Lecture
Это окончание невероятной информации про распределенные и параллельные системы баз данных.
...
Например, система поддержки кооперативной деятельности предполагает, скорее, кооперацию при доступе к общим данным, чем конкуренцию. Именно этими изменяющимися требованиями вызвана необходимость разработки новых моделей транзакций и соответствующих критериев корректности.
В качестве кандидатов, способных удовлетворить упоминавшимся выше требованиям, сейчас рассматриваются объектно-ориентированные СУБД. В таких системах операции (методы) инкапсулированы вместе с данными. Следовательно, для них необходимы четкие определения семантики модификации данных и модели транзакций, опирающиеся на семантику инкапсулированных операций [Ozsu, 1994].
За последние несколько лет распределенные и параллельные СУБД стали реальностью. Они предоставляют функциональность централизованных СУБД, но в такой среде, где данные распределены между компьютерами, связанными сетью, или между узлами многопроцессорной системы. Распределенные СУБД допускают естественный рост и расширение баз данных путем простого добавления в сеть дополнительных машин. Подобные системы обладают более привлекательными характеристиками "цена/производительность", благодаря современным прогрессивным сетевым технологиям. Параллельные СУБД – это, пожалуй, единственный реалистичный подход для удовлетворения потребностей многих важных прикладных областей, которым необходима исключительно высокая пропускная способность баз данных. Поэтому при проектировании параллельных и распределенных СУБД следует предусмотреть в них соответствующие протоколы и стратегии обработки, направленные на достижение высокой производительности. Обзор именно таких протоколов и стратегий и представлен в данной статье.
Мы не охватили ряд смежных вопросов. Две важные проблемы, не рассмотренные здесь, – это системы мультибаз данных и распределенные объектно-ориентированные базы данных. Многие информационные системы развиваются независимо, опираясь на собственные реализации СУБД. Позже, когда появляется необходимость "интегрировать" эти автономные и часто разнородные системы, возникают серьезные трудности. Системы, которые предоставляют доступ к подобным, независимо разработанным разнородным базам данных, называются мультибазами данных (multidatabase system) [Sheth and Larson, 1990].
Проникновение баз данных в такие области (проектирование, мультимедийные системы, геоинформационные системы, системы обработки графических образов), для которых реляционные СУБД изначально не предназначались, послужило стимулом для поиска новых моделей и архитектур баз данных. Среди наиболее серьезных кандидатов, претендующих на удовлетворение потребностей новых классов приложений, – объектно-ориентированные СУБД [Dogac et al., 1994]. Внедрение принципов распределенной обработки в эти СУБД стало источником целого ряда проблем, относящихся к области так называемого распределенного управления объектами [Ozsu et al., 1994]. Вопросы, связанные с мультибазами данных и распределенным управлением объектами, остались за рамками рассмотрения настоящей статьи.
Алгоритм голосования на базе кворума (quorum-based voting algorithm). Протокол управления репликами, при котором транзакция, для того чтобы выполнить операцию чтения или записи элемента данных, должна собрать необходимый кворум голосов его физических копий.
Алгоритм управления одновременным доступом (concurrency control algorithm). Алгоритм, который обеспечивает синхронизацию операций, относящихся к одновременно выполняемым транзакциям над разделяемой базой данных.
Архитектура клиент-сервер (client/server architecture). Архитектура распределенных/параллельных СУБД, в которой множество машин-клиентов, обладающих ограниченной функциональностью, осуществляют доступ к множеству серверов управления данными.
Архитектура без разделяемых ресурсов (shared-nothing architecture:). Архитектура параллельной СУБД, в которой каждый процессор имеет монопольный доступ к своей собственной оперативной памяти и к собственному набору дисков.
Архитектура с разделяемой памятью (shared-memory architecture). Архитектура параллельной СУБД, в которой каждый процессор посредством быстрых линий связи (высокоскоростной шины или коммутатора) имеет доступ к любому модулю памяти и к любому дисковому устройству.
Архитектура с разделяемыми дисками (shared-disk architecture). Архитектура параллельной СУБД, в которой каждый процессор имеет разделяемый доступ к любому диску системы посредством коммуникационных средств и монопольный доступ к собственной оперативной памяти.
