Lecture
Modern hard drive - a unique component of the computer. It is unique in that it stores service information in itself, by studying which you can evaluate the "health" of the disc. This information contains the history of changes in the set of parameters monitored by the hard drive during operation. No other component of the system unit provides the owner with statistics of their work! Coupled with the fact that HDD is one of the most unreliable components of a computer, such statistics can be very useful and help its owner avoid the hassle and waste of money and time.
Information about the state of the disk is available through a set of technologies called the common name SMART (Self-Monitoring, Analisys and Reporting Technology, that is, the technology of self-monitoring, analysis and reporting). This complex is quite extensive, but we will talk about those aspects of it that allow you to look at the SMART attributes displayed in any hard drive testing program and understand what is happening with the disk.
I note that the following applies to drives with SATA and PATA interfaces. SAS, SCSI and other server disks also have SMART, but its presentation is very different from SATA / PATA. Yes, server disks are usually monitored not by a human, but by a RAID controller, therefore we will not talk about them.
So, if we open SMART in any of the numerous programs, we will see approximately the following picture (the screenshot shows the SMART Hitachi Deskstar 7K1000 disk. From HDS721010CLA332 in HDDScan 3.3):
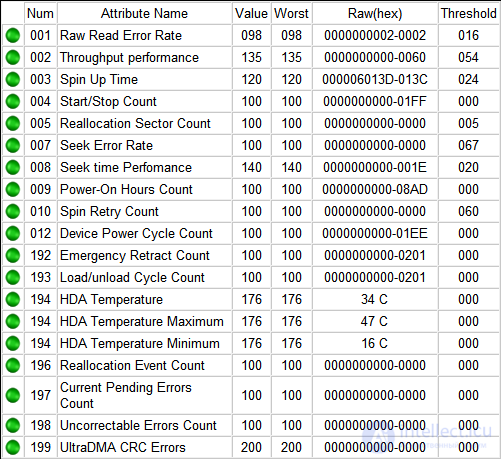
SMART to HDDScan 3.3
To check the smart parameters in linux ubunutu from the command line, you can use the command
smartctl -a / dev / sda smartctl -a / dev / sdb
etc..
the result of this command will be approximately the following
=== START OF INFORMATION SECTION ===
Device Model: MB1000EBNCF
Serial Number: WMAW30411327
LU WWN Device Id: 5 0014ee 206954b20
Firmware Version: HPG2
User Capacity: 1,000,204,886,016 bytes [1.00 TB]
Sector Size: 512 bytes logical / physical
Vendor Specific SMART Attributes with Thresholds:
ID # ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 142
3 Spin_Up_Time 0x0027 175 173 021 Pre-fail Always - 4241
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 47
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 13
7 Seek_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0
9 Power_On_Hours 0x0032 072 072 000 Old_age Always - 20583
10 Spin_Retry_Count 0x0033 100 253 051 Pre-fail Always - 0
11 Calibration_Retry_Count 0x0033 100 253 051 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 44
180 Unknown_HDD_Attribute 0x002f 200 200 100 Pre-fail Always - 0
184 End-to-End_Error 0x0033 100 100 097 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 095 000 Old_age Always - 13
188 Command_Timeout 0x0032 100,096,000 Old_age Always - 8
190 Airflow_Temperature_Cel 0x0022 070 061 045 Old_age Always - 30
192 Power-Off_Retract_Count 0x0032 200,200,000 Old_age Always - 39
193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 7
194 Temperature_Celsius 0x0022 117 108 000 Old_age Always - 30
195 Hardware_ECC_Recovered 0x0036 200 200 000 Old_age Always - 0
196 Reallocated_Event_Count 0x0032 188 188 000 Old_age Always - 12
197 Current_Pending_Sector 0x0032 199 199 000 Old_age Always - 194
198 Offline_Uncorrectable 0x0030 199 199 000 Old_age Offline - 191
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 199 199 000 Old_age Offline - 207
Each line displays a separate SMART attribute. Attributes have more or less standardized names and a certain number that do not depend on the model and manufacturer of the disk.
Each SMART attribute has several fields. Each field belongs to a specific class of the following: ID, Value, Worst, Threshold, and RAW. Consider each of the classes.
This is what we are going to do now - let's look at all the most used SMART attributes, see what they say and what to do if they are not in order.
| SMART attributes | |||||||||||||||||
| 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | ten | eleven | 12 | 183 | 184 | 187 | 188 | 189 | 190 | |
| 0x | 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 0A | 0B | 0C | B7 | B8 | BB | BC | Bd | BE |
| 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 220 | 240 | 254 | ||
| 0x | Bf | C0 | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | Ca | CB | DC | F0 | FE | |
Before describing the attributes and valid values of their RAW field, I’ll clarify that attributes can have a different type of RAW field: current and accumulative. The current field contains the value of the attribute at the moment, it is typical for it to periodically change (for some attributes it is rare, for others it happens many times in a second; another thing is that this fast change is not displayed in SMART reading programs). Accumulating field - contains statistics, usually it contains the number of occurrences of a specific event since the first launch of the disk.
