Lecture
When creating parallel programs for the SMP system, multithreaded programming is used with the help of:
• threads (threads, threads)
• OpenMP directives
OrepMR directives - special compiler directives
• directives are used to highlight sections of code that need to be parallelized (fragments)
• in parallel fragments, the code is divided into streams
• threads run separately
The program is a set of consecutive and parallel code sections (forkfork-join or pulsating parallelism).
OpenMP is part of the compiler gcc scoring versions of 4.2, and MSVisualStudio versions of 2008 above.
If the compiler is not yet supported by OpenMP, the directives are ignored and executed as usual (sequential).
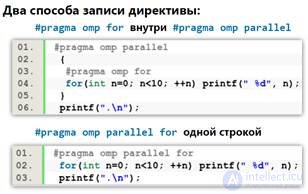
Uses special pragma directives, re-parsing the code that needs to be parallelized
Directions are divided into "\"
#pragmaompparallelforshared (a) \
private (i, j, sum) \
schedule (dynamic, CHUNK)
parallel directive is used to distinguish parallel fragments
#pragmaomppa parallel
<program_block>
The word is optional for all OpenMP directives.
Block of the program –statement or compoundstatement {...}.
Rule for block: one input \ one output
Программы Order of the program with the directive:
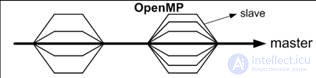
Набор a set (team) of N threads is created (the source thread is number 0 and is called master);
Программы the program block is duplicated or divided between threads for parallel execution;
At the end, synchronization occurs - all threads wait for completion, after which all threads end and the master continues.
The num_threads parameter allows you to specify the number of threads to be created.
The standard does not guarantee the creation of a specified number of threads (in the case of very large values).
The number of additionally created streams is <specified value> -1 (since there is a master stream).
if the number of threads is not specified, they will be created so much that their total number = the number of computing elements (cores or processors).
Each thread has its own stack of counter commands (a stream can have local variables).
Variables - local (private) or shared (shared).
Standard OpenMP Feature
• omp_get_thread_num returns id stream (from 0 to n-1);
• omp_get_num_threads returns the number of threads.
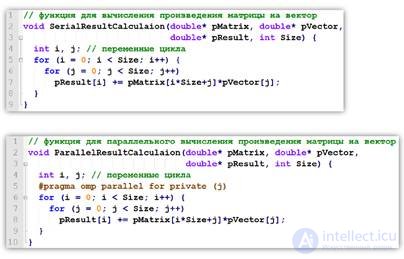
parallelfor directive is used to parallelize the for loop.
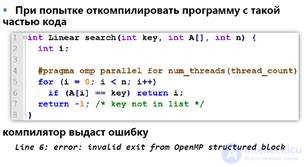
The cycle must always follow the directive.
EACH FLOW PERFORMS PART OF THE CYCLE ITERATIONS!
Each stream gets in ~ 1 \ n loop iterations in order of id (master executes the first 1 \ n iterations, the stream with id = 1 executes the following 1 \ n iterations, etc.
The loop counter is always a local variable.

Only for loops are parallelized (while or do-while are not parallelized).
The number of iterations must be exactly known in advance. Type cycles
for (;;) {...}
or
for (i = 0; i <n; i ++) {
if (...) break;
...
}
cannot be parallelized.
Only cycles in canonical form are parallelized:
• cycle counter –int or pointer;
• start, end, and increment must be compatible types (if the counter is a pointer, then the increment is aint).
• start, end and increment should not change in the body of the cycle.
• the cycle counter should not be changed in the body of the cycle
If the result of calculations in a cycle depends on the result of one or several previous iterations (recursion, dynamic programming), then the result will be incorrect.
The program for calculating the Fibonacci number will produce an incorrect and each time a new result.

OpenMP does not check the dependencies between iterations in a loop. Programmers should do this.
The cycle in which the results of one or several iterations depend on other iterations cannot be correctly parallelized using OpenMP.
The situation where the calculation of fibo [6] depends on the calculation of fibo [5] is called data dependency.
Data dependency can exist within one iteration, but cannot within different iterations.
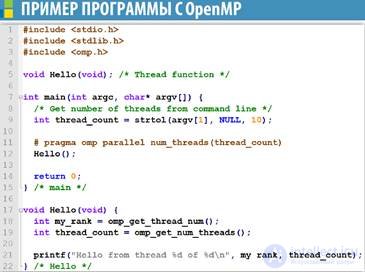
Hello OpenMP program




Comments
To leave a comment
Highly loaded projects. Theory of parallel computing. Supercomputers. Distributed systems
Terms: Highly loaded projects. Theory of parallel computing. Supercomputers. Distributed systems