Lecture
Это продолжение увлекательной статьи про архитектура нейронных сетей.
...
осмыслена и осознана. На самом деле идея простая — взяли рекуррентную сеть, в какой-то момент заменили нейроны на какие-то хитрые ячейки, чтобы по времени можно было хранить состояние долго. Если наша сеть глубокая в этом направлении, то там нет никаких gate, градиенты также теряются. Что, если в этом направлении тоже что-то такое добавить? Да, добавили, оказалось круто!
Просто проблема — сейчас почти нет готовых программных библиотек, где это реализовано. Есть 1-2 кусочка кода, которые можно попытаться использовать. Надеюсь, что в ближайший год появятся общедоступные эти вещи, и будет совсем круто.
Это замечательная вещь, смотрите, что с ней будет, она хорошая.
Теперь начинаются продвинутые темы.
Смешивание различных модальностей в одной нейросети, например, изображение и текст
Мультимодальное обучение — это идейно тоже простая штука, когда мы берем и в нейросети смешиваем 2 модальности, например, картинки и текст. До этого мы рассматривали случаи работы на 1 модальности — только на картинках, только на звуке, только на тексте. Но можно и смешать!

http://arxiv.org/abs/1411.4555
Например, есть классный кейс — генерация описания картинок. Вы подаете в нейросеть картинку, она на выходе генерит текст, допустим, на нормальном английском языке, который описывает, что происходит на этой картинке. Эта технология еще несколько лет назад казалась вообще не возможной потому, что непонятно было, как это сделать. Но сейчас это реализовано.
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
Inside, everything is simple. There is a convolutional neural network that processes the image, extracts some signs from it and writes it in some tricky state vector. There is a recurrent network that is taught to generate and expand text from this state.
This combination of 2 modalities is very productive. There are many such examples.
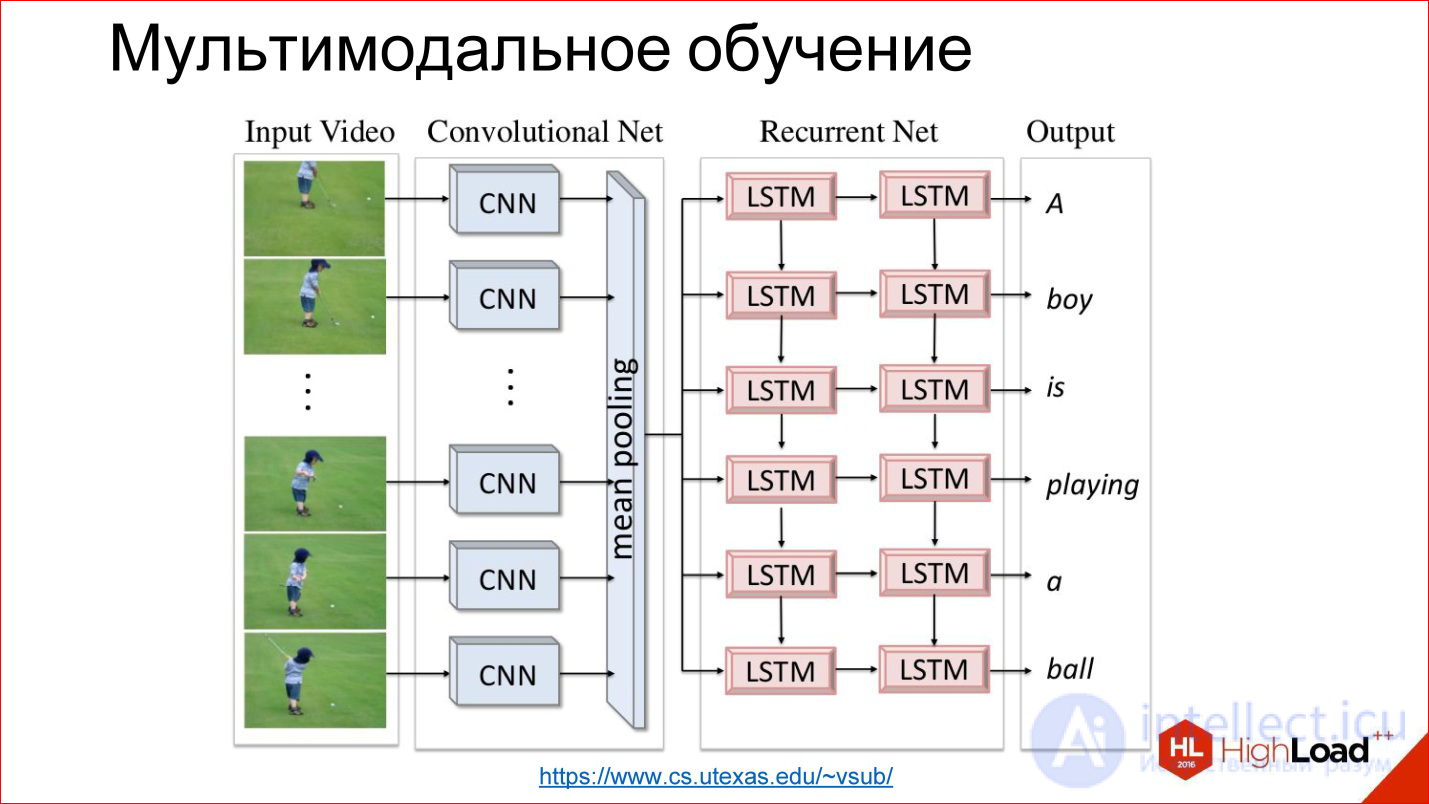
https://www.cs.utexas.edu/~vsub/
There is, for example, an interesting task of annotating a video. In fact, another dimension is simply added to the previous task - time.
For example:
It is interesting!
In a little more detail, how multi-modal learning looks like inside.
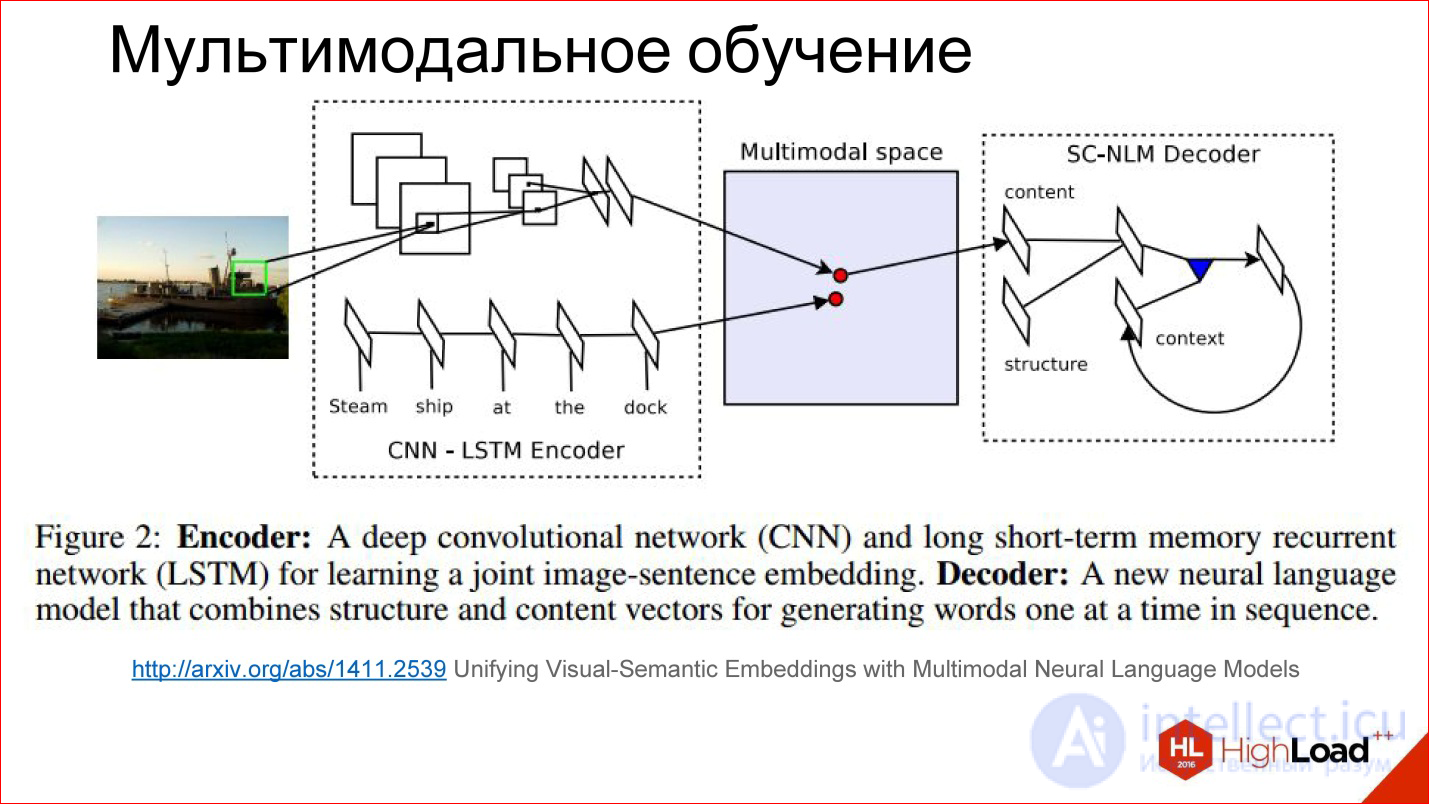
http://arxiv.org/abs/1411.2539
There is some tricky space that we can’t see at all, but it exists within the neural network in the form of these scales, which it considers for itself. It turns out that in the process of learning we learn two different neural networks: convolutional and recurrent for the text that describes the picture and for the picture itself to generate vectors in this tricky space in one place. That is, to reduce 2 modalities into one.
If we have learned to do this, then further there it is not important to some extent: submit a picture - generate text, submit text - find a picture. You can play with different things and build interesting things.
By the way, there are already attempts to build networks that generate pictures in the text. This is interesting, it also works. Not very good yet, but the potential is huge.
When it is necessary to work with sequences of arbitrary length at the input and / or output
The second interesting topic is Sequence Learning or the seq2seq paradigm. I will not even translate it. The idea is that a lot of your tasks come down to the fact that you have sequences. That is, not just a picture that needs to be classified, to give out one number, but there is one sequence, and the output needs another sequence.
For example, the translation is a classic task of Sequence 2 Sequence Learning: you set the text in English, you want to receive it in French.
There are a lot of such tasks. This is a picture description case.
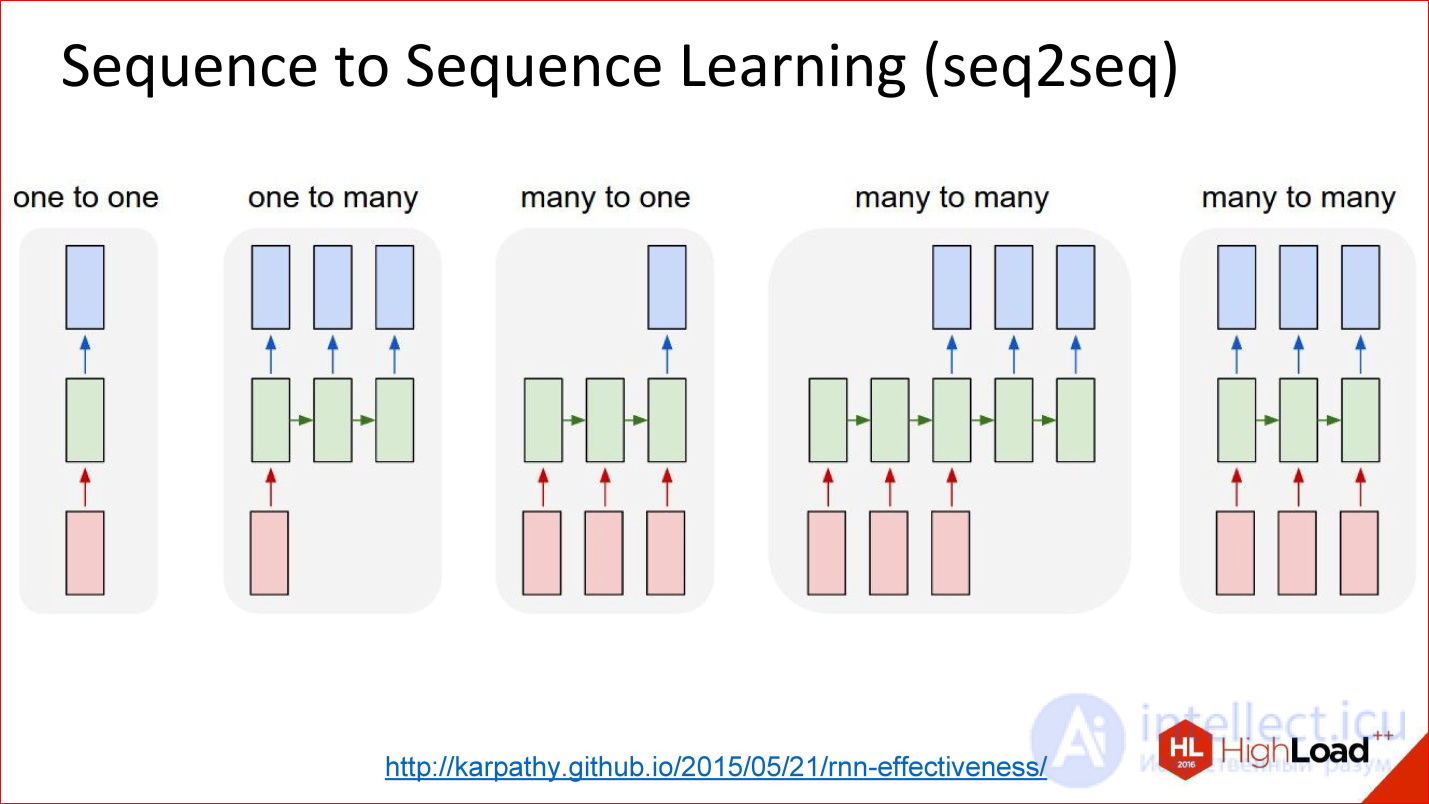
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Ordinary neural networks, which we considered - drove something, drove through the network, removed at the output - not interesting.
There is an option called One to many. They drove the picture into the network, and then she went to work, work and generated a description of this picture. Great.
You can in the opposite direction. For example, the classification of texts. This is the favorite task of all marketers - to classify tweets - they are positive or negative in terms of emotional coloring. You drove your proposal into a recurrent neural network, and then at the end it gave one number — yes, positively colored tweet, no, negatively colored tweet, or neutral, for example.
There is a story about the translation. You have long driven the sequence in the same language. Then the network worked and started generating a sequence in another language. This is generally the most common setting.
There is another interesting setting when the inputs and outputs are synchronized. For example, if you need to annotate each frame of the image, there is something on it or not.
The figure shows all the variants of Sequence 2 Sequence Learning, and this is a very powerful paradigm. It is powerful in that if everything inside the neural network is differentiable - and the neural networks that we discussed are all differentiable inside, this means that you can train the neural network, so to speak, end-to-end: some sequences have been fed to the input, others and what happens inside doesn’t matter to you. The neural network itself will cope - at the entrance a bunch of examples in English, on the way out - a bunch of examples in French - great, she will learn the translation. And really with good quality, if you have a large database and good computing power to drive it all away.
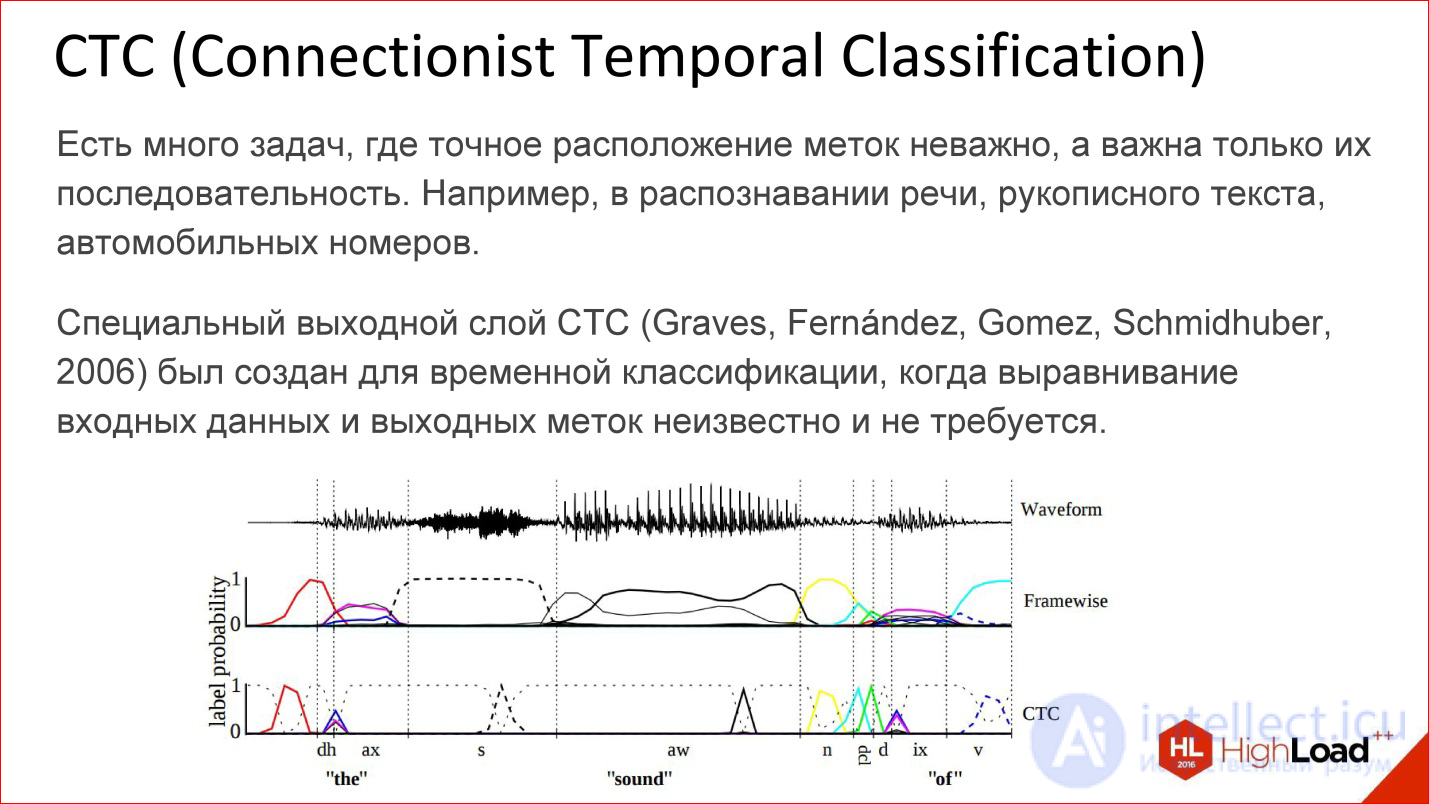
Another insanely important thing, about which they almost never speak, but without which neither Google’s speech recognition nor Baidu, nor Microsoft - CTC works.
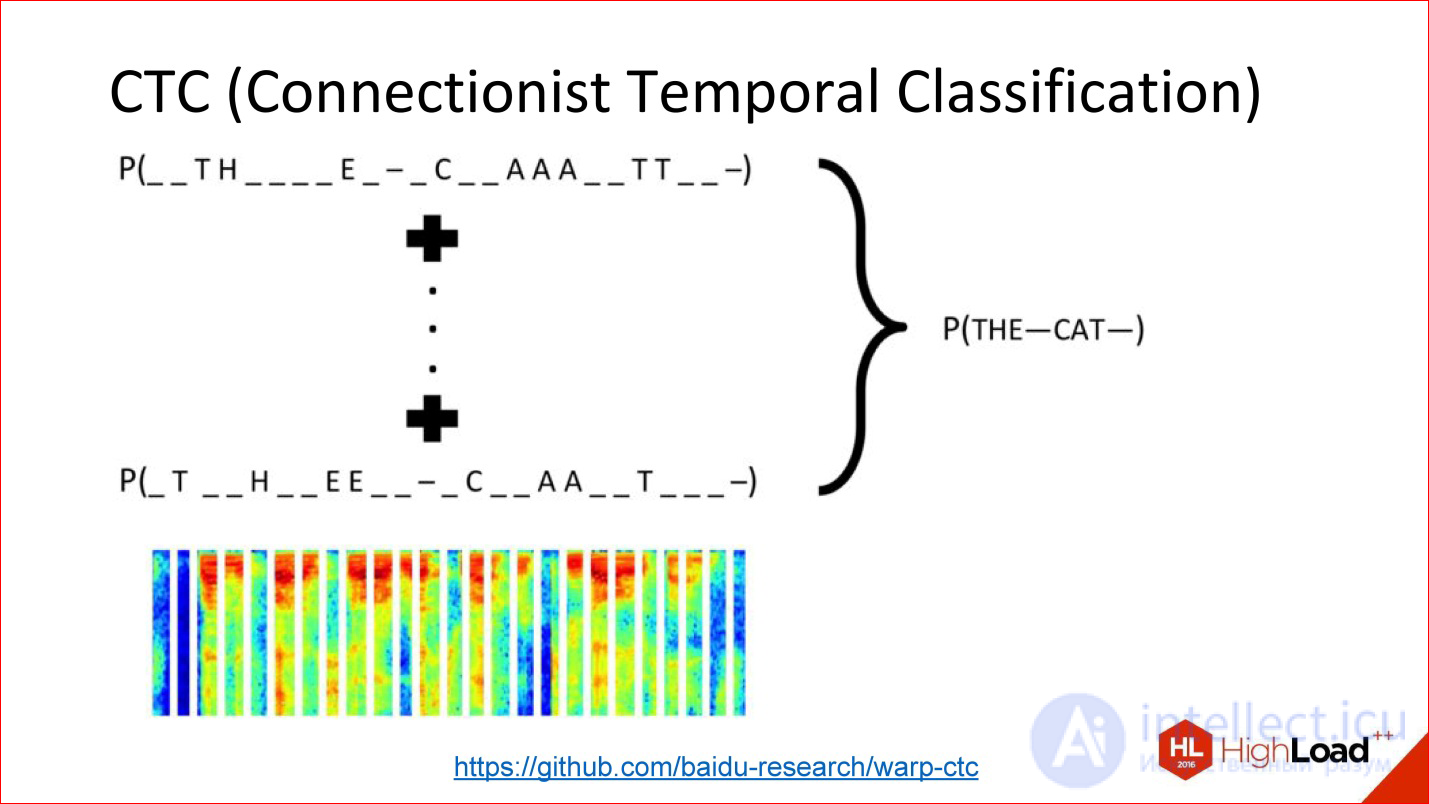
https://github.com/baidu-research/warp-ctc
CTC is such a tricky output layer. What is he doing? There are many tasks in which the alignment within this sequence is not really important. There is a speech recognition task. You took a sound, cut it into short frames of 50 ms, for example, and then you need to generate at the output what word it was, a sequence of phonemes. By and large, you do not care where in the original signal was one or another phoneme. It is only the order between them that is important to get a word at the exit.
The fact that you can throw out all the information about the exact position, in fact, a lot of what adds. For example, you do not need to have accurate markup of phonemes across all frames of sound, because getting such markup is insanely expensive. You need to plant a man who will mark everything.
You can just take everything and throw it away - there is input data, there is a way out - what should happen in terms of the output sequence is a word, there is this tricky CTC-layer that will do some kind of alignment inside itself, and this will allow, again, end- to-end to train such a tricky network, for which you did not mark anything at all.
This is a powerful thing, it is also not implemented in all modern packages. But, for example, a year ago Baidu laid out its implementation of the CTC layer - this is great.
Just a couple of words about different architectures.
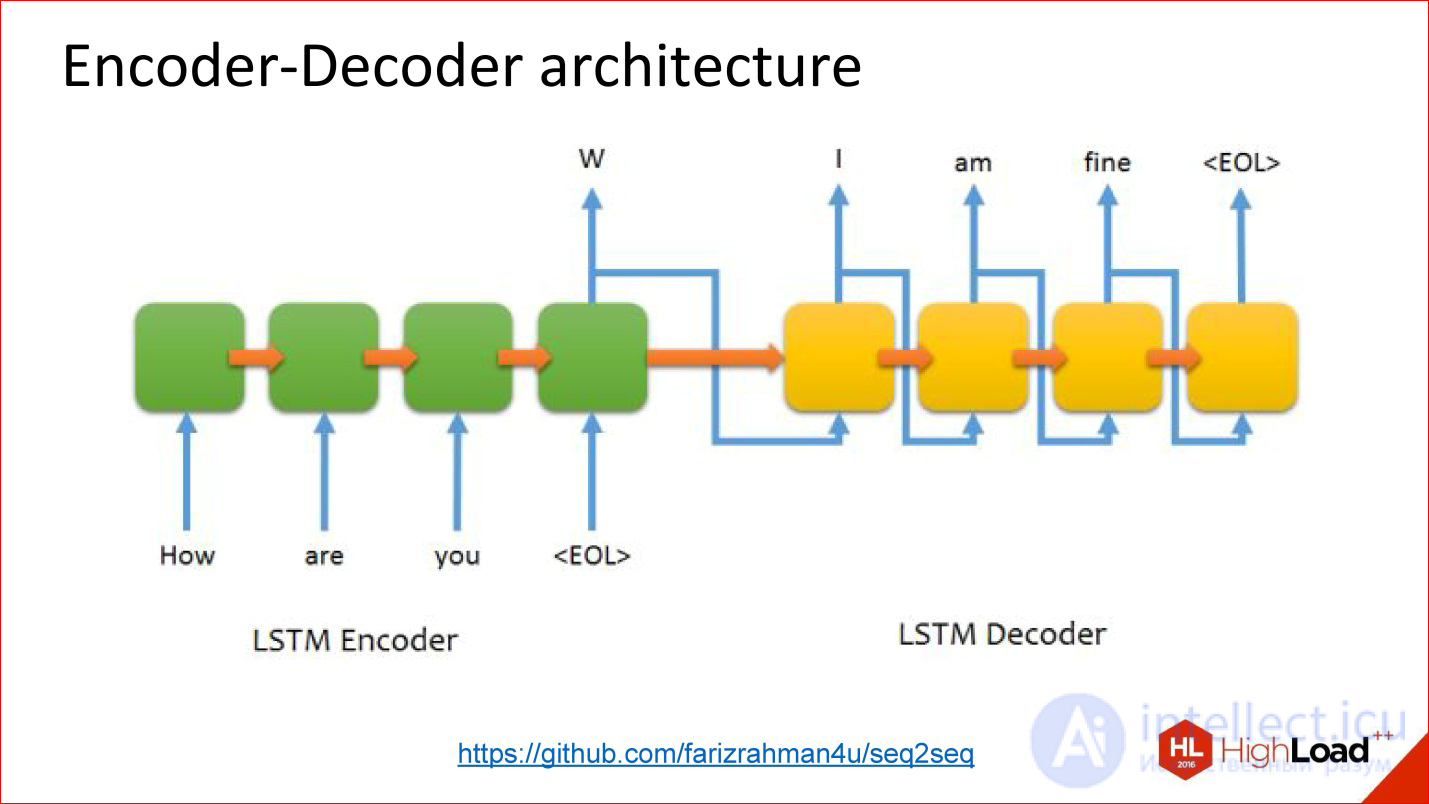
https://github.com/farizrahman4u/seq2seq
There is a classic architecture Encoder-Decoder. The translation example, about which I spoke, is almost entirely reduced to this architecture.
There is one input neural network, words are fed into it. The output of this neural network is ignored, as it were, until the end of sentence character is given. After that, the second network turns on and reads the state of the first network and starts generating the output words from it. At the entrance are her results in the previous step.
It works. Many translation systems work like this.
But this architecture has one problem - also a bottleneck. The state vector (the size of the hidden layer), which is transmitted, is limited and fixed. That is, it turns out that it is the same for both the short sentence and the insanely long one — this is not very good. It may be that a long sentence does not fit into this volume.
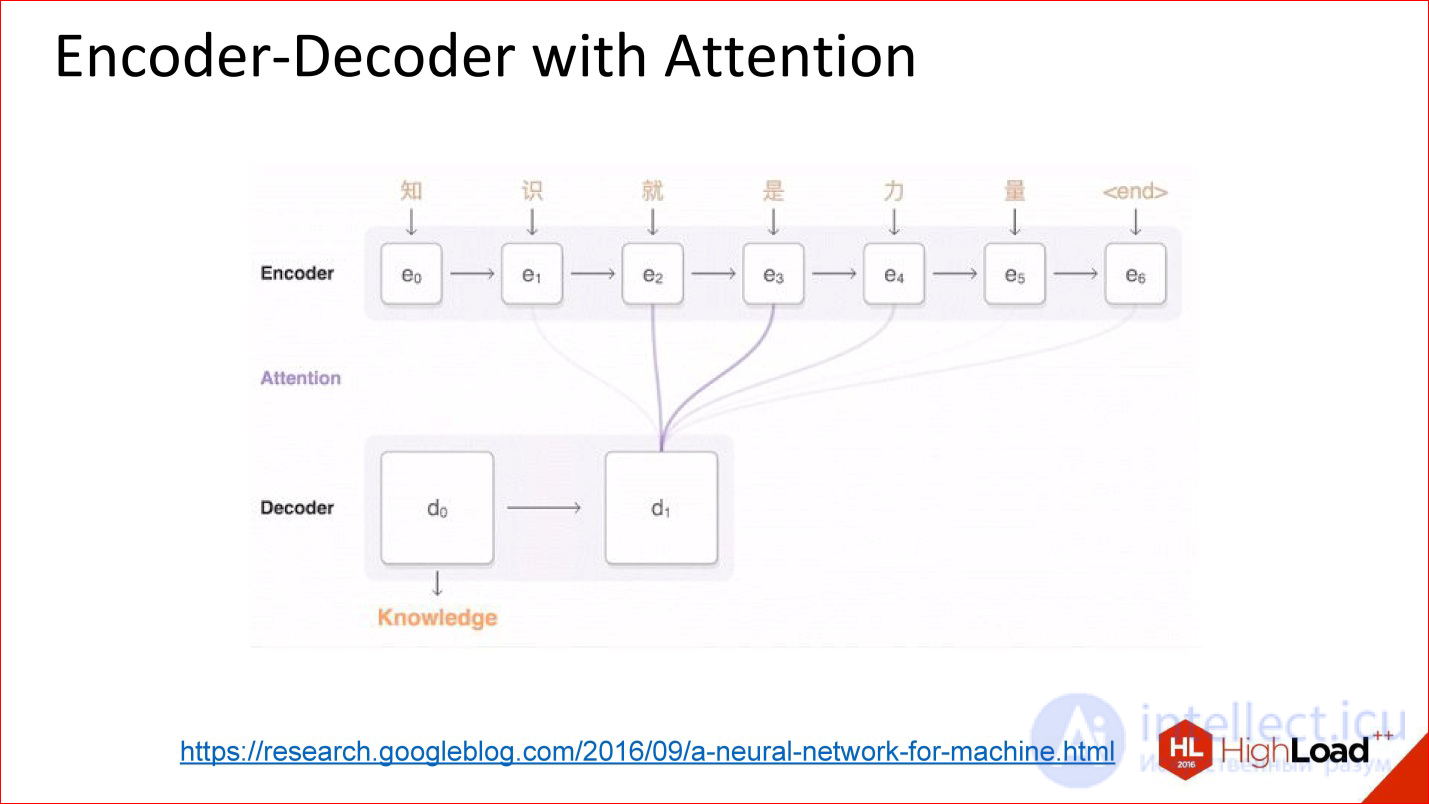
https://research.googleblog.com/2016/09/a-neural-network-for-machine.html
Appeared architecture, as they say, with attention.
Attention - this is such a tricky thing, which in fact is, in fact, very simple. The idea is that now the decoder output to the neural network does not look at the output value of the previous neural network, but at all its intermediate states, but with some weights. Weights are coefficients, how much you need to take each of those states into the final large amount that the decoder will work with.
That is, attention is actually a simple linear combination of all previous states of an encoder, which is also being trained.
Neural networks with attention in fact work very well. On translation tasks and other complex tasks, they are very much superior in quality to neural networks without attention.
Hide ads: Not interested in this topicProduct purchased or service foundIs violating the law or spamHispersing content viewing
|
getyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser. comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser. comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowsergeegeababser.comgetyabrow.comgetyabrow.comgetyabrow.comgetyabrow wser.comgetyabrowser comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser. comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrow.comgetyabrowser.comgetyabrowsergeegeababser.comgetyabrow.comgetyabrow.comgetyabrow.comgetyabrow.com.com getyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser. comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser. comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowsergeegeababser.comgetyabrow.comgetyabrow.comgetyabrow.comgetyabrow wser.comgetyabrowser comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser. comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrow.comgetyabrowser.comgetyabrowsergeegeababser.comgetyabrow.comgetyabrow.comgetyabrow.comgetyabrow.com.com getyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser. comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser. comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowsergeegeababser.comgetyabrow.comgetyabrow.comgetyabrow.comgetyabrow wser.comgetyabrowser comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser. comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrow.comgetyabrowser.comgetyabrowsergeegeababser.comgetyabrow.comgetyabrow.comgetyabrow.comgetyabrow.com.com getyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser.comgetyabrowser. comFree access to services 0 + getyabrowser.comgetyabrowser.comUpdated Browser opens Yandex services without restrictionsHide advertising: Not interested in this topicProduct purchased or service foundIs violating the law or spamTo hinder content viewing
|
Yandex.Direct
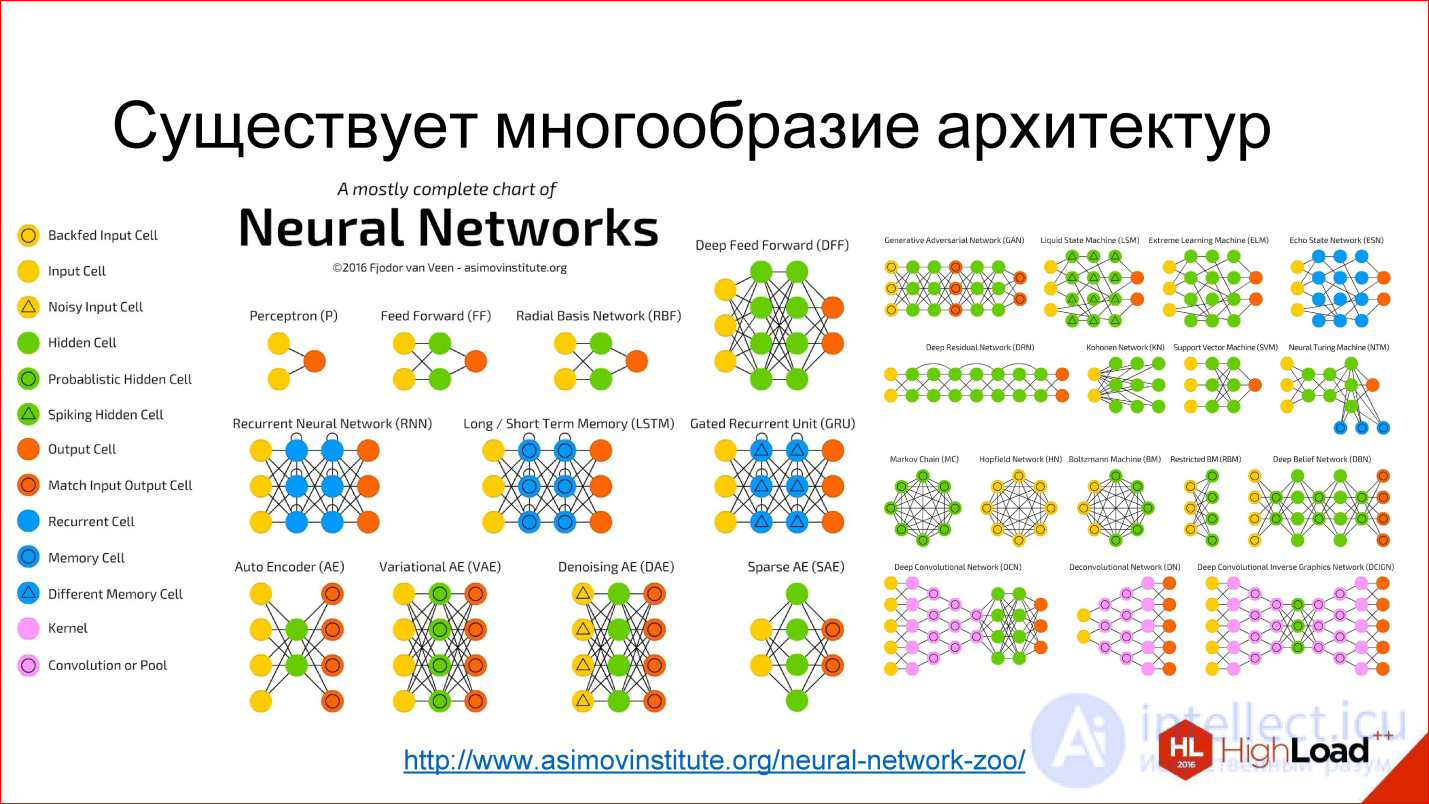
My name is Grigory Sapunov, I am a workshop of the company Intento. I have been engaged in neural networks for quite some time and machine learning, in particular, has been engaged in building neural network recognizers of road signs and numbers. I participate in the project on neural network stylization of images, I help many companies.
Let's get right to the point. My goal is to give you a basic terminology and understanding of what is happening in this area, from which building blocks of neural networks, and how to use it.
The outline of the report is as follows. First, a small introduction about what a neuron is , a neural network , a deep neural network , so that we can communicate in the same language.
Then I will tell you about the important trends that are happening in this area. Then we dive into the architecture of neural networks , consider the three main classes . This will be the most informative part.
After that, we will look at 2 relatively advanced topics and end with a small overview of the frameworks and libraries for working with neural networks.
link - look, read.
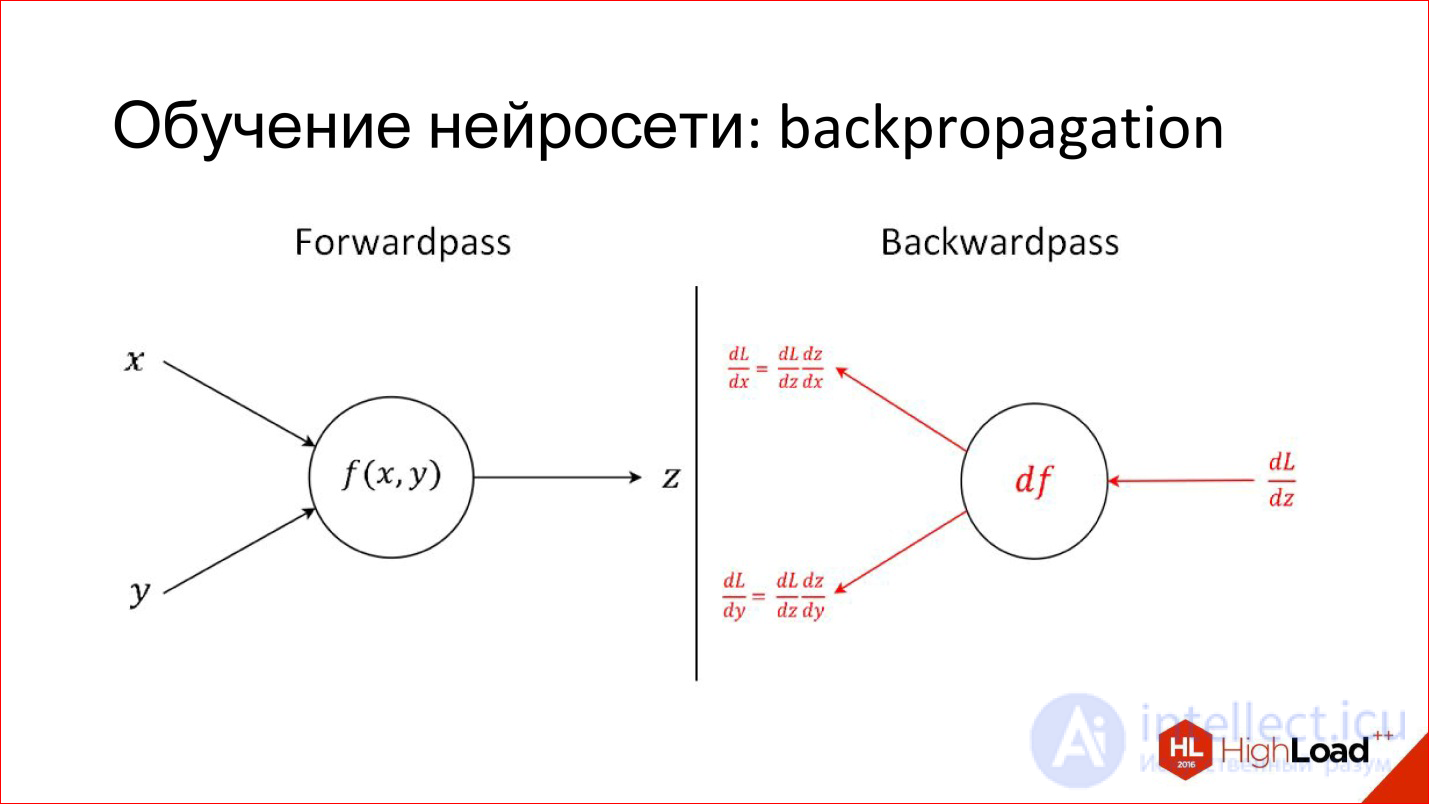
Another useful thing to know when discussing neural networks. I have already described how one neuron works: how each input multiplies by weights, by coefficients, sums up, multiplies by non-linearity. This is, let's say, the production mode of the neuron, that is, inference, as it works in the already trained form.
There is a completely different task - to train a neuron. Training is to find these correct weights. The training is based on the simple idea that if we, at the output of the neuron, know what the answer should be, and know how it turned out, we will know this difference, an error. This error can be sent back to all inputs of the neuron and understand what input influenced this error, and, accordingly, adjust the weight on this input so that the error is reduced.
This is the main idea behind Backpropagation, an error back-propagation algorithm. This process can be driven throughout the network and for each neuron to find how its weight can be modified. For this you need to take derivatives, but in principle, recently it is not required. All packages for working with neural networks are automatically differentiated. If 2 years ago it was necessary to manually write complex derivatives for tricky layers, now the packages do it themselves.
What is happening with the quality and complexity of models
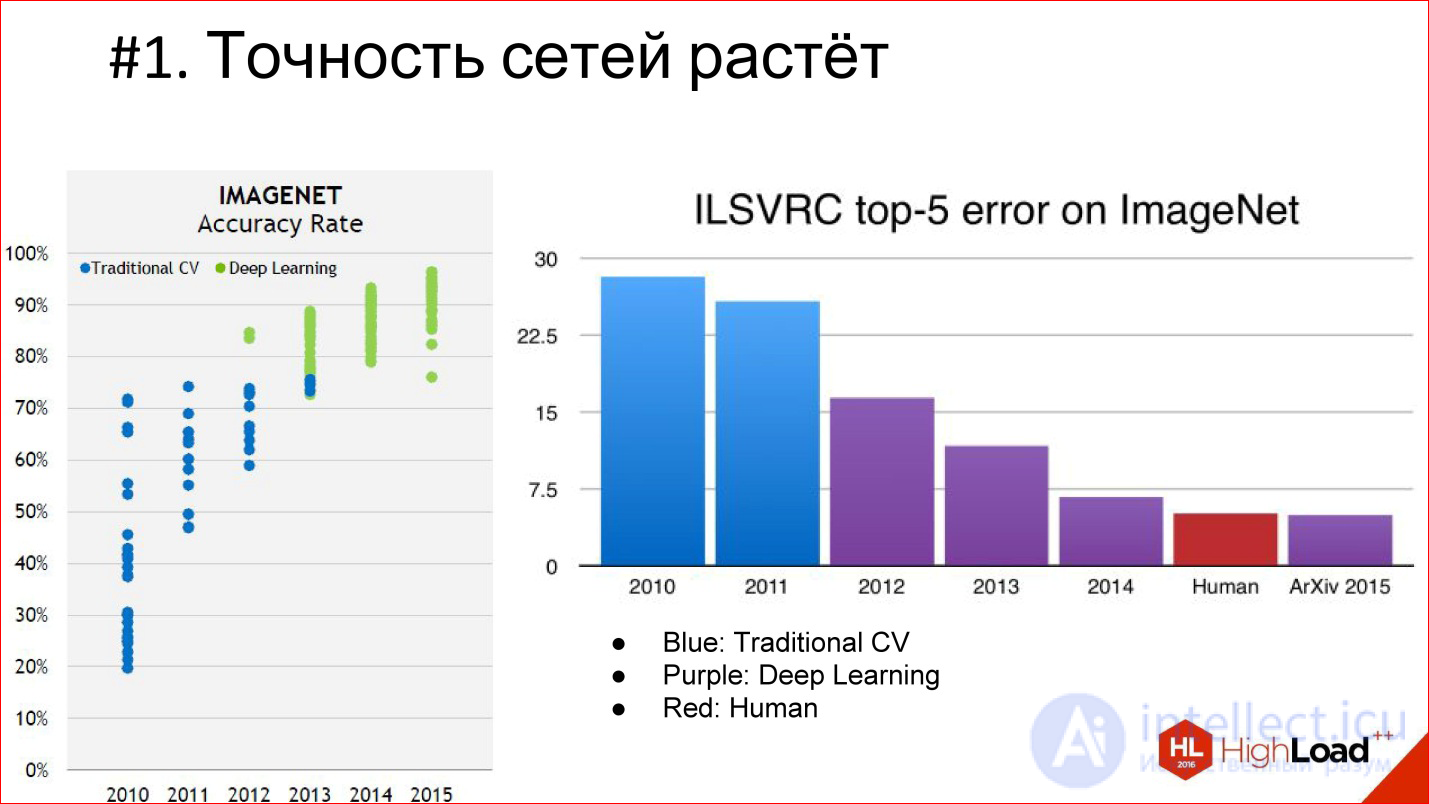
Firstly, the accuracy of neural networks is growing, and is growing very strongly. There are already a few examples when neural networks come to some area and force out the whole classical algorithm. So it was in image processing and speech recognition, it will happen in different areas. That is, there are neural networks that greatly reduce the error.
Deep Learning is highlighted in purple on the diagram, and the classic computer vision algorithm is highlighted in blue. It is seen that Deep Learning has appeared, the error has decreased and continues to decrease further. That is why Deep Learning completely supersedes all, conditionally, classical algorithms.
Another important milestone is that we are beginning to overtake the quality of a person. At the ImageNet competition, this happened for the first time in 2015. But in fact, neural network systems that are superior to humans in quality have appeared earlier. The first documented distinct case is 2011, when a system was built that recognized German road signs and did it 2 times better than a person.
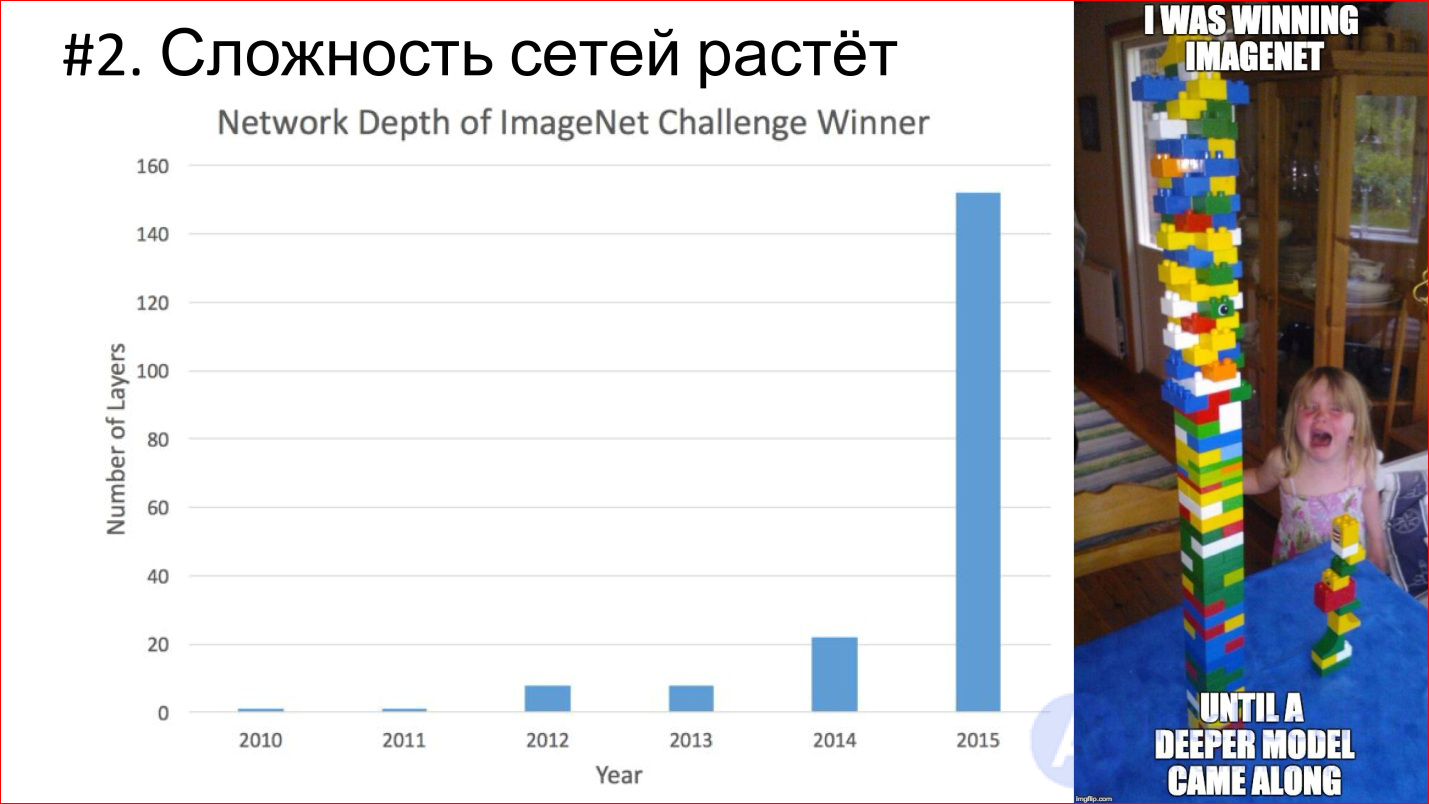
The second important trend - the complexity of neural networks is growing. In terms of depth, depth increases. If the winner of 2012 on ImageNet is the AlexNet network - there were less than 10 layers, then in 2014 there were already more than 20, in 2015 - under 150. This year, it seems, already beyond 200. What will happen next is not clear, perhaps will be even more.

http://cs.unc.edu/~wliu/papers/GoogLeNet.pdf
In addition to the growing depth, the architectural complexity grows as well. Instead of simply joining the layers one by one, they begin to branch, blocks and structure appear. In general, the architectural complexity is also growing.
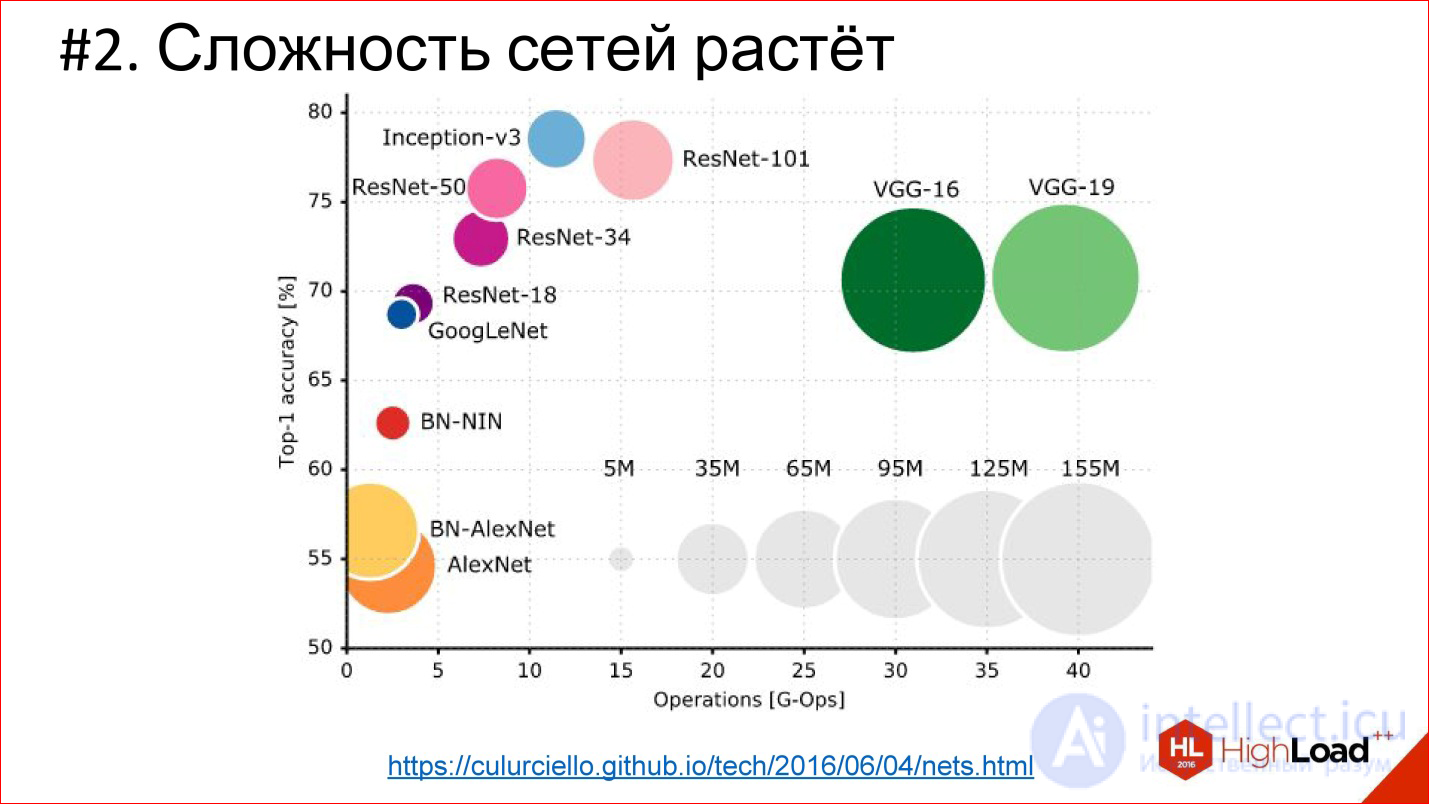
https://culurciello.github.io/tech/2016/06/04/nets.html
This is a graph of the accuracy of various neural networks. Here is the time it takes to execute, on the miscalculation of this network, that is, some kind of computational load. The size of the circle is the number of parameters that are described by the neural network. It is interesting to compare the classic network AlexNet - the winner of 2012 and later networks. They are better in accuracy, but usually contain fewer parameters. This is also an important trend that neural networks complicate very cleverly. That is, the architecture changes so that even though the number of layers is 150, the total number of parameters is less than in the 6-7-layer network, which was in 2012. The architecture is somehow complicated in a very interesting way.
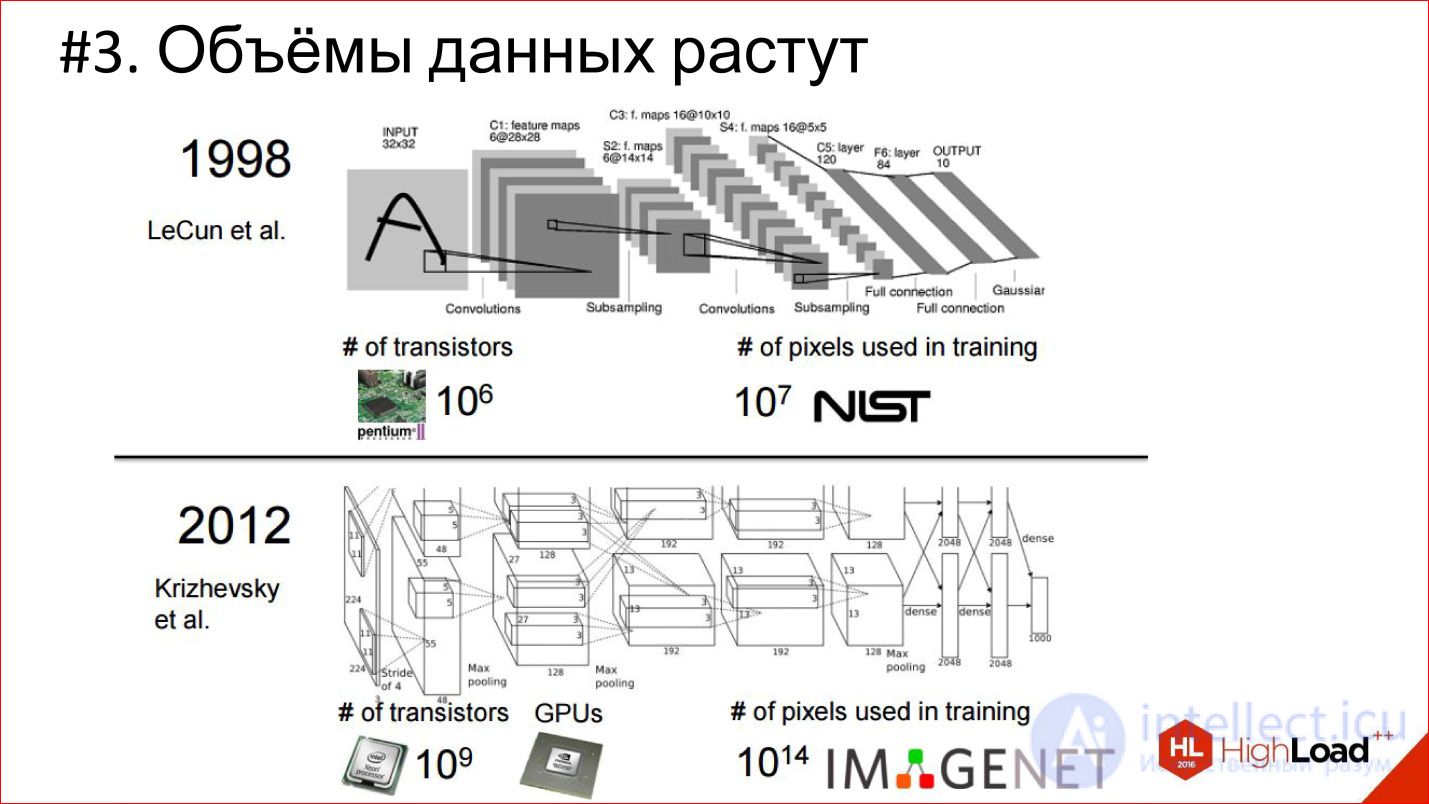
Another trend is data growth. In 1998 for training convolutional
The neural network that recognized the handwritten checks was used 10 7 pixels, in 2012 (IMAGENET) - 10 14.
7 orders in 14 years is a crazy difference and a huge shift!
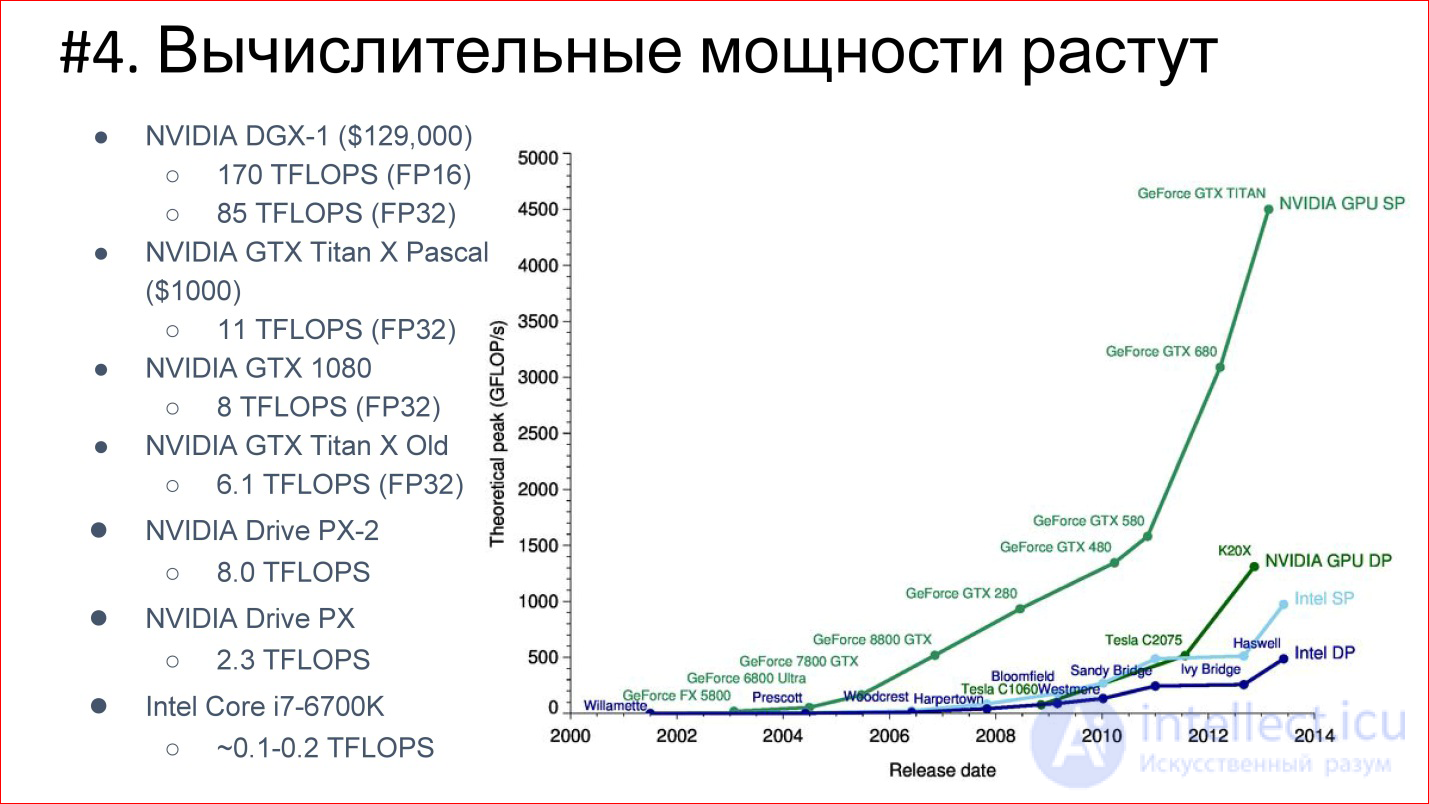
At the same time, the number of transits on the processor is also growing, computing power is growing - Moore's law is in effect. Over these 14 years, processors have become conditionally 1000 times faster. This is illustrated by the example of GPUs, which now dominate in the area of Deep Learning. Almost everything counts on graphics accelerators.
NVIDIA has been redeveloped from gaming to actually a company for artificial intelligence. Ее экспоненты оставили далеко позади экспоненты Intel, которые на этом фоне вообще не смотрятся.
Это картинка 2013 года, когда топовая видеокарта была 4,5 TFLOPS. Сейчас новый TITAN X — это уже 11 TFLOPS. В общем, экспонента продолжается!
На самом деле можно ожидать, что в ближайшее время появится FPGA'сики, которые частично потеснят GPU, и, может быть, со временем появятся даже нейроморфные процессоры. Следите за этим — там тоже много интересного происходит.
Fully Connected Feed-Forward Neural Networks, FNN
Первая классическая архитектура — полносвязные нейросети прямого распространения, или Fully Connected Feed-Forward Neural Network, FNN.

Многослойный Perceptron — это вообще классика нейросетей. Та картинка нейросетей, которую вы видели, это он и есть — многослойная полносвязная сеть. Полносвязная — это значит, что каждый нейрон связан со всеми нейронами предыдущего слоя. Хорошая сеть, работает, для классификации годится, многие задачи классификации успешно решаются.
Однако у нее есть 2 проблемы:
Например, если взять нейросеть из 3 скрытых слоев, которой нужно обрабатывать картинки 100*100 ps, это значит, что на входе будет 10 000 ps, и они заводятся на 3 слоя. В общем, если честно посчитать все параметры, у такой сети их будет порядка миллиона. Это на самом деле много. Чтобы обучить нейросеть с миллионом параметров, нужно очень много обучающих примеров, которые не всегда есть. На самом деле сейчас примеры есть, а раньше их не было — поэтому, в частности, сети не могли обучать, как следует.
Кроме того, сеть, у которой много параметров, имеет дополнительную склонность переобучаться. Она может заточиться на то, чего в реальности не существует: какой-то шум Data Set. Даже если, в конце концов, сеть запомнит примеры, но на тех, которых она не видела, потом не сможет нормально использоваться.
Плюс есть другая проблема под названием:
Remember that story about Backpropagation, when an error from the outputs is sent to the input, distributed to all weights and sent further along the network? Further, these derivatives - that is, the gradient (error derivative) - are run back through the neural network. When there are many layers in a neural network, a very, very small part of this gradient can remain at the very end. In this case, the input weight will be almost impossible to change because this gradient is practically “dead”, it is not there.
This is also a problem, due to which deep neural networks are also difficult to train. We will return to this topic further, especially on recurrent networks.

There are various variations of FNN networks. For example, a very interesting variation of the Auto ENCODER. This is a network of direct distribution with the so-called bottleneck in the middle. This is a very small layer, say, of only 10 neurons.
What are the advantages of such a neural network?
The purpose of this neural network is to take some kind of input, drive it through itself and generate the same input at the output, that is, so that they match. What's the point? If we can train such a network that takes input, drives it through itself and generates exactly the same output, it means that these 10 neurons in the middle are enough to describe this input. That is, you can greatly reduce the space, reduce the amount of data, economically encode any input data in the new terms of 10 vectors.
It is convenient and it works. Such networks can help you, for example, reduce the dimension of your task or find some interesting features that you can use.

There is another interesting model of RBM. I wrote it in the FNN variation, but in reality this is not true. Firstly, it is not deep, and secondly, it is not Feed-Forward. But it is often associated with FNN networks.
What it is?
This is a shallow model (on the slide it is drawn in a corner), which has an entrance and there is some hidden layer. You give a signal to the input and try to train the hidden layer so that it generates this input.
This is a generative model. If you have trained it, then you can generate analogs of your input signals, but slightly different. It is stochastic, that is, every time it will generate something slightly different. If you, for example, have trained such a model to generate handwritten ones, then it will accumulate them a number of slightly different ones.
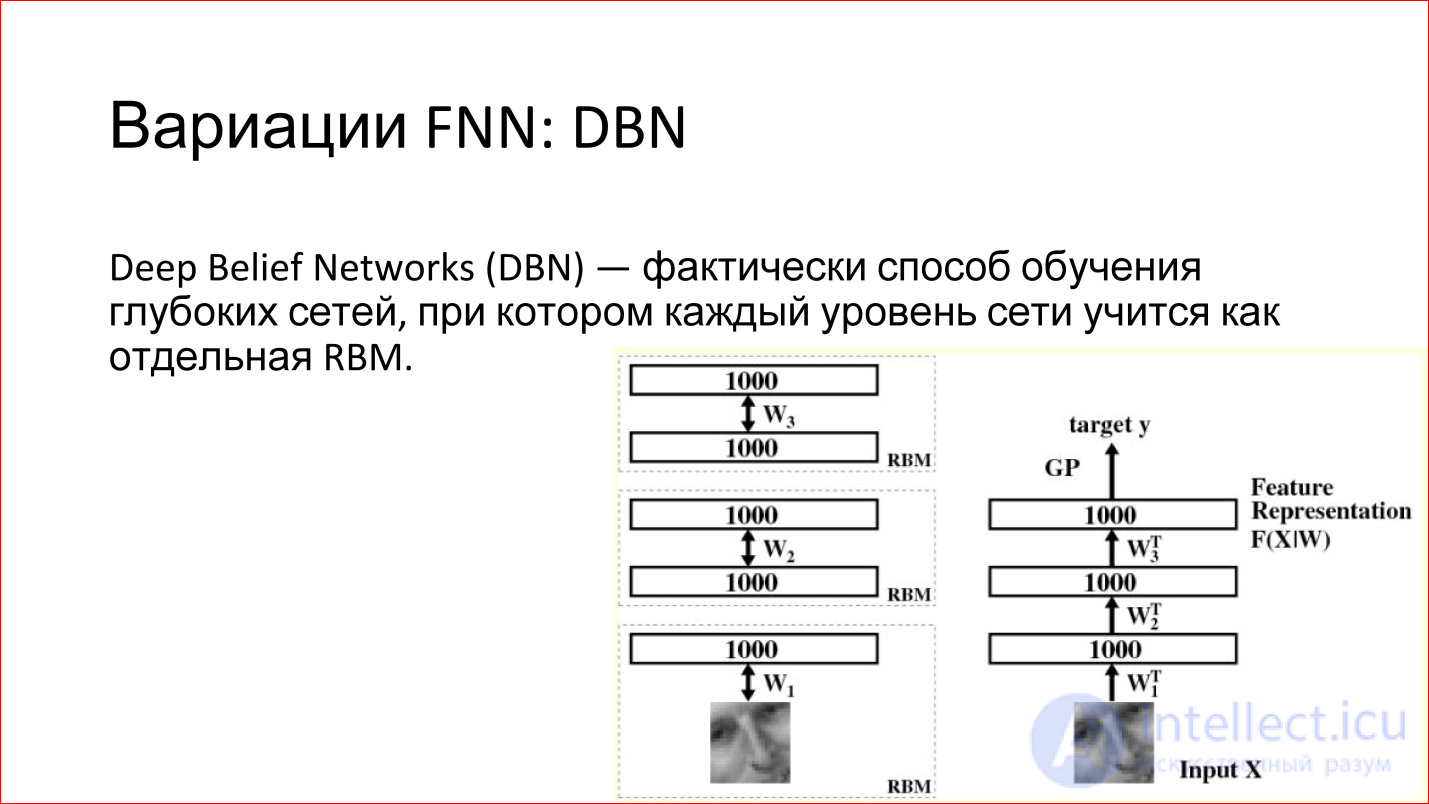
What is good about RBM is that they can be used to train deep networks. There is such a term — Deep Belief Networks (DBN) —in fact, this is a way to train deep networks, when 2 lower layers of a deep network are taken separately, input is given and RBM is trained on these first two layers. After that, these weights are recorded. Next, the second layer is taken, considered as a separate RBM and is also being trained. And so throughout the network. Then these RBMs are joined, combined into one neural network. It turns out a deep neural network, which should be.
But now there is a huge advantage - if earlier you had just taught it from some random (random) state, now it is not random — the network is trained to restore or generate data from the previous layer. That is, her weight is reasonable, and in practice this leads to the fact that such neural networks are already quite well trained. Then you can slightly train them with some examples, and the quality of such a network will be good.
Plus there is an additional advantage. When you use RBM, you essentially work on unallocated data, which is called Un supervised learning. You have just pictures, you do not know their classes. You drove millions, billions of pictures that you downloaded from Flickr or from somewhere else, and you have some kind of structure in the network itself that describes these pictures.
You do not know what it is yet, but these are reasonable weights, which can then be taken and supplemented by a small number of different pictures, and this will be good. This is a cool way to use a combination of 2 neural networks.
Then you will see that this whole story is really about Lego. That is, you have separate networks - recurrent neural networks, some other networks are all blocks that can be combined. They are well combined on different tasks.
These were the classic direct propagation neural networks. Next, we turn to convolutional neural networks.
Convolutional Neural Networks, CNN
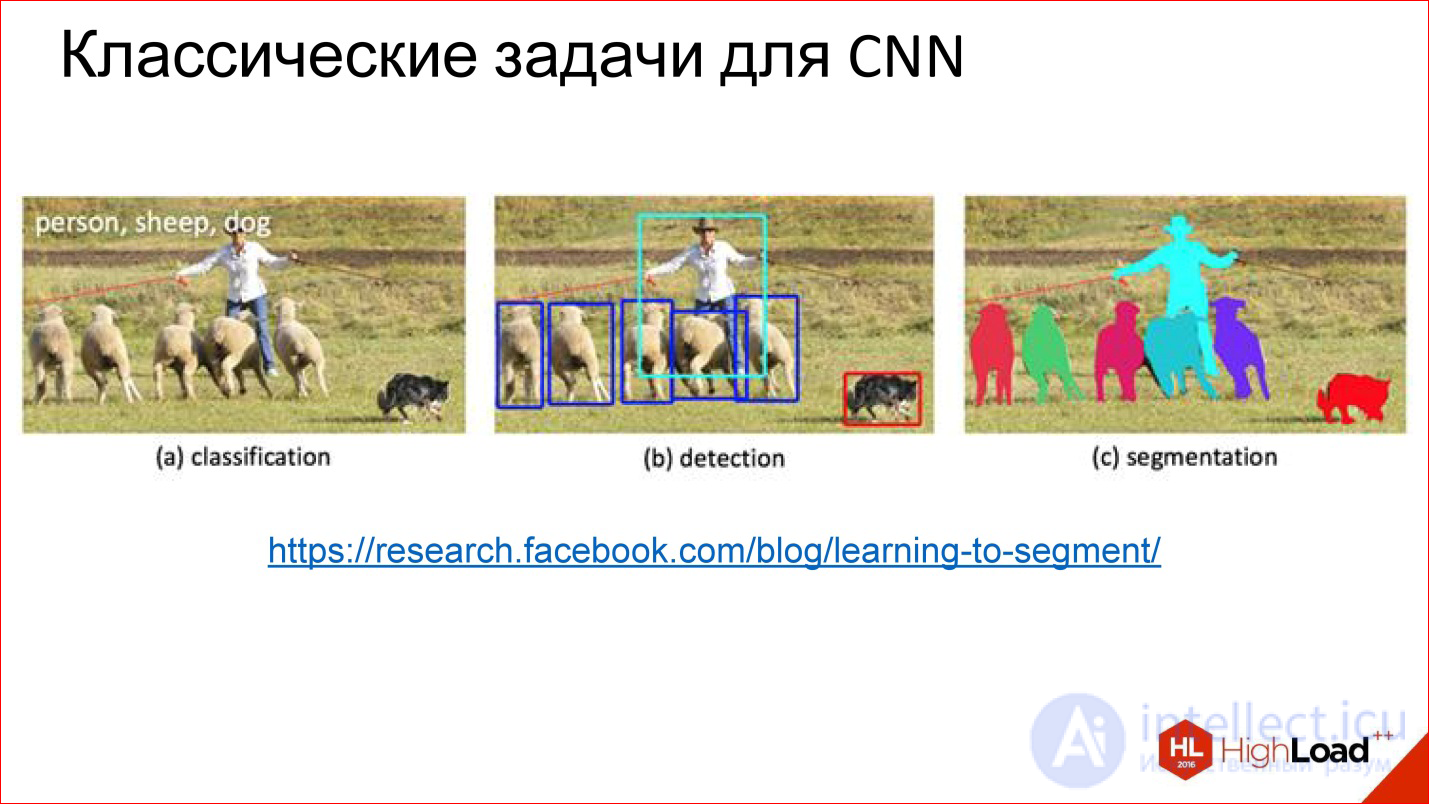
https://research.facebook.com/blog/learning-to-segment/
Convolutional neural networks solve 3 main tasks:
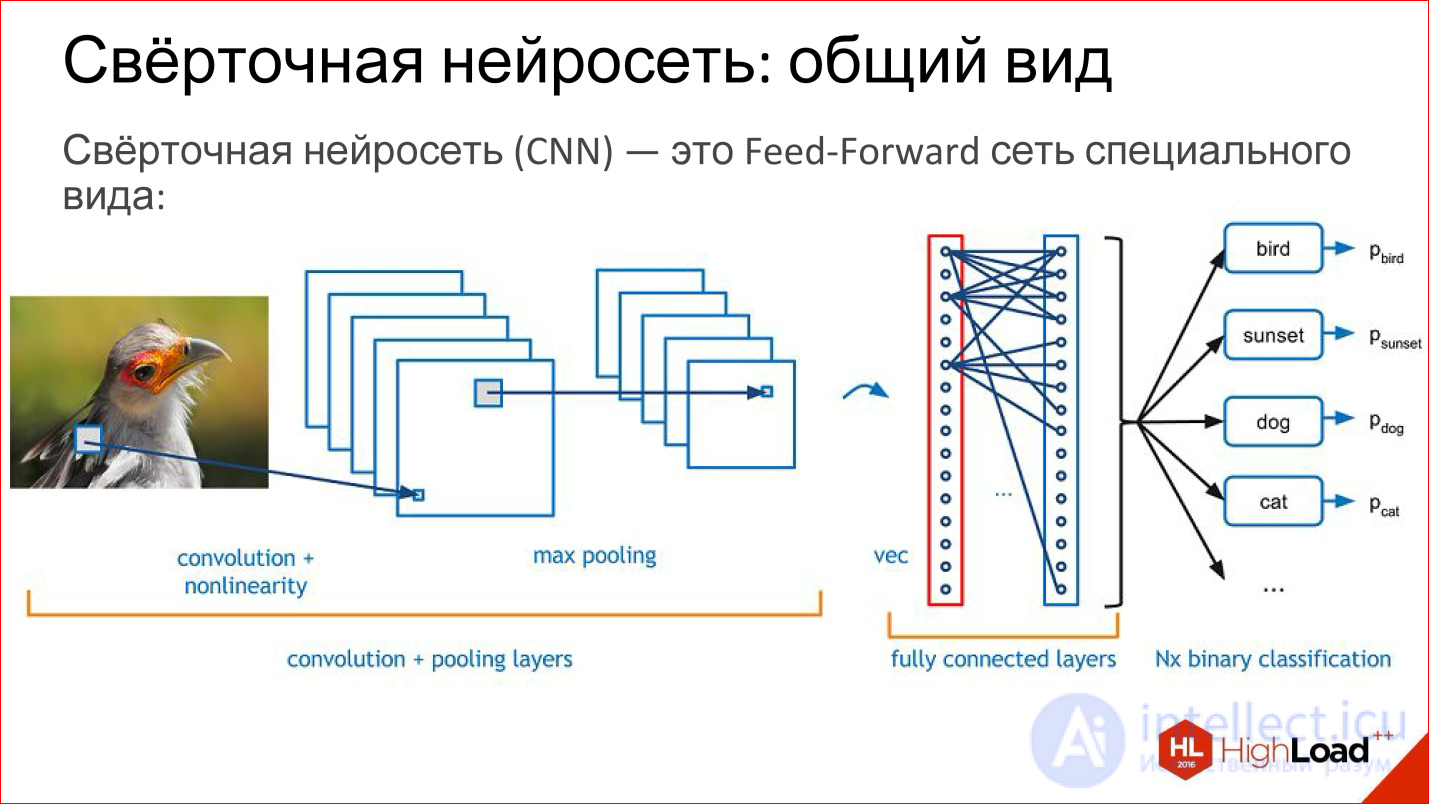
What is a convolutional neural network? In fact, the convolutional neural network is the usual feed-forward network, it’s just a little bit of a special kind. Lego starts now.
What is in the convolution network? She has:
A little more detail about all these layers.

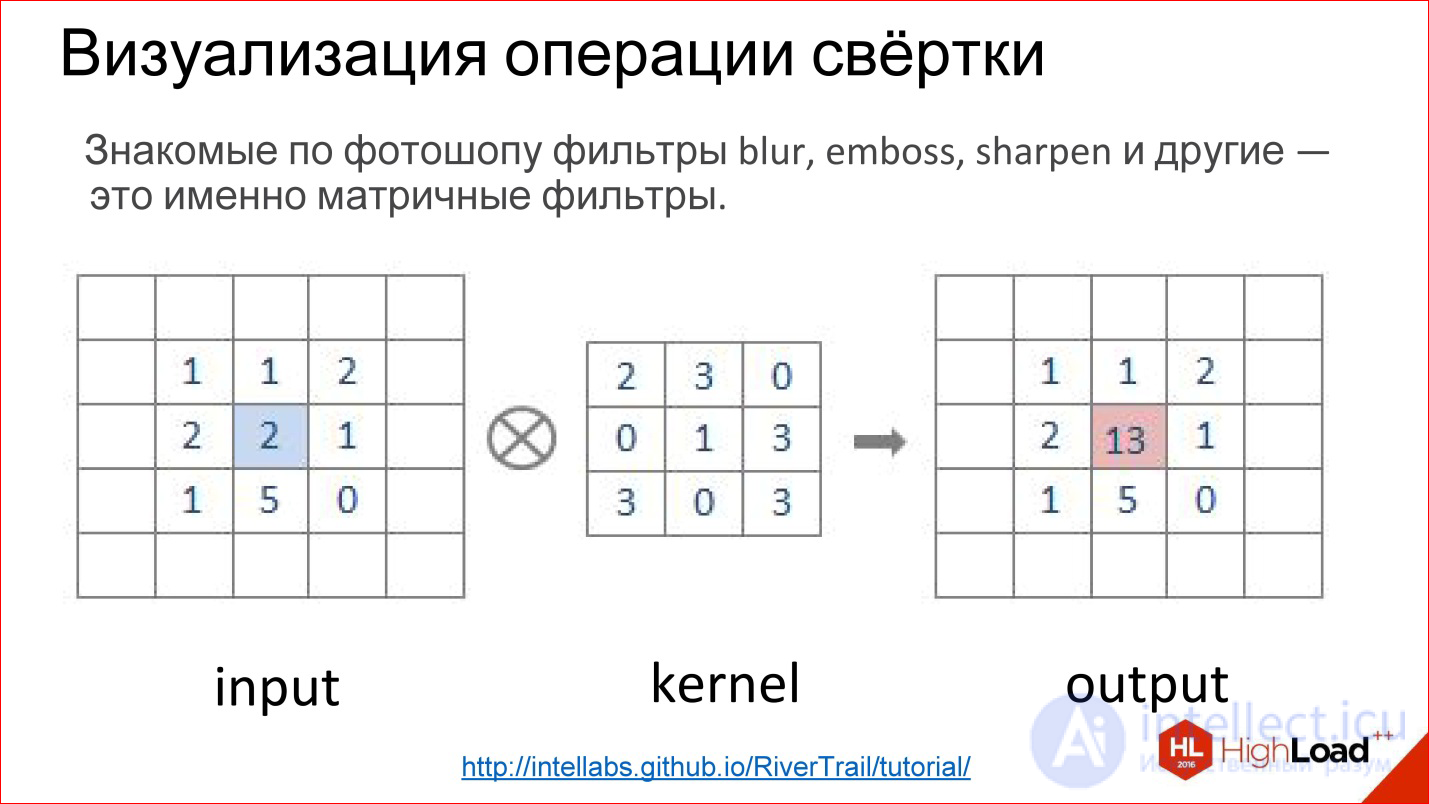
http://intellabs.github.io/RiverTrail/tutorial/
What is a convolution operation? It scares everyone, but in reality it’s a very simple thing. If you worked in Photoshop and made Gaussian Blur, Emboss, Sharpen and a bunch of other filters, these are all matrix filters. Matrix filters are in fact a convolution operation.
How is it implemented? There is a matrix, which is called the filter kernel (in the figure kernel). For Blur it will be all units. There is an image. This matrix is superimposed on a piece of the image, the corresponding elements are simply multiplied together, the results are added and recorded at the center point.
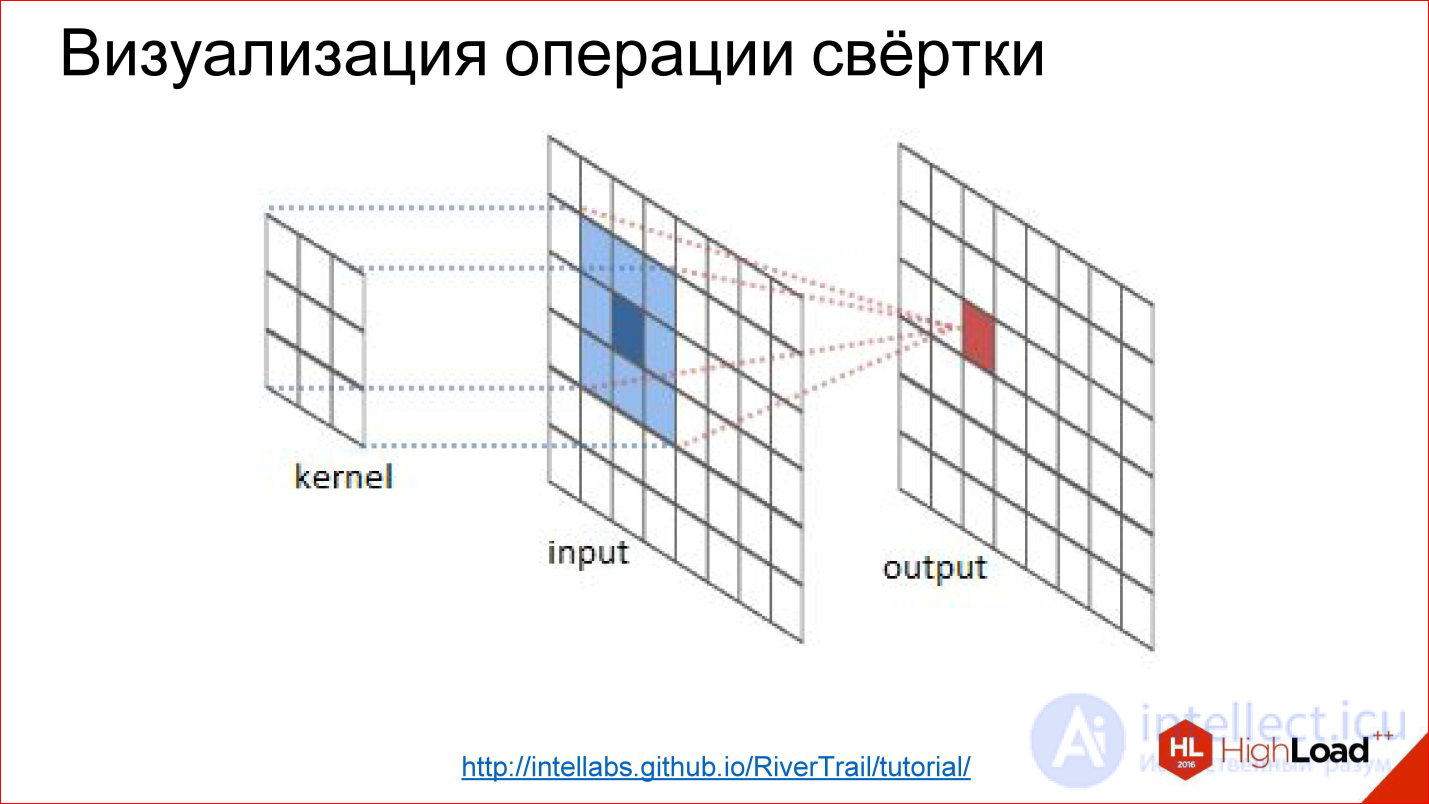
http://intellabs.github.io/RiverTrail/tutorial/
So it looks more clearly. There is an image Input, there is a filter. You run a filter over the entire image, honestly multiply the corresponding elements, add, write to the center. Run, run - built a new image. All this is a convolution operation.
That is, in fact, convolution in convolutional neural networks is a cunning digital filter (Blur, Emboss, anything else), which itself is trained.
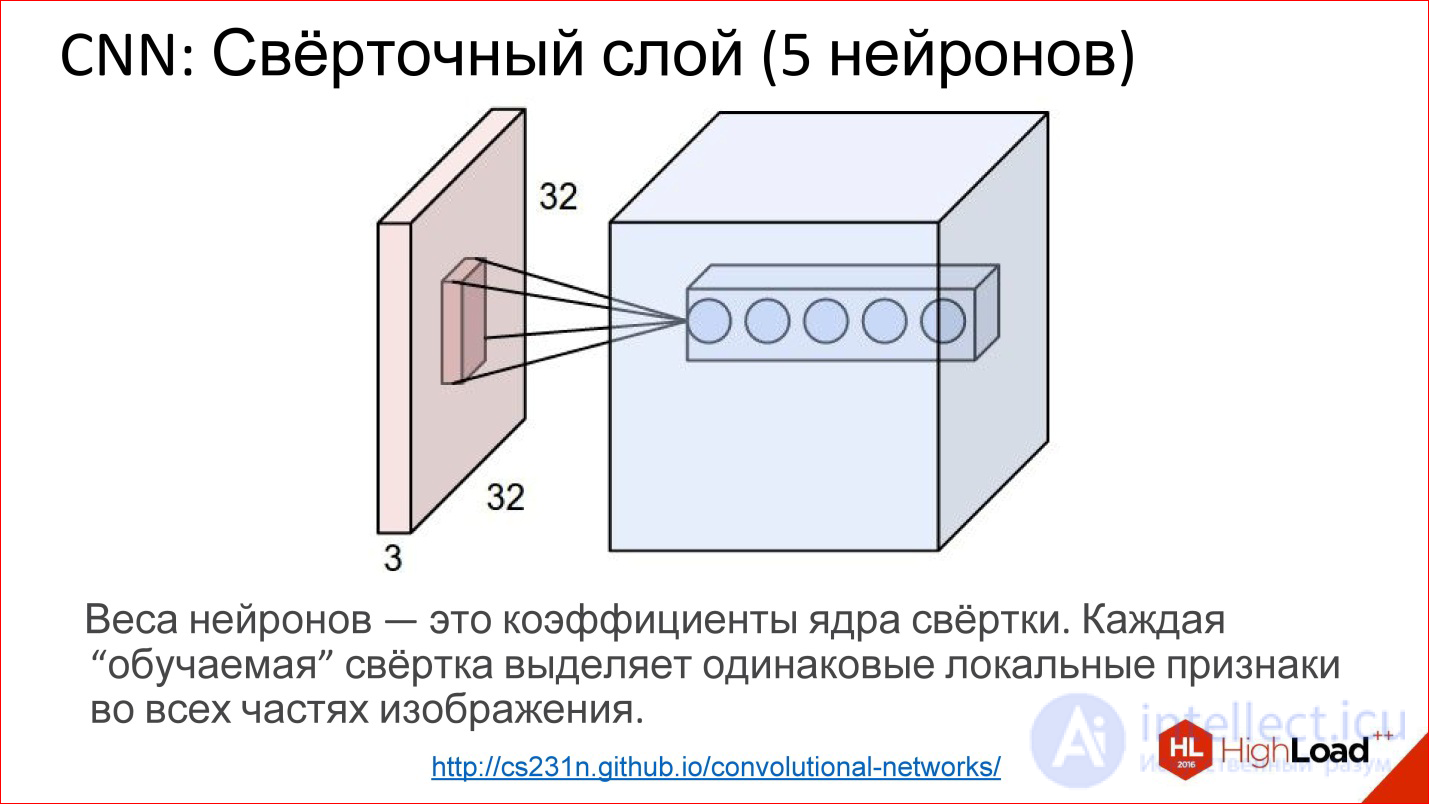
http://cs231n.github.io/convolutional-networks/
In fact, convolutional layers all work on volumes. That is, even if you take an ordinary RGB image, there are already 3 channels - this is, in fact, not a plane, but a volume of 3, conditionally, cubes.
Convolution in this case is no longer a matrix, but a tensor - actually a cube.
You have a filter, you run through the entire image, it immediately looks at all 3 color layers and generates one new point for one of this volume. Run through the entire image - built one channel, one plane of the new image. If you have 5 neurons, you have built 5 planes.
This is how the convolutional layer works. The task of learning the convolutional layer is the same as in ordinary neural networks - to find the weights, that is, to actually find the convolution matrix, which is completely equivalent to the weights in the neurons.
What are these neurons doing? They actually learn to look for some features, some local signs in the small part that they see - and that’s all. Running one such filter is building a certain map of finding these features in the image.
Then you built many such planes, then use them as an image, feeding them on the following entrances.

http://vaaaaaanquish.hatenablog.com/entry/2015/01/26/060622
Pooling operation is an even simpler operation. It is just averaging or taking a maximum. It also works on some small squares, for example, 2 * 2. You overlay the image and, for example, select the maximum element from this 2 * 2 box, send it to the output.
Thus, you reduced the image, but not with a cunning Average, but with a slightly more advanced piece - you took the maximum. This gives a slight shift invariance. That is, it does not matter to you whether some sign was found in this position or 2 ps to the right. This thing allows the neural network to be a little more resistant to image shifts.
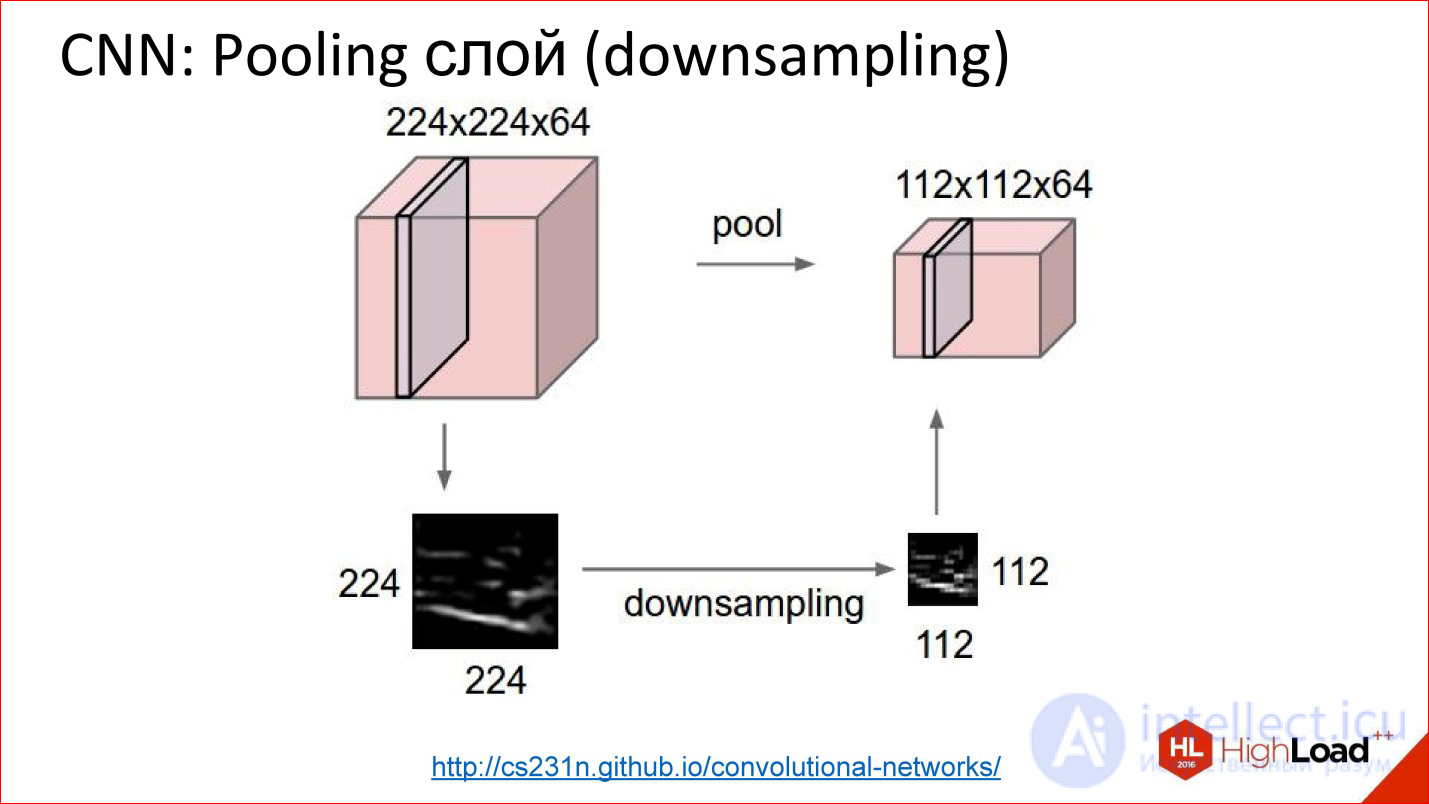
http://cs231n.github.io/convolutional-networks/
This is how the pooling layer works. There is a cube of some size - 3 channels, 10, or 100 channels, which you counted by convolutions. It simply reduces it in width and height, it does not touch the other dimensions. Everything is a primitive thing.

What are good convolutional networks?
They are good because they have much fewer parameters than a regular fully connected network. Remember the example of a fully connected network, which we considered, where we got a million weights. If we take a similar one, more precisely, a similar one — it cannot be called a similar one, but a close convolutional neural network, which has the same input, the same output, will also have one fully connected output layer and 2 more convolutional layers, where there will also be 100 neurons each. in the core network, it turns out that the number of parameters in such a neural network has decreased by more than an order of magnitude.
It's great if the parameters are so much smaller - the network is easier to train. We see it, it’s really easier to train.
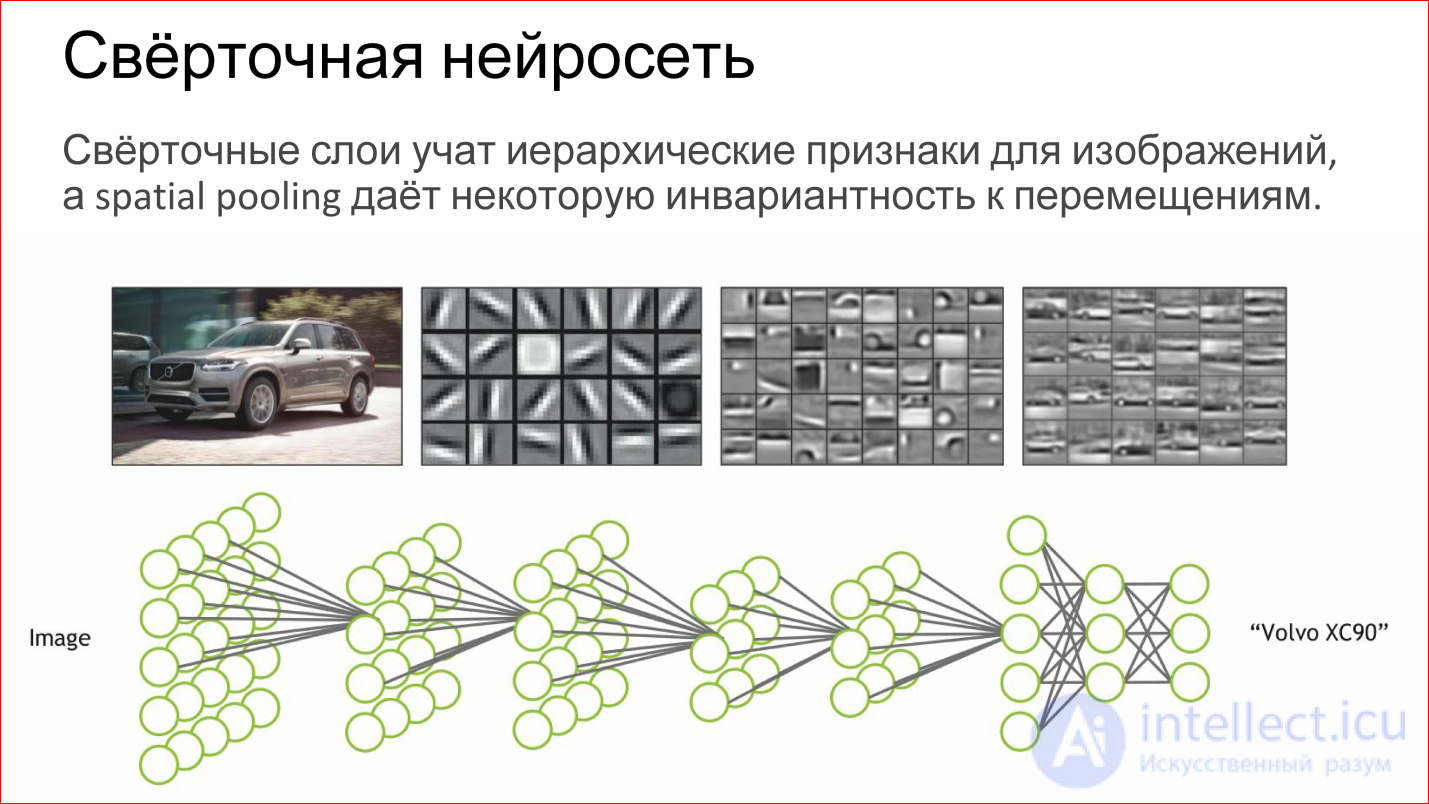
What does the convolutional neural network do?
In fact, it automatically learns some hierarchical features for images: first, basic detectors, lines of different inclination, gradients, etc. Of these, she collects some more complex objects, then even more complex ones.
If you perceive a neuron as a simple logistic regression, a simple classifier, then a neural network is just a hierarchical classifier. First, you single out simple signs, combine complex signs of them, even more complex ones, even more complex ones, and in the end you can combine some very complex sign - a specific person, a specific machine, an elephant, anything else.
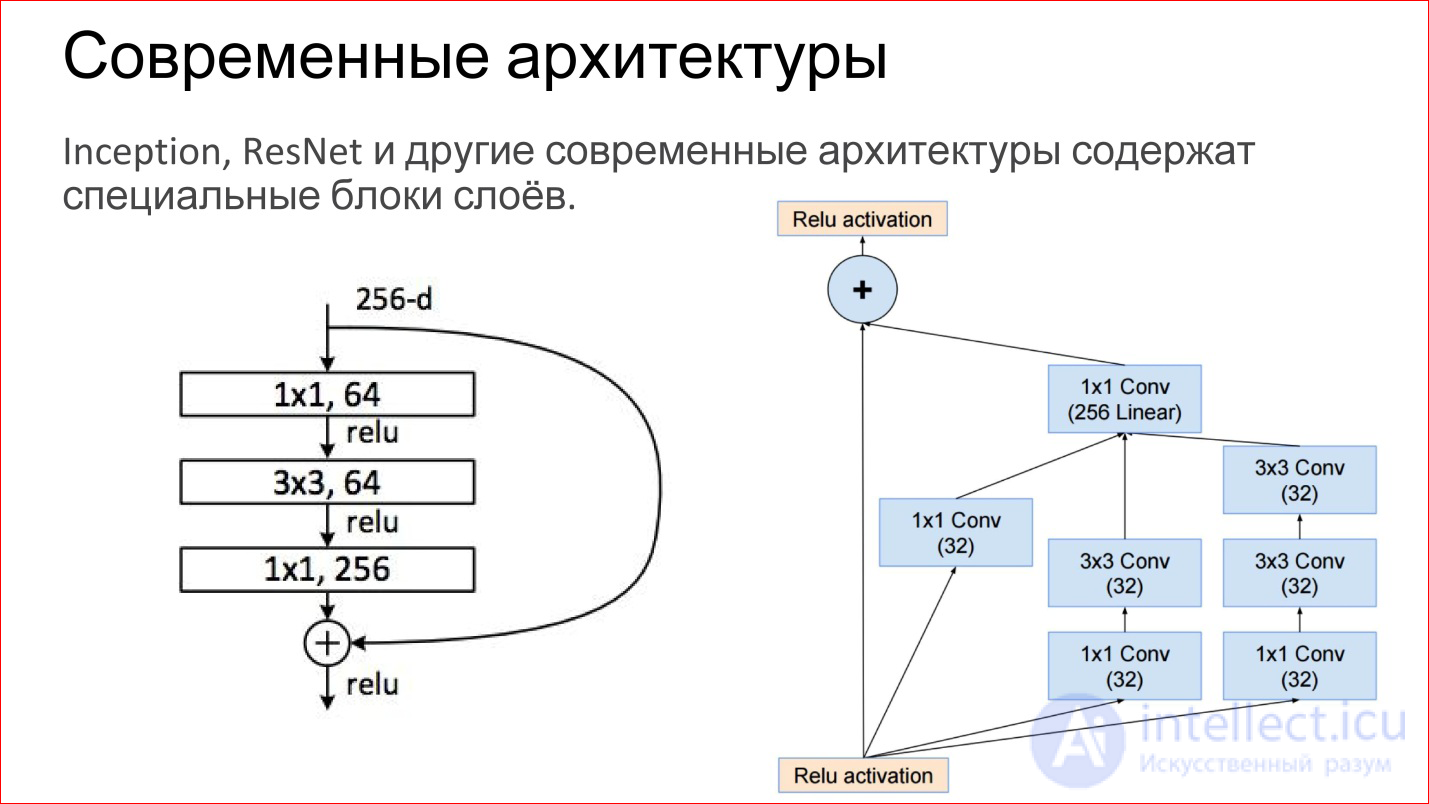
Modern architectures of convolutional neural networks have become very complicated. Those neural networks that won at the latest ImageNet contests are no longer just some convolutional layers, Pooling layers. These are directly finished blocks. The figure shows examples from the network Inception (Google) and ResNet (Microsoft).
In essence, the same basic components are inside: the same convolutions and pooling. Just now there are more of them, they are somehow slyly combined. Plus, now there are direct links that allow you not to transform the image at all, but simply transfer it to the output. It, by the way, helps that gradients do not fade. This is an additional way to pass the gradient from the end of the neural network to the beginning. It also helps to train such networks.
It was a very classic convolutional neural networks. Yes, there are different types of layers that can be used for classification. But there are more interesting uses.

https://arxiv.org/abs/1411.4038
For example, there is such a kind of convolutional neural networks called Fully-convolutional networks (FCN). People rarely talk about them, but this is a cool thing. You can take and tear off the last multilayer perceptron, it is not needed - and throw it out. And then the neural network can magically work on images of arbitrary size.
That is, she learned, let's say, to define 1000 classes in the images of cats, dogs, something else, and then we took the last layer and did not tear it off, but transformed it into a convolutional layer. There are no problems - you can count the weights. Then it turns out that this neural network seems to work with the same window for which it was trained, 100 * 100 ps, but now it can run through this window across the entire image and build a heat map at the output - where in this particular image is specific class.
You can build, for example, 1000 of these Heatmap for all your classes and then use it to determine the location of the object in the picture.
This is the first example where a convolutional neural network is not used for classification, but in fact for generating an image.
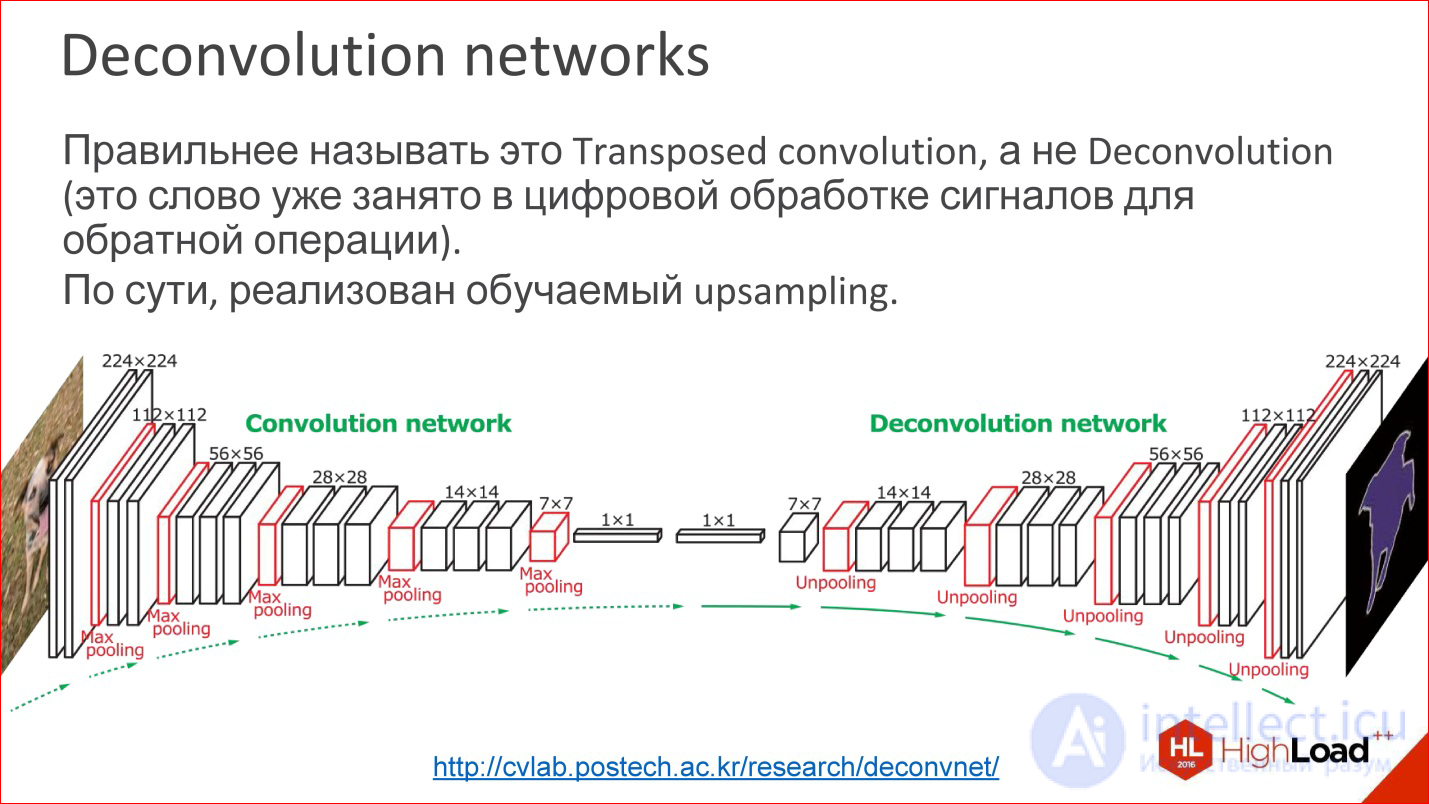
http://cvlab.postech.ac.kr/research/deconvnet/
A more advanced example is Deconvolution networks. They are rarely spoken of either, but this is even more awesome.
In fact, Deconvolution is the wrong term. In digital signal processing, this word is taken by a completely different thing - a similar, but not such.
What it is? In essence, this is a trained upsling. That is, at some point you have reduced your image to a small size, maybe even 1 ps. Rather, not to a pixel, but to some small vector. Then you can take this vector and open.
Or, if at some point you got an image of 10 * 10 ps, now you can do Upsampling of this image, but in some tricky way in which Upsampling weights are also trained.
This is not magic, it works, and in fact it allows us to train neural networks that receive some kind of output image from the input image. That is, you can submit entry / exit samples, and the one in the middle will learn by itself. It is interesting.
In fact, many tasks can be reduced to the generation of images. Classification is a cool task, but it is still not comprehensive. There are many tasks where pictures need to be generated. Segmentation is basically a classic task, where you need to have a picture at the output.
Moreover, if you have learned to do so, then you can do it in a different way, more interesting.
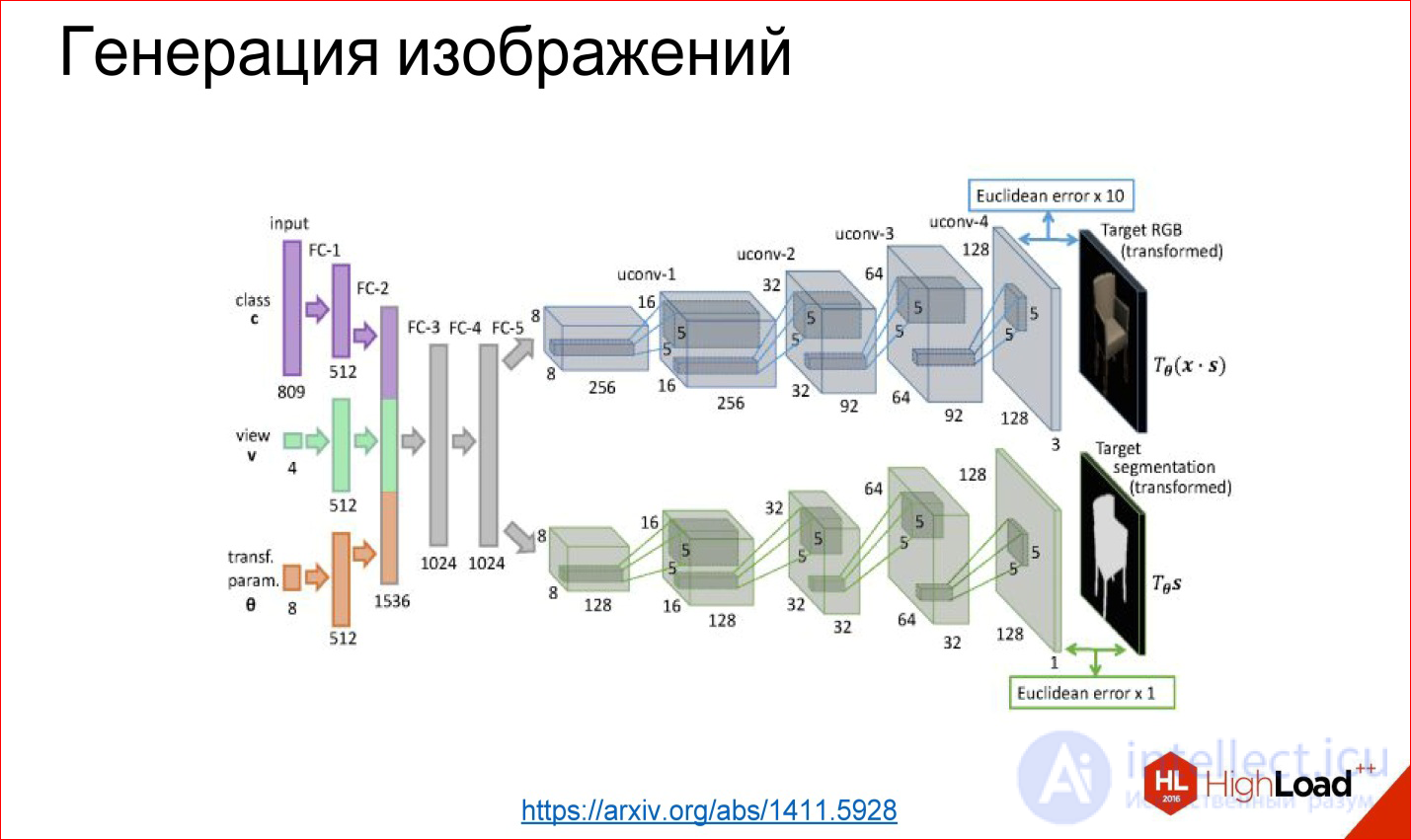
https://arxiv.org/abs/1411.5928
It is possible to tear off the first part, for example, and fasten some kind of fully meshed network that we will teach - what comes to the entrance, for example, a class number: generate a chair for me at such and such an angle and in such and such form. These layers generate further some internal representation of this chair, and then it unfolds into a picture.
This example is taken from the work where the neural network really taught to generate different chairs and other objects. It also works, and it's fun. This is collected, in principle, from the same basic blocks, but they are wrapped differently.

https://arxiv.org/abs/1508.06576
There are non-classical tasks, for example, the transfer of style, about which in the last year we all hear. There are a bunch of applications that can do this. They work on about the same technology.
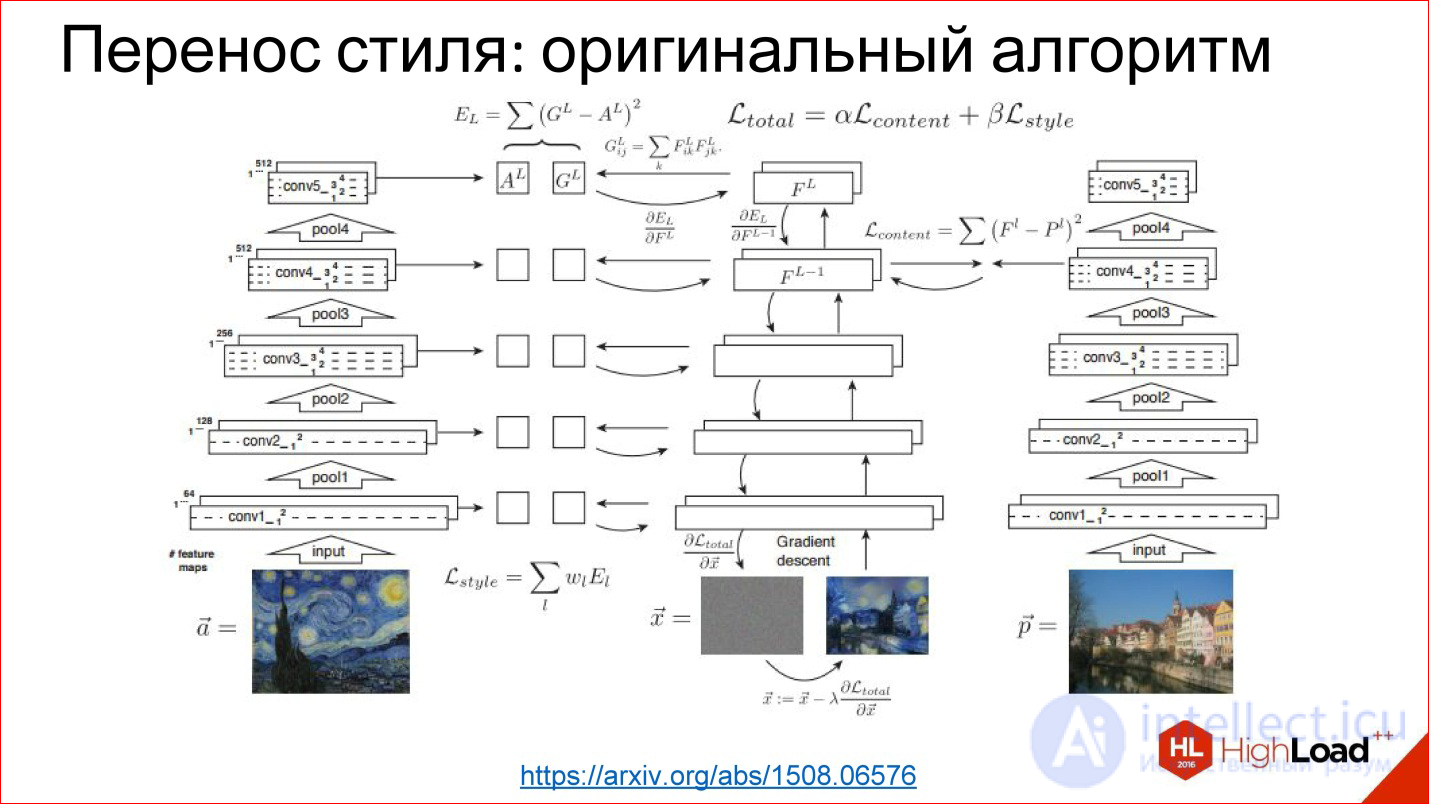
https://arxiv.org/abs/1508.06576
There is a ready trained network for classification. It turned out that if we take a derived picture, load it into this neural network, then different convolutional layers will be responsible for different things. That is, on the first convolutional layers there will be stylistic features of the image, on the latter - content features of the image, and this can be used.
You can take a picture as a model of style, drive it through a ready-made neural network, which was not taught at all, remove stylistic signs, remember. You can take any other picture, get rid of, take the content signs, remember. And then the random image (noise) can be driven away again through this neural network, to get the signs on the same layers, to compare with those that should have been received. And you have a task for Backpropagation. In fact, further gradient descent can be transformed random image to one for which these weights on the desired layers will be as necessary. And you got a stylized picture.
The only problem with this method is that it is long. This iterative run of the picture back and forth is a long time. Who played with this code in the style generation, knows that the classic code is long, and you have to suffer. All services like Prism and so on, which generate more or less quickly, work differently.
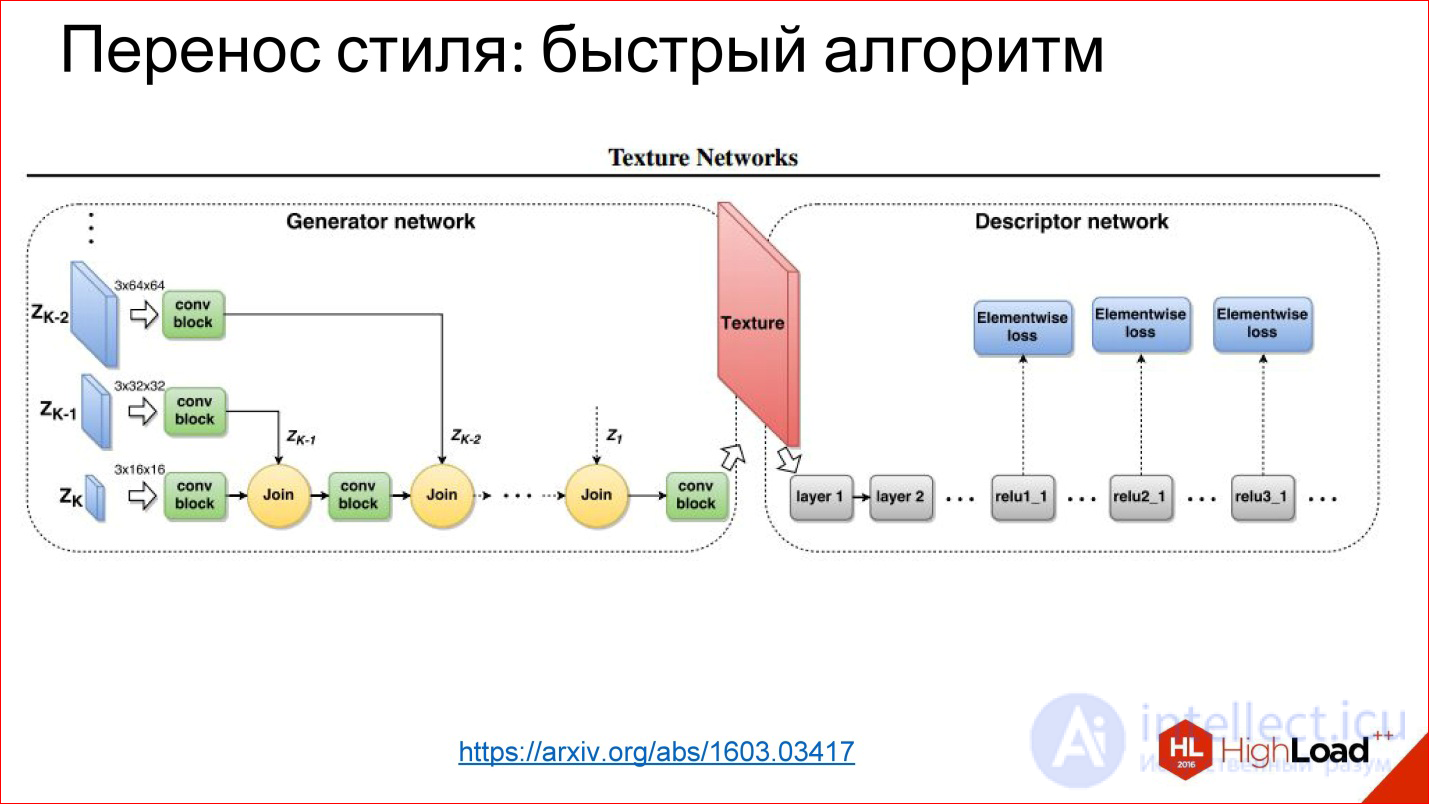
https://arxiv.org/abs/1603.03417
Since then, they have learned to generate networks that simply generate a picture in 1 pass. This is the same task of transforming an image that you have already seen: there is something at the entrance, there is something at the output, you can train everything in the middle.
In this case, the trick is that the loss function is the very function of the error you get on this neural network, and the error function is removed from the normal neural network that was trained for classification.
These are such hacker methods of using neural networks, but it turned out that they work, and this leads to cool results.
Next, we turn to recurrent neural networks.
Recurrent Neural Networks, RNN
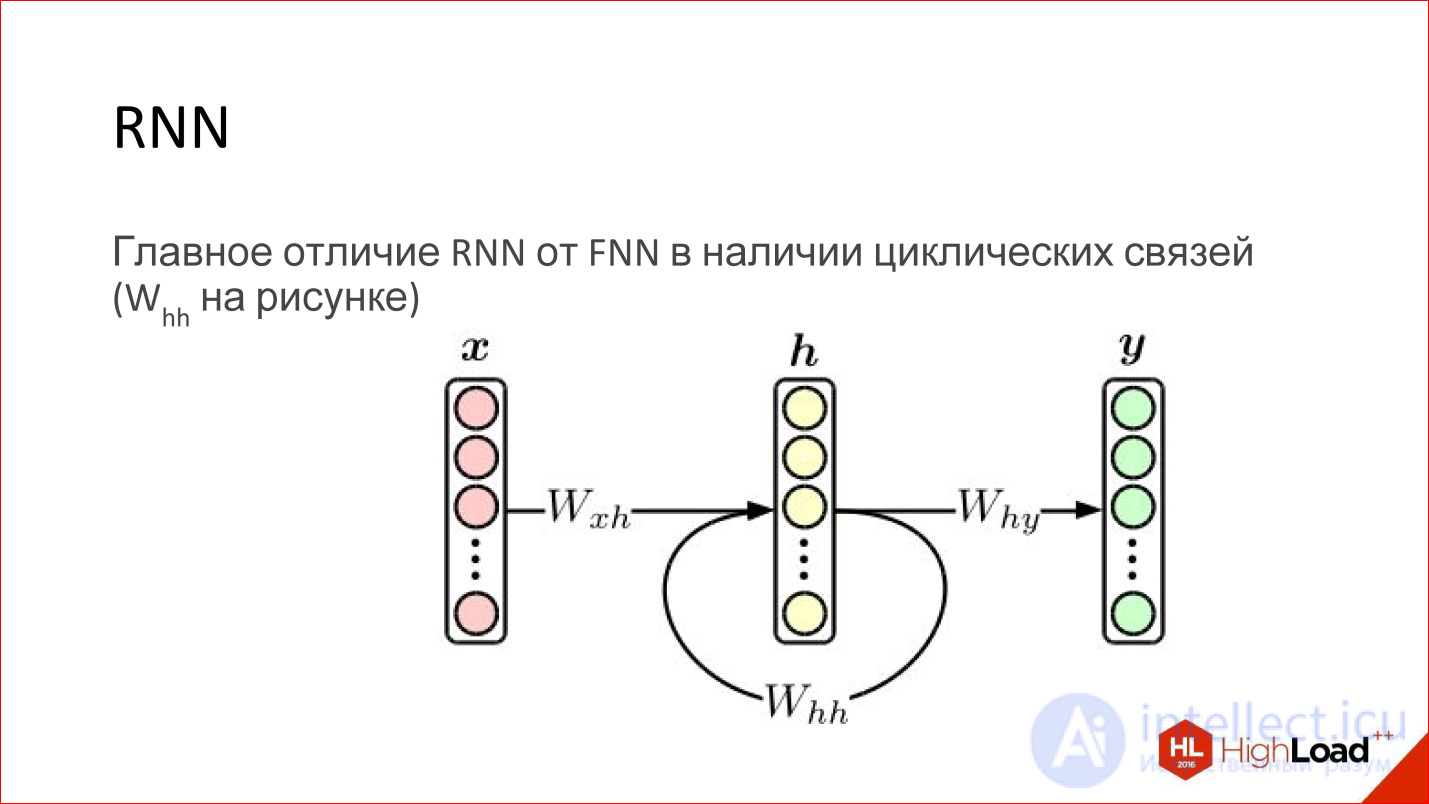
A recurrent neural network is actually a very cool thing. At first glance, their main difference from conventional FNN networks is that some kind of cyclic connection just appears. That is, the hidden layer sends its own values to itself in the next step. It would seem to be a minor thing, but there is a fundamental difference.
продолжение следует...
Часть 1 Introduction to neural network architectures. Classification of neural networks, principle of operation
Часть 2 Grigory Sapunov (Intento) - Introduction to neural network architectures. Classification
Часть 3 Мультимодальное обучение (Multimodal Learning) - Introduction to neural network architectures.

Comments
To leave a comment
Computational Neuroscience (Theory of Neuroscience) Theory and Applications of Artificial Neural Networks
Terms: Computational Neuroscience (Theory of Neuroscience) Theory and Applications of Artificial Neural Networks