Lecture
Recently, information technology trends have begun to be felt more clearly. Processor clock speeds and chip dimensions are becoming ever faster. All available large memory sizes at a lower cost. And, judging by reports in the press, this is far from the limit in the technical race. Already there are reports of attempts to create chips based on living tissue, which promises unprecedented opportunities to the world. But is the informational progress over the technical one so soon?
For games, video, music, accounting applications and most databases, the available capacity is enough. The further technological progress goes forward, the less excusable is its lag behind the informational one. Indeed, in this area, in comparison with the technical, so far nothing radically new has been proposed, and consequently, there is no place to progress. This is well understood by the developers of information technology hardware: the staff leave, production closes, product prices fall. But in the information area things are not better. If there was a lot of work in it before, now it is clearly stalled. Judge for yourself - more and more of these professionals, but the areas of application of their knowledge are almost the same: web-development, database management and development of accounting applications. Consequently, many of the experts are out of work. And what can we say about people who do not know programming languages or who do not know how to program at all, but who are able to influence information technologies with their originality, unusual talent, knowledge and skills in other areas. They would attract! I want to share my thoughts on how to use this potential. I hope it will be beneficial both materially and morally to everyone who will listen to my words. By “all” I mean this:
1) extraordinary people with unusual talents;
2) programmers looking for opportunities to apply their knowledge and skills;
3) specialists in the development, creation and connection of various hardware computer “lotions”;
4) all those who are able to further increase the clock frequency, increase memory and the like.
What do I understand by the words "financially" and "morally"? I explain to you the essence of the idea. Using it, you become a developer of very expensive systems. So much for your material satisfaction. In addition, you are the author of the system, and depending on its level, you get the corresponding equivalent of recognition. And it can be considered as moral satisfaction.
Now that I thought up. And he came up with an easy way to create robots with artificial intelligence, which is quite comparable to human, in everyday life.
If you are a pessimist, this is not for you.
I am perfectly aware of how much fair distrust is caused by such statements. And this is quite understandable, but first I want to give a few examples that will help you overcome pessimism. If you are not able to cope with this enemy, it is better to turn the page.
Recently, talking with a friend about the possibility of creating artificial intelligence. He will take it to me and say: “Oh well, such things are not done by IF operators alone (IF - in Russian“ IF ”)”. In fact, it should be understood: "I can not imagine how to do it." After all, my friend perfectly understood that the question is not in the use of some operators, but in the complexity of writing the mechanism of intelligence itself. Any sane person will not dispute the fact that all the most complex programs known to us at the level of machine commands generally work with the simplest operators and a set of several registers. It all depends on how unusual a person looks at the problem and how it solves it outside the box; whether he tries to understand the fact or turns away from him. It is non-standard solutions that in many cases make us wonder, exclaiming: “It cannot be. How did this happen? ”And, a little later,“ Why did I not think of it before? ”And all because they tried to solve the problem using the usual method. A striking example of a non-standard approach is the Mars program. It was written at a time when there were no graphics accelerators or huge amounts of memory. The program on the 386th processor in real time simulated movement above the surface of the planet. In addition, the program was written so that its volume was only 4 kilobytes! Feel the difference between its volume and the volume of modern game engines (it is clear that they are much more able, but still). What about complaints from modern gamers about the lack of speed of their computers to build game scenes in real time? And on the 386th car without super-duper video cards in the Mars program, not a single frame fell out. And many programmers of that time, when they saw Mars, wondered: “How did they do it, and even in 4 kilobytes?” But a non-standard solution was just the replacement of complex 3D-construction mathematics with tables of pre-calculated values. This led not only to raising the speed of rendering the planet’s landscape, but also to reducing the size of the program. And there are a lot of such examples in life.
How robots are prepared
Development of a robot with artificial intelligence includes the development of software , logic and technical parts. To begin, you must form the necessary development teams for each of the parts. As a rule, one in the field is not a warrior, so this work should be done by a group. Well, these are organizational issues that are for you, not for me.
The software development team, IMHO, consists of programmers and is engaged in writing both the software internals of the robot and the editors of its logic modules. Here, the ways of writing the software engine of the robot will not be considered, since the main task is to convey the idea to those who have ever (or have to) develop a logical part. The program group is able to figure out what procedures, functions, and the like should be written in the engine. She will also have to give the logical group some ideas about the data types used in the robot. In general, all groups will have to work closely with each other, and the program group will often have to act as a project coordinator.
The development group of the logical part consists of people who are able to describe the logic of the work of a living being (psychologists, teachers, philologists, etc.)
The technical development team includes specialists responsible for the mechanical parts of the robot (arms, legs, eyes, etc.). If a virtual creature is being made, then you can do without a technical group. In any case, you should clearly consider these points.
Having decided what robot you will be doing, you start writing a software engine. Behind the engine comes the turn of the logical and technical part. In the course of creating the logical part, the incomplete moments of the program part are communicated. The result is a finished robot. In general, an idea implies the possibility of writing a universal engine, to which the logical part then clings. That is, the "logic" can buy a ready-made engine and connect its logic to it.
