Lecture
No matter how the indexes are organized in a specific DBMS, their main purpose is to ensure effective direct access to the relation tuple by key. Typically, an index is defined for a single relationship, and the key is the value of the attribute (possibly composite). If the index key is a possible relation key, then the index must have the uniqueness property, i.e. do not contain duplicate key. In practice, the situation usually looks the opposite: when declaring the primary key of a relationship, a unique index is automatically started, and the only way to declare a possible key other than the primary key is to explicitly create a unique index. This is due to the fact that in order to verify the preservation of the uniqueness property of a possible key, index support is somehow required.
Since many language-level operations require the relationship to be sorted according to the values of some attributes, a useful property of the index is to ensure that the tuples of a relationship are consistently viewed in a range of key values in ascending or descending order of key values.
Finally, one of the ways to optimize the performance of relationship equilibrium (the most common of the number of expensive operations) is the organization of so-called multi-indices for several relations that have common attributes. Any of these attributes (or a set of them) can act as a multi-index key. The key value is mapped to a set of tuples of all related multi-index relations, the values of the selected attributes of which coincide with the key value.
The general idea of any organization of an index that supports direct access by key and sequential browsing in ascending or descending order of key values is storing an ordered list of key values with a binding to each key value of a list of tuple identifiers. One organization of the index differs from the other mainly in the way of finding a key with a given value.
Apparently, the most popular approach to organizing indexes in databases is to use the B-tree technique. From the point of view of an external logical representation, a B-tree is a balanced, highly branched tree in external memory. Balance means that the length of the path from the root of the tree to any leaf is the same. Tree branching is a property of each tree node to refer to but a large number of child nodes. From the point of view of physical organization, a B-tree is represented as a multi-list structure of external memory pages, i.e. each node of the tree corresponds to a block of external memory (page). Internal and leaf pages usually have a different structure.
In a typical case, the structure of the inner page is as follows:
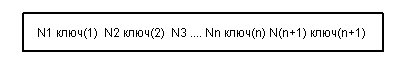
The following properties are maintained:
A leaf page usually has the following structure:
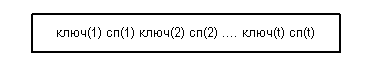
Sheet page has the following properties:
Search in a B-tree is the passage from the root to the leaf in accordance with the specified key value. Note that since trees are highly branched and balanced, to perform a search for any key value you will need the same (and usually small) number of exchanges with external memory. More precisely, in a balanced tree, where the lengths of all paths from root to leaf are the same, if n keys are placed in the inner page, then storing m records requires a tree of log n (m) depth, where log n calculates the logarithm of the base n . If n is large enough (the usual case), then the depth of the tree is small, and a quick search is performed.
The main "highlight" of B-trees is the automatic maintenance of the property of balance. Consider how this is done when performing entries and deletion of records.
When a new entry is made:
When deleting a record, the following actions are performed:
As you can see, when performing insertion and deletion operations, the B-tree balance property is preserved, and the external memory is consumed quite economically.
The problem is that splitting and merging may occur too often when performing modification operations. To achieve efficient use of external memory while minimizing the number of splits and merges, more sophisticated techniques are used, including:
It should be noted that the organization of multi-access to B-trees, which is typical when used in a DBMS, has to solve a number of non-trivial problems. Of course, coarse solutions are obvious, for example, the exclusive capture of a B-tree for the entire execution of a modification operation. But there are more subtle solutions, consideration of which is beyond the scope of our course.
And one final note on B-trees. In the literature, it is common to refer to the type of trees examined by us as B * or B + trees.
An alternative and increasingly popular approach to index organization is the use of hashing techniques. This is a very broad topic that deserves separate consideration. We confine ourselves to a few remarks. A common idea of hashing methods is to apply a convolution function (hash function) to a key value that produces a smaller value. The key value convolution is then used to access the entry.
In the simplest, classic case, the key convolution is used as an address in a table containing keys and records. The main requirement for the hash function is the uniform distribution of the value of convolution. In the event of collisions (the same convolution for several key values) overflow chains are formed. The main limitation of this method is the fixed size of the table. If the table is too full or overflowed, but there are too many overflow chains, and the main advantage of hashing - access to the record is almost always in one access to the table - will be lost. Expansion of the table requires its complete rework based on the new hash function (with a larger convolution value).
In the case of databases, such actions are completely unacceptable. Therefore, it is usual to introduce intermediate reference tables containing the key values and addresses of entries, and the entries themselves are stored separately. Then, when the directory overflows, only its reworking is required, which causes less overhead.
To avoid the need for complete rework of reference books, they often use B-tree technique with splits and merges when organizing them. The hash function changes dynamically depending on the depth of the B-tree. By means of additional technical tweaks, it is possible to achieve the preservation of the order of records in accordance with the key values. In general, B-tree and hashing methods are increasingly converging.

Comments
To leave a comment
Databases IBM System R - relational DBMS
Terms: Databases IBM System R - relational DBMS