Атомарность (atomicity). Свойство обработки транзакций, заключающееся в том, что либо выполняются все операции транзакции, либо не выполняется ни одна (принцип "все или ничего").
Блокирование (locking). Метод управления одновременным доступом, при котором на единицы хранения базы данных (страницы) накладываются блокировки от имени транзакции, которой необходим доступ к ним.
Внутризапросный параллелизм (intra-query parallelism). Параллельное выполнение множества независимых операций, которые могут относиться к одному и тому же запросу.
Внутриоперационный параллелизм (intra-operation parallelism). Параллельное выполнение одной реляционной операции в виде множества субопераций.
Двухфазовая фиксация транзакций (two-phase commit). Протокол атомарной фиксации, который гарантирует одинаковое завершение транзакции на всех затрагиваемых ею узлах. Название связано с тем, что в ходе выполнения протокола происходит два "раунда" обмена сообщениями между узлами.
Двухфазовое блокирование (two-phase locking). Алгоритм блокирования, при котором транзакция не имеет права установить новую блокировку на элемент данных, пока не сняты предыдущие.
Долговечность (durability). Свойство обработки транзакций, заключающееся в том, что результаты успешно завершенной (зафиксированной) транзакции сохраняются даже при последующих сбоях системы.
Изолированность (isolation). Свойство обработки транзакций, заключающееся в том, что результат действий, производимых транзакцией, не может зависеть (изолирован) от одновременно выполняющихся других транзакций.
Линейная масштабируемость (linear scaleup). Сохранение той же скорости обработки при увеличении размера базы данных вместе с одновременным пропорциональным наращиванием процессорной мощности и объема памяти.
Линейное ускорение (linear speedup). Пропорциональное увеличение скорости обработки при увеличении процессорной мощности и объема памяти и сохранении прежнего размера базы данных.
Межзапросный параллелизм (intra-query parallelism). Параллельное выполнение нескольких запросов, относящихся к разным транзакциям.
Независимость данных (data independence). Устойчивость прикладных программ и запросов к изменениям в физической организации базы данных (независимость от физических данных) или в ее логической организации (независимость от логических данных) и обратная независимость.
Неустойчивая база данных (volatile database). Часть базы данных, хранимая в буферах оперативной памяти.
Обработка запроса (query processing). Процесс трансляции декларативного запроса в последовательность низкоуровневых операций манипулирования данными.
Оптимизация запроса (query optimization). Процесс нахождения "наилучшей" стратегии выполнения запроса из некоторого множества альтернатив.
Параллельная система управления базами данных (parallel database management system). Система управления базами данных, реализованная на сильносвязанной многопроцессорной архитектуре.
Полная эквивалентность копий (one copy equivalence). Политика управления реплицированием, требующая, чтобы по завершении транзакции все копии каждого элемента данных, который модифицирует данная транзакция, были идентичны.
Прозрачность (transparency). Распространение понятия независимости данных на распределенные системы, при котором от пользователей экранируются такие аспекты хранения данных, как распределение, фрагментация, реплицирование.
Протокол журнализации (logging protocol). Протокол, который производит в отдельной области памяти записи обо всех изменениях в базе данных, прежде чем эти изменения будут реально выполнены.
Протокол терминирования (termination protocol). Протокол, при помощи которого отдельный узел может принять решение о том, как следует завершить транзакцию в условиях, когда он не может взаимодействовать с другими участвующими в данной транзакции узлами.
Протокол ROWA (Read-Once/Write-All protocol). Протокол управления реплицированием, который логическую операцию чтения отображает на операцию чтения любой физической копии, а логическую операцию записи – на множество операций записи во все физические копии элемента данных.
Распределенная система управления базами данных (distributed database management system). Система, которая управляет базой данных, распределенной по узлам компьютерной сети, и обеспечивает для пользователей прозрачность распределения данных.
Сериализуемость (serializability). Критерий корректности для управления одновременным доступом, который требует, чтобы эффект множества одновременно выполняемых транзакций был эквивалентен эффекту от их последовательного выполнения при каком-либо упорядочении.
