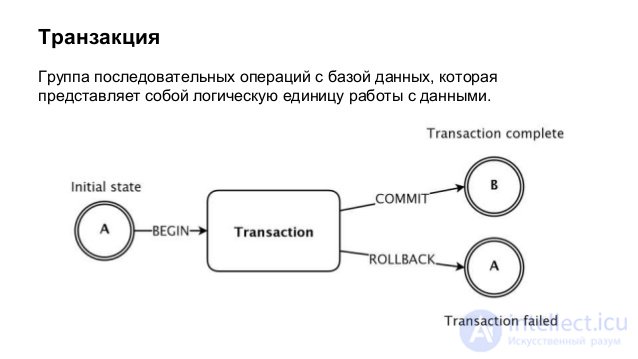
Lecture
The transaction isolation level is a value that determines the level at which inconsistent data is allowed in a transaction, that is, the degree of isolation of one transaction from another. A higher level of isolation improves data accuracy, but it may decrease the number of concurrent transactions. On the other hand, a lower isolation level allows for more concurrent transactions, but reduces the accuracy of the data.



The following problems are possible when executing transactions in parallel:
Consider the situations in which the occurrence of these problems.
A situation where, when simultaneously changing a single data block with different transactions, one of the changes is lost.
Suppose there are two transactions executed simultaneously:
| Transaction 1 | Transaction 2 |
|---|---|
UPDATE tbl1 SET f2=f2+20 WHERE f1=1; |
UPDATE tbl1 SET f2=f2+25 WHERE f1=1; |
In both transactions, the value of the f2 field changes, upon their completion the field value should be increased by 45. In fact, the following sequence of actions may occur:
As a result, the value of the f2 field after the completion of both transactions may increase not by 45, but by 20 or 25, that is, one of the data-changing transactions will “disappear”.

Reading data added or modified by a transaction that is not subsequently confirmed (rolled back).
Suppose there are two transactions opened by various applications in which the following SQL statements are executed:
| Transaction 1 | Transaction 2 |
|---|---|
SELECT f2 FROM tbl1 WHERE f1=1; |
|
UPDATE tbl1 SET f2=f2+1 WHERE f1=1; |
|
SELECT f2 FROM tbl1 WHERE f1=1; |
|
ROLLBACK WORK; |
In transaction 1, the value of the f2 field is changed, and then in transaction 2, the value of this field is selected. After this, transaction 1 is rolled back. As a result, the value obtained by the second transaction will differ from the value stored in the database.

The situation when, when re-reading in one transaction, the previously read data is changed.
Suppose there are two transactions opened by various applications in which the following SQL statements are executed:
| Transaction 1 | Transaction 2 |
|---|---|
SELECT f2 FROM tbl1 WHERE f1=1; |
|
UPDATE tbl1 SET f2=f2+1 WHERE f1=1; |
|
COMMIT; |
|
SELECT f2 FROM tbl1 WHERE f1=1; |
In transaction 2, the value of the f2 field is selected, then in transaction 1, the value of the f2 field is changed. If you try again to select a value from the f2 field in transaction 2, a different result will be obtained. This situation is especially unacceptable when data is read in order to partially modify it and write back to the database.

The situation when, when re-reading in the same transaction, the same sample gives different sets of rows.
Suppose there are two transactions opened by various applications in which the following SQL statements are executed:
| Transaction 1 | Transaction 2 |
|---|---|
SELECT SUM(f2) FROM tbl1; |
|
INSERT INTO tbl1 (f1,f2) VALUES (15,20); |
|
COMMIT; |
|
SELECT SUM(f2) FROM tbl1; |
In transaction 2, a SQL statement is executed using all the values of the f2 field. Then, in transaction 1, a new line is inserted, causing the repeated execution of the SQL statement in transaction 2 to produce a different result. This situation is called phantom reading. It differs from non-repeating reading in that the result of repeated access to data has changed not because of the change / deletion of this data itself, but because of the appearance of new (phantom) data.