The current type is characteristic of attributes for which there is no point in summarizing their previous readings. For example, the disk temperature indicator is current: its goal is to show the temperature at the moment, and not the sum of all previous temperatures. The accumulating type is peculiar to attributes, for which their whole meaning is to provide information for the entire period of the hard drive's “life”. For example, an attribute that characterizes the disk operation time is accumulating, that is, it contains the number of units of time that a drive has worked through its entire history.
Let us proceed to the consideration of attributes and their RAW-fields.
Attribute: 01 Raw Read Error Rate
| Type of | current may be accumulating for WD and old Hitachi |
| Description | contains the error rate when reading from the plates |
All Seagate, Samsung discs (starting with the SpinPoint F1 family (inclusive)) and Fujitsu 2.5 ″ have huge numbers in these fields.
For the remaining Samsung drives and all WD drives in this field, 0 is typical.
For Hitachi drives, this field is characterized by 0 or periodic field changes in the range from 0 to several units.
Such differences are due to the fact that all Seagate hard drives, some Samsung and Fujitsu consider the values of these parameters differently from WD, Hitachi and other Samsung. When any hard drive works, errors of this kind always occur, and it overcomes them on its own, this is normal, just on the disks that contain 0 or a small number in this field, the manufacturer did not consider it necessary to indicate the true number of these errors.
Thus, the non-zero parameter on the WD and Samsung disks to SpinPoint F1 (not inclusive) and the large parameter value on the Hitachi disks can indicate hardware problems with the disk. It is necessary to take into account that utilities can display several values contained in the RAW field of this attribute as one, and it will look very large, although this will be incorrect (see details below).
On the Seagate, Samsung (SpinPoint F1 and newer) and Fujitsu drives, you can ignore this attribute.
Attribute: 02 Throughput Performance
| Type of | current |
| Description | contains the value of the average performance of the disk and is measured in some "parrots". Usually its non-zero value is noted on Hitachi hard drives. On them, it can change after changing the parameters of AAM, and maybe by itself using an unknown algorithm. |
The parameter does not give any information to the user and does not speak about any danger for any of its value.
Attribute: 03 Spin-Up Time
| Type of | current |
| Description | contains the time during which the spindle of the disk was last accelerated from a state of rest to the rated speed. It may contain two values - the last and, for example, the minimum time of promotion. It can be measured in milliseconds, tens of milliseconds, etc. - it depends on the manufacturer and model of the disk. |
Acceleration time may vary for different disks (and for disks of the same manufacturer too) depending on the spinning current, weight of pancakes, nominal spindle speed, etc.
By the way, Fujitsu hard drives always have a unit in this field in the absence of problems with the spindle promotion.
Virtually nothing says about the health of the disk, so when assessing the state of the hard drive on the parameter you can not pay attention.
Attribute: 04 Number of Spin-Up Times (Start / Stop Count)
| Type of | accumulating |
| Description | contains the number of times the disk has been turned on. It happens to be non-zero on a disk that was just bought, which was in a sealed package, which can speak of testing a disk at the factory. Or something else that I don’t know :) |
When assessing health, do not pay attention to the attribute.
Attribute: 05 Reallocated Sector Count
| Type of | accumulating |
| Description | contains the number of sectors reassigned by the hard drive to the backup area. Practically key parameter in assessing the state |
Let us explain what the “reassigned sector” is. When a disk encounters an unreadable / poorly readable / non-writable / poorly written sector in the course of work, it may consider it irreparably damaged. Especially for such cases, the manufacturer provides on each disc (on some models - in the center (logical end) of the disc, on some - at the end of each track, etc.) a spare area. If there is a damaged sector, the disk marks it as unreadable and instead uses a sector in the backup area, making the appropriate marks in the special list of surface defects - G-list. Such an operation to assign a new sector to the role of the old one is called remap (remap) or reassignment , and the sector used instead of the damaged one is reassigned . The new sector receives the logical LBA number of the old one, and now when the software accesses the sector with this number (the programs are not aware of any reassignments!), The request will be redirected to the backup area.
Thus, even though the sector has failed, the disk volume does not change. It is clear that it does not change for the time being, since the volume of the reserve area is not infinite. However, the reserve area may well contain several thousand sectors, and to allow it to end is very irresponsible — the disk will need to be replaced long before that.
By the way, repairmen say that Samsung discs very often don’t want to reassign sectors.
Opinions differ on this attribute. Personally, I think that if it has reached 10, the disk must be changed - this means a progressive process of degradation of the surface state of either pancakes, or heads, or something else hardware, and there is no longer possible to stop this process. By the way, according to those close to Hitachi, Hitachi itself considers the disk to be replaced when there are already 5 reassigned sectors on it. Another question is whether this information is official and whether the service centers follow this opinion. Something tells me that no :)
Another thing is that service center employees may refuse to recognize the disk as defective if the proprietary utility of the disk manufacturer writes something like “SMART Status: Good” or the Value or Worst attribute values are greater than Threshold (actually, the utility itself can evaluate by this criterion manufacturer). And formally they will be right. But who needs a drive with a constant deterioration of its hardware components, even if such a deterioration corresponds to the nature of the hard drive, and the production technology of hard drives tries to minimize its consequences, highlighting, for example, a spare area?
