Search for signs is one of the most important steps in the process.
pattern recognition and, in particular, characters. Description of some
solving the problem of identifying character traits based on cellular
automata is given in sect. 3.2.
Prior to the feature extraction process, characters are required, as indicated in
Section 1.1, solve several problems: you need a text image
process from the noise, bring it into a state that allows you to perform
conditions of recognition algorithms, and select from it separate
character images.
1.1. Preliminary image processing
Image processing is a task of changing the characteristics
images in order for the algorithms involved in the recognition
text, worked better with fewer errors. Besides,
to increase the productivity of cellular automata,
involved in recognition, a very critical element is
the number of cell states (dot colors) of the image.
In this paper, cellular automata involved in recognition
characters, function on the basis of two states of cells,
Corresponding to black and white color of image pixels.
In the process of transferring the image to black and white
the components of the point symbols should be distinguished from the background. For this
tasks can be used cellular automaton, in which each cell
corresponds to the image point, and the local radius for the cell is
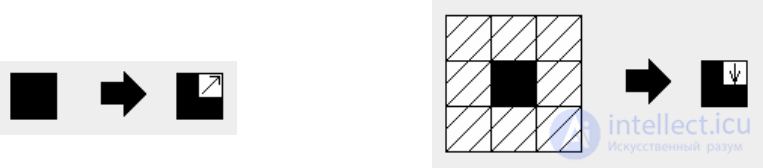
to zero. The machine implements three rules: translates the color of each point.
images in a shade of gray; fills the cell with black if it is darker
certain limit color; fills the cage with white colors if
it is lighter than the set border. In fig. 13 presents the rules
described cellular automata, created on the basis of simulating
programs,
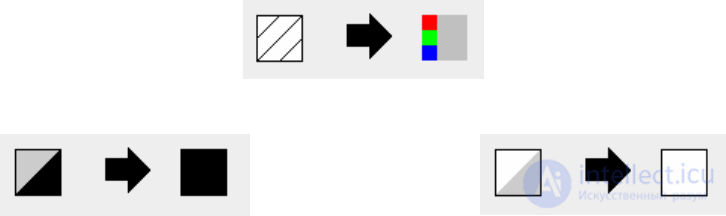
Fig. 13. The rules of the machine translation of the text image in black and white
colors: a - the translation of the color of a point in a shade of gray, b - painting
cells are black if its shade is more than the limit color, in -
painting the cell white if its shade is less than the limit color
1.2. Division of text into symbols
One of the currently unresolved tasks for systems
text recognition - its division into characters [4].
Most often this problem is solved in such systems in the complex:
pre-splitting the text image into separate
images of characters and after that the relationship between
different images with an estimate of the distance between them. On stage
Recognition of the partitioning results can be refined to
additional splitting or merging multiple received
images. Refinements can be based on context: if part
characters are well recognized, they may indicate unrecognized, or
clarification may be based on poor recognition of the resulting
character images.
Cellular automata can assist in pre-shattering.
text images on character images. In this case it is necessary
identify two cellular automata with labels whose rules are described
below.
1. The first machine puts a mark on each black dot of the image.
in the form of sequentially generated integers.
2. The second automaton for each black point scans the local
the neighborhood of the unit radius and itself, puts in a label with
the minimum number from this neighborhood. This removes the old tag.
Schemes of automata created on the basis of a simulation program
are presented on fig. 14.
a b
Fig. 14. Cellular automata tagged from the image
text symbols: a - automatic generation of tags - numbers, b - automatic on
search tags with a minimum number
After the completion of the work of the machines in the text image will be
different characters are marked with different characters, which will allow to isolate
images of individual characters.
1.3. Highlighting of characters
It was noted above that a person perceives images based on
associations of attributes of evaluated objects with familiar objects.
Each character of the text (Russian, English or other) has its own
unique signs. These signs uniquely distinguish
characters apart.
Text characters have a large number of features: position and tilt
lines, arcs, the presence of loops, vertical - horizontal lines, protrusions
and their slope, intersection. The main features can be considered protrusions
loops and intersections, as well as their mutual arrangement. In fig. 15
presents the position of the elements of these three species in the symbols of Russian
the alphabet. The figure does not represent characters that are a union.
several unrelated items. These are the symbols "Yo", "Y" and "Y". AT
In this robot, these characters are not considered, for their recognition
Algorithms must contain additional special blocks.

Fig. 15. Position of loops, ends and intersections in symbols.
russian alphabet
The solution to the problem of identifying character traits based on cellular
automata is solved in sec. 2
1.4. Classification and training
The previous step of the text recognition process is highlighted.
signs of characters. After that, a classification process is assumed,
which on the basis of the received signs will determine the name of the symbol.
Classification, as noted in section. 1.2, most often
based on neural networks. In addition, for this purpose applicable
statistical methods that are based on accumulated information about
Signs can define a character.
The recognition system assumes the presence of a learning unit. Training
system is directly related to the classification, it allows you to change and
adjust coefficients based on the association of the classification result with
the name of the character. For neural networks and statistical methods
training is done in various ways [5, 22].
Cellular automata can also participate in the classification process.
signs. The idea of classification can be the creation of a characteristic
cellular automaton for each trait and its correction taking into account
certain signs in the learning process. This concept requires
study and further research.
2. Cellular automata in the process of selecting text properties
Consider the characteristics of cellular automata in the process of text recognition. Process splitting
text recognition on the stages involves the use of different
cellular automata to perform various tasks. Definition
character characteristics and the allocation of their characteristics requires the development
complex rules on the basis of which this becomes possible.
In section 1 describes that the main elements of characters are
loops, intersections, position of the ends. By these elements is possible
image identification, correlation with a specific symbol.
It is possible that a person subconsciously uses these very signs.
in the process of reading the text.
There are many strategies for highlighting the described features on
based on cellular automata. Below are two such strategies that
use cellular automata labeled.
2.1. The first strategy is the selection of the ends and loops of the symbol
The first strategy is that from the top edge of the character along
the points that make up this symbol start a “wave”. This “wave” can
divided into components, repeating the contour of the image of the symbol. AT
certain moment the components of the "wave" can meet or
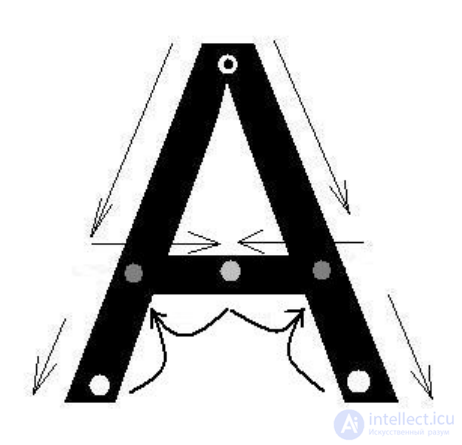
fade out at the end of the character. In fig. 16 shows the direction of travel.
"Waves" along the image of the symbol "A" and showing the starting points of the "wave",
attenuation at the ends of the symbol and at the meeting place of its two components.
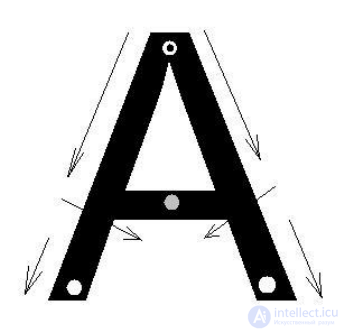
Fig. 16. The direction of propagation of the "wave" along the symbol "A" with
marking the positions of the ends of the characters and loops
The concept of "waves" in this algorithm is embedded several
constituents. "Wave Front" - symbol points that move from
one end of the symbol image to the other. "Wave loop" is points
the images in which the “front
waves. " “Points of the Path” are the points of the image, where
there was a “wave front”, and then a “wave plume”, at these points
The process does not resume.
At the initial moment of time, all points of the symbol are not marked with labels.
The first point of the wave is marked, and the algorithm begins its work.
The algorithm is based on the idea that during the passage of a wave in some
then the “wave front” will fade away, while the train will still be
to attend. This event can only happen at the end of a character.
or at the meeting point of the two components of the wave. Position of the wave plume in
this moment is remembered.
Additionally, the event of the meeting of the two components of the wave
is recorded based on the fact that the plumes of two wave components
at the time of the meeting are not related. Thus remembered
character loop position.
The scheme of the work of cellular automata is presented
in fig. 17. Cellular automata are indicated in oval blocks.
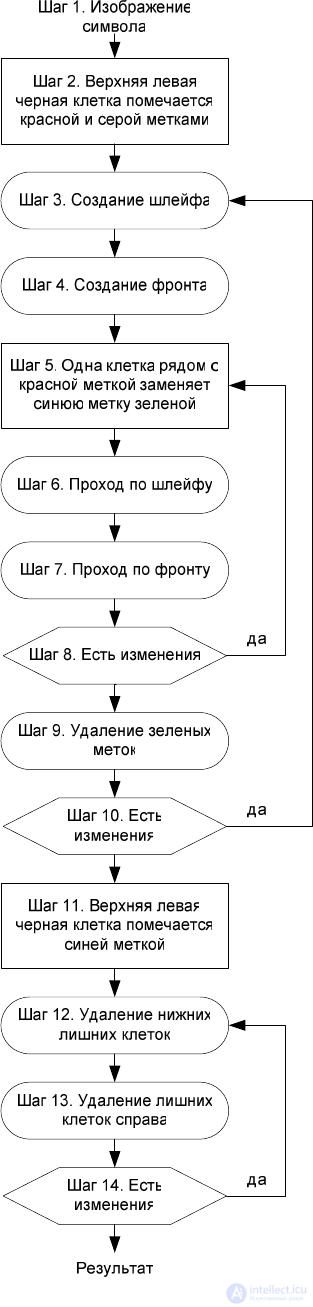
Fig. 17. The block is a diagram of the work sequence of cellular automata for
the first algorithm for the selection of characters
We give a description of the algorithm based on a sequence of cellular
machines with tags. In addition to cellular automata in the sequence
there are additional controls. Cell condition
determined by its color. In addition to color, a cell may contain one or
more tags that are separated by colors.
Step 1. The input sequence of cellular automata comes
symbol image.
Step 2. The upper left black cell of the image is marked with red.
and gray tick marks.
Step 3. Automatic “create loop”: the red label is replaced by blue
tagged.
Step 4. “Front creation” automaton: black cells without a gray mark
next to the cells with a gray label are marked with gray and red tags.
Step 5. One square next to the red mark replaces the blue mark.
green.
Step 6. Automatic "passage through the train": all the cells next to the cells with
Green labels replace blue labels with green ones.
Step 7. Automatic "pass on the front": all cells with red, but without
a green tag next to the green labeled cells
marked with a green tag; if a cell with a red and green tag
located next to the cell with a blue mark, then this cell
marked with an orange label.
Step 8. If, starting from Step 5, the automata did not change their state
one cell, then go to step 9, otherwise go to step 5.
Step 9. Automatic "removal of green labels": all green labels in cells
are deleted.
Step 10. If, starting from Step 3, the automata did not change their state
single cell, then go to step 11, otherwise go to step 3.
Step 11. The top left black cell of the image is marked blue.
tagged.
Step 12. Automaton “do the bottom extra tags”: if above the cell with
the blue or orange label is a cell with the same label, then in
This cell remove this label.
Step 13. Automatic "delete unnecessary marks on the right": if to the left of
cells with a blue or orange label is a cell with the same
tag, then in this cell remove this tag.
Step 14. If, starting from step 12, the automata did not change their state
single cell, then complete the sequence, otherwise go to step
12.
At the output of the algorithm, some cells of the image are labeled
tags. A blue label means that the symbol is at the end of the symbol.
symbol, and an orange label indicates a loop symbol.
In the process of the algorithm, cells with red marks can be
interpreted as a wave front, blue cells as a wave plume, and
gray cells - like cells traversed.
Below are the formal transition rules for cellular automata with
tags. For the described cellular automata, five
different labels: red, blue, gray, green and orange.
This means that the state of the cell consists of six components: color and
presence / absence of five tags.
The rule number is indicated by six numbers, which mean
cell condition and the presence / absence of the label. The position of each tag in
The number is determined based on the above list.
Some rules of automata in schemes contain instead of symbol color
strokes - this means a set of rules with all sorts of combinations
colors / presence of cell labels.
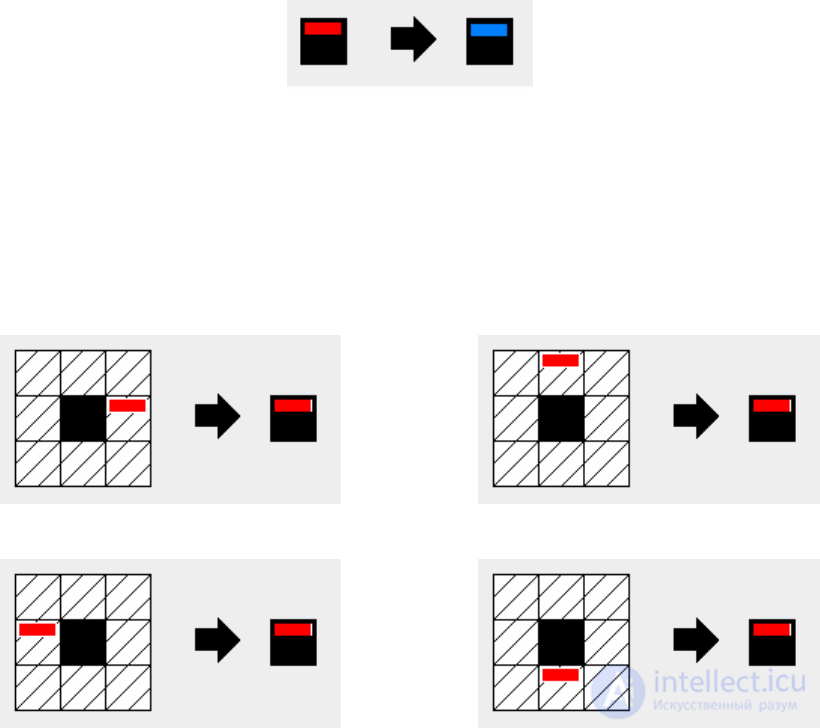
1. The “creation of a loop” automaton has a neighborhood of N of radius zero - on
The state of the cell is affected only by the cell itself. The machine contains only one
rule: 3: 2: 1: 1: 0: 0. Scheme of the rule is shown in Fig. 18.
Fig. 18. Diagram of the cellular automaton “creation of a loop”
Fig. 19. Schemes of the rules of the cellular machine “creation of the front”
2. The automaton “front creation” has a local neighborhood with radii.
in one cell and contains several rules. Scheme of rules is presented on
rice nineteen.
3. The “passage through train” machine is based on surroundings from neighbors.
unit radius and contains eight rules whose schemes are presented
in fig. 20.
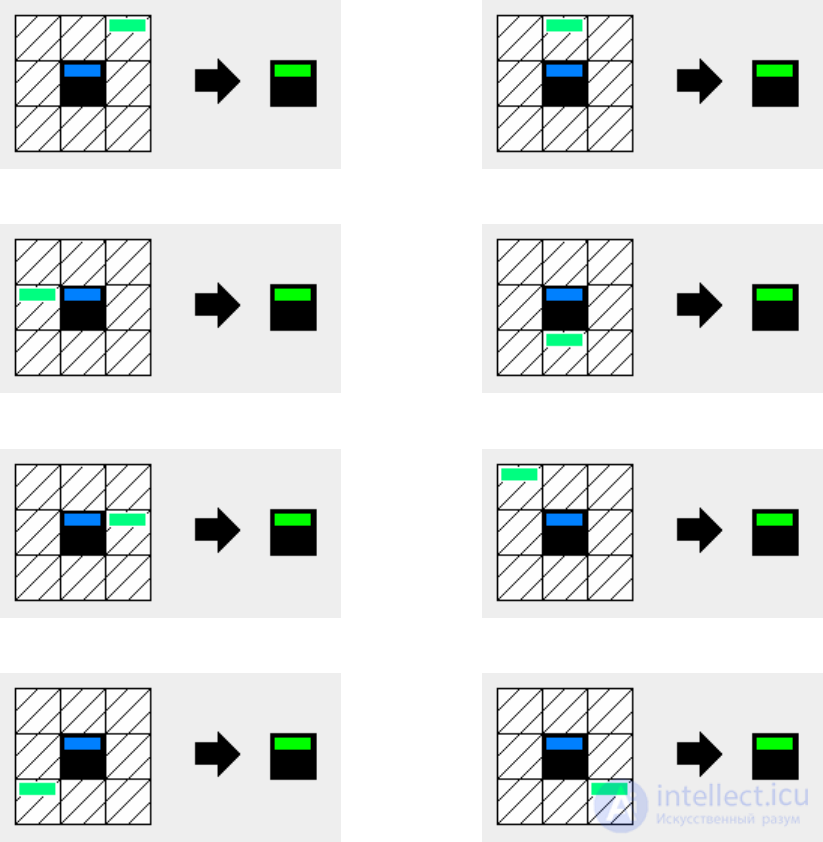
Fig. 20. Scheme of the rules of the cellular machine "passage through the train"
4. Schemes of the “passage along the front” machine are shown in fig. 21,
machine contains 12 rules.
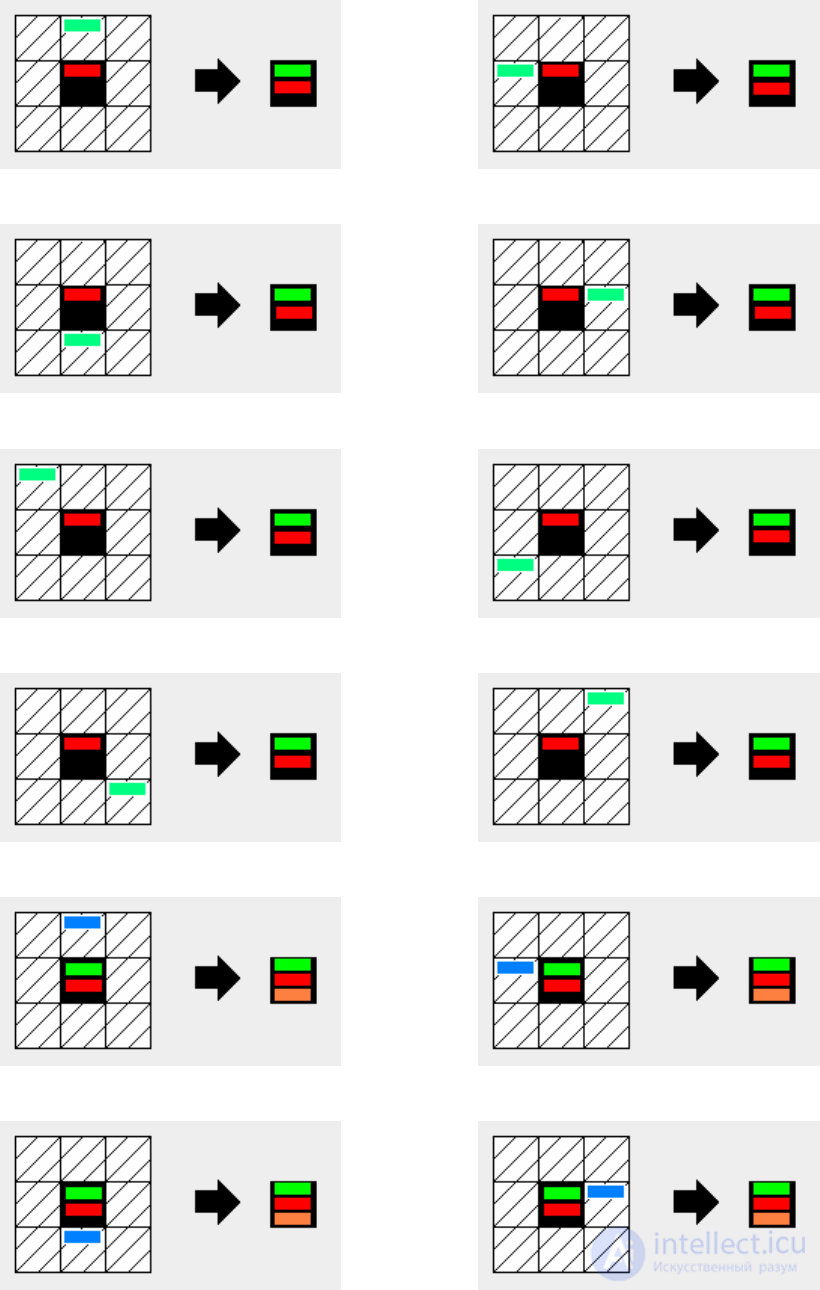
Fig. 21. Schemes of the rules of the cellular automaton “passage along the front”
5. The automatic machine “removal of green tags” is similar to the automatic machine “creation
loop contains one rule and has a radius of local surroundings -
zero. The scheme of the automaton rule is shown in fig. 22
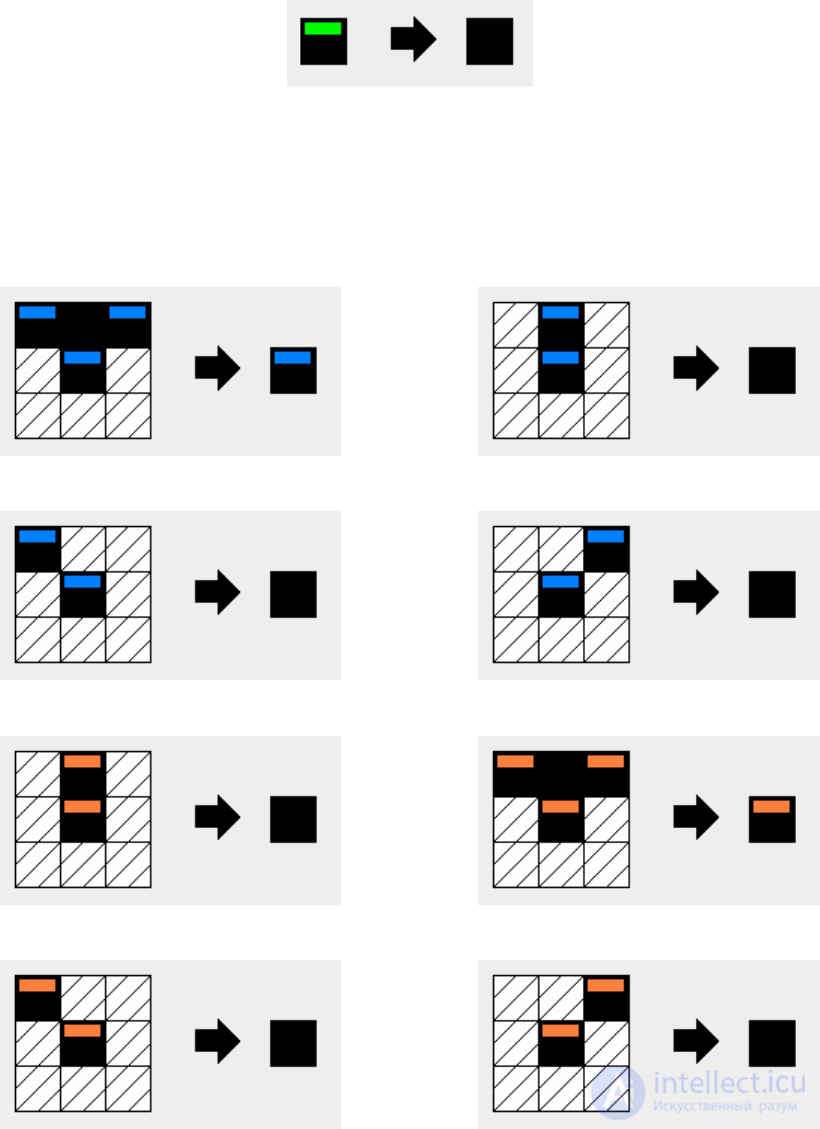
Fig. 22. Schemes of the cellular automaton "removal of green labels"
Fig. 23. Schemes of the rules of the machine "removal of the lower unnecessary tags"
6. Schemes of the rules of the cellular automaton "removal of the lower excess
labels ”is shown in fig. 23.
7. The rules of the “delete unnecessary labels on the right” automaton are shown in
rice 24
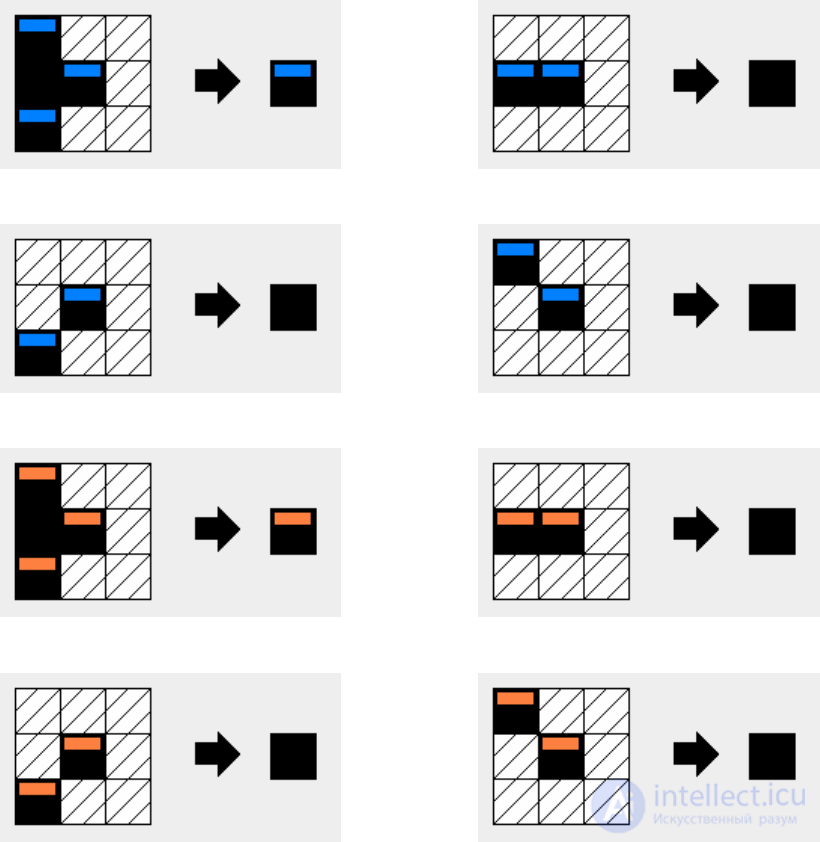
Fig. 24. Schemes of cellular automaton rules “deleting unnecessary tags
on right"
2.2. The second strategy is the selection of intersections, ends and loops
character
The second strategy is an improved first and
develops it. In the process of propagation of the "wave" at the moment when
The cell of the end of a symbol or the cell of the meeting of two components is determined.
"Waves", generated response "wave" - "echo" along the already passed
cells. "Echo" goes the way back and marks the cells, in
which initial wave was divided into components. It must
allow to find the positions of the intersections of the segments that make up
characters.
The second strategy allows you to determine the position of the intersection of lines in
image symbol. Wave propagation can be seen in Fig. 25
Fig. 25. The direction of propagation of the "wave" along the symbol "A" with
marking the positions of the ends of the characters and loops, as well as
echo propagation with marking intersection positions
The pattern of the cellular automata sequence is shown in
rice 26
Fig. 26. Block Scheme of the sequence of cellular automata for
second character extraction algorithm
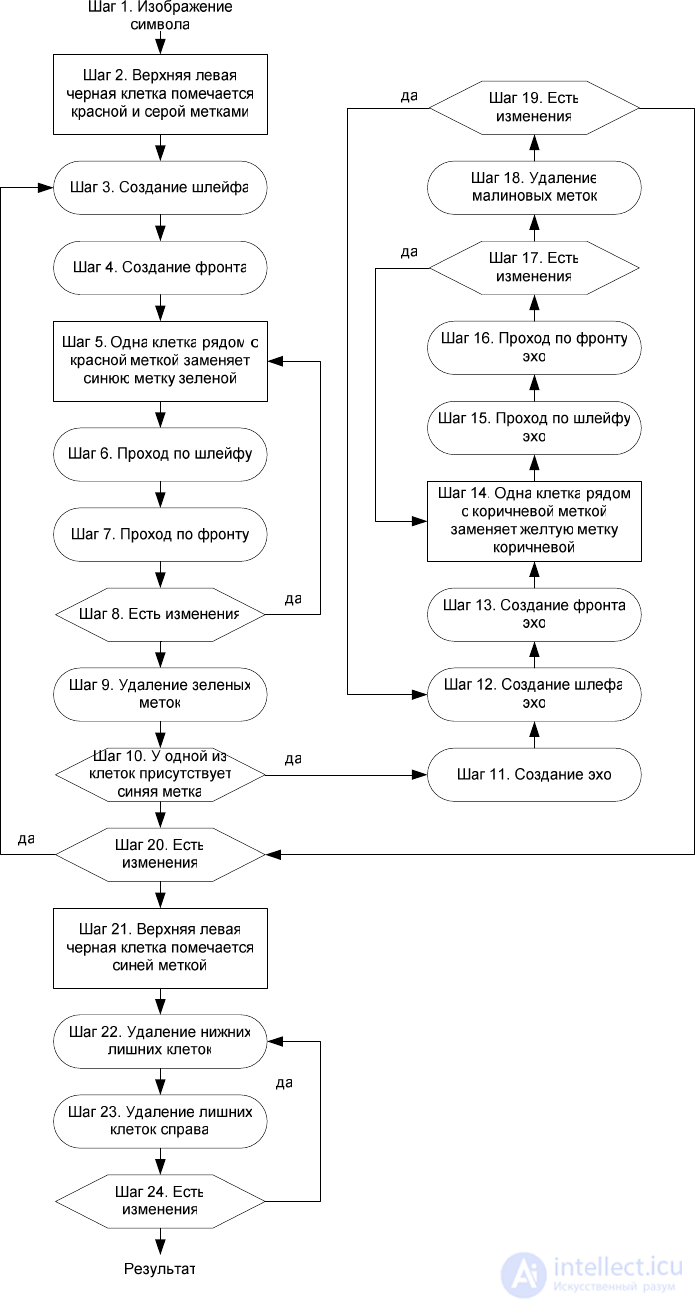
We give an informal description of the second algorithm based on
sequences of cellular automata with labels.
Step 1. The input sequence of cellular automata comes
symbol image.
Step 2. The upper left black cell of the image is marked with red.
and gray tick marks.
Step 3. Automatic “create loop”: the red label is replaced by blue
tagged.
Step 4. “Front creation” automaton: black cells without a gray mark
next to the cells with a gray label are marked with gray and red tags.
Шаг 5. Одна клетка рядом с красной меткой изменяет синюю метку
зеленой.
Шаг 6. Автомат «проход по шлейфу»: все клетки рядом с клетками с
зелеными метками заменяют синие метки зелеными.
Шаг 7. Автомат «проход по фронту»: все клетки с красной, но не с
зеленой меткой, находящиеся рядом с клетками с зеленой меткой,
помечаются зеленой меткой; если клетка с красной и зеленой метками
находится рядом с клеткой с синей меткой, то данная клетка
помечается оранжевой меткой.
Шаг 8. Если, начиная с шага 5, автоматы не изменили состояние ни
одной клетки, то перейти на шаг 9, иначе перейти на шаг 5.
Шаг 9. Автомат «удаление зеленых меток»: все зеленые метки у клеток
убираются.
Шаг 10. Если у одной из клеток присутствует синяя метка, то перейти
на шаг 11, иначе на шаг 20.
Шаг 11. Автомат «создание эха»: синюю метку клеток заменить
коричневой и голубой, к красной метке символов добавить коричневую
метку.
Шаг 12. Автомат «создание шлейфа эха»: коричневая метка заменяется
желтой меткой.
Шаг 13. Автомат «создание фронта эха»: черные клетки с серой меткой,
но без фиолетовой метки рядом с клетками с фиолетовой меткой
помечаются фиолетовой и коричневой метками.
Шаг 14. Одна клетка рядом с коричневой меткой меняет желтую метку
малиновой.
Шаг 15. Автомат «проход по шлейфу эха»: все клетки рядом с клетками
с малиновыми метками заменяют желтые метки малиновыми.
Шаг 16. Автомат «проход по фронту эха»: все клетки с коричневой, но
не с малиновой меткой, находящиеся рядом с клетками с малиновой
меткой, помечаются малиновой меткой; если клетка с коричневой и
малиновой метками находится рядом с клеткой с желтой меткой, то
данная клетка помечается пурпурной меткой.
Шаг 17. Если, начиная с шага 14, автоматы не изменили состояния ни
одной клетки, то перейти на шаг 18, иначе перейти на шаг 14.
Шаг 18. Автомат «удаление малиновых меток»: все малиновые метки у
клеток убираются.
Шаг 19. Если, начиная с шага 12, автоматы не изменили состояния ни
одной клетки, то перейти на шаг 20, иначе перейти на шаг 12.
Шаг 20. Если, начиная с шага 3, автоматы не изменили состояния ни
одной клетки, то перейти на шаг 21, иначе перейти на шаг 3.
Шаг 21. Верхняя левая черная клетка изображения помечается синей
меткой.
Шаг 22. Автомат «удание нижних лишних меток»: если над клеткой с
синей или оранжевой меткой находится клетка с соответственно синей
или оранжевой меткой, то в данной клетке эту метку удалить.
Шаг 23. Автомат «удание лишних меток справа»: если слева от клетки с
синей или оранжевой меткой находится клетка с соответственно синей
или оранжевой меткой, то в данной клетке эту метку удалить.
Шаг 24. Если, начиная с шага 22, автоматы не изменили состояния ни
одной клетки, то завершить последовательность, иначе перейти на шаг
22
Второй алгоритм может показаться, на первый взгляд, громоздким, но,
на самом деле, он содержит в себе две составляющих, аналогичных первому
алгоритму. Правила автоматов данного алгоритма аналогичны правилам
автоматов первого алгоритма по выделению признаков символов.
Достоинством второго алгоритма можно считать выделение большего
количества признаков символов, чем с помощью первого алгоритма. Однако,
второй алгоритм выполняет больше шагов и поэтому работает дольше.
Таблица 1 – Сравнение систем распознавания символов
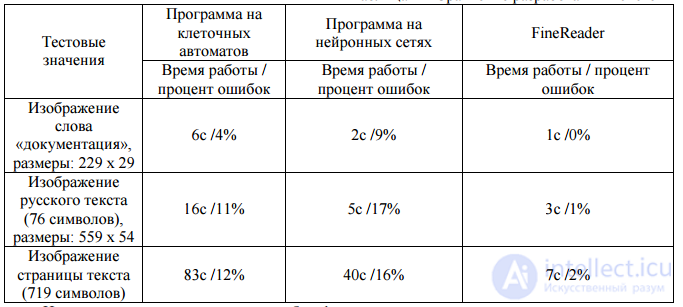
Таблица 2. Скоростные характеристики моделирующей программы
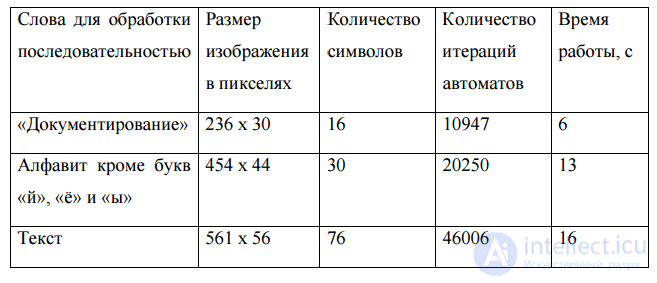
Low performance is determined by the modeling nature of the developed program. Used algorithms require optimization and refinement.

Comments
To leave a comment
Pattern recognition
Terms: Pattern recognition