Lecture
As we noted, the System R database is located in one or more external memory segments. Each segment consists of data pages and index information pages. The size of the data page in the segment can be chosen equal to either 4 or 32 kilobytes; The page size of the index information is 512 bytes. In addition, an additional set of logging data is supported with RSS. To improve the reliability of the journal (and this is the most critical information; if it is lost, database recovery after failures is impossible) this data set is duplicated on two external media.
Each data page stores tuples of one or more relationships. The fundamental concept of RSS is a tuple identifier (tid identifier - tid). Tid'a is guaranteed to be immutable throughout the existence of a tuple in the database, regardless of the movements of the tuple within the page and even when the tuple is moved to another page. In reality, tid is a pair of <page number, index of tuple descriptor in page>. In this case, the tuple can actually be located in this page:
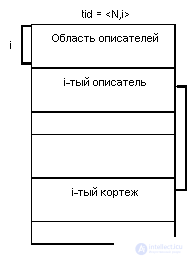
or in another page:
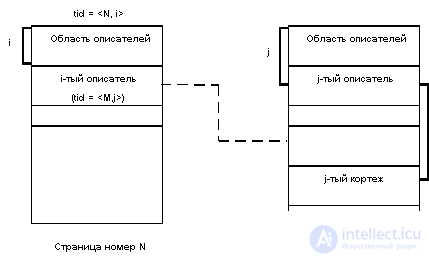
In the second case, the tuple handle does not contain the coordinates of the tuple in this page, but the tid indicating the real position of the tuple in another page. It is easy to see that the use of this approach allows us to limit ourselves to at most one level of indirection.
Since it is allowed to have different relationships in one page of these tuples, each tuple must, in addition to its content, include service information identifying the relationship to which the tuple belongs. In addition, in System R (more precisely, in the SQL language) dynamic fields can be added to existing relationships. In this case, only a modification of the relationship handle in relation to the relationship catalog takes place. In the existing relation tuple, a new field arises only when this tuple is modified, affecting a new field. This allows you to avoid mass restructuring of the stored relationship when adding new fields to it, but, of course, requires storing additional service information during the tuple, which determines the actual number of fields in this tuple. (Note that deleting existing fields of an existing relationship in SQL System R is not allowed).
Based on the presence of unchangeable tids during the existence of tuples in System R, additional control structures — indices — are supported. Each index is defined on one or several relationship fields whose values make up its key, and allows you to directly search for tuples (their tids) and sequentially scan an index relationship, starting with the specified key, in ascending or descending order of key values. Some indexes when they are created may have a unique attribute. In this index are not allowed duplicate key. This is the only SQL tool for specifying the primary key system of a relationship (in fact, a set of primary and all alternative relation keys).
To organize indexes in System R, the B-tree technique is used. Each index occupies a separate set of pages, the root page number is stored in the index descriptor. The use of B-trees allows to achieve efficiency in direct search, since they, due to their strong branching, have a small depth. In addition, B-trees preserve the order of the keys in the leaf blocks of the hierarchy, which allows sequential scanning of the relationship in ascending or descending order of the values of the fields on which the index is defined. The fundamental property of B-trees - automatic balancing of the tree - allows the product of only local modifications of the index with overflows and empty pages of the index. (We use the term B-tree quite loosely here. In fact, System R uses a modified version of B-trees compared to the original one, which is called B * -, and sometimes B + -trees). There is nothing special about the System R B-trees themselves; we will not dwell on this in more detail. We only note that System R, as far as we know, was the first system in which B-trees were used to organize indexes. This tradition is followed by most of the relational systems that emerged after System R.
Apparently, the most important feature of the physical organization of databases in System R is the ability to ensure the clustering of related tuples of one or more relationships. The clustering of tuples is the physically close location (within one data page) of logically related tuples. Providing appropriate clustering allows to achieve high system efficiency when performing a dedicated class of queries. Due to the great importance of the concept of clustering in System R and its developments, we consider the history of the issue in more detail.
