Lecture
Information coding algorithms that lead to a decrease in the length of the code, relative to the original message length, are called information compression algorithms, and such coding is called compression coding.
We are, in fact, already familiar with codes of this kind. These are the Shannon – Fano and Huffman codes, which are called the optimal non-uniform variable-length codes. If we encode, for example, a text message without taking into account the probability of characters appearing, then we can spend up to 8 bits for each character (if the characters are defined by the ASCII table). Knowledge of the statistics of the appearance of characters reduces the number of bits per character of the alphabet on average to the value of the source entropy.
Shannon-Feno and Huffman coding methods are collectively called statistical methods, since they use the probabilities of occurrence of individual words or characters in the source of messages to obtain the effect of compression. Vocabulary algorithms are more practical. Their advantage over statistical ones is theoretically explained by the fact that they make it possible to economically encode sequences of characters of different lengths without knowing the statistics of the source of the messages.
Virtually all the word methods for encoding are based on the algorithms described in the work of two Israeli scientists, Ziva and Lempel, published in 1977. The essence of them is that the phrases in the compressible text are replaced by a pointer (or a link) to the place where they have already met this text.
One of the reasons for the popularity of LZ algorithms is their exceptional simplicity with high compression efficiency.
This method quickly adapts to the structure of the text and can encode short teslov pointers that often appear in the text. New words and phrases can also be coded by parts of previously encountered words by replacing them with their pointers or numbers.
Decoding compressed text is carried out directly - there is a simple replacement of the pointer with a ready-made phrase from the dictionary to which it points. In practice, the LZ-method achieves good compression, its important feature is very fast decoder operation. (When we talk about text, we assume that some data set with a finite discrete alphabet is subjected to coding, and this is not necessarily the text in the literal sense of the word.)
All vocabulary coding methods of the LZ type can be divided into two groups.
The first group with an implicit dictionary view is the LZ77 algorithm.
The methods belonging to the first group find in the encoded sequence the chains of characters that have previously met, and instead of repeating these chains, replace them with pointers to the previous repetitions of these chains.
Dictionary of this group of algorithms is implicitly contained in the data being processed; only pointers to the encountered chains of repeating characters are saved.
All algorithms from this group are based on the LZ77 algorithm. The most perfect representative of this group, which included all the achievements made in this direction, is the LZSS algorithm, published in 1982 by Storeor and Szymanski.
The coding procedure in accordance with the algorithms of this group is illustrated by example 12.1.
Login A B C D A B B E
one
Exit A B C D 1 E
Example 12.1
compression occurred due to a repeating piece of text A B B.
Algorithms of the second group based on the LZ78 method use the dictionary explicitly
The algorithms of the second group in addition to the source source dictionary in the course of compression-coding create a dictionary of phrases, which are repeated combinations of characters of the source dictionary, which are encountered in the input data. At the same time, the source dictionary’s size increases, and more bits will be needed to encode it, but a significant part of this dictionary will be no longer individual letters, but letter combinations or whole words. When the coder detects a phrase that has already been encountered, it replaces it with its index phrases in the dictionary. In this case, the length of the index code is less or much less than the length of the phrase code.
All methods of this group are based on an algorithm developed and published by Lempel and Ziv in 1978 - LZ78. The most perfect at the moment representative of this group of dictionary methods is the LZW algorithm, developed in 1984 by Terry Welch.
The idea of this group of algorithms can also be explained using Example 12.2.
Example 12.2
Login A B C A B C A B D E
Dictionary of the main A-1, B-2, B-3, G-4, D-5, E-5, dictionary of phrases AB-6, ABV-7
Logout12361645 plus you must somehow save the main dictionary.
12 2 LZ - data packaging algorithms : LZ77.
Consider the algorithm of operation of the LZ77 compression encoder in more detail.
The main idea of LZ77 is that the second and subsequent occurrences of a string of characters in a message are replaced by references to its first occurrence.
LZ77 uses the already scanned part of the message as a dictionary. In order to achieve compression, he tries to replace the next message fragment with the index of this fragment in the dictionary.
LZ77 uses a "sliding" window according to the message, divided into two unequal parts. The first, larger in size, includes the part of the message already scanned. This is the current dictionary of the encoder, from where it takes duplicate pieces. The second, much smaller, is a buffer containing still unencoded characters in the input stream. Usually, the dictionary window size is several kilobytes, and the buffer size is no more than one hundred bytes. The algorithm attempts to find a fragment in the dictionary that slides over the text that matches the contents of the buffer or part of the buffer.
The LZ77 algorithm generates codes consisting of three elements:
· offset in the dictionary relative to its beginning of the substring, coinciding with the beginning of the contents of the buffer;
· the length of this substring;
· the first character of the buffer following the substring.
An example . 12.3
Code LZ77 string "RED PAINT".
