Lecture
One of the basic requirements for any database management system is that the DBMS must reliably store databases. This means that the DBMS must maintain a means to restore the state of the databases after any possible failures. These failures include individual transaction failures (for example, dividing by zero in the application program that initiated the transaction); processor failure during the operation of the DBMS (so-called soft failures) and failures (breakdowns) of external media on which the databases are located (hard failures).
Situations arising from failures of each of the noted classes are different and, generally speaking, require different approaches to the organization of database recovery. Individual transaction failures mean that all changes made to a database by a transaction are illegal and must be corrected. To do this, you must perform an individual rollback of a transaction of the same type as when performing an RSS explicit RESTORE operation.
When a soft system failure occurs, the contents of the RAM are lost. Restoring the state of the database is that after it is completed, the database should contain all changes made by transactions that ended at the time of the failure, and should not contain any changes made by transactions that did not end at the time of the failure. An essential aspect of the situation is that the state of the database on the external memory is not destroyed, which makes it possible to make the recovery process not too long.
Hard failures lead to complete or partial loss of the contents of databases on external memory. However, the goal of the recovery process is the same as in the case of a soft failure: after this process is completed, the database should contain all changes made by transactions that ended at the time of the failure, and should not contain any changes made by transactions that did not end by malfunction. In the event of a hard failure, the only possible approach to restoring a database state may be based on using a previously made copy of the database. In general, the recovery process after a hard failure is significantly more complicated than after a soft failure.
System R recovery algorithms are based on two basic tools - logging and support for shadow segment states. Consider first the logging mechanism. We have already mentioned the presence of the magazine in the previous subsections. A log is a separate external memory file, for which two copies are usually maintained for reliability, and in which information is placed about all database state change operations. In the previous subsection, we mentioned the use of a log for rolling back a transaction using an explicit RESTORE operation or with implicit rollbacks when breaking deadlocks. The same scheme is used when rollbacks of individual transactions in case of failures.
The mechanism of individual rollback is based on the reverse implementation of all changes made by this transaction (undo). In this case, in the reverse chronological order, all records of database changes made on behalf of this transaction are selected. This requires the identification of all entries in the log. In System R, all records of a single transaction are linked into one list in the reverse order of chronological order. The link in the list is the address of the entry in the log file. Since the scheme of individual rollback is the same for all situations of individual failures, in particular for the situation of the destruction of dead ends, the reverse execution of operations is accompanied by the removal of the synchronization captures installed during direct operation of the database objects. Consequently, after performing an individual rollback of a transaction, the situation in the system is as if the transaction never began.
The specific nature of a soft system failure is the loss of the state of the RAM. In memory there are database buffers. Two kinds of buffers are supported: the log buffer and the database buffer itself. Log buffers contain the latest log entries. There are two log buffers. As soon as one buffer is completely filled, it is written to the log file and the filling of the second buffer continues. Thus, during normal operation of the system, exchanges with the log file do not lead to suspension of work. Database buffers contain copies of the database pages that have been used recently. Due to the usual principles of localization of links in programming, it is rather likely that after placing a copy of a database page in a buffer, this page will be required in the near future. Therefore, having a copy of the page in the buffer will allow you to avoid sharing with the external memory device the next time you need this page.
Note that the size of the DBMS buffer pool largely determines its performance. A conventional relational DBMS, such as System R, is sufficiently competitive with systems based on specialized hardware of database machines in the presence of a sufficient buffer pool size.
The task of System R is to ensure reliable completion of transactions, i.e. the guaranteed availability of the changes made by them in the database requires the presence in the external memory of information about these changes. To this end, at the end of any transaction, a guaranteed presence in the log file of all records of changes made by this transaction is maintained. When buffering is used for logging, it is sufficient to forcibly push the underfilled log buffer into external memory. By forcible pushing is meant writing a buffer to external memory in accordance with the logic of the end of the transaction, not with the logging logic. Only after such a violent ejection of the log buffer has been effected is the transaction considered complete. Note that the last log entry from any transaction modifying the database is the record of the end of the transaction. These records are used during recovery. Consider now (not quite exactly yet) how database recovery is performed after a soft failure.
The basis of the recovery algorithm is that the system adheres to the Write Ahead Log (WAL) rule. This rule means that when ejecting any page from the page buffer, it is first guaranteed that there is an entry in the log file related to changes to this page after it is pushed into the buffer. Since the log entries are blocked, to comply with the WAL rule, before pushing the data page, it is necessary to push out the underfilled log buffer if it contains an entry related to the page change. Applying the WAL rule ensures that if there is a database page in external memory, then the log file contains all the records of the operations that caused the change of this page. The reverse is not true: the log file may contain records about changes in some pages of the database, and these changes themselves may not be reflected in the page states in the external memory.
At the end of any transaction (i.e., performing the RSS END TRANSACTION operation), an underfilled log buffer is pushed out and thereby ensures that the journal contains full information about all changes made by this transaction. Forcibly pushing out the pages of the database buffer is not performed (it would be too costly to make such pushing at the end of any transaction). Thus, after a soft failure, the state of the database in external memory may not correspond to that which should be after the end of transactions. Consequently, after a soft failure, some pages in external memory may not contain information placed in them by already completed transactions, and other pages may contain information placed by transactions that were not completed by the time the failure occurred. When restoring, you need to add information in the pages of the first type and delete the information in the pages of the second type.
System R periodically sets system checkpoints. In more detail we will focus on this below. For now, we only note that when such a checkpoint is established, the log buffer and all page buffers are forcedly ejected into the external memory. This is an expensive operation, and it is rarely performed. For each system checkpoint, a special entry is placed in the log.
Suppose that the last system control point was set at time tc, and a mild failure occurred at some later time point tf. Then all system transactions can be divided into five categories.