In the final version of System R, there is only one means of determining the conditions for clustering a relationship — declare before filling a relationship one (and only one) index, defined in the fields of this relationship, is clustered. Then, if the relationship is filled with tuples in ascending or descending values of the clustering fields (depending on the attributes of the index), the system physically arranges the tuples in the data pages in the same order. In addition, some backup free space is left on each page of the clustered relation data. With subsequent insertions of tuples into this relationship, the system tends to place each tuple in one of the data pages that already contain tuples of this relationship with the same (or similar) values of the clustering fields. Naturally, the ideal clustering of relations can be maintained only up to a certain limit, until the backup memory in the pages is exhausted. Further than this limit, the degree of clustering of a relationship begins to decrease, and to restore the ideal clustering of a relationship, a physical reorganization of the relationship is required (it can be done using SQL tools).
The obvious advantage of clustering a relationship is that if you sequentially scan a clustered relationship using a clustered index, you only need as many reads of data pages from external memory as the tuples of this relationship take up. Therefore, with properly selected clustering criteria, queries related to the specification of conditions on the clustering fields can be performed almost optimally.
In earlier versions of System R, there was another way to physically access relation tuples and, accordingly, another way of specifying the condition of clustering using so-called links. At the level of the physical representation, a link is a physical link (tid) from one tuple to another (not necessarily one relation). In the SEQUEL language (until the moment when it became known as SQL) there were means of defining relationships in a hierarchical manner: it was possible to declare some relation as parent to relation to the same or another relation-descendant. At the same time, the fields of the parent relationship and the child relationship were specified, in accordance with the values of which a hierarchy was formed. The rules of construction were very simple - links were made between the tuple of the parent relation to all tuples of the child relationship with the same values of the binding fields. In fact, all tuples of a child relationship with the common value of the binding fields formed a ring list, on which one link was made from the corresponding tuple of the parent relationship. Naturally, the parent relationship was required to be unique with respect to the values of the binding fields.
It should be noted that we described the method of using the linkage mechanism, which was supported in earlier versions of SEQUEL. In the RSS System R interface of this period, the possibility of arbitrary linking was allowed without regard to the coincidence of the values of the binding fields. Thus, the system as a whole did not use all the possibilities of RSS, which more than surpassed the needs of organizing hierarchical binary links because of the coincidence of the binding fields.
For one relationship, the creation of many relationships was allowed: a relationship tuple could be the parent of several hierarchies and belong to several other hierarchies as a descendant. In this case, one link could be declared clustered. Then the system sought to put all the tuples of one hierarchy into one data page. In this case, of course, the possibility was used to place in one page these tuples of several relationships. The main point of such clustering was to optimize the execution of some queries, including (equi) combining two related relationships in accordance with the values of the binding fields.
In later publications on System R, references to the linkage mechanism disappeared, from which we can conclude that the developers refused to use it. It seems that the main reasons for not using links were the following. First, the link building tools provided by RSS were of a very low level, much lower than the index maintenance tools. If, when entering a tuple, RSS provided automatic correction of all indices, then, to correct links, a number of additional calls to RSS were required, which resulted in an increase in the operation of entering a tuple, of course, increased (the same applies to deletion and modification of the tuple). Secondly, when implementing this mechanism, additional synchronization problems of the lower level (the level of joint access to data pages) arise. In particular, the presence of direct links between data pages increases the likelihood of synchronization deadlocks. Finally, thirdly, all these additional overheads were not paid off by the advantages provided by the communication mechanism. Indeed, the maximum effect of using links can be achieved only when performing the join operation of two relationships clustered on this link, if the join field coincides with the binding field, and the conditions imposed on the parent relation are exactly one tuple in it. Obviously, such requests in practice are rare. (Note that these considerations belong to the author and were not described in System R publications, so in fact there could be other reasons.)
In addition to relations and indexes, when System R is running, temporary objects - lists (lists) can also be located on external memory. A list is an instant snapshot of some sample with a projection of the tuples of one relation, possibly ordered according to the values of some fields. Tools for working with lists are available in the RSS interface, but, of course, they are not in SQL. Accordingly, these tools are used only inside the system when executing queries (in particular, one of the most efficient algorithms for performing connections is based on using sorted lists of tuples). Publications on System R do not provide an accurate picture of the data structures used in organizing lists, but from common sense, it can be assumed that they are not structured like relationships (for example, for a tuple included in the list, tid addressing is not required) and that they are located in temporary files (in the event of a system failure, all temporary objects disappear).

Comments