Attribute: 07 Seek Error Rate
| Type of | current |
| Description | contains the frequency of errors in the positioning of a block of magnetic heads (BMG) |
The description of the formation of this attribute almost completely coincides with the description for the attribute 01 Raw Read Error Rate, except that for Hitachi hard drives the normal value of the RAW field is only 0.
Thus, the attribute on the Seagate, Samsung SpinPoint F1 and newer disks and Fujitsu 2.5 ″ ignore, on other Samsung models, as well as on all WD and Hitachi, a non-zero value indicates problems, for example, with a bearing, etc. .
Attribute: 08 Seek Time Performance
| Type of | current |
| Description | contains the average performance of head positioning operations, measured in “parrots”. Like the 02 Throughput Performance parameter, a non-zero value is usually marked on Hitachi disks and may change after changing the AAM parameters, or maybe by itself using an unknown algorithm. |
It does not give any information to the user and does not speak about any danger at any value.
Attribute: 09 Power On Hours Count (Power-on Time)
| Type of | accumulating |
| Description | contains the number of hours during which the hard drive was turned on |
The number of hours in the on state. It is not directly related to the health of the disc but is indirectly related. With very small or very large number of hours there is a high probability of disk failure.
Reaching the limit value of this attribute means that the drive produces a MTBF (Mean Time Between Failures).
What does mean time between failures mean? For hard drives there are values from 600-700 thousand hours to 2 million. Consider, for example, a WD Red disc with a MTBF of a million hours. Does the manufacturer guarantee the disk for 1000000/8760 = 114 years and you can not worry about anything?
Not at all. The MTBF value (in the case of HDD it would be better to use MTTF - mean time to failure) cannot be applied to a single product, this is a statistical indicator. Here is what Hitachi writes about this:
The calculation of the MTBF is based on the statistical operating conditions. MTBF ratings are not intended to be an individual drive's reliability. MTBF does not constitute a warranty.
This means that more than one disk will work for 114 years, and in a batch of 114 disks in 1 year we can expect the failure of one disk. In practice, of course, it is more convenient to operate with a value not of MTBF, but of AFR (the annual failure rate is the annual failure rate). A simplified formula (if you do not take into account the specifics of the distribution of failure rates) looks like this:
AFR = 1 / (MTBF / 8760)
Those. for the same WD Red, we get an AFR value of about 0.88%, and it will be valid only in a small area on the graph of the probability of failure. After 2-3 years of working in a regular HDR mode for this class, the AFR will grow non-linearly. And what will happen if the mode is different from the regular one (for example, when the temperature is exceeded, the level of vibrations or round-the-clock operation of Seagate consumer drives for which the manufacturer recommends 8x5 mode of operation), and what generally happens in reality? After all, all these are theoretical calculations, maybe stories that “here in my house old Maxtor has been working for almost ten years without a single bad” can you extrapolate? Here is a chart from the famous Google report:
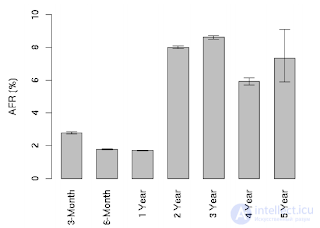
It illustrates annual hard drive failure statistics. The sharp increase in the AFR value after one year of work is due to the fact that Google used household drives in 24x7 mode (it was the first half of the 2000s, the nearline class did not exist yet). The result: almost two percent in the first year, then a rise to more than eight percent, which is the result of increased workload. By the way, here is the distribution of AFR depending on the loading of the disks:
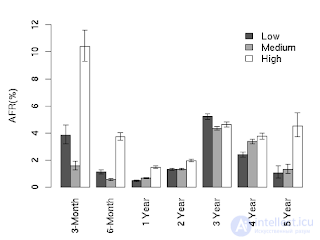
As can be seen from the graph, heavy operating modes dramatically increase AFR, especially in the first months of operation, when a high load helps to identify discs with hidden manufacturing defects, and after four years, when the load finishes off worn discs.
Pay attention to the specification of modern Seagate consumer drives: MTBF 700,000 hours, with the parameter Power-On Hours (POH) 2400 hours per year, which roughly corresponds to the 8x5 mode of operation. Those. the manufacturer promises compliance with the MTBF declared only subject to this mode of operation. Want 24/7 Seagate desktop operation? Get an AFR of 8% instead of 1.25%. There is one more clarification in the manual:
Average rate of <55TB / year. The MTBF specification for the workload does not exceed the average annualized workload rate limit of 55TB / year.
Those. traffic is also limited, if you can read / write no more than 55TB per year. Not satisfied? Use nearline class discs with MTBFs of 1.2 million hours and unlimited Power-On Hours.