Стабильная база данных (stable database). Часть базы данных, хранимая во вторичной памяти.
Транзакция (transaction). Неделимая (атомарная) единица выполнения операций над базой данных, в результате которой база данных остается в согласованном состоянии.
Тупик (deadlock). Ситуация, когда множество транзакций образует цикл, ожидая снятия блокировок, установленных другими транзакциями из этого множества.
1) Разница между оптимальным и "наилучшим" планом состоит в том, что для нахождения первого требуется исследование всех возможных планов, что на практике никогда не реализуется из-за трудноразрешимого характера задачи.
2) Вопросы репликации не столь существенны для параллельных СУБД, данные которых обычно не копируются на нескольких процессорах. Репликация может возникать как результат передачи (транспортировки) данных в ходе оптимизации запроса, но эти ситуации находятся вне ведения протоколов управления репликами.
Становление систем управления базами данных совпало по времени со значительными успехами в развитии технологий распределенных вычислений и параллельной обработки. В результате возникли системы управления распределенными базами данных. Именно эти системы становятся доминирующими инструментами для создания приложений интенсивной обработки данных. В среде распределенных СУБД упрощается решение вопросов, связанных с возрастанием объема баз данных или потребностей обработки. При этом редко возникает необходимость в серьезной перестройке системы; расширение возможностей обычно достигается за счет добавления процессорных мощностей или памяти.
В идеале распределенная СУБД обладает свойством линейной расширяемости и линейного ускорения. Под линейной расширяемостью понимается сохранение того же уровня производительности при увеличении размера базы данных и одновременном пропорциональном увеличении процессорной мощности и объема памяти. Линейное ускорение означает, что с наращиванием процессорной мощности и объема памяти при сохранении прежнего размера базы данных пропорционально возрастает производительность. Причем при расширении системы потребуется минимальная реорганизация существующей базы данных.
С учетом соотношения цена/производительность для микропроцессоров и рабочих станций экономически выгоднее оказывается составить систему из нескольких небольших компьютеров, чем реализовать ее на эквивалентной по мощности одной большой машине. Множество коммерческих распределенных СУБД функционируют на мини-компьютерах и рабочих станциях именно по причине более выгодного соотношения цена/производительность. Технологии, основанные на применении рабочих станций, получили столь широкое распространение благодаря тому, что большинство коммерческих СУБД способны работать в рамках локальных сетей, где в основном и используются рабочие станции. Развитие распределенных СУБД, предназначенных для глобальных сетей WAN, может привести к повышению роли мэйнфреймов. С другой стороны, распределенные СУБД будущих поколений, скорее всего, будут поддерживать иерархические сетевые структуры, состоящие из кластеров, в пределах которых компьютеры взаимодействуют на базе локальной сети, а сами кластеры соединяются между собой посредством высокоскоростных магистралей.
Все эти причины привели к бурному развитию технологий распределенных баз данных информационных систем. Однако остаются нерешенными некоторые сложные вопросы связанные с данной темой. Один из этих вопросов - динамические процессы в распределенных базах данных.
Объектом исследования является распределенная база данных компьютерных информационных систем.
Предметом исследования является влияние динамических процессов на функционирование распределенной базы данных.
Распределенная база данных (РБД) -- это совокупность логически взаимосвязанных баз данных, распределенных в компьютерной сети.
Другими словами, системы распределенных баз данных состоят из набора узлов, связанных вместе коммуникационной сетью, в которой:
one)
каждый узел обладает своими собственными системами баз данных;
2)
узлы работают согласованно, поэтому пользователь может получить доступ к данным на любом узле сети, как будто все данные находятся на его собственном узле.
На рисунке 1 приведен пример распределенной базы данных.
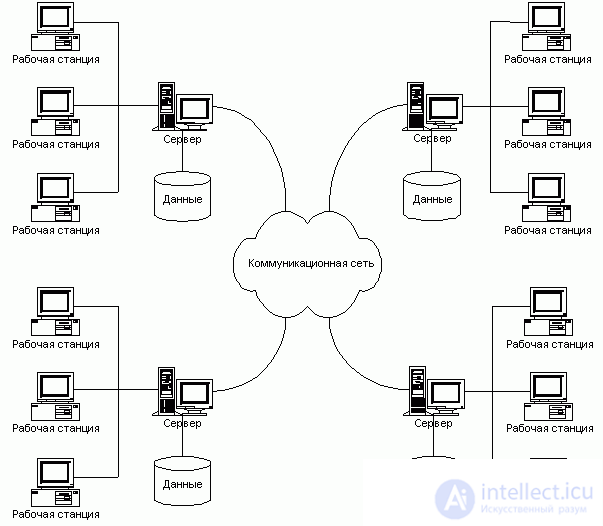
Система управления распределенной базой данных (РСУБД) -- это программная система, которая обеспечивает управление распределенной базой данных таким образом, чтобы ее распределенность была прозрачна для пользователей.
Эти определения можно дополнить, если рассмотреть также различные характеристики РБД и РСУБД. В 1981г К. Дейт опубликовал свои правила для распределенных баз данных1. Ниже приведены эти 12 правил.
База данных физически распределяется по узлам данных при помощи фрагментации и репликации, или тиражирования, данных.
Отношения, принадлежащие реляционной базе данных, могут быть фрагментированы на горизонтальные или вертикальные разделы.
Горизонтальная фрагментация реализуется при помощи операции селекции, которая направляет каждый кортеж отношения в один из разделов, руководствуясь предикатом фрагментации. Например, для отношения Employee (Сотрудник) возможна фрагментация в соответствии с территориальным распределением рабочих мест сотрудников.
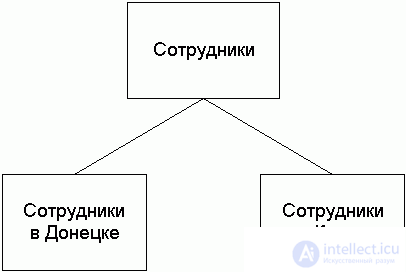
Тогда запрос ``получить информацию о сотрудниках компании'' может быть сформулирован так:
SELECT * FROM employee@donetsk, employee@kiev
При вертикальной фрагментации отношение делится на разделы при помощи операции проекции. Например, один раздел отношения Employee может содержать поля Номер_сотрудника (emp_id), ФИО_сотрудника (emp_name), Адрес_сотрудника (emp_adress), а другой -- поля Номер_сотрудника (emp_id), Оклад (salary), Руководитель (emp_chief).
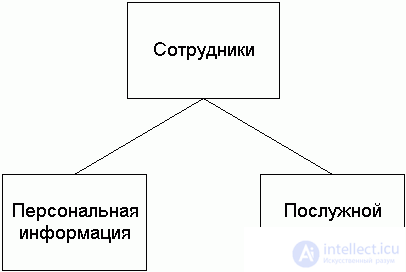
Тогда запрос ``получить информацию о заработной плате сотрудников компании'' будет выглядеть следующим образом:
SELECT employee.emp_id, emp_name, salary FROM employee@donetsk, employee@kiev ORDER BY emp_id
За счет фрагментации данные приближаются к месту их наиболее интенсивного использования, что потенциально снижает затраты на пересылки; уменьшаются также размеры отношений, участвующих в пользовательских запросах.
Второй способ распределения данных -- репликация. Репликация (или тиражирование) означает создание дубликатов данных. Репликаты -- это множество различных физических копий некоторого объекта базы данных (обычно таблицы), для которых поддерживается синхронизация (идентичность) с некоторой ``главной'' копией. Теоретически значения всех данных в тиражированных объектах должны автоматически и незамедлительно синхронизироваться друг с другом. (На практике это правило обычно несколько ослаб***яется.) В некоторых системах копии используются исключительно в режиме чтения и обновляются в соответствии с заданным расписанием. В других средах допускается модификация отдельных значений в копиях, и эти изменения распространяются в соответствии с процедурами планирования и координации. На рисунке 4 показаны различные модели тиражирования.
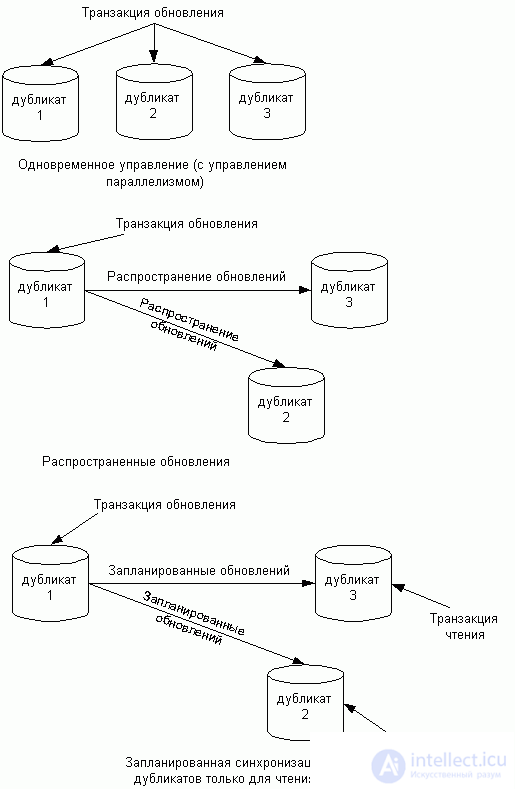
При репликации фрагменты данных тиражируются с учетом спроса на доступ к ним. Это полезно, если доступ к одним и тем же данным нужен из приложений, выполняющихся на разных узлах. В таком случае, с точки зрения экономии затрат, более эффективно будет поддерживать копии данных на всех узлах, чем непрерывно пересылать данные между узлами.
Основной проблемой репликации данных является то, что обновление любого логического объекта должно распространяться на все хранимые копии этого объекта. Трудности возникают из-за того, что некоторый узел, содержащий данный объект, может быть недоступен (например, из-за краха системы или данного узла) именно в момент обновления. В таком случае очевидная стратегия немедленного распространения обновлений на все копии может оказаться неприемлемой, поскольку предполагается, что обновление (а значит и исполнение транзакции) будет провалено, если одна из копий будет недоступна в текущий момент.
Важным компонентом структуры логического уровня РБД является сетевой каталог , который обеспечивает эффективное выполнение основных функций управления РБД и содержит всю информацию, необходимую для обеспечения независимости размещения, фрагментации и репликации. Существует несколько вариантов хранения системного каталога. Ниже перечислены некоторые из этих вариантов.
Для каждого подхода характерны определенные недостатки и проблемы. В первом подходе, очевидно, не достигается "независимость от центрального узла". Во втором утрачивается автономность функционирования, поскольку при обновлении каждого каталога это обновление придется распространять на каждый узел. В третьем выполнение не локальных операций становится весьма дорогостоящим (для поиска удаленного объекта потребуется в среднем осуществить доступ к половине имеющихся узлов). Четвертый подход более эффективен, чем третий (для поиска удаленного объекта потребуется осуществить доступ только к одному удаленному каталогу), но в нем снова не достигается ``независимость от центрального узла''.
Сегодня практически все крупнейшие производители СУБД предлагают решения в области управления распределенными ресурсами. Однако все эти решения поддерживают ограниченные функции построения неоднородных распределенных систем.
Среди многочисленных прототипов и научно-исследовательских систем следует упомянуть систему SDD-1 , созданную в конце 70-х -- начале 80-х годов в научно-исследовательском отделении фирмы Computer Corporation of America; систему R* , которая является распределенной версией системы System R и создана в начале 80-х годов фирмой IBM; а также систему Distributed INGRES , которая является распределенной версией системы INGRES и создана также в начале 80-х годов в Калифорнийском университете в Беркли.
Что касается коммерческих продуктов, то в настоящее время в большинстве реляционных систем предусмотрены разные виды поддержки использования распределенных баз данных с разной степенью функциональности. Среди таких систем наиболее известны система INGRES/STAR отделения Ingres Division фирмы The ASK Group Inc., система ORACLE фирмы Oracle Corporation, а также модуль распределенной работы системы DB2 фирмы IBM.
