There are two fundamental approaches to the physical storage of relationships. The most common is the storied storage of relationships (a tuple is a unit of physical storage). Naturally, this provides quick access to the whole tuple, but at the same time, the common values of different tuples of the same relation are duplicated in the external memory and, generally speaking, unnecessary exchanges with the external memory may be necessary if a part of the tuple is needed.
An alternative (less common) approach is to store the column relation, i.e. storage unit is a relationship column with excluded duplicates. Naturally, with such an organization, on average, less external memory is spent on average, since duplicate values are not stored; in one exchange with external memory, in general, more useful information is read. An additional advantage is the ability to use the values of a relation column to optimize the execution of join operations. But this requires significant additional steps for assembling the whole tuple (or part of it).
Since row storage is much more common, we will look at this method of storing relationships in a little more detail. The typical, inherited from System R data page structure is as follows:
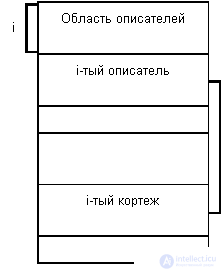
The main characteristics of this organization include the following:
- Each tuple has a unique identifier (tid) that is not changed during the entire existence of the tuple. The tid structure follows from the figure above.
- Usually each tuple is stored entirely in one page. From this it follows that the maximum length of a tuple of any relation is limited by the size of the page. The question arises: how to deal with the "long" data, which in principle do not fit in one page? Several methods are used. The simplest solution is to store such data in separate (outside the database) files, replacing the “long” data in the tuple with the name of the corresponding file. In some systems (for example, in the penultimate version of the Informix DBMS), such data was stored in a separate set of external memory pages linked by physical links. Both of these solutions severely limit the ability to work with long data (such as deleting a few bytes from the middle of a 2 MB line?). Nowadays, the method proposed several years ago in the Exodus project, when “long” data is organized in the form of B-trees of sequences of bytes, is increasingly used.
- As a rule, in one data page, tuples of only one relation are stored. There are, however, options with the possibility of storing several relationships in a single page of tuples. This causes some additional expenses in terms of service information (for each tuple, information about the appropriate relationship should be stored), but sometimes it allows drastically reducing the number of exchanges with external memory when making connections.
- Changing the schema of the stored relationship with the addition of a new column does not cause the need for physical reorganization of the relationship. It is enough to change the information in the relationship descriptor and expand the tuples only when entering information into the new column.
- Since relationships may contain null values, appropriate storage support is required. This is usually achieved by storing the appropriate scale for each tuple, which in principle may contain undefined values.
- The problem of memory allocation in data pages is associated with synchronization and logging problems and is not always trivial. For example, if during the execution of a transaction, some data page is empty, then it cannot be converted to the free status until the end of the transaction, because when a transaction is rolled back, the tuples deleted during the direct execution of the transaction and restored during its rollback should receive the same identifiers.
- A common way to increase the efficiency of a DBMS is to cluster the relationship according to the values of one or more columns. Useful for optimizing connections is the joint clustering of multiple relationships.
- In order to use the possibilities of parallelization of exchanges with external memory, sometimes the scheme of declustered storage of relations is used: tuples with the total value of the declustering column are placed on different disk devices, exchanges with which can be performed in parallel.
As for storing the column relation, the basic idea is to store all the values of one (or several) columns together. For each tuple of a relation, a tuple of the same degree is stored, consisting of references to the locations of the corresponding column values. In the last lecture, we will consider the features of the organization of distributed relational DBMS. One of the methods is the so-called vertical separation of relations, when different projections of this relationship are stored in different network nodes. Storing a column relationship is in a sense a limiting case of a vertical separation of ratios.
Previous chapter || Table of Contents || Next chapter

Comments
To leave a comment
Databases IBM System R - relational DBMS
Terms: Databases IBM System R - relational DBMS