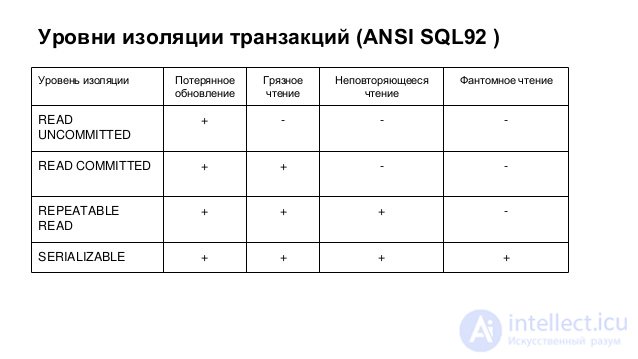
“ Transaction isolation level ” means the degree of protection provided by the internal DBMS mechanisms (that is, not requiring special programming) against all or some of the above-mentioned data inconsistencies that arise during the parallel execution of transactions. The SQL-92 standard defines a scale of four isolation levels: Read uncommitted, Read committed, Repeatable read, Serializable. The first one is the weakest, the last one is the strongest, each subsequent one includes all the previous ones.
The lowest (zero) isolation level. It guarantees only the absence of lost updates [1] . If several parallel transactions try to change the same row of the table, then in the final version the row will have the value defined by the entire set of successfully completed transactions. In this case, it is possible to read not only logically inconsistent data, but also data whose changes have not yet been recorded.
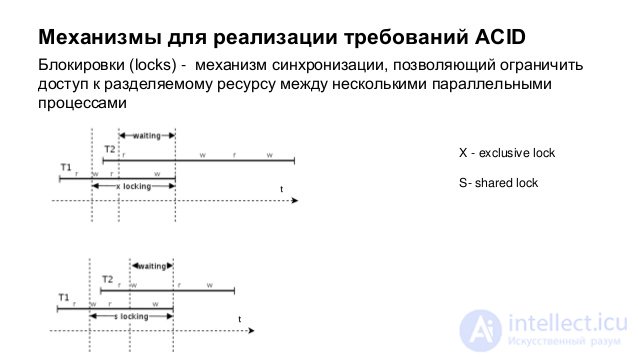
A typical way to implement this level of isolation is to block data for the duration of a change command, which ensures that the change commands for the same lines that are run in parallel are actually executed sequentially and none of the changes are lost. Read-only transactions are never blocked at this isolation level.
Most industrial DBMS, in particular, Microsoft SQL Server, PostgreSQL and Oracle, use this level by default. At this level, protection against a rough, “dirty” reading is provided, however, in the course of one transaction, the other can be successfully completed and the changes made by it are fixed. As a result, the first transaction will work with a different data set.
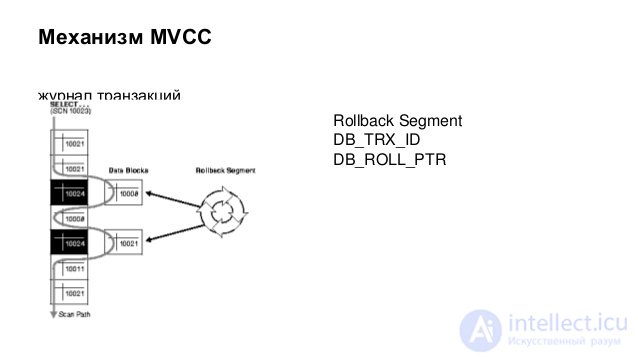
The implementation of the completed reading can be based on one of two approaches: blocking or versioning.
Block readable and changeable data.
The fact is that the reading transaction blocks the readable data in a shared mode, as a result of which a parallel transaction trying to change this data is suspended, and the writing transaction locks the modified data for read transactions running at the level read committed or higher to its completion, thus hindering dirty reading.