РБД стали в настоящее время объектом всестороннего исследования. При этом наряду с принципами конструирования и организации, алгоритмами действия большое внимание уделяется методам анализа качества работы РБД, а также исследованию закономерностей их функционирования и взаимосвязи качества работы с особенностями конструктивных и алгоритмических решений.
Однако ввиду исключительной сложности РБД как объекта формального описания и расчета до настоящего времени априорная оценка ожидаемого эффекта от тех или иных конструктивных и алгоритмических решений, а следовательно, и от капиталовложений, необходимых для их реализации, обычно базируется на общих качественных соображениях, не подкрепленных расчетом, когда влияние отдельных факторов оценивается интуитивно, и возможны грубые ошибки. Для практически убедительного суждения о качестве работы РБД с позиции потребителя необходимо оценить пусть с ограниченной, но заранее известной точностью функции распределения вероятностей параметров работы ИС.
Реальные сложные системы можно исследовать с помощью двух типов математических моделей: аналитических и имитационных. В аналитических моделях поведение систем записывается в виде некоторых функциональных соотношений или логических условий. Наиболее полное исследование удается провести в том случае, когда получены явные зависимости, связывающие искомые величины с параметрами исследуемых объектов и начальными условиями его изучения. Однако это удается выполнить только для сравнительно простых систем. Для РБД, которая является сложной системой, нам придется идти на упрощения представления реальных явлений, дающие возможность описать их поведение и представить взаимодействия между компонентами распределенной системы. Для построения аналитических моделей имеется мощный математический аппарат (алгебра, функциональный анализ, разностные уравнения, теория вероятностей, математическая статистика, теория массового обслуживания и т.д.).
Аналитические модели распределенных баз данных предложены в ряде работ изданных в начале 90-х годов. В своей книге [Cegel90] Г. Г. Цегелик рассмотрел несколько моделей РБД. Эти модели различаются разными подходами к их построению и выбранными топологиями. Эти модели позволяют оптимизировать распределение объектов РБД по узлам распределенной системы. Однако они построены при некоторых, очень значительных, упрощениях. Самое существенное из них -- это то, что эти модели статичны. Those. они не учитывают влияние динамических процессов в РБД. Это приводит к неточности модели и мы не в состоянии измерить степень этой неточности.
Аналитическую модель также рассматривают А. Г. Мамиконов, В. В. Кульба и др. Для этой модели характерны те же недостатки что и для модели, предложенной Г. Г. Цегеликом.
Основными методами расчета параметров работы ИС, используемыми в настоящее время, являются методы теории массового обслуживания и, имитационного моделирования. Применение их при ряде упрощающих допущений на законы распределения времени возникновения запросов, их объема, структуру системы и т.п. позволяет наряду с оценками времени передачи информации получить значения многих других характеристик РБД -- оценить длины очередей, вероятности отказа в обслуживании и т.п.
Однако методы теории массового обслуживания достаточно сложны и не могут в настоящее время использоваться для расчета временных характеристик в реальных РБД с большим числом узлов и каналов связи. Также при помощи теории массового обслуживания трудно предусмотреть все специфичные моменты работы реальных РБД. Поэтому для исследования предпочтительней использовать имитационное моделирование.
В имитационной модели поведение компонент объекта описывается набором алгоритмов, которые затем реализуют ситуации, возникающие в реальной системе. Моделирующие алгоритмы позволяют по исходным данным, содержащим сведения о начальном состоянии объекта, и фактическим значениям параметров системы отобразить реальные явления в системе и получить сведения о возможном поведении объекта для данной конкретной ситуации.
При всех преимуществах данного подхода автору неизвестны примеры использования методов имитационного моделирования для расчета параметров функционирования РБД в компьютерных информационных системах.
Часть 1 Distributed and parallel database systems
Часть 2 Исследовательские проблемы - Distributed and parallel database systems
Часть 3 Объект и предмет исследования. - Distributed and parallel database systems

Comments
To leave a comment
Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL
Terms: Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL