Lecture
Это окончание невероятной информации про архитектура нейронных сетей.
...
src="/th/25/blogs/id7740/646d9afd928e8a2758d02c8e3a32ae54.png" data-auto-open loading="lazy" alt="Introduction to neural network architectures. Classification of neural networks, principle of operation" >
About the usual Feed-Forward neural network it is known that it is a universal approximator. They can approximate more or less any continuous function (there is such a Tsybenko theorem). It's great, but recurrent neural networks are turing full. They can calculate any computable.
Essentially, recurrent neural networks are a regular computer. The task is to train him correctly. Potentially, it can read any algorithm. Another thing is that it is difficult to teach him.
In addition, the usual Feed-Forward neural networks have no opportunity to take into account the order in time - this is not in them, not presented. Recurrent networks do this explicitly, the concept of time is embedded in them.
Regular feed-forward networks do not have any memory, except for the one that was obtained at the training stage, and recurrent networks do. Due to the fact that the content of the layer is transferred back to the neural network, it is like its memory. It is stored while the neural network is running. This also adds a lot.
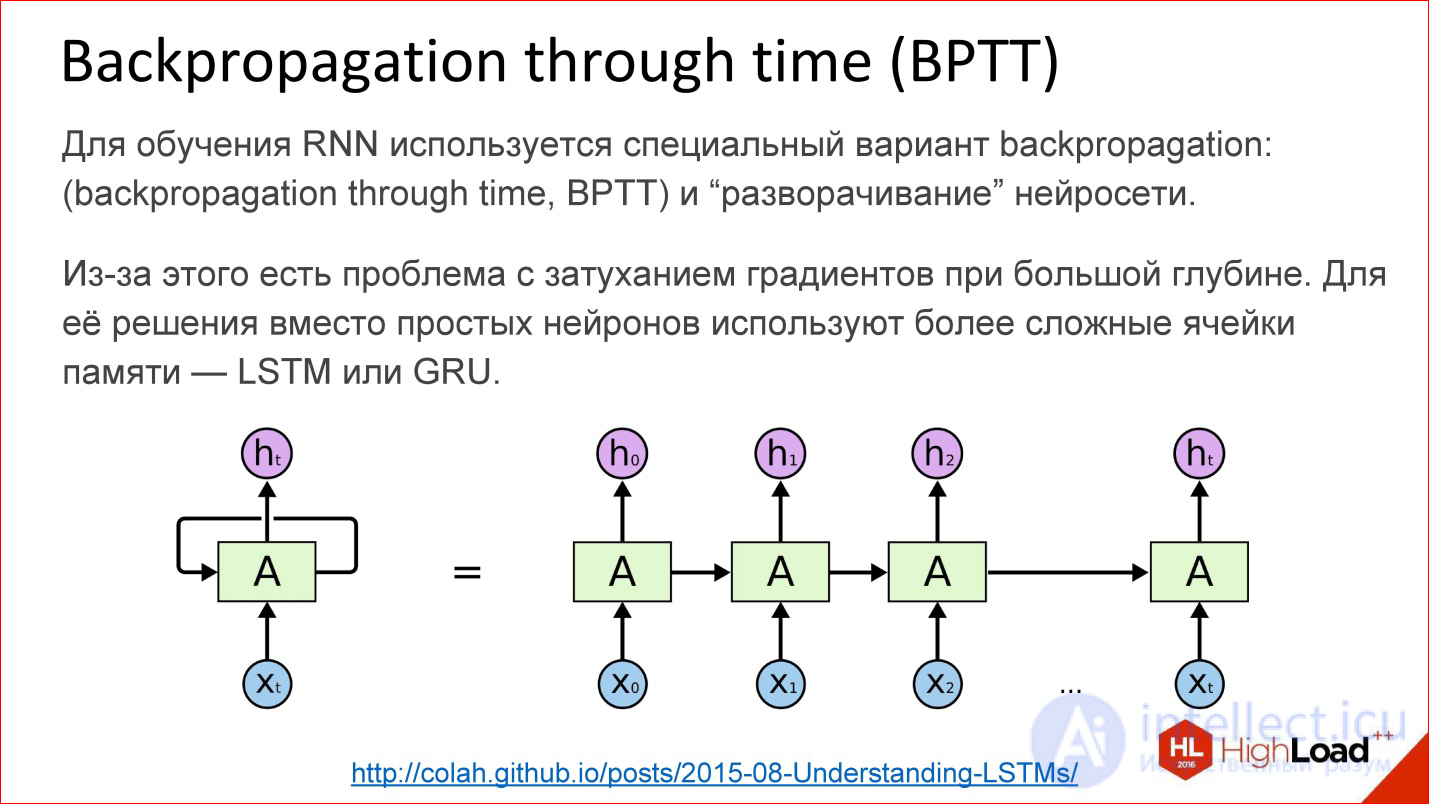
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
How are recurrent neural networks trained? In fact, almost the same. In addition to Backpropagation, of course, there are many other algorithms, but at the moment Backpropagation works best.
For recurrent neural networks, there is a variation of this algorithm - Backpropagation through time. The idea is very simple - you take a recurrent neural network and the cycle simply expands on a few steps, for example, 10, 20 or 100, and you get an ordinary deep neural network, which you then teach with ordinary Backpropagation.
But there is a problem. As soon as we start talking about deep neural networks - where there are 10, 20, 100 layers - there is nothing left from the gradients that should pass to the very beginning from the end, there are no 100 layers. We need to do something about it. In this place a certain hack was invented, a beautiful engineering solution called LSTM or GRU is the memory cells.
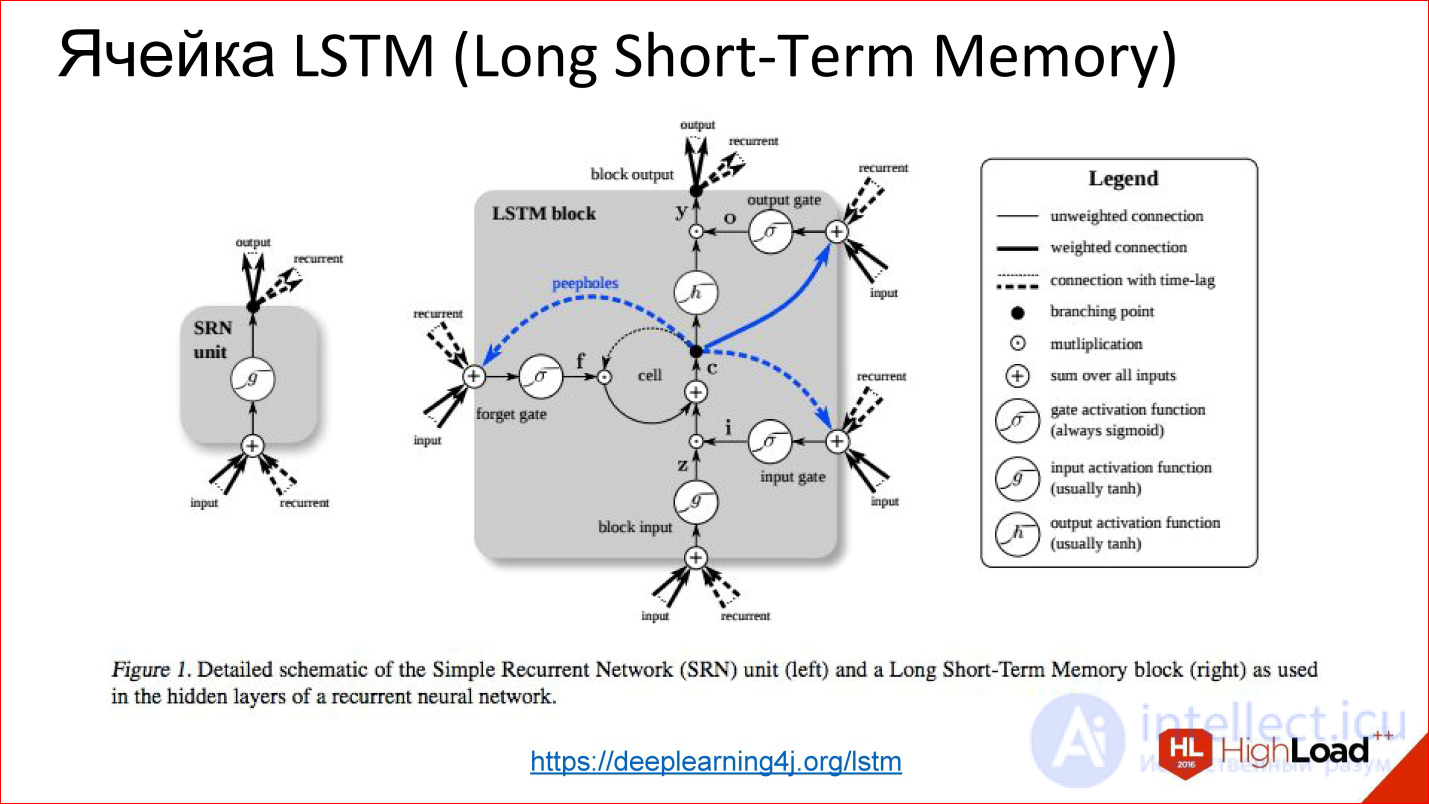
https://deeplearning4j.org/lstm
Their idea is that the visualization of a normal neuron is replaced by some kind of clever thing that has memory and there is a gate, which control when this memory needs to be reset, rewritten or saved, etc. These gates are also trained in the same way as everything else. In fact, this cell, when it has learned, can tell the neural network that we are now keeping this internal state for a long time, for example, 100 steps. Then, when the neural network used this state for something, it can be reset. It became unnecessary, we went to a new count.
On all more or less serious tests, these neural networks strongly do the usual classical recurrent ones, which are simply on neurons. Almost all recurrent networks are currently built on either LSTM or GRU.
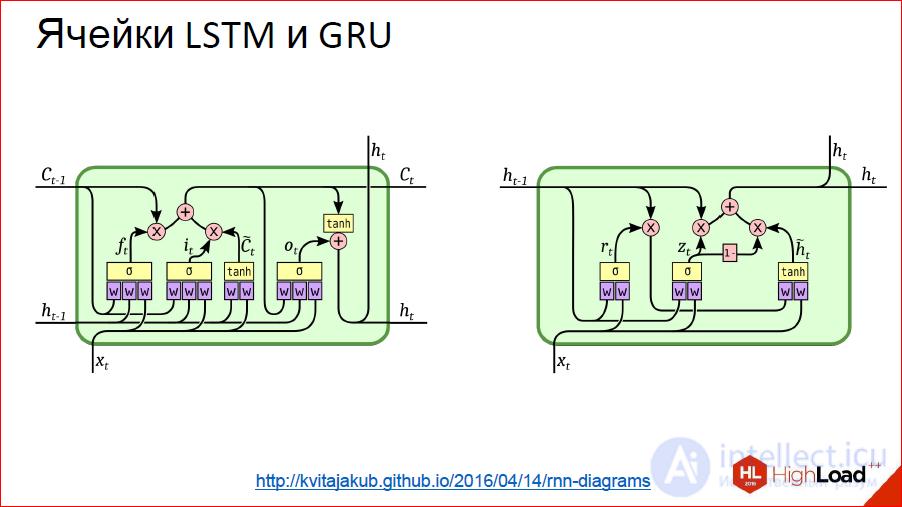
http://kvitajakub.github.io/2016/04/14/rnn-diagrams
I will not go into what it is inside, but these are such tricky blocks, much more complicated than ordinary neurons, but, in fact, they are similar. There are some gateways that control this very “remember - do not remember”, “pass on - do not pass on”.
These were the classic recurrent neural networks. Then begins the topic, which is often silent, but it is also important.
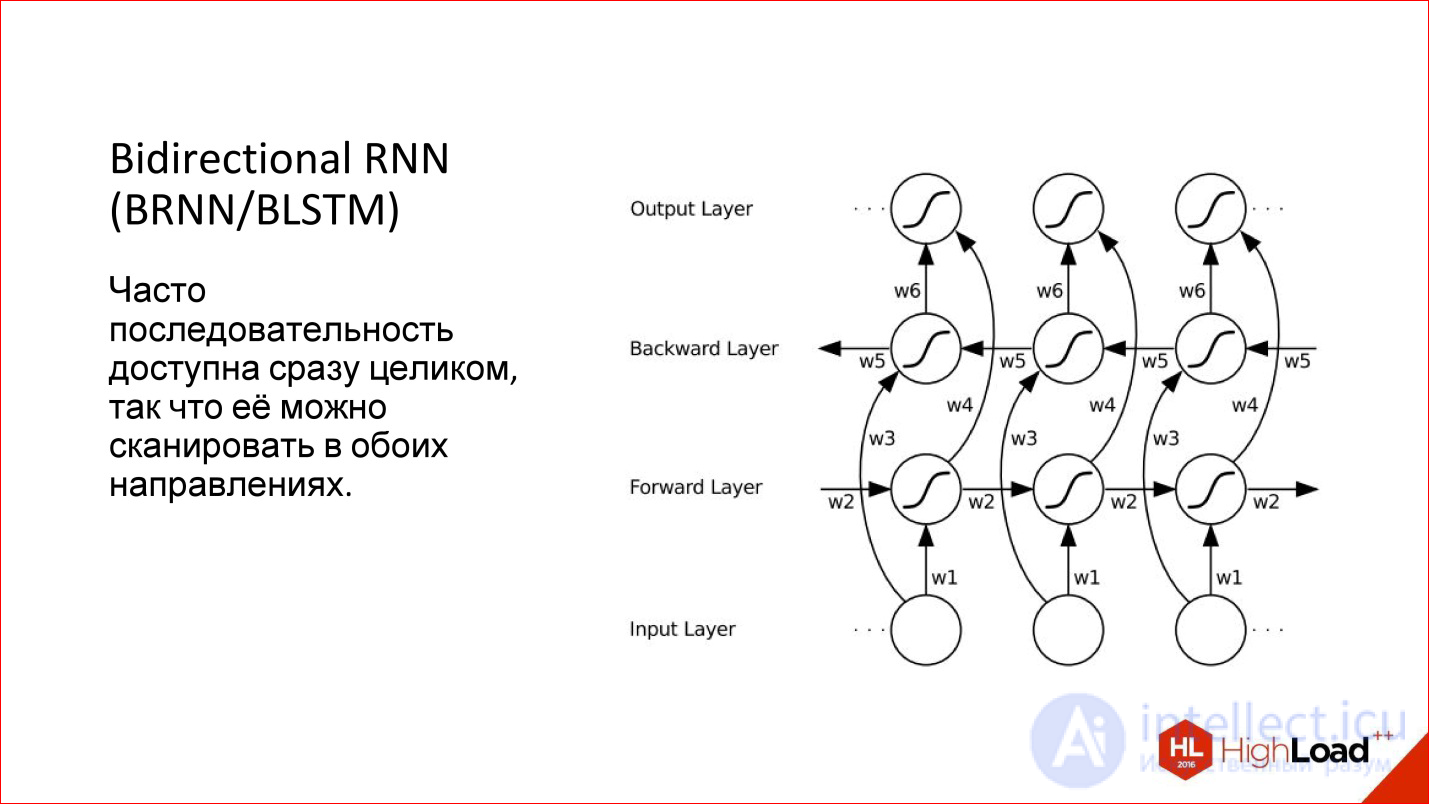
When we work with a sequence in a recurrent network, we usually feed one element, then the next, and set the previous state of the network to the input, this natural direction arises - from left to right. But it is not the only one! If we have, for example, a proposal, we begin to submit his words in the usual way to the neural network - yes, this is the normal way, but why not submit it from the end?
That is, in many cases, the sequence has been given entirely from the very beginning. We have this proposal, and it makes no sense to somehow single out one direction relative to another. We can run a neural network on the one hand, on the other hand, actually having 2 neural networks, and then combine their result.
This is called Bidirectional - a bi-directional recurrent neural network. Their quality is even higher than conventional recurrent networks, because there is more context: for each point there are now 2 contexts - what was before, and what will be after. For many tasks this adds quality, especially for language related tasks.
For example, there is German, where in the end something will definitely be hung up, and the sentence will change - such a network will help.
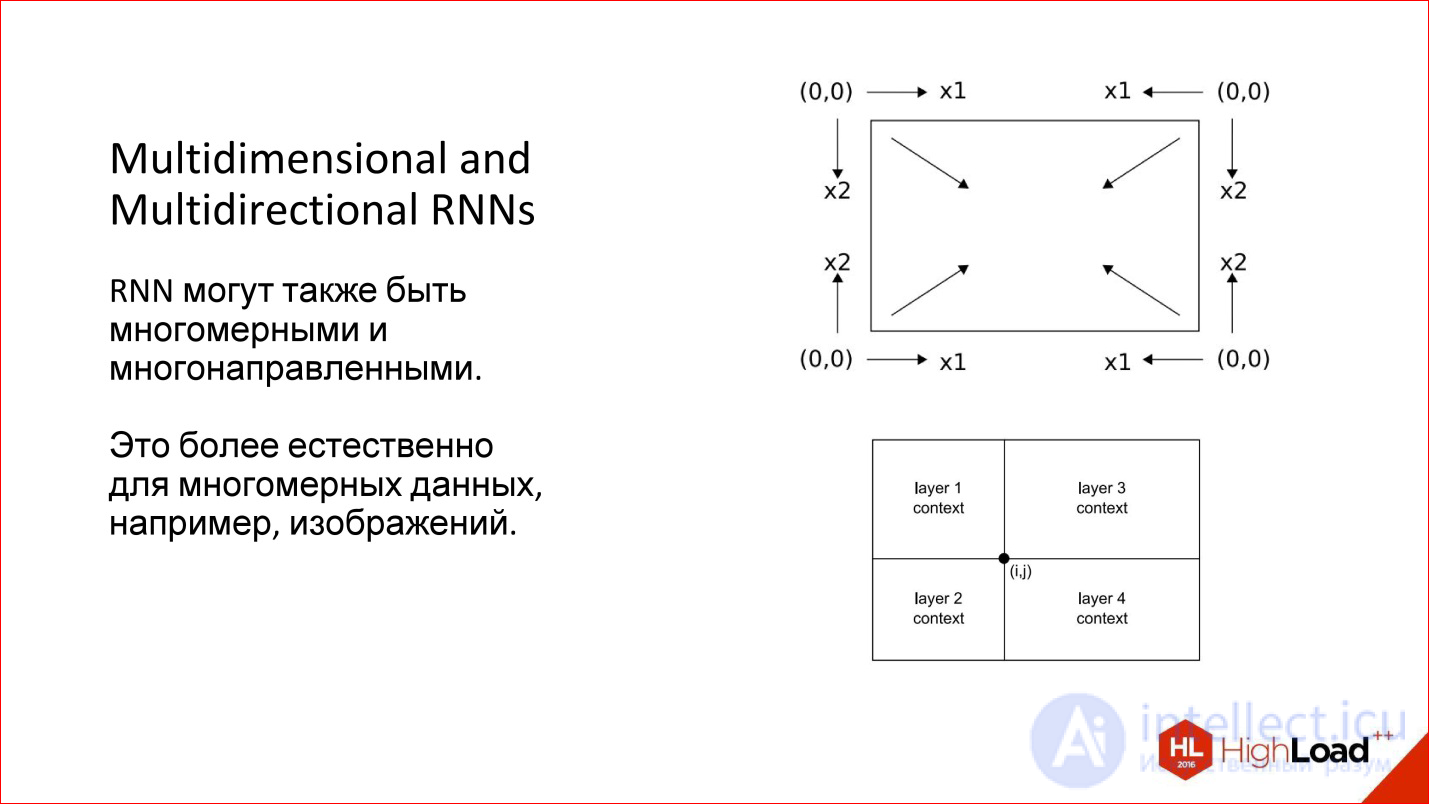
Moreover, we considered one-dimensional cases - for example, sentences. But there are multidimensional sequences - the same image can also be viewed as a sequence. Then he generally has 4 directions that are reasonable in their own way. For an arbitrary point of the image there are, in fact, 4 contexts with such a detour.
There are interesting multidimensional recurrent neural networks: they are both multidimensional and multidirectional. Now they are a little forgotten. This, by the way, is an old development, which is already 10 years old, probably, but now it is beginning to emerge.
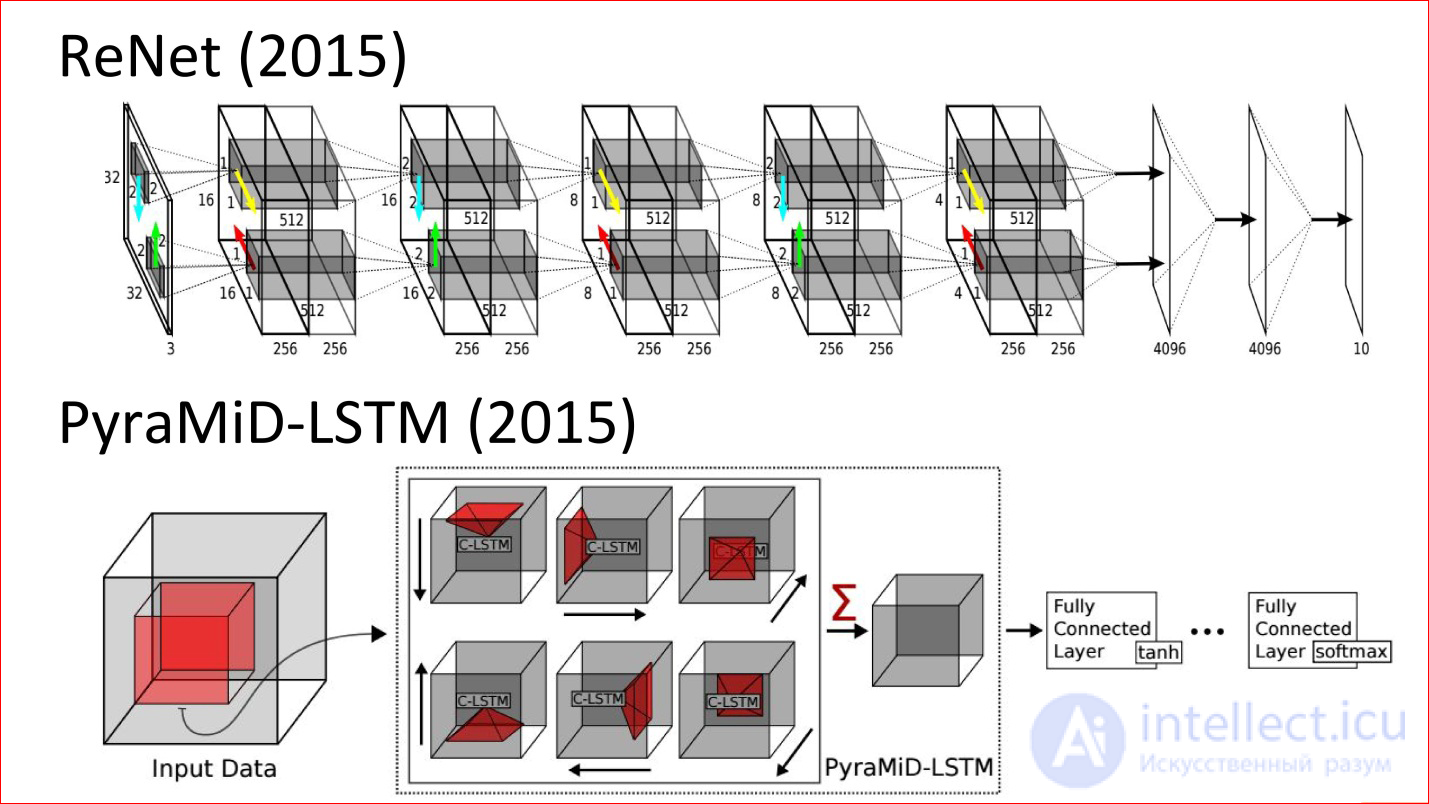
Here are the latest works (2015). This neural network is analogous to the classic LeNet neural network, which classified handwritten numbers. But now it is never convolutional, but recurrent and multidirectional. There are arrows that are in different directions in the image.
The second example is the tricky neural network, which was used for segmentation of brain sections. She, too, is never convolutional, but recurrent, and she won in some regular competition.
На самом деле это крутые технологии. Думаю, что в ближайшее время рекуррентные сети очень сильно потеснят сверточные потому, что даже для изображений они добавляют очень много чего. Это потенциально более мощный класс.
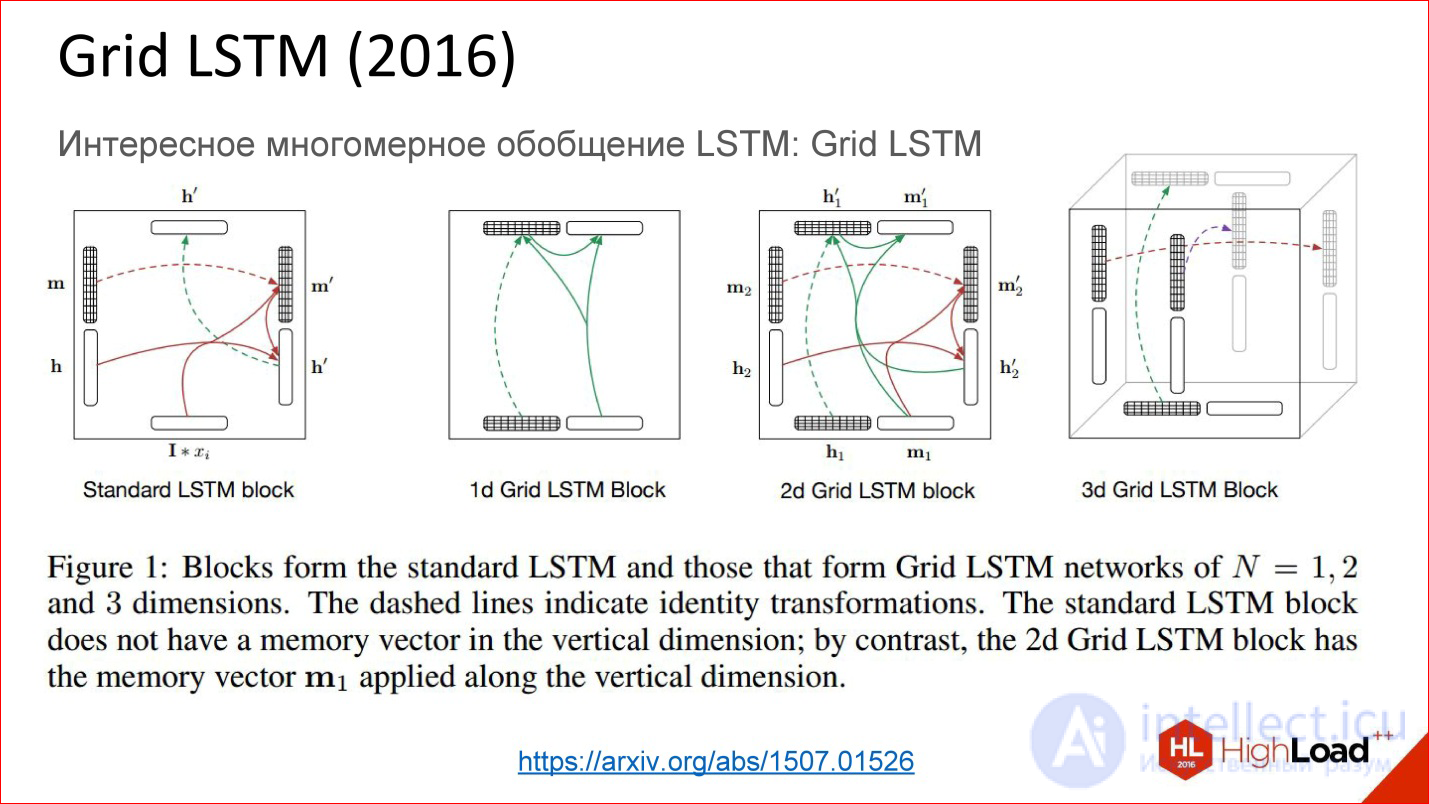
https://arxiv.org/abs/1507.01526
А еще есть совсем свежая разработка Grid LSTM, которая пока еще не очень осмыслена и осознана. На самом деле идея простая — взяли рекуррентную сеть, в какой-то момент заменили нейроны на какие-то хитрые ячейки, чтобы по времени можно было хранить состояние долго. Если наша сеть глубокая в этом направлении, то там нет никаких gate, градиенты также теряются. Что, если в этом направлении тоже что-то такое добавить? Да, добавили, оказалось круто!
Просто проблема — сейчас почти нет готовых программных библиотек, где это реализовано. Есть 1-2 кусочка кода, которые можно попытаться использовать. Надеюсь, что в ближайший год появятся общедоступные эти вещи, и будет совсем круто.
Это замечательная вещь, смотрите, что с ней будет, она хорошая.
Теперь начинаются продвинутые темы.
Смешивание различных модальностей в одной нейросети, например, изображение и текст
Мультимодальное обучение — это идейно тоже простая штука, когда мы берем и в нейросети смешиваем 2 модальности, например, картинки и текст. До этого мы рассматривали случаи работы на 1 модальности — только на картинках, только на звуке, только на тексте. Но можно и смешать!

http://arxiv.org/abs/1411.4555
Например, есть классный кейс — генерация описания картинок. Вы подаете в нейросеть картинку, она на выходе генерит текст, допустим, на нормальном английском языке, который описывает, что происходит на этой картинке. Эта технология еще несколько лет назад казалась вообще не возможной потому, что непонятно было, как это сделать. Но сейчас это реализовано.
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
Внутри все устроено просто. Есть сверточная нейросеть, которая обрабатывает изображение, выделяет из него какие-то признаки и записывает его в каком-то хитром векторе состояния. Есть рекуррентная сеть, которая научена из этого состояния генерить и разворачивать текст.
Это совмещение 2-х модальностей очень продуктивно. Таких примеров много.
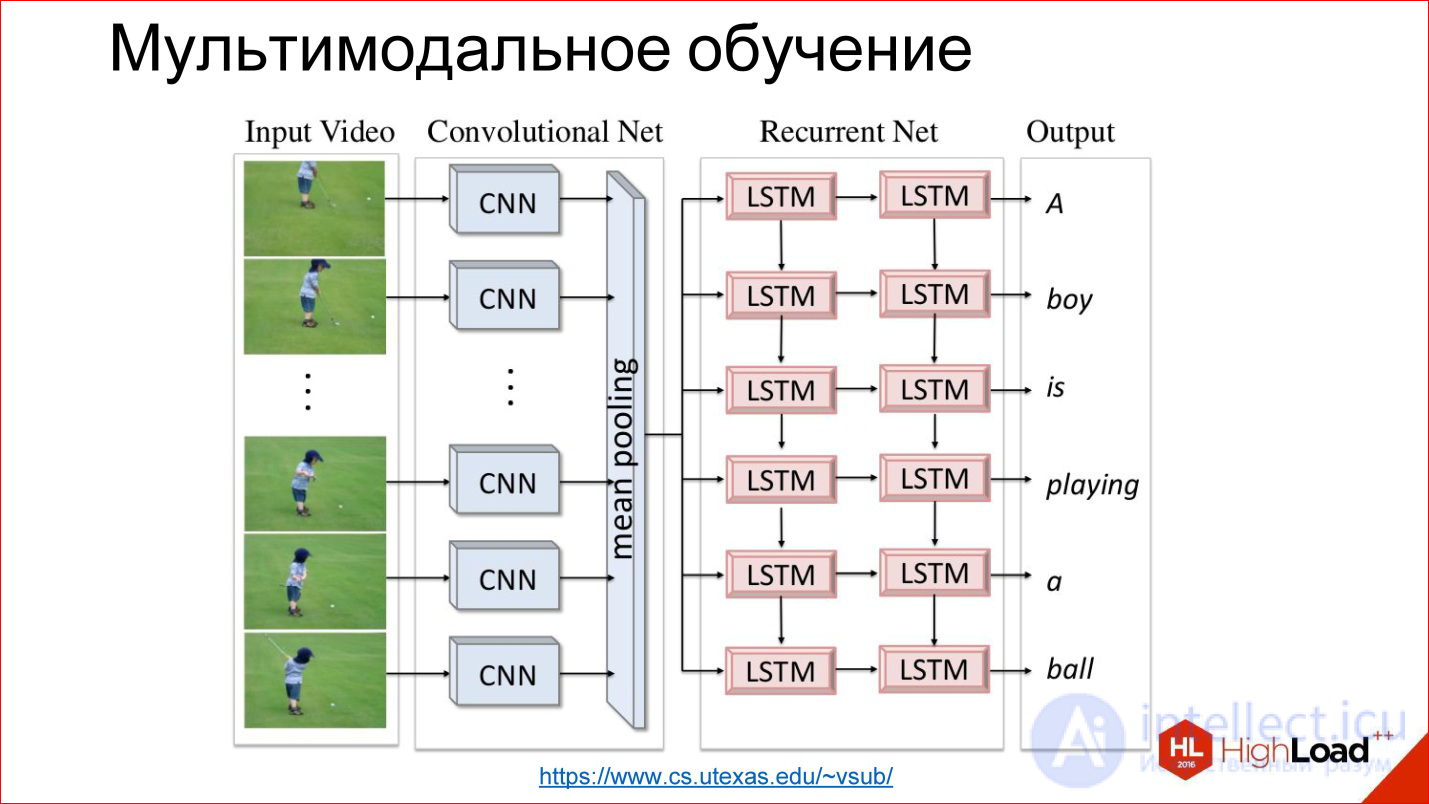
https://www.cs.utexas.edu/~vsub/
Есть, например, интересная задача аннотирования видео. По сути, к предыдущей задаче просто добавляется еще одно измерение — время.
For example:
It is interesting!
In a little more detail, how multi-modal learning looks like inside.
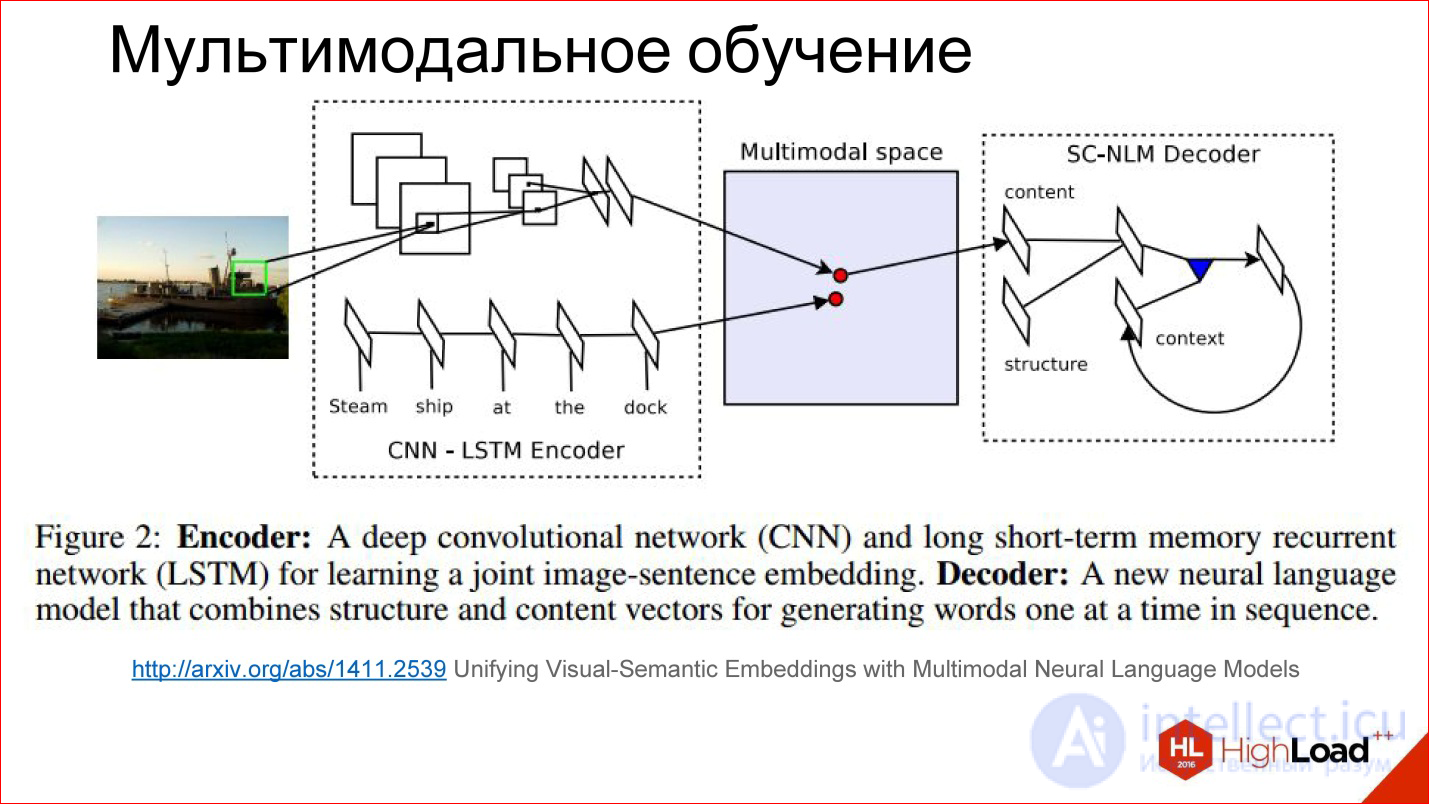
http://arxiv.org/abs/1411.2539
There is some tricky space that we can’t see at all, but it exists within the neural network in the form of these scales, which it considers for itself. It turns out that in the process of learning we learn two different neural networks: convolutional and recurrent for the text that describes the picture and for the picture itself to generate vectors in this tricky space in one place. That is, to reduce 2 modalities into one.
If we have learned to do this, then further there it is not important to some extent: submit a picture - generate text, submit text - find a picture. You can play with different things and build interesting things.
By the way, there are already attempts to build networks that generate pictures in the text. This is interesting, it also works. Not very good yet, but the potential is huge.
When it is necessary to work with sequences of arbitrary length at the input and / or output
The second interesting topic is Sequence Learning or the seq2seq paradigm. I will not even translate it. The idea is that a lot of your tasks come down to the fact that you have sequences. That is, not just a picture that needs to be classified, to give out one number, but there is one sequence, and the output needs another sequence.
For example, the translation is a classic task of Sequence 2 Sequence Learning: you set the text in English, you want to receive it in French.
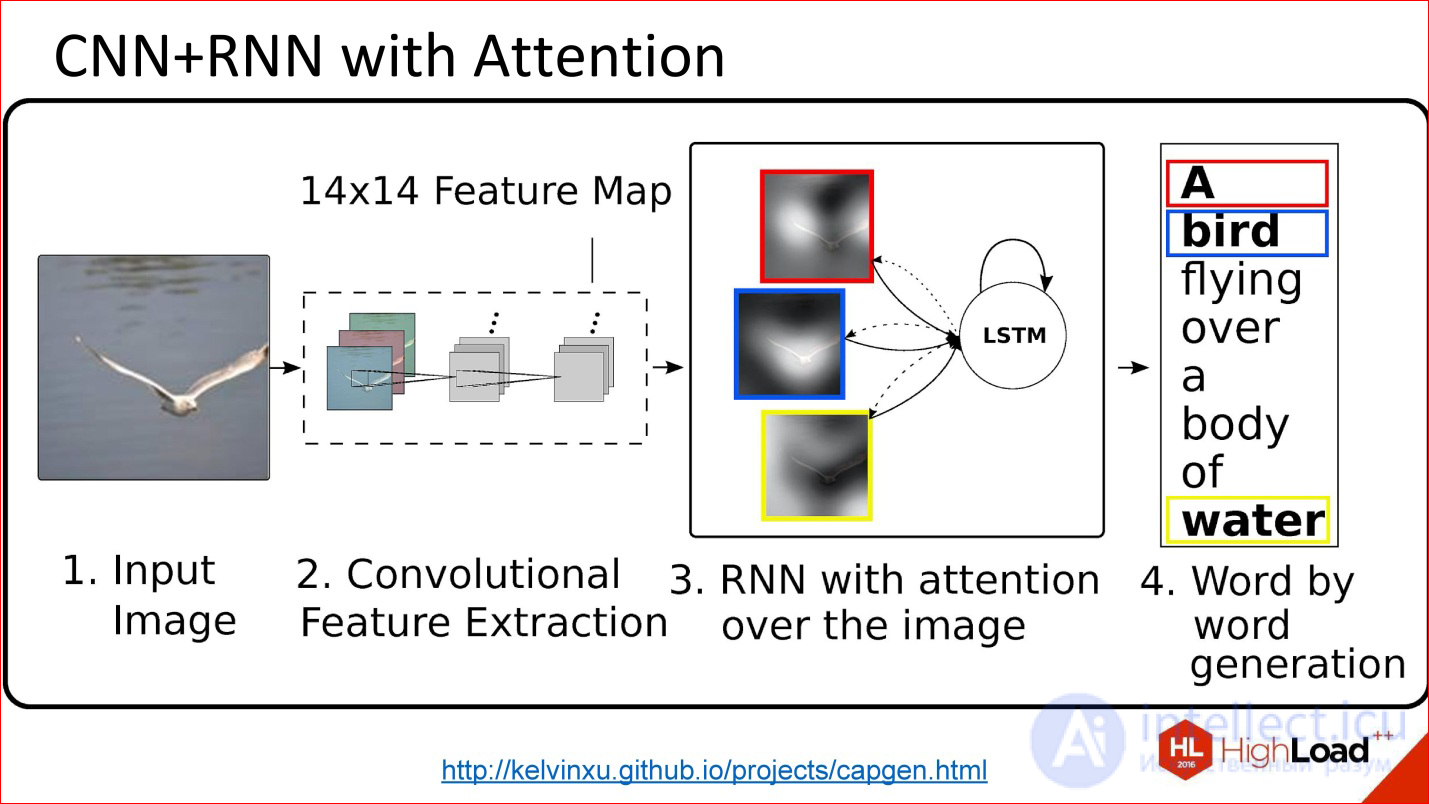
There are a lot of such tasks. This is a picture description case.
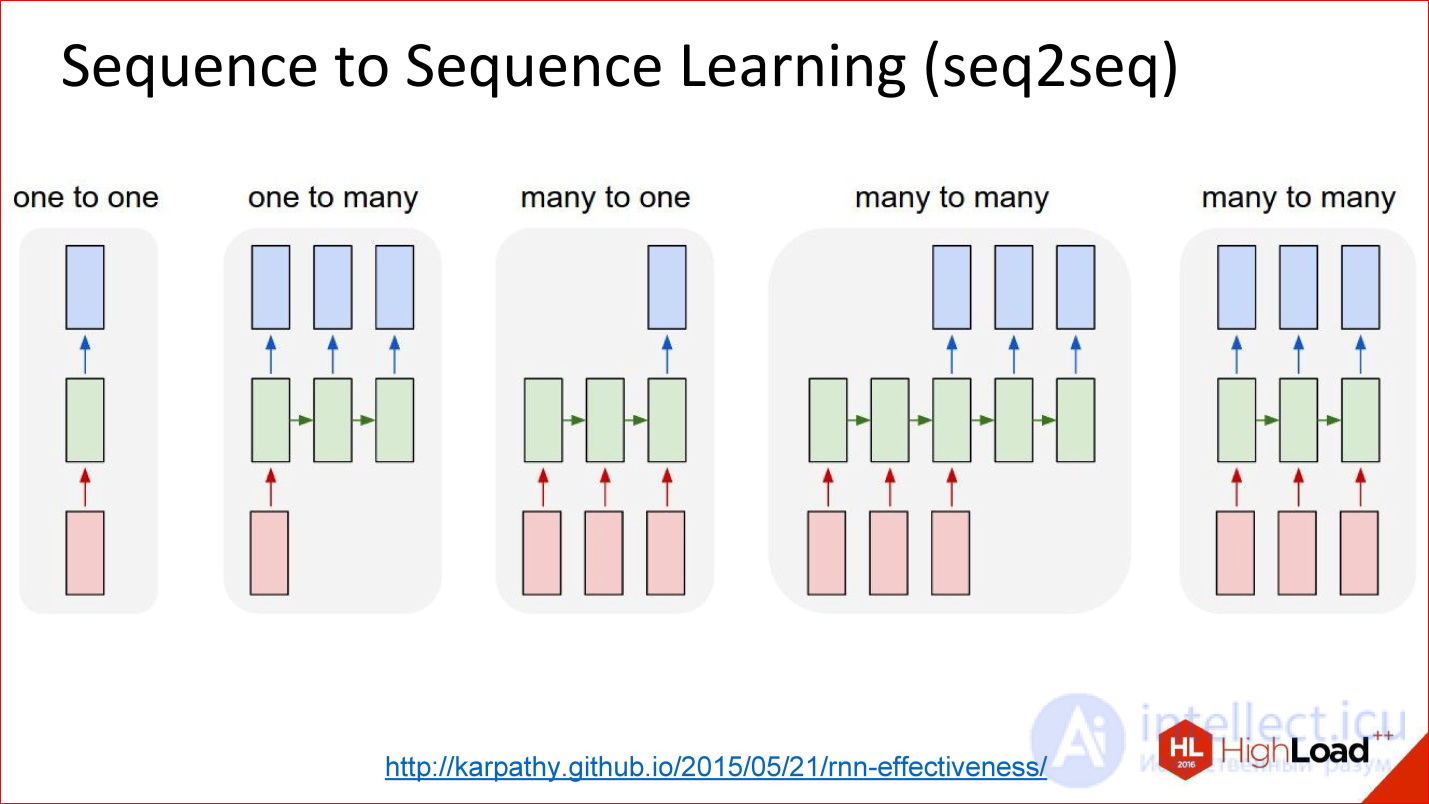
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Ordinary neural networks, which we considered - drove something, drove through the network, removed at the output - not interesting.
There is an option called One to many. They drove the picture into the network, and then she went to work, work and generated a description of this picture. Great.
You can in the opposite direction. For example, the classification of texts. This is the favorite task of all marketers - to classify tweets - they are positive or negative in terms of emotional coloring. You drove your proposal into a recurrent neural network, and then at the end it gave one number — yes, positively colored tweet, no, negatively colored tweet, or neutral, for example.
There is a story about the translation. You have long driven the sequence in the same language. Then the network worked and started generating a sequence in another language. This is generally the most common setting.
There is another interesting setting when the inputs and outputs are synchronized. For example, if you need to annotate each frame of the image, there is something on it or not.
The figure shows all the variants of Sequence 2 Sequence Learning, and this is a very powerful paradigm. It is powerful in that if everything inside the neural network is differentiable - and the neural networks that we discussed are all differentiable inside, this means that you can train the neural network, so to speak, end-to-end: some sequences have been fed to the input, others and what happens inside doesn’t matter to you. The neural network itself will cope - at the entrance a bunch of examples in English, on the way out - a bunch of examples in French - great, she will learn the translation. And really with good quality, if you have a large database and good computing power to drive it all away.
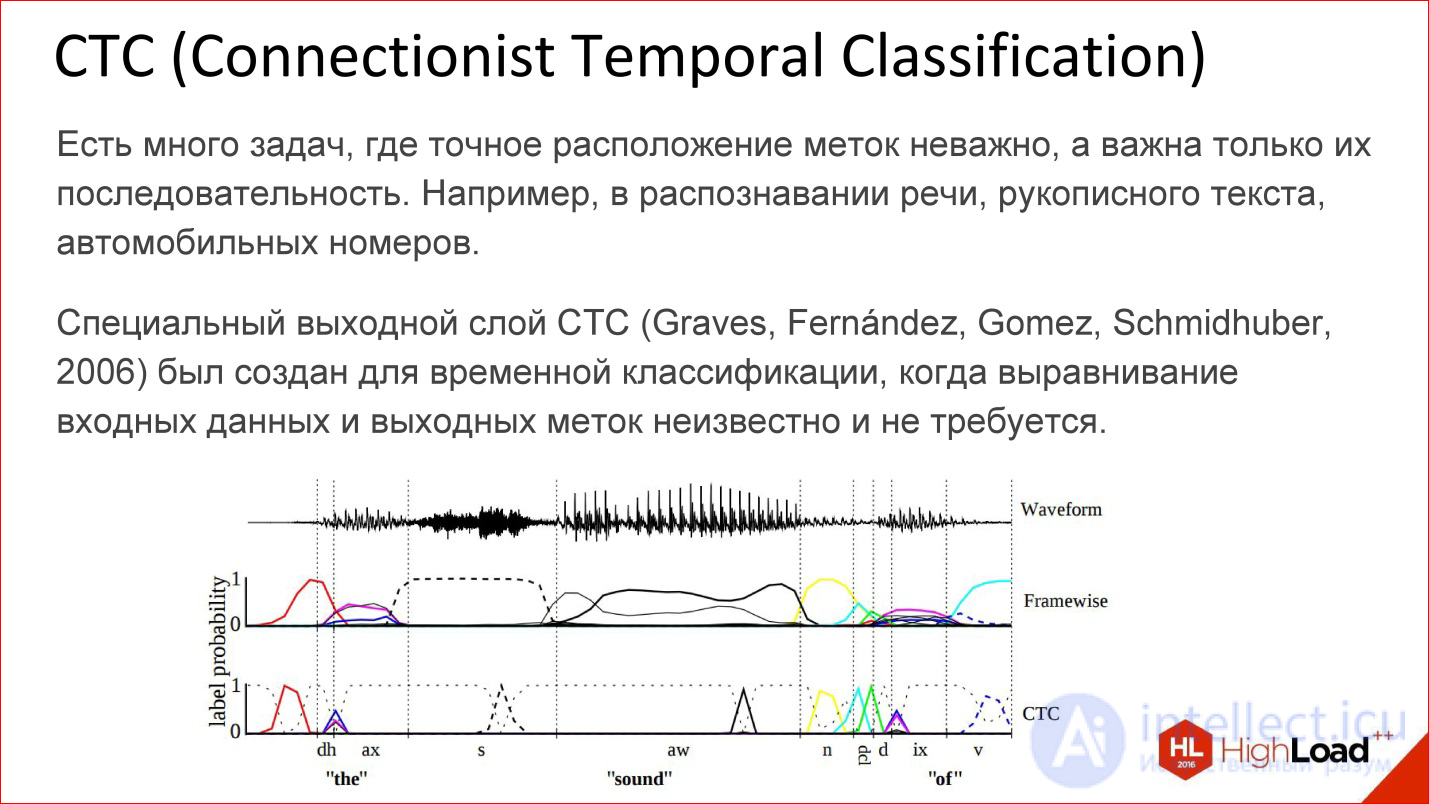
Another insanely important thing, about which they almost never speak, but without which neither Google’s speech recognition nor Baidu, nor Microsoft - CTC works.
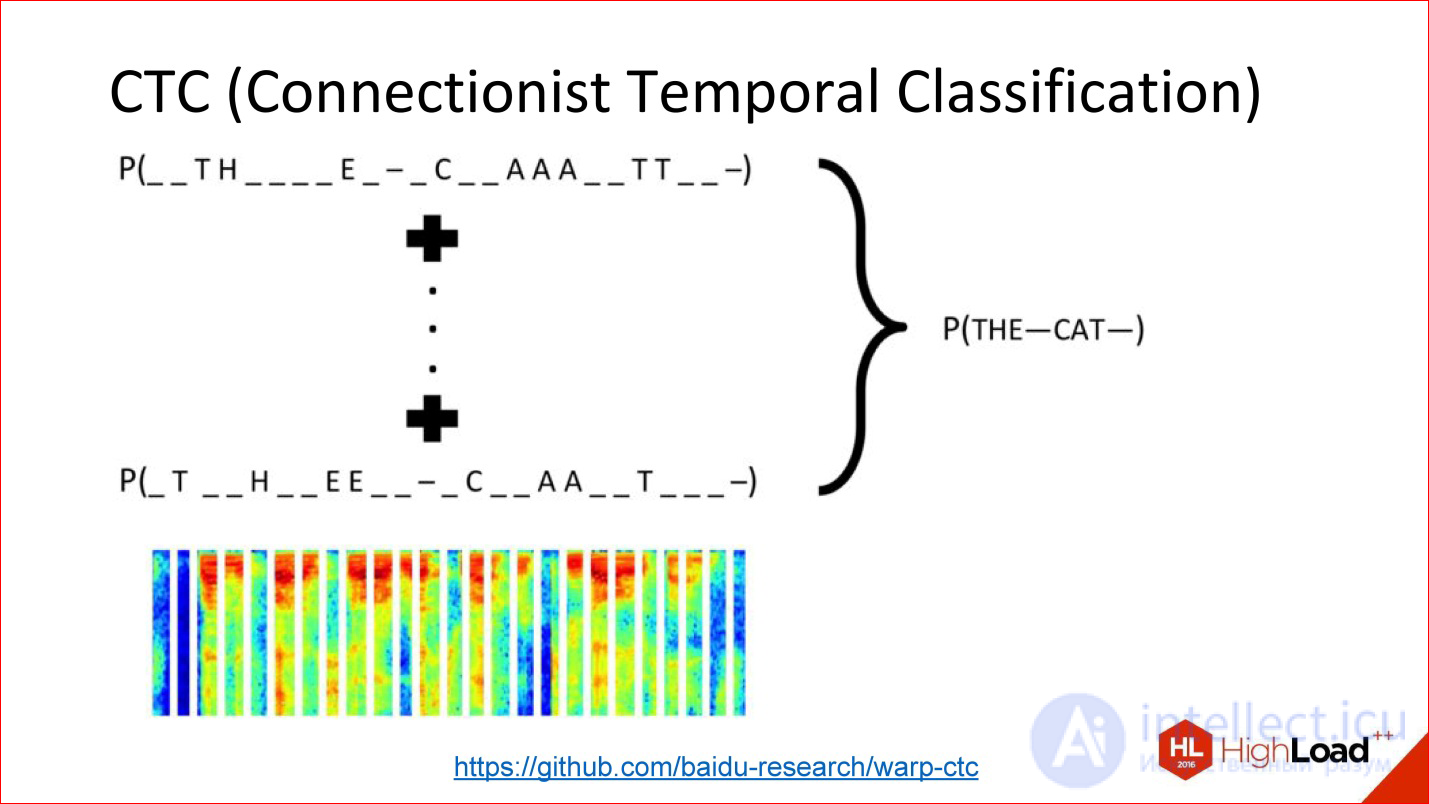
https://github.com/baidu-research/warp-ctc
CTC is such a tricky output layer. What is he doing? There are many tasks in which the alignment within this sequence is not really important. There is a speech recognition task. You took a sound, cut it into short frames of 50 ms, for example, and then you need to generate at the output what word it was, a sequence of phonemes. By and large, you do not care where in the original signal was one or another phoneme. It is only the order between them that is important to get a word at the exit.
The fact that you can throw out all the information about the exact position, in fact, a lot of what adds. For example, you do not need to have accurate markup of phonemes across all frames of sound, because getting such markup is insanely expensive. You need to plant a man who will mark everything.
You can just take everything and throw it away - there is input data, there is a way out - what should happen in terms of the output sequence is a word, there is this tricky CTC-layer that will do some kind of alignment inside itself, and this will allow, again, end- to-end to train such a tricky network, for which you did not mark anything at all.
This is a powerful thing, it is also not implemented in all modern packages. But, for example, a year ago Baidu laid out its implementation of the CTC layer - this is great.
Just a couple of words about different architectures.
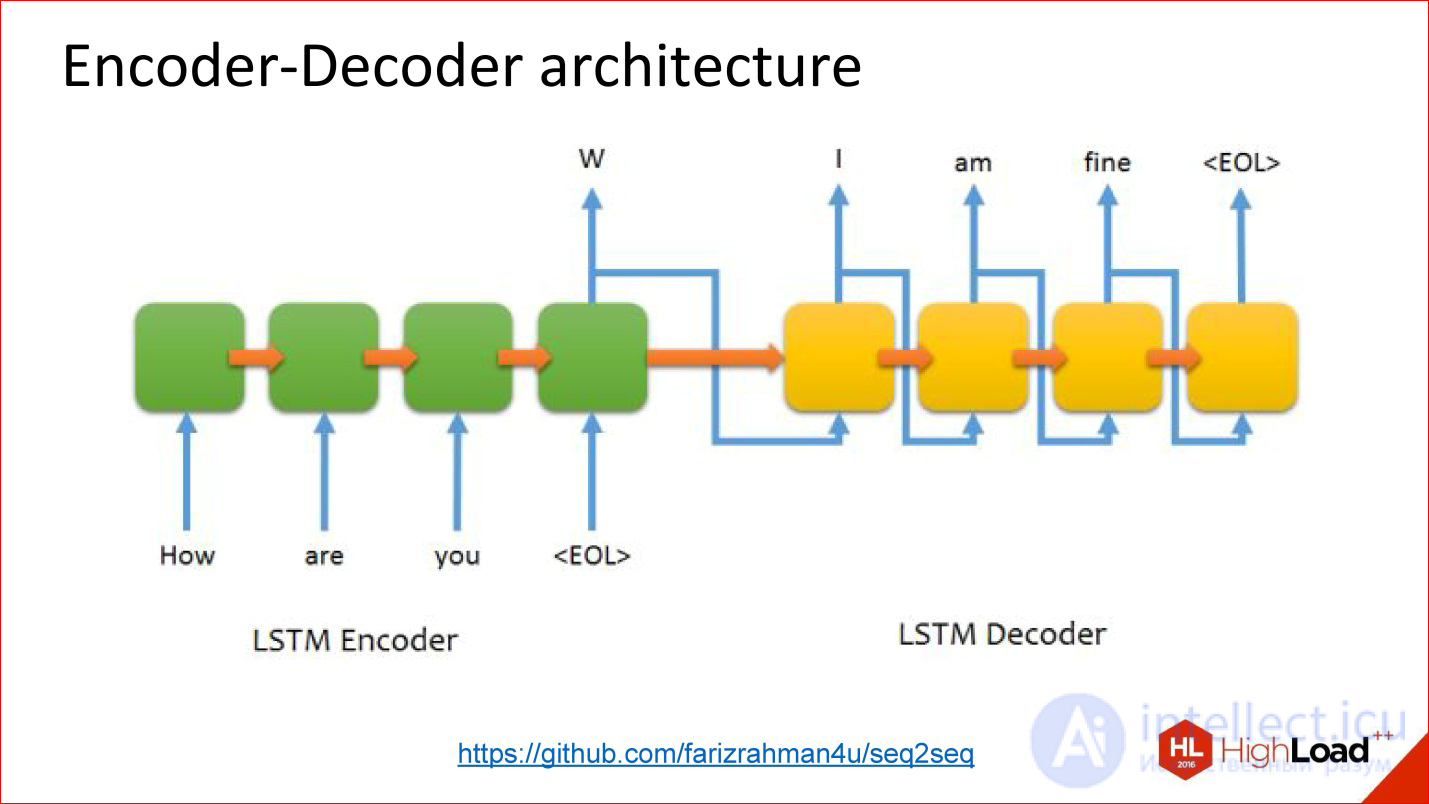
https://github.com/farizrahman4u/seq2seq
There is a classic architecture Encoder-Decoder. The translation example, about which I spoke, is almost entirely reduced to this architecture.
There is one input neural network, words are fed into it. The output of this neural network is ignored, as it were, until the end of sentence character is given. After that, the second network turns on and reads the state of the first network and starts generating the output words from it. At the entrance are her results in the previous step.
It works. Many translation systems work like this.
But this architecture has one problem - also a bottleneck. The state vector (the size of the hidden layer), which is transmitted, is limited and fixed. That is, it turns out that it is the same for both the short sentence and the insanely long one — this is not very good. It may be that a long sentence does not fit into this volume.
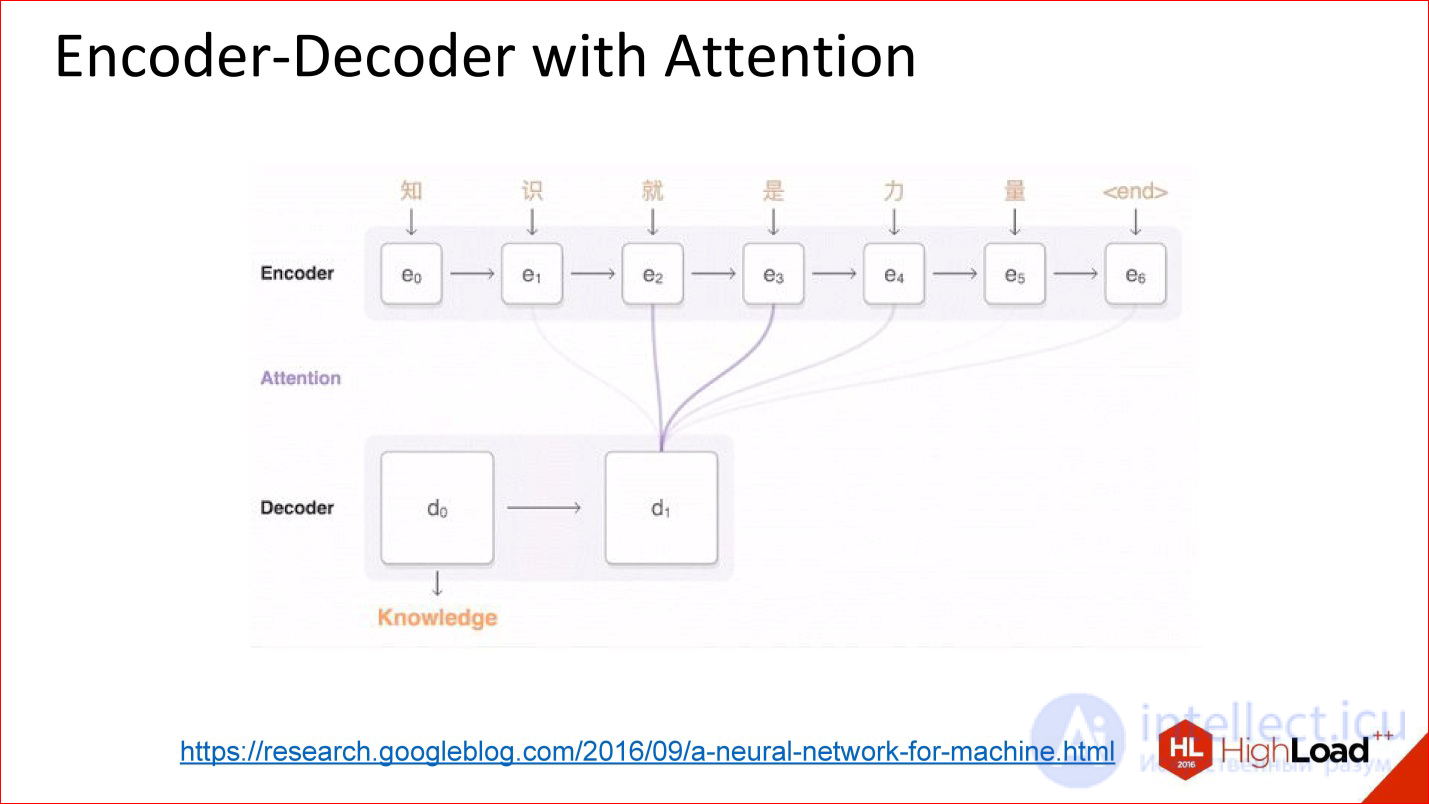
https://research.googleblog.com/2016/09/a-neural-network-for-machine.html
Appeared architecture, as they say, with attention.
Attention - this is such a tricky thing, which in fact is, in fact, very simple. The idea is that now the decoder output to the neural network does not look at the output value of the previous neural network, but at all its intermediate states, but with some weights. Weights are coefficients, how much you need to take each of those states into the final large amount that the decoder will work with.
That is, attention is actually a simple linear combination of all previous states of an encoder, which is also being trained.
Neural networks with attention in fact work very well. On translation tasks and other complex tasks, they are very much superior in quality to neural networks without attention.
Часть 1 Introduction to neural network architectures. Classification of neural networks, principle of operation
Часть 2 Grigory Sapunov (Intento) - Introduction to neural network architectures. Classification
Часть 3 Мультимодальное обучение (Multimodal Learning) - Introduction to neural network architectures.

Comments
To leave a comment
Computational Neuroscience (Theory of Neuroscience) Theory and Applications of Artificial Neural Networks
Terms: Computational Neuroscience (Theory of Neuroscience) Theory and Applications of Artificial Neural Networks