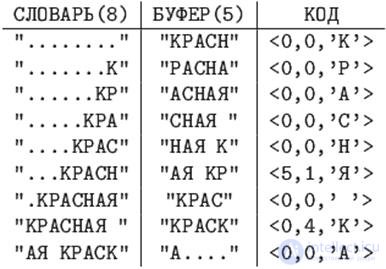
In the 9th line, you need to shift to 5 positions (the length of the matching string is +1) and read as many characters to the buffer.
In the last line, the letter "A" is taken not from the dictionary, since she is the last.
The length of the code is calculated as follows: the length of the substring cannot be larger than the buffer size, and the offset cannot be larger than the size of the dictionary minus one . Therefore, the length of the binary offset code will be rounded up log 2 ( dictionary size ) , and the length of the binary code for the length of the substring will be rounded up log2 (buffer size +1) . A character is encoded with 8 bits (for example, in an ASCII + table).
In the last example, the length of the resulting code is 9 * (3 + 3 + 8) = 126 bits, versus 14 * 8 = 112 bits of the original string length.
LZ77 unpacking algorithm. Example 12.4
1. LZ77, dictionary length - 8 bytes (characters). Compressed Message Codes
- 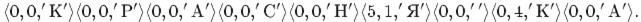
Disadvantages of LZ77:
LZ77 has the following obvious disadvantages:
1. the length of the substring that can be encoded is limited by the size of the buffer.
2. with increasing dictionary size, the speed of the algorithm-coder slows down proportionally;
3. encoding single characters is very inefficient.
The encoding of single characters can be made effective by discarding unnecessary references to the dictionary for them. In addition, in some versions of LZ77, the ability to encode consecutive identical characters is added to enhance compression.
If mechanically excessively increasing the size of the dictionary and buffer, this will lead to a decrease in coding efficiency, since with the growth of these values, the lengths of codes for encoding offsets and lengths will also increase, which will make codes for short substrings unacceptably large.
12 3 LZ - data packaging algorithms : LZ78.
In 1978, the authors of LZ77 developed the LZ78 algorithm, devoid of these disadvantages.
LZ78 does not use a "sliding" window, it stores a dictionary of already viewed phrases. When the algorithm starts, this dictionary contains only one empty string (a string of length zero). The algorithm reads the characters of the message until the accumulated substring is included entirely in one of the dictionary phrases. As soon as this line no longer corresponds to at least one phrase of the dictionary, the algorithm generates a code consisting of the index of the line in the dictionary, which until the last character entered contained the input string, and the character following the match. Then the entered substring is added to the dictionary. If the dictionary is already full, then the phrase used in the comparisons is deleted from it beforehand.
The key to the size of the resulting codes is the size of the dictionary in the phrases, because each code, when encoded using the LZ78 method, contains the phrase number in the dictionary. It follows from the latter that these codes have a constant length equal to the rounded upward binary logarithm of the size of the dictionary + 8 (this is the number of bits in the extended ASCII byte code).
Example 12.5 .
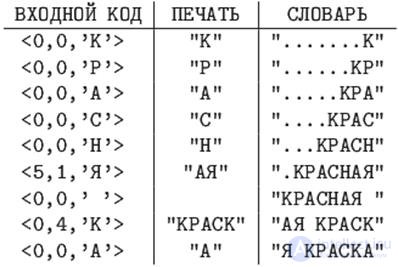
Using the LZ78 algorithm, encode the string "RED PAINT" using a dictionary with a length of 16 phrases.
A pointer to any phrase in such a dictionary is a number from 0 to 15, four bits are enough to encode it.
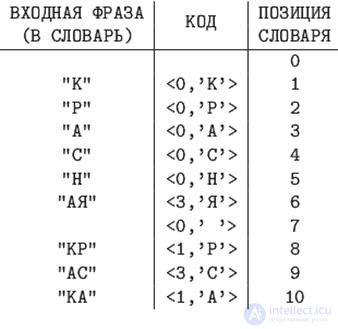
LZ-data decompression algorithms. Example 13.6
LZ78, dictionary length - 16 phrases. Compressed Message Codes -
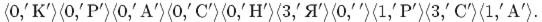
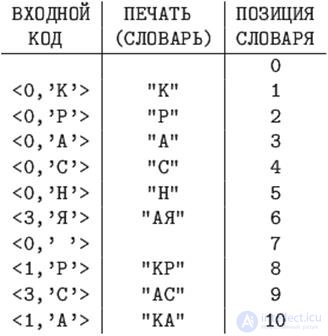
In the last example, the length of the resulting code is 10 * (4 + 8) = 120 bits.
Algorithms LZ77, LZ78 and can be used freely.
In 1984, Welch created the LZW algorithm, more efficient than its prototype, by modifying LZ78. The LZW algorithm is used as the basis in many well-known and effective data compression programs - archivers.
12 4 Test questions .
1. What are the main goals of coding with data compression?
2. The basic technique for coding with compression.
3. What is the difference between the LZ77 coding method and the LZ78 coding method?
4. Which of the LZ77 or LZ78 coding methods is potentially more efficient?
5. What are the main disadvantages of the LZ77 method?

Comments