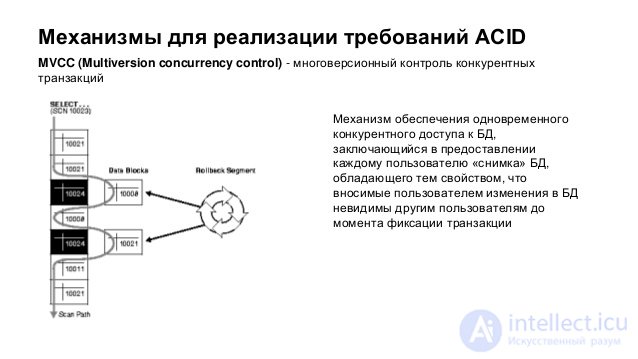
Save multiple versions of parallel variable lines.
Each time a line is changed, the DBMS creates a new version of this line, with which the transaction that changed the data continues to work, while any other “reading” transaction returns the last committed version. The advantage of this approach is that it provides greater speed, as it prevents blocking. However, it requires, in comparison with the first, a significantly larger expenditure of RAM, which is spent on storing versions of strings. In addition, when parallel data is modified by several transactions, a situation may arise where several parallel transactions will make inconsistent changes to the same data (since there are no locks, nothing will prevent it). Then the transaction that is committed first will save its changes to the main database, and the remaining parallel transactions will be impossible to fix (as this will lead to the loss of the first transaction update). The only thing that the DBMS can do in such a situation is to roll back the remaining transactions and give the error message "The record has already been changed."
The specific implementation method is chosen by the DBMS developers, and in some cases can be customized. So, by default, MS SQL uses locks, but (in version 2005 and higher) when setting the READ_COMMITTED_SNAPSHOT parameter of the database, it switches to a versioning strategy, Oracle initially works only according to the versioned version. Informix, you can prevent conflicts between read and write transactions by setting the USELASTCOMMITTED configuration parameter (starting with version 11.1), and the reading transaction will receive the latest confirmed data [2]
The level at which the reading transaction "does not see" the changes in the data that it had previously read. However, no other transaction can change the data read by the current transaction until it is completed.
The locks in dividing mode are applied to all data read by any transaction instruction and are kept until completion. This prevents other transactions from changing rows that were read by an incomplete transaction. However, other transactions may insert new rows matching the search terms of the instructions contained in the current transaction. When the instruction is restarted, the current transaction will extract new lines, which will lead to phantom reading. Considering that the dividing locks are maintained until the completion of the transaction, and not removed at the end of each instruction, the degree of concurrency is lower than with the isolation level READ COMMITTED. Therefore, using data and higher transaction levels unnecessarily is usually not recommended.
The highest level of isolation; transactions are completely isolated from each other, each is performed as if there are no parallel transactions. Only at this level are parallel transactions not subject to the effect of "phantom reading."
Transactional DBMSs do not always support all four levels, and they can also introduce additional ones. Various nuances in providing isolation are also possible.
Thus, Oracle basically does not support the zero level, since its implementation of transactions excludes “dirty reads”, and formally does not allow setting the level of Repeatable read, that is, it supports only Read committed (by default) and Serializable. At the same time, at the level of individual commands, it actually guarantees repeatability of reading (if the SELECT command in the first transaction selects a set of rows from the database, and at this time the parallel second transaction changes some of these rows, then the resulting set obtained by the first transaction will be contain unchanged rows, as if there was no second transaction). Oracle also supports so-called READ-ONLY transactions that are Serializable, but cannot change the data themselves.
Microsoft SQL Server supports all four standard transaction isolation levels, and additionally the SNAPSHOT level, located between Repeatable read and Serialized. A transaction operating at this level sees only those changes in the data that were recorded before it was launched, as well as changes made by it itself, that is, it behaves as if it received a snapshot of the database data when it starts up and works with it.