By the way, in general, the statistics provided by Google correspond to the classic failure distribution schedule. Because of its characteristic form, it is also called bathtub curve :
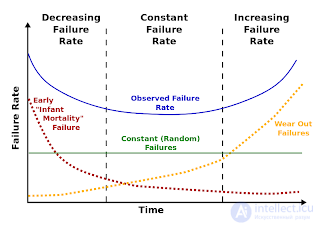
At the very beginning there is a large number of failures of products with hidden manufacturing defects, the so-called. "infant mortality". Then the frequency of failures stabilizes for the period of the product’s service life, and then the wear begins to show - the failures are nonlinearly growing.
Findings:
Statistics is a stubborn thing. Do not confuse MTBF and service life. Treat drives as consumables; plan a replacement for high-end desktop and nearline drives for servers that work three to four years. You can count on AFR of the order of 1% for nearline disks, about 0.5% for the enterprise class (10k / 15k), of course, only during the service life and subject to all operating conditions. With desktop drives with high loads, nothing can be guaranteed at all: temperature, vibration (in large disk shelves, vibration becomes important), the increased load on the head unit will do its job, and you can get a massive case of disks after a year of work.
Is it possible to use household disks in servers at all if Google did this? The thing is exactly how to use. Google is a cloud technology. In terms of data storage, this means using a distributed file system, in this case GFS, the Google File System. Parallels Cloud Storage, for example, has a similar architecture. Data is divided into blocks (chunks) of several megabytes in size, these blocks are replicated between several servers. Metadata servers store block allocation information and control the process of reading and writing blocks. This approach solves one of the problems associated with the operation of consumer disks — the relatively high probability of unrecoverable error rate occurring, which leads to great difficulties when working in RAID arrays.
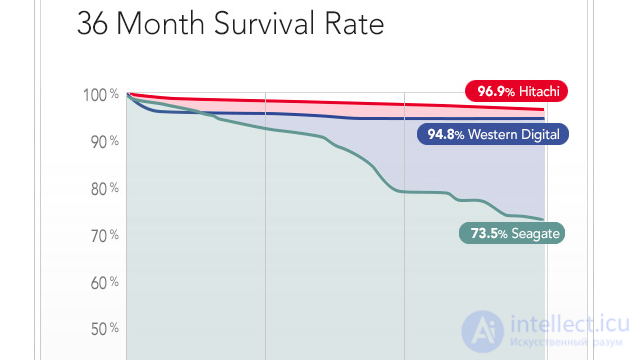
Comparison between Seagate, Hitachi and Western Digital.
Attribute: 10 (0A - in hexadecimal numbering system) Spin Retry Count
| Type of | accumulating |
| Description | contains the number of spindle start retries if the first attempt failed |
On the health of the disc often does not say.
The main reasons for the increase in the parameter are bad contact of the disk with the power supply unit or the inability of the power supply unit to deliver the required current to the power line of the disk.
Ideally, it should be equal to 0. If the value of the attribute is 1-2, attention can be ignored. If the value is greater, first of all, pay close attention to the state of the power supply, its quality, the load on it, check the hard drive's contact with the power cable, check the power cable itself.
Surely the disk may not start immediately because of problems with it, but this happens very rarely, and this possibility should be considered as the last thing.
Attribute: 11 (0B) Calibration Retry Count (Recalibration Retries)
| Type of | accumulating |
| Description | contains the number of repeated attempts to reset the drive (installation of BMG on the zero track) upon unsuccessful first attempt |
A non-zero, and especially increasing parameter value may indicate disk problems.
Attribute: 12 (0C) Power Cycle Count
| Type of | accumulating |
| Description | contains the number of complete cycles "on-off" disk |
Not related to the state of the disk.
Attribute: 183 (B7) SATA Downshift Error Count
| Type of | accumulating |
| Description | contains the number of unsuccessful attempts to lower the SATA mode. The bottom line is that a hard drive operating in SATA 3 Gb / s or 6 Gb / s modes (and that there will be more in the future), for some reason (for example, due to errors) may try to "agree" with the disk the controller is about a lower speed mode (for example, SATA 1.5 Gb / s or 3 Gb / s, respectively). In the event of a "failure" of the controller to change the mode the disk increases the value of the attribute |
Does not speak about drive health.
Attribute: 184 (B8) End-to-End Error
| Type of | accumulating |
| Description | contains the number of errors that occurred during data transmission through the hard drive cache |
A non-zero value indicates a disk problem.
Attribute: 187 (BB) Reported Uncorrected Sector Count (UNC Error)
| Type of | accumulating |
| Description | contains the number of sectors that have been recognized as candidates for reassignment (see attribute 197) for the entire life history of the disk. And if the sector becomes a candidate again, the value of the attribute also increases |
A non-zero attribute value clearly indicates an abnormal state of the disk (in combination with a non-zero attribute value 197) or that it was previously (in combination with a zero value 197).
Attribute: 188 (BC) Command Timeout
| Type of | accumulating |
| Description | contains the number of operations that were canceled due to exceeding the maximum allowed response timeout |
Such errors can occur due to poor cable quality, contacts, used adapters, extension cords, etc., as well as due to the incompatibility of the drive with a specific SATA / PATA controller on the motherboard (or discrete). Because of errors of this kind, BSOD is possible in Windows.
A non-zero attribute value indicates a potential disk “disease”.
Attribute: 189 (BD) High Fly Writes
| Type of | accumulating |
| Description | contains the number of recorded cases of recording when the flight height of the head is higher than the calculated one, most likely due to external influences, such as vibration |
In order to say why such cases occur, you need to be able to analyze the SMART logs, which contain information specific to each vendor that is not currently implemented in publicly available software — hence, you can ignore the attribute.
Attribute: 190 (BE) Airflow Temperature
| Type of | current |
| Description | contains the temperature of the hard drive for drives Hitachi, Samsung, WD and the value of “100 - [RAW attribute value 194]” for Seagate |
Does not indicate the status of the disk.
Attribute: 191 (BF) G-Sensor Shock Count (Mechanical Shock)
| Type of | accumulating |
| Description | contains the number of critical accelerations recorded by the disk electronics to which the drive was subjected and which exceeded the allowable ones. Usually this happens with bumps, falls, etc. |
Relevant for mobile hard drives. On Samsung disks, you can often ignore it, since they can have a very sensitive sensor, which, figuratively speaking, reacts almost to the movement of air from the wings of a fly flying in the same room with the disk.
In general, triggering the sensor is not a sign of shock. It can even grow from the positioning of BMG by the disk itself, especially if it is not fixed. The main purpose of the sensor is to stop the recording operation during vibrations in order to avoid errors.
Does not speak about the health of the disk.
one
Today, when choosing a laptop in the technical specifications, you will surely find such a parameter as a hard disk accelerometer (it is also often called a G-sensor). Unintelligent customers immediately have a logical question: what is it and why do we need an accelerometer in a laptop?
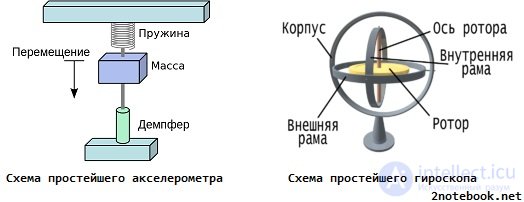
Scheme accelerometer and mechanical horoscope
Let's try to abstract from abstruse phrases with which Wikipedia is replete, and we will explain the essence of the device operation in simple language. The definition can be formulated as follows: an accelerometer is a device that measures the acceleration of an object relative to the gravitational acceleration of the Earth. For example, if an object, in our case a laptop, starts falling from the table to the floor, the accelerometer detects a sharp acceleration, which is not typical for normal operation, and includes protective mechanisms against damage.
As you know, hard drives that store data on computers are fairly fragile devices. If the laptop is dropped or hit hard, damage to the hard disk is very likely. The head of the HDD drive is constantly moving along disk sectors, reading information. In response to a sudden change in acceleration, the Winchester control system gives the command to park the hard disk head, preventing possible damage and data loss.
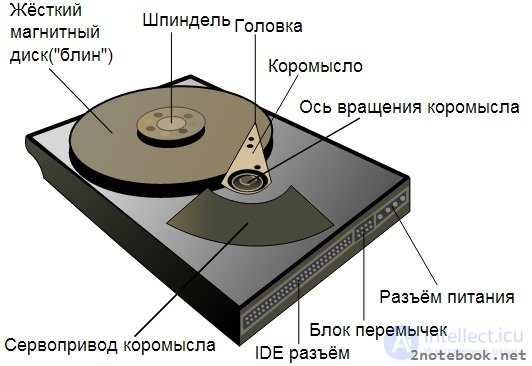
Hard disk drive

example of protection operation upon detection of increased acceleration of the G-sensor hard disk
Attribute: 192 (C0) Power Off Retract Count (Emergency Retry Count)
| Type of | accumulating |
| Description | for different hard drives, it can contain one of the following two characteristics: either the total number of parking spaces on a BMD disk in emergency situations (by a signal from a vibration sensor, breakage / power down, etc.), or the total number of power cycles on / off the disk (typical for modern WD and Hitachi) |
Does not allow to judge the status of the disk.
Attribute: 193 (C1) Load / Unload Cycle Count
| Type of | accumulating |
| Description | contains the number of complete parking / unparking cycles. Analysis of this attribute is one of the ways to determine whether the automatic parking function is on the disk (so beloved, for example, by Western Digital): if its content exceeds (usually - many times) the content of attribute 09 - the number of hours worked - then parking is enabled |
Does not speak about the health of the disk.
Attribute: 194 (C2) Temperature (HDA Temperature, HDD Temperature)
| Type of | current / accumulative |
| Description | contains the current disk temperature. The temperature is read from the sensor, which can be located in different places on different models. The field along with the current one can also contain the maximum and minimum temperatures recorded during the entire operation of the hard drive. |
The attribute does not indicate the status of the disk, but allows you to control one of the most important parameters. My opinion: when working, try not to allow the temperature of the hard drive to rise above 50 degrees, although the manufacturer usually declares the maximum temperature limit of 55-60 degrees.
Attribute: 195 (C3) Hardware ECC Recovered
| Type of | accumulating |
| Description | contains the number of errors that were corrected by hardware ECC disk |
The features inherent in this attribute on different disks fully correspond to those of attributes 01 and 07.
Attribute: 196 (C4) Reallocated Event Count
| Type of | accumulating |
| Description | contains the number of sector reassignment operations |
Indirectly talking about the health of the disk. The greater the value, the worse. However, it is impossible to unambiguously judge the health of the disk by this parameter without considering other attributes.
This attribute is directly related to attribute 05. With growth 196 most often grows and 05. If attribute 05 does not grow with attribute 196 growth, it means that when trying to remap the candidate for bad blocks turned out to be soft-bad (see details below), and corrected it, so the sector was deemed healthy, and there was no need to reassign.
If attribute 196 is less than attribute 05, it means that during some operations of reassignment, several damaged sectors were transferred at one time.
If attribute 196 is greater than attribute 05, it means that after some reassignment operations, the subsequently corrected soft bed were found.
Attribute: 197 (C5) Current Pending Sector Count
| Type of | current |
| Description | contains the number of candidate sectors for reassignment to the reserve area |
Current Pending Sector Count - The current number of unstable sectors. The raw value field of this attribute indicates the total number of sectors that the drive currently considers candidates for reassignment to the reserve area (remap). If in the future one of these sectors is read successfully, then it is excluded from the list of candidates. If the reading of the sector will be accompanied by errors, the drive will try to recover the data and transfer it to the backup area, and mark the sector itself as remapped.
Bumping into the “bad” sector in the course of work (for example, the sector checksum does not match the data in it), the disk marks it as a candidate for reassignment, puts it into a special internal list and increases parameter 197. It follows that damaged sectors, which he still doesn’t know about - there may well be areas on the plates that the hard drive doesn’t use for some time.
When attempting to write to a sector, the disk first checks whether the sector is in the list of candidates. If the sector is not found there, the recording goes on as usual. If found, this sector is tested by writing and reading. If all test operations are normal, then the disk considers that the sector is healthy. (Ie, there was the so-called “soft-bad” - the erroneous sector arose not due to the fault of the disk, but for other reasons: for example, at the moment of recording the information the electricity went off, and the disk interrupted the recording, parked the BMG. As a result, the data in the sector will be unfinished, and the sector checksum, depending on the data in it, will generally remain old. There will be a discrepancy between it and the data in the sector.) In this case, the disk performs the originally requested record and removes the sector from the list of candidates. In this case, the attribute 197 decreases, it is also possible to increase the attribute 196.
If testing fails, the disk performs a reassignment operation, reducing attribute 197, increasing 196 and 05, and also marks in the G-list.
So, a non-zero value of the parameter indicates a problem (although it cannot say whether the disk itself has a problem).
If the value is nonzero, it is necessary to start sequential reading of the entire surface with the remap option in the Victoria or MHDD programs. Then, when scanning, the disk will necessarily hit the bad sector and try to write to it (in the case of Victoria 3.5 and the Advanced remap option, the disk will try to record the sector up to 10 times). Thus, the program will provoke the “treatment” of the sector, and as a result, the sector will either be corrected or reassigned.
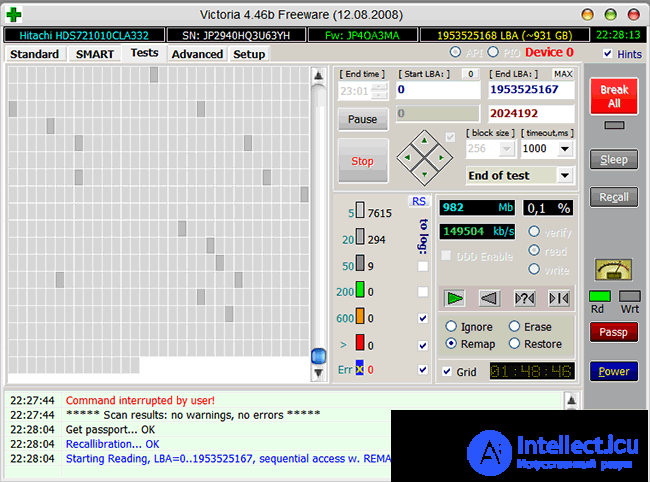
There is a consistent reading with REMAP in Victoria 4.46b
In case of failure to read with both remap and Advanced remap , it is worth trying to start a sequential write in the same Victoria or MHDD. Be aware that the write operation erases the data, so be sure to backup before using it!
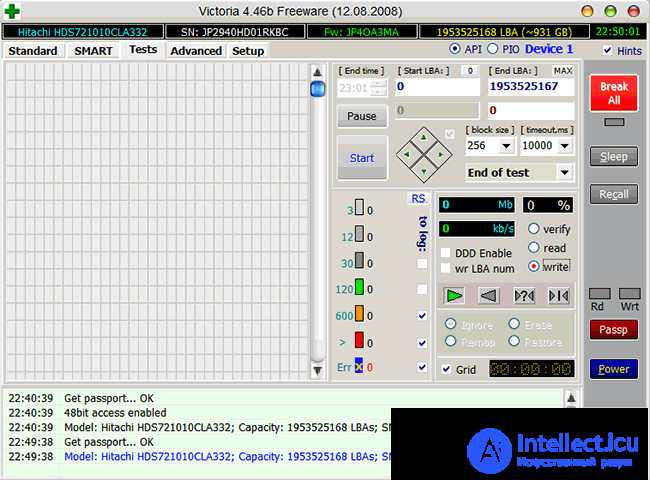
Starting sequential recording in Victoria 4.46b
Sometimes the following manipulations can help against the failure of a remap: remove the disk electronics board and clean the hard disk drive contacts connecting it to the board - they can be oxidized. Be careful when performing this procedure - because of it you can lose the warranty!
The impossibility of REMAP can be due to another reason - the disk has exhausted the backup area, and it simply has nowhere to reassign the sectors.
If the value of the attribute 197 is not reduced by any manipulations to 0, you should think about replacing the disk.
Attribute: 198 (C6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
| Type of | current |
| Description | means the same as attribute 197, but the difference is that this attribute contains the number of candidate sectors found in one type of disk self-testing — offline testing, which the disk launches into idle time in accordance with the parameters specified by the firmware |
This parameter is changed only under the influence of offline testing, no scanning program does not affect it. During operations during self-testing, the behavior of the attribute is the same as the attribute 197.
A non-zero value indicates a problem on the disk (just like 197, without specifying who is to blame).
Attribute: 199 (C7) UltraDMA CRC Error Count
| Type of | accumulating |
| Description | contains the number of errors that occurred during transmission via the interface cable in UltraDMA mode (or its emulation by SATA hard drives) from the motherboard or a discrete controller to the disk controller |
In the overwhelming majority of cases, poor-quality data transmission cable, PCI / PCI-E bus overclocking of the computer, or poor contact in the SATA connector on the disk or on the motherboard / controller become the causes of errors.
Errors during transmission via the interface and, as a result, the growing attribute value may cause the operating system to switch the mode of the channel on which the drive is in to PIO mode, which causes a sharp drop in the read / write speed when working with it and processor load up to 100% (seen in Windows Task Manager).
In the case of the Hitachi hard drives of the Deskstar 7K3000 and 5K3000 series, the growing attribute may indicate incompatibility between the drive and the SATA controller. To remedy the situation, you need to force such a drive to SATA 3Gb / s mode.
My opinion: in the presence of errors - reconnect the cable from both ends; if their number grows and it is more than 10 - throw out the cable and put a new one in its place or remove the overclocking.
We can assume that the attribute does not speak about the health of the disk.
Attribute: 200 (C8) Write Error Rate (MultiZone Error Rate)
| Type of | current |
| Description | contains the recording error rate |
A non-zero value indicates problems with the disk — in particular, for WD disks, large numbers can mean “dying” heads.
Attribute: 201 (C9) Soft Read Error Rate
| Type of | current |
| Description | contains the frequency of read errors that occurred due to software fault. |
Health effects unknown.
Attribute: 202 (CA) Data Address Mark Error
| Type of | unknown |
| Description | Attribute content is a mystery, but after analyzing various disks, I can state that a nonzero value is bad |
Attribute: 203 (CB) Run Out Cancel
| Type of | current |
| Description | contains the number of ECC errors |
Health effects unknown.
Attribute: 220 (DC) Disk Shift
| Type of | current |
| Description | contains measured in unknown units shear disk plates relative to the spindle axis |
Health effects unknown.
Attribute: 240 (F0) Head Flying Hours
| Type of | accumulating |
| Description | contains the time spent on positioning BMG. The counter can contain several values in one field. |
Health effects unknown.
Attribute: 254 (FE) Free Fall Event Count
| Type of | accumulating |
| Description | contains recorded by the electronics of the acceleration of the free fall of the disk to which it was subjected, i.e., simply put, shows how many times the disk has fallen |
Health effects unknown.
Summarize the description of the attributes. Non-zero values :
When analyzing attributes, keep in mind that several parameters of SMART can store several values of this parameter: for example, for the penultimate launch of the disk and for the latter. Such parameters with a length of several bytes logically consist of several values with a length of fewer bytes - for example, a parameter storing two values for the last two launches, each of which has 2 bytes, will have a length of 4 bytes. Programs that interpret SMART often do not know about it, and show this parameter as one number rather than two, which sometimes leads to confusion and excitement of the disk owner. For example, “Raw Read Error Rate”, storing the penultimate value of “1” and the last value of “0”, will look like 65536.
It should be noted that not all programs are able to correctly display such attributes. Many just translate an attribute with several values into the decimal number system as one huge number. Correctly display such content - either by splitting into values (then the attribute will consist of several separate numbers), or in hexadecimal numbering system (then the attribute will look like one number, but its components will be easily distinguishable at first glance), or , and another at the same time. Examples of correct programs are HDDScan, CrystalDiskInfo, Hard Disk Sentinel.
Let's demonstrate the differences in practice. This is what the instant value of the attribute 01 on one of my Hitachi HDS721010CLA332 looks like in the non-recognizable features of this attribute Victoria 4.46b:

Attribute 01 in Victoria 4.46b
And this is what it looks like in the “correct” HDDScan 3.3:

Attribute 01 in HDDScan 3.3
The advantages of HDDScan in this context are obvious, isn't it?
If you analyze SMART on different disks, you can see that the same attributes can behave differently. For example, some SMART parameters of Hitachi hard drives after a certain period of disk inactivity are reset; Parameter 01 has features on Hitachi, Seagate, Samsung and Fujitsu drives, 03 on Fujitsu drives. It is also known that after flashing the disk, some parameters can be set to 0 (for example, 199). However, such a forced zeroing of the attribute will in no way suggest that problems with the disk have been resolved (if any). After all, a growing critical attribute is a consequence of problems, not a cause .
When analyzing a set of SMART data arrays, it becomes obvious that the set of attributes for disks of different manufacturers and even for different models of the same manufacturer may differ. This is due to the so-called vendor-specific attributes (that is, the attributes used to monitor their drives by a particular manufacturer) and should not be a cause for excitement. If the monitoring software can read such attributes (for example, Victoria 4.46b), then on disks for which they are not intended, they can have “terrible” (huge) values, and they simply do not need to pay attention. So, for example, Victoria 4.46b displays the RAW attribute values that are not intended to be monitored on the Hitachi HDS721010CLA332:
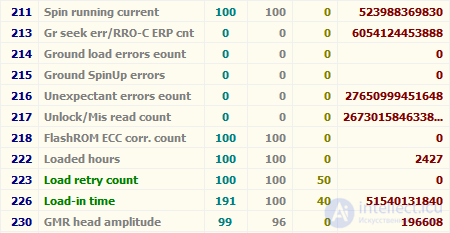
Scary Values in Victoria 4.46b
Often there is a problem when the program can not read the SMART disk. In the case of a good hard drive, this can be caused by several factors. For example, very often SMART is not displayed when a disk is connected in AHCI mode. In such cases, it is worth trying different programs, in particular HDD Scan, which has the ability to work in this mode, although it does not always succeed, or it is worthwhile to temporarily switch the disk to IDE compatibility mode, if possible. Further, on many motherboards, the controllers to which the hard drives are connected are not built into the chipset or south bridge, but are implemented by separate microchips. In this case, the DOS version of Victoria, for example, will not see the hard disk connected to the controller, and it will have to force it by pressing the [P] key and entering the channel number with the disk. Often, SMART cannot be read from USB disks, which is explained by the fact that the USB controller simply does not skip commands for reading SMART. SMART is almost never read from disks that function as part of a RAID array. Here, too, it makes sense to try different programs, but in the case of hardware RAID controllers, it is useless.
If after the purchase and installation of a new hard drive, any programs (HDD Life, Hard Drive Inspector and others like them) show that: the disk has 2 hours left to live; its productivity is 27%; Health - 19.155% (choose to taste) - then you should not panic. Understand the following. First, you need to look at the SMART indicators, and not from where the numbers of health and productivity come from (however, the principle of their calculation is clear: the worst indicator is taken). Secondly, when evaluating the parameters of a SMART program, any program looks at the deviation of the values of different attributes from previous indications. At the first launches of a new disk, the parameters are not constant, it takes some time to stabilize them. The program, evaluating SMART, sees that the attributes change, makes calculations, it turns out that if they change at such a pace, the drive will soon fail, and it starts to signal: “Save the data!” It will take some time (up to a couple of months), attributes stabilize (if the disk is really all right), the utility will collect data for statistics, and the timing of the demise of the disk as SMART stabilizes will be transferred further and further into the future. Evaluation programs drive Seagate and Samsung - generally a separate conversation. Due to the characteristics of the attributes of 1, 7, 195 programs, even for a completely healthy disk, they usually conclude that he has wrapped himself in a sheet and is crawling on the graveyard.
Please note that the following situation is possible: all the attributes of SMART are normal, but in fact the disk is with problems, even though this is still not visible. This is explained by the fact that the SMART technology works only “in fact”, that is, the attributes change only when the disk encounters problem areas in the process. And while he didn’t come across them, he doesn’t know about
продолжение следует...
Часть 1 HDD status and SMART technology and failure prediction. G-sensor in HDD. Types of malfunctions HDD.
Часть 2 Learning Smart to predict hard drive failures - HDD status
Часть 3 Final settlement - HDD status and SMART technology and failure

Comments
To leave a comment
Diagnostics, maintenance and repair of electronic and radio equipment
Terms: Diagnostics, maintenance and repair of electronic and radio equipment