T1 category transactions began and ended before tc. Consequently, all changes made by the database are reliably located in the external memory, and in relation to them no actions are required during restoration. T2 category transactions began before tc, but managed to end by the time of the soft failure tf. Changes made by such transactions after the tc time could not get into the external memory, and should be re-executed when restored. T3 category transactions began before tc, but did not end at the time of failure. All their changes made before tc, and possibly some changes made after tc, are contained in the external memory. When restoring, they must be removed. T4 category transactions began after the installation of the system checkpoint and managed to end before the failure. Their changes could not be displayed in external memory; when restoring, they must be re-executed. Finally, category T5 transactions began after tc and did not end at the time of failure. Their changes should be removed from pages in external memory.
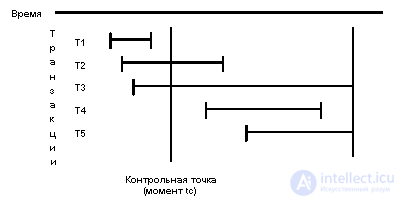
In principle, it would be possible to perform all the necessary recovery actions after a mild failure, based only on information from the log. However, in System R, the situation is somewhat simplified by the use of shadow page techniques. The principle of shadow pages has long been used in file systems that support paging files. In accordance with this principle, after opening a file for modification, modified pages are written to a new place in external memory (that is, free blocks of external memory are allocated for them). At the same time, the old (shadow) table of displaying the pages of a file into external memory is stored in external memory, and a new table is formed in RAM as the file changes. When a file is closed, the newly formed table is written to the external memory, forming a new shadow table, and the blocks of external memory containing the previous images of the file pages are released. When a processor fails, the state of the file in which it was before the last opening is automatically saved (of course, with the possible loss of some blocks of external memory, which are then collected using a special utility). The operations of explicitly fixing the current state of the file and explicitly rolling back the state of the file to the point of the last commit are allowed.
System R applies the development of the ideas of the shadow mechanism in the context of multi-accessible databases. As we have noted, the System R database segments are paged files. Accordingly, there are also tables of registration of these files in blocks of external memory. When performing the installation of the system checkpoint after pushing page buffers to the external memory, the tables of all segments are also recorded in the external memory, i.e. become shadowy. Further, up to the next checkpoint, access to the segment pages is made through the display tables located in the RAM, and each changeable page of any segment is written to the new external memory location with the correction of the corresponding current display table.
Then, if a mild failure occurs, all segments automatically go to the state corresponding to the last system control point, i.e. changes made after the establishment of this control point, they simply do not contain.
This greatly simplifies the recovery procedure after a mild failure. The system should not take any action at all with respect to changes in T5 type transactions: these changes are not in external memory. When restoring, it is enough to perform reverse changes of T3 type transactions (undo in System R terminology), re-perform changes of T2 type transactions (redo in System R terminology; note, by the way, these changes can now be performed unconditionally without worrying that perhaps, and so are contained in external memory). In addition, you just need to repeat the changes in T4 type transactions. Naturally, you should start the actions on the log with an entry about the last control point.
In fairness, we note that in fact the shadow mechanism is used in System R mainly not to simplify the recovery procedure after a mild failure. As we have already noted, this can be done without. The main reason is different, namely, that the recovery of the database can only begin from its physically consistent state. The fact is that the log contains information about changes in database objects, not pages. For example, a log can contain information about the modification of a tuple in the form of a triplet <tid, old tuple state, new tuple state>. In reality, while performing a modification operation, several pages change: the original page; possibly a replacement page if the tuple did not fit in the original page; index pages. And this happens when performing any database modification operation. Since page buffers are pushed out to external memory separately, by the time of a soft failure in external memory, a set of physically mismatched pages may occur, not corresponding to any journaling operation. Under this condition, the external memory cannot be recovered from the log.
When a system checkpoint operation is performed, the system waits until all operations of all transactions have been completed until the forced pushing out of page buffers and until new pushing is completed. Therefore, the shadow state of all database segments is physically consistent and can serve as a basis for log recovery.
In case of hard failures, the contents of all or part of the database segments are lost. To restore the database, a log and a previously generated copy of the database are used. Segment recovery is allowed on System R. To do this, a copy of the segment is copied from the archive media to the newly allocated working medium, and then all changes made in the objects of this segment after the moment of copying are repeated in the log. Since at the time of a hard failure the contents of the RAM are not lost, it is possible to continue the execution of transactions after the recovery is completed. Moreover, if the accident affected only a part of the database segments, then transactions against the recovery process can continue to work with database objects located in intact segments.
The only requirement for an archived copy of a segment is that it must be in a consistent state (since recovery is carried out in terms of log entries). Therefore, to create an archived copy of a segment, all you have to do is wait until the end of operations on the objects of this segment and prohibit the start of new operations until the end of copying. Thus, the execution of an archive copy does not require transferring the system to any special mode of operation and only slightly inhibits the normal operation of transactions.
In conclusion of this subsection, we note that in the first versions of System R, magnetic tapes were used as archival media. However, over time, it became clear that, firstly, the reliability of magnetic tapes is significantly less than the reliability of magnetic disks, and secondly, they began to yield in capacity. Therefore, in the latest versions of the system only disk memory was used.
And the last remark. The System R log is located in a file of large but constant size. It is used in cyclic mode. When journal entries reach the end of the file, they begin to be placed at its beginning. Since the transition to the beginning of the file can be considered the loss of the previous log, this transition is accompanied by copying the database segments. Some other systems use the archiving of the journal itself.

Comments
To leave a comment
Databases IBM System R - relational DBMS
Terms: Databases IBM System R - relational DBMS