"+" - prevents, "-" - does not prevent.
| Isolation level | Phantom read | Non-repeatable reading | "Dirty" reading | Lost Update [3] |
|---|---|---|---|---|
| SERIALIZABLE | + | + | + | + |
| REPEATABLE READ | - | + | + | + |
| READ COMMITTED | - | - | + | + |
| READ UNCOMMITTED | - | - | - | + |
CREATE TABLE test (id INT, value VARCHAR(255)) ENGINE=InnoDB;
START TRANSACTION; INSERT INTO test(id, value) VALUES (1, 'test'), (2, 'test 2'); SELECT * FROM test; COMMIT; SELECT * FROM test;
SHOW VARIABLES LIKE '%tx_isolation%';
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
You can get information about isolation level, global or for the current connection:
SELECT @@ global.tx_isolation; SELECT @@ tx_isolation;
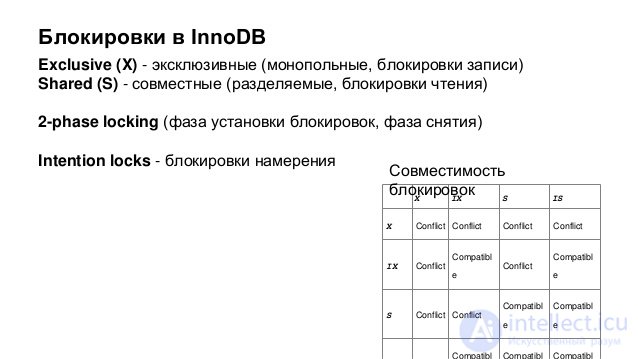
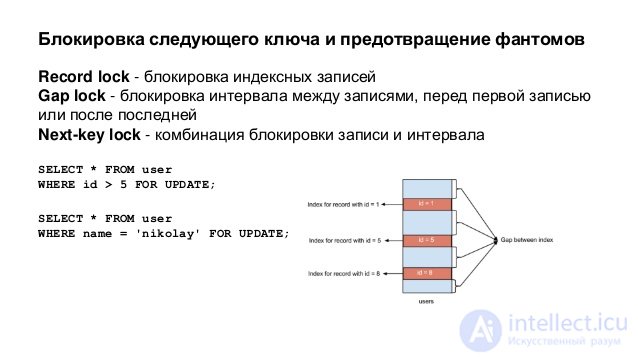
In line-level locking, InnoDB uses the so-called next-key lock. This means that, in addition to index entries, InnoDB can also block the "interval" before the index entry for blocking inserts by other users immediately before the index entry. Locking the next key means locking, which is placed on the index record and the interval in front of it. Interval lock only means blocking an interval before some index entries.
A detailed description of each isolation level in InnoDB:
READ UNCOMMITTED Also called dirty reading: non-blocking selections ( SELECT ) are performed in such a way that we do not see possible early versions of the record; thus, they are "inconsistently" read in this level of isolation; otherwise, this level works the same as READ COMMITTED .
READ COMMITTED Something like an Oracle isolation level. All SELECT ... FOR UPDATE and SELECT ... LOCK IN SHARE MODE block only index entries and do not block the interval in front of them. Therefore, they allow you to freely add new entries after being blocked. UPDATE and DELETE , which use a unique index and unique search conditions, block only the found index entry, and do not block the interval in front of it. But in UPDATE and DELETE range type in InnoDB must set the next key lock or interval lock and block other users from adding to the interval covered by the range. This is necessary because "phantom lines" must be blocked for successful replication and recovery in MySQL. Consistent reading works just like Oracle: every consistent read, even within a single transaction, sets and reads its own snapshot.
REPEATABLE READ This isolation level is used by default in InnoDB. SELECT ... FOR UPDATE , SELECT ... LOCK IN SHARE MODE , UPDATE , and DELETE , which use unique indexes and a unique search condition, block only the found index entry and do not block the interval in front of it. In other cases, this operation uses the next key lock, blocks the range of indexes scanned by the next key lock or interval lock, and blocks new additions by other users.
In a consistent reading, there is an important difference from the previous isolation level: at this level, all agreed readings within the same transaction read a snapshot made for the first reading. This convention means that if you execute several simple selections ( SELECT ) within the same transaction, these selections will be consistent with each other.
SERIALIZABLE This level is similar to the previous one, but simple SELECT converted to SELECT ... LOCK IN SHARE MODE .








Comments
To leave a comment
Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL
Terms: Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL