Lecture
Criteria informative signs |
When solving recognition problems, the main criterion (including for evaluating the informativeness of features) is the risk of loss. We will talk more about it in the second section of the course of lectures. Here we only note that it is based on an estimate of the probabilities of recognition errors and their cost. It is possible to speak about the estimation of probabilities only within the framework of a statistical approach, therefore in this section it is better to apply a type criterion: the proportion of the control (examination) sample that was recognized incorrectly. We have already mentioned that the training sample objects should not be included in the control sample. In cases where the total sample is small in size, dividing it into two parts is a very undesirable step (both the quality of training and confidence in the results of control will deteriorate). Some researchers apply the so-called sliding control method to compensate for this deficiency. It consists of the following. All objects, except one, are presented as a training sample. One object that did not participate in the training is presented for control. Then another object is selected from the total sample for control, and the rest of the sample is trained. This procedure is repeated as many times as the objects in the total sample. In this case, the entire sample is involved in both training and control, but control objects do not participate in training. This positive effect is achieved at the cost of training not just once, as it would have been if there were two different samples (training and control) of a sufficiently large volume, but as many times as there are objects in the total sample. This disadvantage is significant, since the training procedure is usually quite complicated and its repeated repetition is undesirable. If this procedure is used to select informative features, then the number of “trainings” should be multiplied by the number of feature sets to be compared. Therefore, to assess the informativeness of features and solve other problems, it is often not the relative number of recognition errors that is used, but other criteria associated with it. In any case, these criteria express the degree of distinguishability of objects of different images. For example, as already noted when considering taxonomy algorithms, the ratio of the average distance between objects of different images to the average distance between objects of the same image in some cases is very effective. It is proposed to independently write the corresponding computational formulas by entering the necessary notation. When using such criteria, a control sample is not needed, but a one-to-one connection with the number of recognition errors is lost. It is clear that the average distance between objects of different classes is obtained by averaging the distances between all possible pairs of objects belonging to different classes. If the number of classes is large and each of them is represented by a significant number of objects, the averaging procedure is cumbersome. In this case, you can use the averaging of the distances between the standards of different classes, and within the classes - the averaging of the distances from the objects to the standard of this class. It is quite clear that such a simplification is not always permissible. It all depends on the shape and relative position of the areas of the attribute space in which objects of different classes are concentrated. |
Selection of informative features |
We assume that the set of initial features is given. In fact, it is determined by the teacher. It is important that it includes those signs that really carry distinctive information. The fulfillment of this condition depends to a decisive extent on the experience and intuition of the teacher, his good knowledge of the subject area for which the recognition system is being created. If the initial feature space is specified, then the selection of a smaller number of the most informative features (the formation of a feature space of a smaller dimension) is formalized. Let be In fig. 16 shows a linear coordinate transformation.
After converting the sign In fig. 17 illustrates the transition from the Cartesian to the polar coordinate system, which led to the expediency of discarding the feature Such transformations simplify the decision rules, since they have to be built in a space of lower dimension. However, this necessitates the implementation of a transformation
Fig. 16. Linear coordinate transformation Highlight the following type of linear transformation:
Where This means that part of the original feature system is discarded. Of course, the remaining signs should form the most informative subsystem. Thus, it is necessary to reasonably organize the selection procedure according to one of the previously considered criteria of informativeness. Consider some approaches. The optimal solution to the problem gives a complete brute force. If the source system contains
Fig. 17. Transition to the polar coordinate system Consider some of the procedures used. 1. Evaluated the information content of each of the source signs, taken separately. Then signs are ranked by decreasing information content. After that are selected 2. It is assumed that the signs are statistically dependent. First, the most individually informative feature is selected (viewed 3. Sequential rejection of signs. This approach is similar to the previous one. From the aggregate containing 4. Random search. Randomly selected numbers 5. Random search with adaptation. This is a sequential directional procedure based on a random search, taking into account the results of previous selections. At the beginning of the procedure, the chances of all the initial signs of entering a subsystem consisting of |
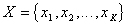 - initial attribute space,
- initial attribute space, 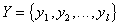 - transformed feature space,
- transformed feature space, 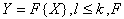 - some function.
- some function. 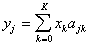 .
. 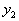 does not carry any distinctive information and its use for recognition does not make sense.
does not carry any distinctive information and its use for recognition does not make sense. 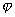 .
. 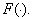 Therefore, total simplification may not be possible, especially when digitally realizing the transformation of the attribute space. It is good if the sensors, which measure the values of the initial features, by their physical nature are such that they simultaneously carry out the required transformation.
Therefore, total simplification may not be possible, especially when digitally realizing the transformation of the attribute space. It is good if the sensors, which measure the values of the initial features, by their physical nature are such that they simultaneously carry out the required transformation. 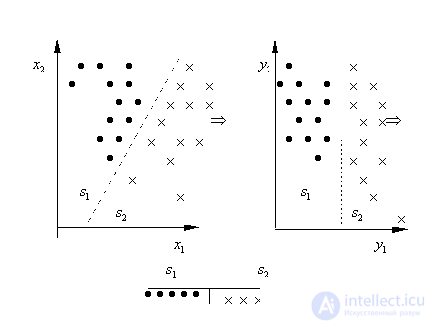
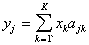 ,
, 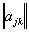 - a diagonal matrix, and its elements are either 0 or 1.
- a diagonal matrix, and its elements are either 0 or 1. 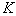 signs, and we need to choose the best subsystem containing
signs, and we need to choose the best subsystem containing 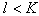 signs, you will have to consider
signs, you will have to consider 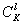 (number of combinations of
(number of combinations of 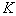 items by
items by 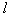 ) possible in this case subsystems. Moreover, the consideration of each subsystem consists in estimating the value of the informativity criterion, which in itself is a time-consuming task, especially if the relative number of recognition errors is used as a criterion. To illustrate, let us point out that for the selection of the 20 basic signs of the five most informative, we have to deal with approximately 15.5 × 103 variants. If the number of initial signs is hundreds, then a complete search becomes unacceptable. They proceed to reasonable procedures of directional selection, which generally do not guarantee an optimal solution, but at least provide not the worst choice.
) possible in this case subsystems. Moreover, the consideration of each subsystem consists in estimating the value of the informativity criterion, which in itself is a time-consuming task, especially if the relative number of recognition errors is used as a criterion. To illustrate, let us point out that for the selection of the 20 basic signs of the five most informative, we have to deal with approximately 15.5 × 103 variants. If the number of initial signs is hundreds, then a complete search becomes unacceptable. They proceed to reasonable procedures of directional selection, which generally do not guarantee an optimal solution, but at least provide not the worst choice. 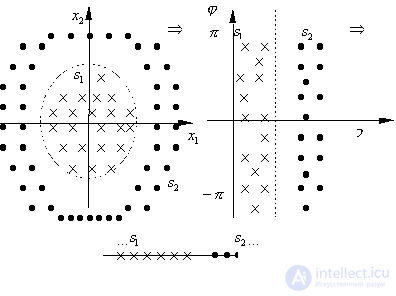
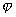
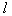 first signs. Here is the number of options under consideration.
first signs. Here is the number of options under consideration. 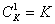 . With this approach, the optimal choice is guaranteed only if all the original signs are statistically independent of each other. Otherwise (and they are most often found in practice) the solution may be far from optimal.
. With this approach, the optimal choice is guaranteed only if all the original signs are statistically independent of each other. Otherwise (and they are most often found in practice) the solution may be far from optimal. 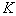 options). Then one more of the remaining ones joins the first selected feature, which makes up the most informative pair with the first one (viewed
options). Then one more of the remaining ones joins the first selected feature, which makes up the most informative pair with the first one (viewed  options). After that, one more of the remaining signs joins the selected pair, making up the most informative troika with the previously selected pair (viewed
options). After that, one more of the remaining signs joins the selected pair, making up the most informative troika with the previously selected pair (viewed 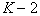 options), etc. to obtain an aggregate of
options), etc. to obtain an aggregate of 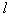 signs. Here the number of viewed options is the value
signs. Here the number of viewed options is the value 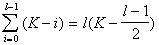 . To illustrate, we note that for the selection of 5 signs from 20 with this approach, it is required to review 90 variants, which is approximately 170 times less than with full enumeration.
. To illustrate, we note that for the selection of 5 signs from 20 with this approach, it is required to review 90 variants, which is approximately 170 times less than with full enumeration. 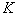 signs discarded one that gives a minimal decrease in information content. Then from the remaining population containing
signs discarded one that gives a minimal decrease in information content. Then from the remaining population containing 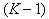 signs, one more is discarded, minimizing the information content, etc., until it remains
signs, one more is discarded, minimizing the information content, etc., until it remains 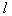 signs. Of these two approaches (sequential addition of features and sequential rejection of features) it is advisable to use the first one when
signs. Of these two approaches (sequential addition of features and sequential rejection of features) it is advisable to use the first one when 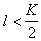 and second when
and second when 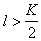 , if you focus on the number of viewed options. As for the selection results, it may in general be different.
, if you focus on the number of viewed options. As for the selection results, it may in general be different. 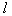 signs and evaluates the information content of this subsystem. Then, again and independently of the previous set, another system is randomly formed from
signs and evaluates the information content of this subsystem. Then, again and independently of the previous set, another system is randomly formed from 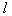 signs. So repeats
signs. So repeats 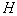 time. Of
time. Of 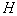 feature sets selected the one that has the most information. Than
feature sets selected the one that has the most information. Than 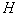 the more, the higher the probability of choosing the best subsystem. With
the more, the higher the probability of choosing the best subsystem. With 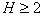 it is possible, at least, to assert that our choice was not the worst (unless, of course, the selected subsystems were found to be the same for informativeness).
it is possible, at least, to assert that our choice was not the worst (unless, of course, the selected subsystems were found to be the same for informativeness). 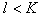 signs are taken equal. For random sampling, a sensor is evenly distributed in the interval.
signs are taken equal. For random sampling, a sensor is evenly distributed in the interval. 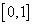 random (pseudo-random) numbers. This interval is divided into
random (pseudo-random) numbers. This interval is divided into 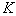 equal segments. The first segment is assigned to the attribute
equal segments. The first segment is assigned to the attribute 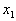 second -
second - 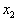 etc. The length of each segment is equal to probability
etc. The length of each segment is equal to probability 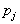 inclusions
inclusions 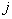 th sign in the informative subsystem. As already noted, at first these probabilities are the same for all signs. Random number sensor is selected
th sign in the informative subsystem. As already noted, at first these probabilities are the same for all signs. Random number sensor is selected 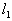 various segments. For those
various segments. For those 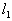 signs of
signs of 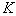 , which correspond to these segments, is determined by the value of the criterion of information
, which correspond to these segments, is determined by the value of the criterion of information 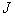 . After receiving the first group of
. After receiving the first group of 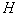 randomly selected subsystems determined
randomly selected subsystems determined 
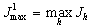 and
and 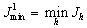 . Adaptation is to change the probability vector
. Adaptation is to change the probability vector 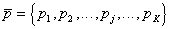 selection of features in the subsequent stages of the search, depending on the results of the previous stages: the length of the segment in the interval
selection of features in the subsequent stages of the search, depending on the results of the previous stages: the length of the segment in the interval 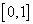 , corresponding to the attribute that fell into the worst subsystem, decreases (the attribute is “punished”), and if it falls into the best subsystem, it increases (the attribute is “encouraged”). The lengths of the segments are changed by
, corresponding to the attribute that fell into the worst subsystem, decreases (the attribute is “punished”), and if it falls into the best subsystem, it increases (the attribute is “encouraged”). The lengths of the segments are changed by 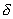
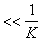 . After iterating through a number of groups, the probability of choosing features that are often found in successful combinations becomes significantly greater than the others, and the random number sensor begins to choose the same combination of
. After iterating through a number of groups, the probability of choosing features that are often found in successful combinations becomes significantly greater than the others, and the random number sensor begins to choose the same combination of 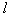 signs. The more
signs. The more 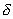 , the faster the convergence of the procedure, but the lower the probability of "going out" to the best subsystem. Conversely, the smaller
, the faster the convergence of the procedure, but the lower the probability of "going out" to the best subsystem. Conversely, the smaller 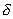 , the slower the convergence, but the higher the probability of choosing the best subsystem. Specific choice of value
, the slower the convergence, but the higher the probability of choosing the best subsystem. Specific choice of value 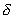 must be such that the procedure converges with the total number of elections
must be such that the procedure converges with the total number of elections 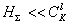 , and the probability of finding the best subsystem or close to it in terms of informativity would be close to unity.
, and the probability of finding the best subsystem or close to it in terms of informativity would be close to unity. 
Comments