Device logical part
The entire logical part consists of a set of matrices, in the cells of which the logic of the operation of the robot is programmed. It is permissible to store any type of data in any cell of the matrix. The cell is designed so that it allows you to easily connect the cells of different matrices with each other, regardless of their types. The matrix supports multilingualism, which makes it possible to develop logic for several countries at once in one matrix. In addition, the use of any element of the matrix is not for its intended purpose. And in general, the structure of the matrix is quite simple and provides a kind of universal skeleton, parts of which the developer will upgrade to fit his own needs. Moreover, the idea implies unlimited modernization while maintaining simplicity and a single line of realization of the matrices of intelligence. The software engine uses matrices and literally jumps over their cells, executing, processing and analyzing the data in them. No one limits the software engine in the cell processing methods. For example, when it hits some cells or certain data types, it is permissible to invoke various internal functions of the program engine. It is acceptable to treat some cells as starting points, generating chains of any operations with automatic output to other cells in the chain, and so on. As you can see, there is room for creativity. Matrices with relative simplicity allow you to create complex logic. Therefore, consider them 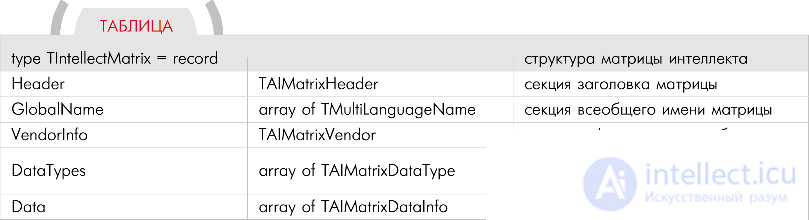
device closer.
Any matrix consists of five sections: a header, a universal matrix name, developer information, a list of data types used in the matrix, and matrix cells. Next, I gave the full structure of the matrix.
Here and in the future, all structures will be described as applied to the Delphi programming system. I think that programmers will be able to adapt these structures for other languages. In black, I highlighted the names of the fields, in red - their types, in blue - comments to them.
Below are the structures for each section of the matrix. We will consider only those fields that are necessary for the development teams of the logical and program parts. I marked such fields with x in front of their names. The remaining fields are of interest only for the program group.
Matrix Header Section
The header section contains all the basic information for transporting matrices. 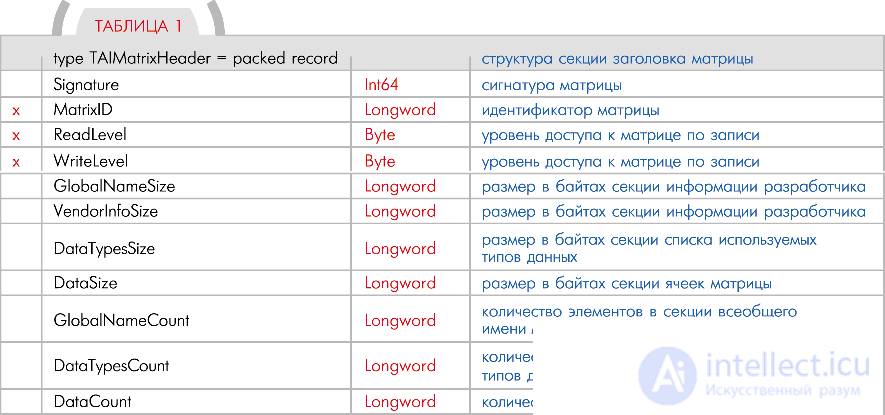 with the help of various information carriers ( Table 1 ).
with the help of various information carriers ( Table 1 ).
The MatrixID field contains the unique identifier of the matrix (its number). To access a specific cell of a matrix, you must specify the identifier of the desired matrix, followed by the identifier of the desired cell. The left side of the cell pointer will always contain the matrix number, and the right side will contain the cell number. For example, the pointer 43:25 points to the 25th cell of the 43rd matrix.
The ReadLevel and WriteLevel fields are intended to specify the level of access by reading and writing to this matrix. The larger the value in these fields, the higher the level must be for the requester to access the matrix data. In practice, these fields may not be used at all, or used entirely for other purposes. But with the help of them it is possible to realize the following similar to the human behavior of the robot.
An example for the ReadLevel field. The robot is asked a question: Do you love Anya? And the matrix with data about Anya is marked as “very personal” for the robot (that is, it has the highest level of access). The initiator of the request for data about Ana - in our case it will be a system for constructing an answer to a question - has a low level of access to operate with the most “intimate” feelings of the robot. But the software engine of the robot must return some kind of result to the request initiator, which can be fictitiously entered into the matrix fictitious data for initiators who do not belong to the circle of secrecy. Here you have one of the simple options for the realization of lies.
An example for the WriteLevel field. If for the robot to provide the opportunity to generate their own kind, plus the ability to change any signs of heredity, then you will inevitably have to decide how the robot will change this heredity. After all, the DNA matrix of the robot in this case should have the maximum access level by writing. And the system for changing the hereditary characteristics of a robot must have very good reasons (an appropriate level of access) in order to perform write operations in the DNA matrix.
Matrix Universal Name Section
This section supports multilingualism and is intended for a completely ordinary text label of a matrix. Despite the fact that the matrix must be addressed through its identifier and cell number, you may need this section for some non-standard actions. First, when developing the logic of a robot, it is very convenient to associate to each matrix identifier some commonly used human word (name). Secondly, it is possible to implement in the software engine a query processing mechanism with a obviously unknown matrix identifier, but with a known name. For example, the robot is asked a question: Do you know Petya ?. Obviously, after analyzing the sections of the universal names of matrices, he will be able to find the identifiers of the matrices that belong to all the known robot, Peter.
As you can see, the universal name section is represented in the matrix structure by an array of elements with the type TMiltiLanguageName, which allows for multilingualism. Therefore, here we consider this type. It allows you to set a name in a particular language of the world. The language identifier is set as it is set for Wide-strings in Windows. For example, the code of the Russian language is 0419h , the code of Ukrainian is 0422h , English is 0409h , German is 0407h , French is 040Bh, and so on.
Note that the number of elements in the universal name section is given by the field  GlobalNameCount of the header section of the matrix ( Table 2 ).
GlobalNameCount of the header section of the matrix ( Table 2 ).
The Name field contains the universal name of the matrix by which it is necessary to search for it, using various string search functions.
Description field allows you to specify next to the name of the matrix any additional comment to it, to its content or purpose.
Developer Information Section
This section contains information related to the design of the corresponding matrix. Since even individual matrices can be sold by developers, this section is intended to fill in data on the matrix version, 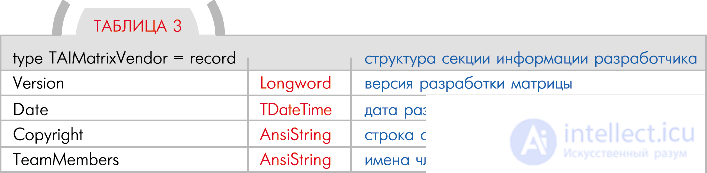 date of its manufacture, etc. ( tab. 3 ).
date of its manufacture, etc. ( tab. 3 ).
All fields of the section should be filled with the development team of the logical part, but they are not used in the logic of the robot itself. I think that you will understand the purpose of each of these fields without my help.
Section used in the matrix data types
This is an auxiliary section, it has no effect on the logic of the robot. Its purpose is to store, during the development of the matrix, a list of data types used in it. In the future, the group of "logic" decides whether to remove this list from the matrix. Thus, this section may be absent altogether. It is represented by an array of elements of type TAIMatrixDataType. The number of elements in a section is specified by the DataTypesCount field of the matrix header section ( Table 4 ).
A section may not reflect the full list of data types used in the matrix, but I think that it is worth making all the used types. Moreover, it will avoid problems when docking different matrices from different  developers. While there are no standards for numbering types, and different developers can number them in their own way. With the help of this section you can find out what types the matrix developer used in its cells. Despite the fact that there is no direct connection between the section list and the data types actually used in the matrix, it is still unpleasant to buy the matrix and be ignorant of the data types used in it.
developers. While there are no standards for numbering types, and different developers can number them in their own way. With the help of this section you can find out what types the matrix developer used in its cells. Despite the fact that there is no direct connection between the section list and the data types actually used in the matrix, it is still unpleasant to buy the matrix and be ignorant of the data types used in it.
Here is an example of a small list of used data types.
1. Fuzzy truth
3. Text
4. Integer
32. Bitmap image
64. Right handler
2048. Video clip
As can be seen from the list, it has a purely informative function and does not pretend to be complete and reliable. With this list, the developer as if declares to his colleagues and future employees that he used such and such data types, thereby helping them to quickly figure out how to connect the matrix.
Cell section matrix
The section of cells is also represented by an array of elements with type TAIMatrixDataInfo. As a matter of fact, it contains all the logic of the matrix. The number of elements in a section is specified by the DataCount field of the matrix header section. Each specific element of the section is a separate cell of the matrix ( Table 5 ).
The CellID field contains a unique cell identifier. What this identifier means is described above in the matrix identifier field. 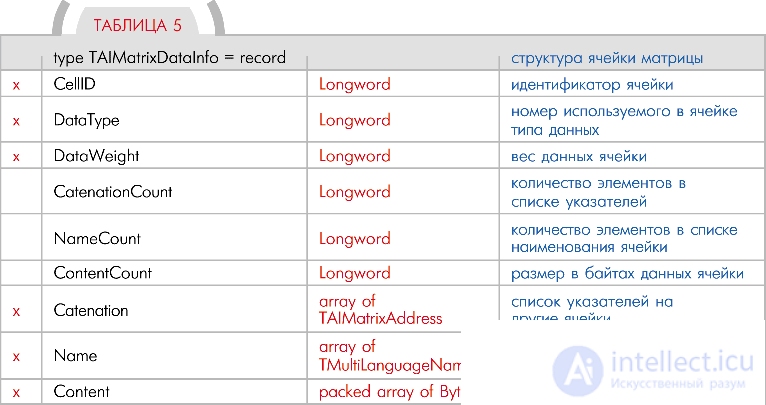 Notice that the cells inside the matrix do not have to be ordered. That is, a cell with a larger number may be at the very beginning of the matrix; a cell with a smaller number may be either at the beginning or in the middle, or at the end of the matrix.
Notice that the cells inside the matrix do not have to be ordered. That is, a cell with a larger number may be at the very beginning of the matrix; a cell with a smaller number may be either at the beginning or in the middle, or at the end of the matrix.
Some data is placed in the cell, which means that they have some type. The DataType field contains the number of the data type placed in the cell. As mentioned earlier, a partial or complete list of the names of the types used is in the auxiliary section of the DataTypes (see the matrix structure).
The DataWeight field is intended to specify some numeric data parameter in the corresponding cell with respect to something specific.
The Catenation field contains a list of various pointers to other cells in matrices (not just cells of the current matrix). Actually, the field is represented by an array of elements TAIMatrixAddress. This type will be discussed below. Количество элементов в массиве задано полем CatenationCount этой же структуры. Несмотря на то, что все указатели имеют одинаковую структуру, вариации их видов и способов использования зависят только от возможностей программного движка вашего робота.
Поле Name предназначено для хранения имени конкретной ячейки. По своей структуре это поле схоже с полем всеобщего имени матрицы. Оно так же поддерживает многоязычность и тоже является массивом из элементов с типом TMultiLanguageName, но количество элементов в этом массиве задается полем NameCount структуры ячейки матрицы. Опять же, поле имени ячейки может использоваться для разных целей. Вам никто не мешает реализовать функции поиска по наименованиям ячеек. Тогда, например, на вопрос: «Что такое вилка?», робот сможет найти все адреса ячеек, которые содержат данные о вилках.
Поле Content представлено массивом из байт и содержит в себе помещенные в ячейку данные. Размер массива задан полем ContentCount этой же структуры. Массив просто содержит данные, а их структура определяется уже вашими собственными законами, разработанными вами же для этого типа данных. Например, нужно поместить классический текст: «Здравствуй, мир!» в ячейку. Это у нас будет тип данных — строка. Дадим этому типу, например, номер 18. Значит, в поле DataType заносим число 18, в поле ContentCount заносим число 16 (длина строки), а в массив поля Content заносим один за другим все символы строки. Или такой пример. Допустим, мне нужно использовать в ячейке свою структуру данных с двумя полями: одно из 7 байт (а не из 4-х, как обычно) для целого числа, а другое из 3 байт для какого-то признака. Даю этому типу данных свой номер. Представим, что у меня уже используется 18 разных типов данных. И новому, чтобы не нарушать нумерации, я решаю дать номер 19. Этот номер заношу в поле DataType. В поле ContentCount заношу число 10 (размер данных = 7 байт для первого поля плюс 3 байта для второго). Ну, и в массиве поля Content выделяю место для 10 байт моей собственной структуры данных. При необходимости заношу какие-то изначальные значения в поля этой структуры. Таким образом, в ячейке оказалась записана новая структура, а ее обработка уже входит в задачи программного движка робота. Ведь «логику» неинтересно, как извлекается, сохраняется или обрабатывается определенный тип данных. Для него поле Content является источником данных, а как они там хранятся — это не его вопрос, а программистов.
Теперь рассмотрим тип TAIMatrixAddress, с помощью которого задается указатель на другую ячейку ( 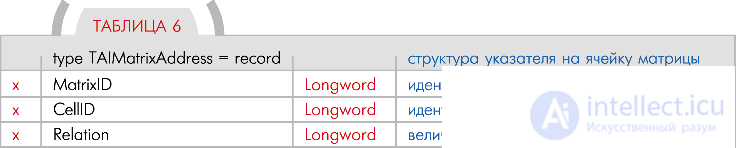 tab. 6).
tab. 6).
Поля MatrixID и CellID содержат указатель на определенную ячейку. Как было сказано выше, адрес ячейки задается идентификатором ее матрицы плюс идентификатором самой ячейки.
Поле Relation предназначено для задания типа соответствующего указателя. Кроме того, это поле можно использовать, например, для задания уровня весомости данного указателя по отношению к другим указателям в списке. То есть, возможности для использования поля очень широкие. В зависимости от его значения это может быть указатель перехода, указатель вызова какой-нибудь функции обработки периферийных устройств робота, указатель соответствия ячейки какой-то другой ячейке, указатель уровня важности обработки некой ячейки и так далее.
Знакомьтесь — основные типы данных.
Как уже было заявлено ранее, моя идея позволяет использовать любые типы данных. Не мне вас, учить какой из них и как использовать. Но все же я подробнее остановлюсь на одном типе, в основе своей заимствованном мной из нечеткой логики.
Тип FuzzyTrue — нечеткая истина — основной элемент для создания нечеткой логики. Если в булевой логике есть два значения (истина и ложь), то в нечеткой логике между истиной и ложью лежит много значений. Эти значения можно назвать долями вероятности результата . В обычном языке человек выражает доли вероятности при помощи наречий («чуть», «слегка», «менее», «более», «почти», «около», «где-то рядом», «совсем близко» и т. п.). А значит, на любой нечеткий смысл мы можем найти какой-то четкий диапазон понятий.
Consider an example. К вам обращаются: «Дай мне немного семечек». Несмотря на то, что «немного» — понятие растяжимое, вы отдадите действительно немного, а не все семечки. Немного — это всего лишь доля вероятности от всех имеющихся у вас семечек. И эта доля при всей своей кажущейся нечеткости имеет достаточно четкие математические грани. Причем, вспомните, каждое последующее отдаваемое «немного» начинает уменьшаться пропорционально оставшемуся количеству семечек. И каждое «немного» будет всегда приблизительно столько-то процентов от имеющихся семечек.
Теперь, если мы определенным словам сопоставим конкретные процентные отношения, то их смысл уже не будет казаться таким расплывчатым (процентные отношения взяты «с потолка», исключительно для наглядности).
Также обратите внимание на тот факт, что каждому нечеткому вопросу всегда явно или неявно ставится в ограничение соответствующий диапазон ответов. То есть, «дайте мне чуточку соли» от ее объема на столе, а не где-нибудь в вагоне на складе. Таким образом, при помощи типа FuzzyTrue можно дать четкий числовой ответ на нечеткий вопрос с конкретным диапазоном ответов. Не обязательно привязывать ответ к процентам. Это может быть, например, и 200 единиц от общего количества в 38000 единиц (немного сахара от его объема в мешке).
Как в булевой логике выполняются разные операции над булевыми типами, так и в нечеткой логике над типом FuzzyTrue можно выполнять операции AND , OR , XOR и т. п. Но результатом будет уже нечеткое множество, потому что операция выполняется не над одними долями вероятностей, а над долями, привязанными к их диапазонам результатов. Соответственно, полученное множество будет читаться приблизительно так: с такого по такой диапазон доля вероятности такая-то, от сих и до сих — сякая, в этом диапазоне — еще какая-нибудь и т. д. Значит, нечеткое множество можно представить массивом значений, где каждый первый элемент значения задает диапазон или какую-то определенную его точку, а второй элемент задает долю вероятности для этого диапазона или точки. Чтобы вы не запутались, объясню это на следующем примере.
Представим, что в одном магазине решили создать робота, раздающего рекламные буклеты входящим в магазин покупателям. Но раздавать нужно не всем подряд, а только определенному кругу людей. Считаем, что в магазине решили выбирать покупателей по возрастному признаку (а ведь робота можно научить выбирать и по дороговизне одежды, количеству золотых украшений, классу подъехавшей машины и т. д.). Нам пока не важно, как в магазине научили робота определять, стар или молод покупатель. Мы смотрим, как он использует нечеткое множество. Для простоты считаем, что он раздает один вид буклетов, подходящий для всех желаемых возрастных категорий. Если буклеты для каждой категории разные, то работа будет вестись с несколькими нечеткими множествами, а не с одним.
Итак, к примеру, робот получает от руководства магазина 1000 буклетов и несколько указаний по возрастным категориям:
Безусловно, малое количество параметров можно не объединять в множество и обрабатывать их скачками по разным ячейкам матрицы, где эти параметры сохранены. Но что если указаний становится все больше и больше? Все же лучше объединить их в множество и хранить в одной ячейке матрицы. В результате робот применяет операцию OR (логическое сложение) ко всем полученным указаниям и выводит из них нечеткое множество. Здесь я тоже процентные отношения взял «с потолка». Элементы нечеткого множества я упорядочил по первому полю элементов — диапазону возрастов. Второе поле — это процент выдаваемых от оставшихся у робота буклетов соответствующей возрастной категории покупателей. После операции OR 16-летний возраст попал в диапазон с большей долей вероятности. Заметьте, что в 40-летний возраст я поставил слово «каждому». На самом деле, вместо этого слова реально используется некое число, которое указывает программному движку робота, что это не процент от возрастной категории:
Далее робот оценивает возраст входящего покупателя, сравнивает возраст с нечетким множеством и поступает в зависимости от результата, извлеченного из нечеткого множества.
Строим словарный запас робота.
Я думаю, не только мне, но и многим из вас хотелось бы, чтобы разработанный робот мог не только выполнять возложенные на него функции, но и быть способным общаться с человеком, понимать смысл его речей. Опять же, оставим в стороне чисто технические аспекты проблемы (синтезатор голоса, распознавание произнесенного текста), но присмотримся внимательнее к проблеме распознавания смысловой структуры речи. Сначала мне хотелось бы привести следующий показательный пример.
Как-то я проходил мимо футбольного поля, где ребята играли в футбол. Один из мальчиков, получив мяч, начинает двигаться к воротам противника. Перед ним появляется несколько защитников противника. В этот момент с другой половины поля его товарищ по команде кричит: «Сергей, открытый!» Сергей пасует крикнувшему — действительно, ведь он один из всей команды нападающих никем не заблокирован.
I, who observed this scene from the outside, understood the meaning of the spoken phrase. In this situation, the word “open” meant the possibility of free movement of the recipient to the opponent’s goal. Imagine, for example, if a boy shouted: “Sergei, a microcircuit!” Nobody would understand the meaning of this phrase, because nobody knows what a microcircuit has to do with football. Obviously, for the construction of a sense recognition system, both the vocabulary of the robot and the correlation of words and phrases with events are important. I offer you the following idea of organizing the vocabulary of the robot.
So, one matrix is allocated that will contain the entire vocabulary of the robot. Each word (or phrase) is placed in a separate cell of the matrix. The text of the word is placed in the Name field of the corresponding cell. So that our robot does not lose face in front of a culture representative who slang words, slang words or terminology, it’s really possible to include various variants of a given word in one field, including foreign-language ones (we understand phrases like “Okay, I agree”). Do not forget that the Name field in its internal subfield Description allows for each name to specify its description - that is, you can easily arrange, for example, the corresponding encyclopedic article corresponding to a given word (in between cases, we already have something similar to multilingual encyclopedic Dictionary). Use the DataType field and the Content field as you like. You may want to attach some additional information (pictures, data, links, etc.) to each word. These two fields are just suitable for these purposes. The Catenation field contains a list of the uses of this word in different areas of knowledge of the robot. In fact, pointers to cells of other matrices containing knowledge of the robot known to the robot are placed in this field. One word in different fields of knowledge can mean completely different concepts. The Catenation field lists all variations of the concepts of a given word in different areas of knowledge of the robot. Each pointer to the matrix cell consists of two parts. If the left part of the index is zero (no matrix is specified), then such an indicator indicates that the word does not belong to any particular area of knowledge, and its universal meaning for all areas is in a cell of a certain predefined matrix, where the cell of this matrix is given right side of the pointer. That is, zero will be replaced by some real number of a predefined matrix, and the cell number will be taken from the right side of the pointer. If the left part is specified and the right part is zero (there is no cell number, and the matrix is indicated), then such a pointer indicates only the relation of the given word to the corresponding area of knowledge, but not its interpretation (recall, for example, how we say: something from the field of medicine, but I do not know what exactly "). Well, when both the left and the right parts are indicated, we will assume that the pointer refers to the possible interpretation of the given word.
Now let's see how it all works. The robot is playing football. We believe that his system of identification of events has established that an event is now happening, well, let's say, with matrix number 24 (suppose her name is “Play Football”). At some point, the robot hears the phrase: “Sergei, open!” The recognition system of the spoken phrase worked. I recognized the first word “Sergey”, transferred it to the further processing of the sense recognition system. Now is the place where the identification system is accepted for work. It searches the vocabulary matrix of the cell in which the word “Sergey” is written. Having found the required cell, the system analyzes the list of pointers in the Catenation field of the same cell. Imagine that there is only one 0: 8 pointer in this list. In the analysis, all pointers are ignored, the matrix identifier of which is not equal to the content, say, cell 24: 5 (the matrix is “Playing football”, and the name of the fifth cell, suppose it is “What field of knowledge is football built on”). As you might guess, the number of the matrix, which is the area of knowledge of the robot about football, is stored in cell 24: 5. Suppose that cell ID 57 is stored in cell 24: 5 (say, its name is “Football knowledge”). As a result of the analysis, our system did not find a single pointer to the matrix with the number 57. Therefore, the system can already make one conclusion: the word “Sergey” does not refer to the knowledge of football. Therefore, the system performs a second analysis of the list of pointers. But now she is looking for the first pointer with the left part equal to zero. Remember, as it was said that zero will be replaced by the real identifier of a predefined matrix (suppose it is matrix 11, whose name is “Universal Knowledge”). In the second stage of the analysis, the system found a 0: 8 pointer. For myself, it replaces zero by 11, the result is a pointer 11: 8 (matrix “Universal knowledge”, and the name of the eighth cell, suppose, is “Names of people”). Thus, the system identified the meaning of the word. She found out that the word "Sergey" belongs to the class of names of people and, most likely, with this word to someone now addressed. Moreover, the system owns a pointer to the interpretation of the word. But recognition of meaning is necessary for the decision-making system. And she is waiting for this pointer from the recognition system - according to this pointer there is a very important information for the decision-making system (what to do, how to do it, etc.). Now imagine that the decision-making system finds in the cell at the 11: 8 pointer such instructions for actions: 1) determine whether an object with this name is in the calling matrix; 2) if it is, then determine whether the name belongs to the robot itself; 3) if the name belongs to the robot, continue to analyze the phrase further, otherwise stop recognition.
Our robot name is Sergei and turned to him, which means that the analysis is carried on. Now the second word is identified - “open” —and it is again transmitted to the sense recognition system. Everything spun on the same scenario. Found in the dictionary cell with the word "open". Analyze the list of pointers in the Catenation field of this cell. Suppose there are three pointers (15:67, 57:25 and 38:21). At the first stage of the analysis, a pointer to the 57:25 cell was found (the “Knowledge of Football” matrix, and the name of the 25th cell, suppose, is “Undiscovered Player”). The resulting pointer is passed to the decision-making system. And she with the question "what should I do?" Looks at the data in the specified cell. And the following instructions are stored there: 1) analyze the likelihood of further advancement to the gates of the enemy; 2) if the probability does not exceed 80%, then give a pass 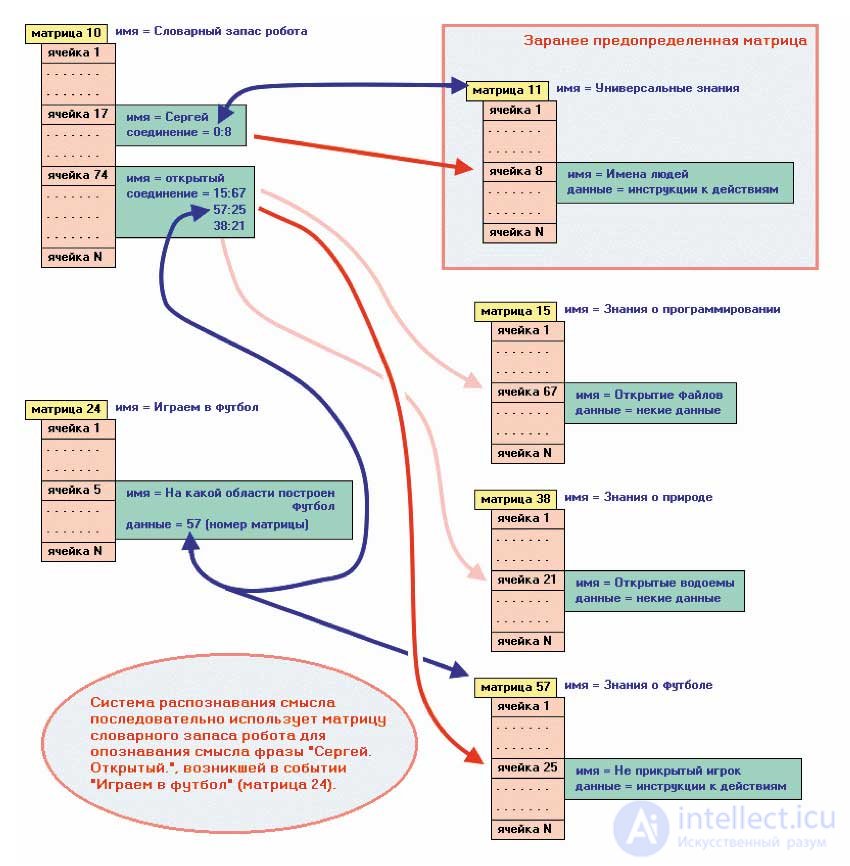 shouting, otherwise move to the gate itself.
shouting, otherwise move to the gate itself.
This picture shows the mechanism for performing the described operations when the sense recognition system is operating. The matrix 24 is the caller because an external event occurred in it (shouted), and it was for this matrix that the recognition operation was initiated. Naturally, the matrix 24 does not know where the vocabulary of the robot is located. This is known by the internal functions of the software engine recognition system. And it is also their responsibility to know which matrix will be predetermined in advance, and also to find out which additional matrices (knowledge) the matrix 24 relies on. And already from this data to carry out recognition.
We connect emotions
That is certainly noticed: "In a word, you can and kill." How acutely a person reacts to the spoken phrase! Only a seemingly insignificant substitution of a word in a sentence can radically transform its meaning. And even if, from a formal point of view, the meaning of the sentence does not change, emotionally the phrase may be perceived completely differently. Judge for yourself how the emotional coloring changes, for example, such phrases: “Hear, you, my sunshine” and “Listen, my sunshine.” Both in the first and in the other case they logically spoke of the same thing. But emotionally phrases are perceived in different ways. In the first case, the beginning of "Hear, you" adds color to the dismissive treatment of a person. The second phrase is much softer than the first. From here we make a simple conclusion: words have their own emotional weight and, depending on it, can give a negative or positive attitude to the text. Imagine if someone told you this: “By the time the house is five, there will be three and there will be eight.” You probably would have understood the meaning of the sentence, but would have noted to myself the rudeness of the interlocutor.
And now we will try to teach the robot to receive emotions from the heard speech. I propose the following idea. Please note that in the previous section we did not use the DataWeight field of the robot vocabulary cells. If in this field for each word to add a certain number, describing it as pleasant or unpleasant for the listener, then for any phrase you can get some quantitative positive or negative attitude to it. Consider this on the example of the previously proposed phrases.
Suppose the word "hear" we assign a negative weight of -100 units, the word "you" - negative weight of -10 units, the word "sun" - a positive weight of +50 units, the word "mine" - weight of +25 units and the word "listen" - weight in -10 units. Now add all the values for each phrase separately. For the phrase “Hear, you, my sweetheart,” we get a negative weight of -35 units. But for the phrase “Listen, my sunshine,” this weight will already be positive and equal to -10 + 50 + 25 = 65 units. Thus, the robot receives a numerical expression of the emotional relationship to the above. Already on the basis of these numbers, he can judge how to treat someone else's speech. The range of values of the DataWeight field allows you to vary the emotional color of the sentence in a fairly large range (from dislike to sympathy, etc.)
How to teach guess
In one of the programs “Field of Miracles” there was a question (unfortunately, I no longer remember its exact wording) about what they had made in the past in a certain country of algae. And, importantly, this is something made specifically for humans. At first, no one could understand what was meant. After Yakubovich gestures tried to tell players otgadku, it became clear what was going on. He hinted at the length of the algae, their structure and color. But the players need only to guess that it was a wig.
In this case, the whole process of guessing looks like this. The player, based on the suggested features (length, structure, color), selected from the data about a person everything that has similar features. Further, comparing the names of the selected features with the letters already opened, the player guessed the answer. Players have a different amount of accumulated data about a person, so one player has time to guess, and the other one, until the end of the game, does not understand what it is about.
In order to teach the robot to guess, it is necessary, whenever possible, to provide each property you wish to guess with pointers to similar properties of other objects. Naturally, it is foolish to try to connect everything with everything. A robot can initially only have some basic set of bundles, and all the other suddenly needed properties can be linked in the course of its evolution - just like a small child develops gradually, and does not immediately know everything at birth.
We already have a signpost field. This is the Catenation field of the matrix cell. But we need not just a pointer, but a pointer with the ability to set the magnitude of the similarity of one property with another. After all, for example, the length of algae can completely coincide with the length of the hair, or not quite, or partially, etc. In relation to the length of the arm, it coincides by so much and so much, relative to the leg - by so much so much. Who has more similarities, he is closer to the result of the guess.
Since the Catenation field includes, in addition to the pointer fields, the Relation field, we can put in it the similarity value of this property with another property defined by the Catenation field pointer.
What did we get as a result? The matrix cell with algae data is supplied with a series of similarity indicators with different objects. Please note that pointers can be mixed with other types of pointers. Remember the example with the vocabulary of the robot. After all, the Relation field can be interpreted according to your own principle. For example, if it contains 0, then it is a dictionary of vocabulary, 1 is a pointer to something else, 2 refers to something else, and all other values are a pointer with the corresponding similarity value. Now the robot analyzes the list of pointers. There is a similarity with the length of such a flower. No, it does not fit. There is a similarity with the color of such a bird. No, not that again. There is a similarity with something else ... and so on. Yeah, the robot did not find anything, and therefore could not guess what it was about. Then he was told the answer, and he adds to the data on algae that wigs were once made of them. But he is also obliged to add algae similarity indexes with hair in the field of algae data cell pointers in length, color and structure. Naturally, each pointer must be provided with its own value of similarity.
Why is the robot required to do this? And because if this is not done, then it will be an ordinary piece of iron, unable to reflect. He is asked the question: “What in the past in such and such a country was made of algae for people?” He answers: “Wigs”. He is asked the following question: "What in the past in the neighboring country did not want to produce from algae for people?" He replies: "I do not know." Though with correctly written system of the analysis, being guided by indexes of similarity he should guess. That's why he has to do it.
Conclusion
Robots are needed everywhere. Naturally, they can be created both for good and for harm. I wish there were more good goals, but these are already questions of developer ethics. A hint is asked, but it will be expressed by an unusual hypothesis. I think you will understand how important your efforts can be for the development of mankind.
Once upon a time there was one civilization. Time went by. Civilization has evolved. Finally, she reached the level when she learned how to make artificial living beings. Another time passed, and it was decided to hold a competition for the best artificial creatures. A great number of the best creatures were sent to a ship in a far space. It is not known why, but it was the Earth that became the home of these creatures. Time went by. And already a new civilization developed on Earth. This civilization has already learned how to make artificial creatures. Already they hold a competition. And now a spaceship is rising from Earth to take a new life to the far expanses of space. Perhaps its creators will never see their offspring, nor will they see the majestic flowering of a future civilization. And life will go on as usual, through all civilizations and ages.
I do not want to impose any hypotheses on you, but look at our civilization through the eyes of a bystander. There is no doubt that it is man who crowns evolution on Earth. Now imagine what happens when a person learns to make truly living beings. And I'm sure he will make them. Not today and not tomorrow, it will take a very long time, but man will make robots, because he needs them. Manufacturing techniques will be improved, the experience of creating artificial creatures will grow, and someday the time will come when the same Adam and Eve will come out from under the “scalpel” of robotics. I don't mean that they will look like biblical characters. By and large, this is not so important. The only important thing is that they will be similar to people with the ability to reproduce their own kind and exist without assistance. And you know why a man will ever do it? Because evolution requires it. But the evolution is not of the man himself, but of the earthly civilization - a huge living organism.
One may say that from an inconceivable number of planets of the Universe only on one Earth, by chance, carbon molecules correctly formed each other, having once formed the first cell, from which the whole earth civilization came later. Which, in turn, is already approaching the synthesis of this very life by artificial means. Does a person violate the theory of evolution? After all, not a single living creature on Earth has created a new branch of life in this way. Inevitably, the question arises: if a person is descended from a creature on Earth, then why is there such a gap in development between man and all earthly creatures? Does any of our four-legged friends care about the existence of beings like them somewhere else in the Universe? Which of them tried, for example, to pray to God or to create for themselves an assistant who would cook food, clean the dwelling, etc.
We do not perceive our civilization as a living organism. But according to the same theory of evolution, and it is evolving, and is also capable of producing its own kind — other civilizations. Man is like the birthing part of a civilization. They create an embryo (the first living robots), they also develop (more advanced models are created, their interconnections among themselves - roughly speaking, who will run errands), and only then “birth” occurs (not on the planet itself, where there is already life, and it is quite aggressive and cruel - a person has nothing to do with it, only “bend over”).
Yes, all these are hypotheses. But you must admit, they also explain quite well the difference in development between man and other earthly beings. In a word, aliens, gods and all that.

Comments
To leave a comment
Artificial Intelligence
Terms: Artificial Intelligence