Lecture
Language structureUnderstanding a language message is akin to decoding. Using logic helps to understand an unknown message. This principle is the basis of the machine understanding of the text. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
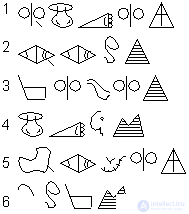
The writing of the Hittite tribes was deciphered due to regularities in the language. Six tablets were found, and it was hypothesized that they correspond to six concepts: two countries (Hamatu and Palaa), two cities (Curcuma, Tuvanava) and two kings (Varpalava, Tarkumuva). |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
  |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
We count the number of syllables in words known to us and the number of signs in the tablets. The number of characters is equal to the number of syllables plus one. The first conclusion is a syllable letter. Note that some signs are found only at the end. Obviously, these are some kind of service characters. Continuing the argument, we come to the conclusion that one syllable corresponds to one sign. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Considering the first tablet and comparing it with the word War-pa-la-va, one can figure out that the first and fourth signs, like syllables, are the same, except for the dash and the letter "p." So dash means the letter "p". Knowing how to spell "WA", you can decide on the third and sixth table. The second tablet is Curcuma, since two identical syllables follow each other and there is a line meaning the letter "p". we now know how to spell "ma". It is easy to find "Hamat" on the sixth plate. Knowing all the translations, we logically establish the meaning of official characters at the end of words. The last sign speaks of the concept class - country, city, king. Note that decoding is possible in another way, which means information is redundant. After decryption, you can write the message itself in the Hittite language. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Task 5. Write in Hittite "Tsar Arthur", "Tartu City", "Tuva Country", "Narva City", "Tsar Part". |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Decoding in this case was simplified by the fact that we were dealing with a bilingual. There was information in two languages at once. Therefore, deciphering yielded a rather small text. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Deciphering the language of Muyow (Papua New Guinea) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Message diameterThere are ambiguities in the text, due to the fact that we ourselves speak ambiguously. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Example. "Letters to a friend from Kiev will not replace the photographs of his beloved and dear daughter Maria" - a phrase that has more than 1000 meanings. Note: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Decrypting messages is an iterative process. Any hypothesis is put forward, if it is not confirmed further in the text, then we are forced to return and change the hypothesis. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The larger the message, the less the ambiguity will be in the perception of the text. Therefore, it is required to transmit redundant messages. The more text, the more likely that you will understand. The diameter of the message for its unequivocal reading depends on the number of graphemes (Hawaiian - 19, Russian - 33, Armenian - 38), on the number of sounds indicated by one grapheme (hard - soft), on the degree of redundancy (number of signs duplicating each other). Typical alphabetic language redundancy is 70 -80%. Verbal language (China) has 50% redundancy. In syllable - 60%. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The shortest message length for an unambiguous reading is called the message diameter. In Hawaiian, the diameter is 20 characters, in Russian - 70 characters, in Armenian - 80 characters, in Chinese - 1,000,000 characters. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
More patterns. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Start writing where the edge is aligned. Grammatical morphemes (endings, prepositions, conjunctions) are less than lexical (roots). They are more common and combined with a large number of diverse lexical morphemes. The text is compressed to the end of the line. Before the verb there can be no preposition. There is no union between the subject and the predicate. And so on. A general set of rules has not yet been compiled. Identify patterns and more complex research. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Shevoroshkina - Sukhotin algorithmThis is how the algorithm for separating vowels from consonants works. Take the phrase from the article "Mysterious Letters" "One of ..." and imagine that we have a text in an unknown language. Where are the vowels, and where are the consonants? Let's write the text without spaces between words, but leaving punctuation marks - they sort of break the sound circuit. For each letter, we write out all its immediate left and right neighbors inside the audio circuit. For the first letter about it there will be combinations: od, bol, ditch, voch, mountains, mov, bot, hot, thief, rosh, ditch, kog, ho (it is more convenient to write them in a column). Now select the repeating pairs (no matter which letter is left and which is right neighbor). For the first four letters o , d , and , n we get: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
From the first and third it can be assumed that o and u belong to the same class, since they have common neighbors p and t then c, p, d, b, t, n. d, w, f, m belong to another class. But it follows from the fourth that, in turn, is opposed to and, s, e, a, c , which should belong to the first class. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Thus, we get a partition: first class - o, i, s, e, a, c ; second class - v, p, g, b, t, n, d, w, f, m The data of the second point confirms it. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
How to decide which of the distinguished classes constitute vowels, and which - consonants? Usually in the sound system of the language of different vowels less than different consonants; accordingly, the vowel must be less in the alphabet. Obviously, the first class is the vowels, the second is the consonants. You can see that in one case the algorithm gave an error: it fell into the class of vowels. However, if you take a longer text for analysis, the error is likely to disappear. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The conclusions were made on a very small material, and yet we got the right distribution for 15 letters out of 16. The Shevoroshkin-Sukhotin algorithm was tested on Russian, English, German, French and Spanish materials in texts of 10 thousand characters each. On the material of the German language, the algorithm gave three errors (due to monotonous letter combinations), in English, Russian and French material - one error, in Spanish - not one. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Alice Kober CoordinateThe idea of Alice Kober in general is to enlighten the structure of the syllable signs of an unknown letter, like an x-ray beam, by separating the consonants from the vowels. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Analyzing the Cretan clay tablets, Alice Kober found that they contain variable words. This was indicated by general signs of the base and different endings. Many of the words could be nouns - with them there were numbers (the signs for numbers were still deciphered by Evans). Variable words could be put together in paradigms - like our declinations. Only Cretan nouns in the texts were allocated only three case forms. If we compare it with Russian words, it could look, for example, as follows:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
In a Cretan letter, these words would be written with syllables:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Here x is the graphic basis of the words, y, ya, z are different case endings. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Exploring changing words, Ventris remarked that not all signs are used in the role of u, but only a few. From this he concluded that in different ys there is one and the same vowel G1, characteristic of this case ending, and different consonants (C1, C2 ...), belonging to different roots. Then for each triple the same final consonant of the root (C1, C2 ...) must also be in z paired with another vowel T2 corresponding to the third case ending. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
This conclusion can be presented as a table:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
This table is the germ of the grid, opening two dimensions of Cretan syllable signs - "consonant" and "vowel". Looking for new "nouns", we continue the series C (for example, table-a - C3 = l, bug-a - C4 = k). Looking for new types of word changes, you can continue a number of vowels. If we take into account all types of words (suppose there may be changes in the type of the grammatical kind of adjectives - good, good, good), then in the form of a similar table, but with a much larger number of cells, you can imagine the entire grammar of the language (the system of word changes ), at least used in texts. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
So far, however, in the table - the grid - there is still no sound value that could associate the resulting grammar with a specific language (our Russian substitutions do not count). These specific sound meanings should be obtained by substitution, trying grammatical endings of different languages. Properly found language, being a "key", will immediately open up the sound meanings of many of the characters that make up the words of a known language. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
A. Kober pointed out the way in which in the process of systematic and painstaking searches one can come to the right result. Michael Ventris managed to go this way to the end. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Harris algorithmAn outstanding representative of American descriptive linguistics, Sellig Harris (1909-1992), developed an algorithm for dividing sentences into morphemes in an unfamiliar language. Usually, when you need to make out a word by its composition, we look for single-root words, that is, words that are similar not only in sound but also in meaning. Harris's algorithm is good in that it does not require an appeal to the meaning, because it is designed to work with an unknown language. However, the algorithm, of course, receives information about the language being studied - in the form of a large-scale source code from which a statement is selected for analysis. The text is not processed manually, but on a computer. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The idea behind the algorithm is simple and familiar to many in the game of "noodle." Players take turns making a word out of letters. The first letter can be any, with each subsequent choice is significantly reduced, and for the last usually there is only one option. A similar text is constructed in the same way. The uncertainty of the choice of a letter (the number of variants) gradually falls from the beginning to the end of a word and increases sharply at the boundaries of words. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
So, in the source text (where words can be written without spaces, while Harris also has a phonetic transcription - he worked with unwritten Indian languages), he chooses a statement for analysis. It can be considered as a chain of letters or characters of transcription between points or pauses. In the first step, take the first letter of the statement and write out from the text all its combinations with other letters. For example, the following statement: At the output we get a new partition. After checking the entire text, they find out what is found in combinations: on, but, not, not, us, well, nn, nt, ns, nch, i.e. only ten different “successors” follow in the text. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
In the second step, examine the letter combination on . He has the following continuations throughout the text: v, d, s, m, x, i, w, s, p, h, b, d ; total 12 "successors". In the third step, we examine the letter combination nav . Only four “successors” were revealed for him: s, o, and, c . This procedure is repeated until the end of the statement, adding one letter to the checked letter combination at each step. Results - the number of "successors" - are entered in the table:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
If the initial hypothesis is true that the diversity of letters is greater on the boundaries of words (morphemes) than inside the words (morphemes), then large numbers should indicate such boundaries — peaks of uncertainty. In this example, the greatest number is 12, after which the morpheme border is drawn. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
To clarify the results of division into morphemes, the same procedure is done from the end of the statement, calculating the number of "predecessors" first of the last letter, then the last two, etc. After separating part of the word from the border, you can start the analysis procedure from the next starting point, in this case with the word exit. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The reliability of the result depends on the amount of text. Harris's algorithm was checked on 100 sentences of the English text, in 85% of cases the morphemes were correctly identified. True, the texts had to be taken in the transcription: English spelling noticeably lagged behind the development of the language itself. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
You can read more about decryption of a message in various languages ... |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
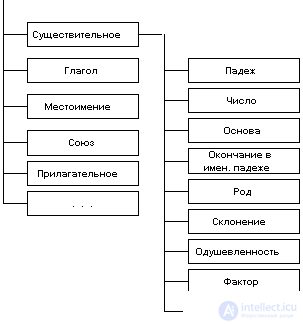
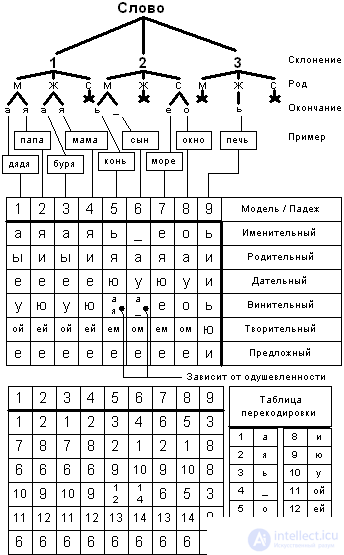
Let us show a fragment of the mathematical model of the Russian language. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
  |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Using this model, one can perform both word analysis and word synthesis in a sentence. Note that this is not a complete table. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Text analysisThe text is analyzed according to the following algorithm. According to the list of punctuation marks, the text and sentences should be broken into words. Determine the end of each word. Determine the part of speech and clarify the attributes of each word. Conflicts are dealt with using a number of special rules (for example: a verb has no preposition; the verb to “-ot” is used with a noun in the accusative case without a preposition; there is no union between the subject and predicate). Define parts of a sentence (an example of a rule is the addition - it is a noun with prepositions for in the genitive case, for the instrumental case, under the accusative case, without the genitive case, and so on). Identify the subjects and objects in the text and the existence of links between them. Objects and subjects form a problem model in their relationships. Bringing the issue to the model closes it. Now you can solve any inverse problems by asking questions to the text. According to the list of punctuation marks, the text and sentences should be broken into words. Determine the end of each word. Determine the part of speech and clarify the attributes of each word. Conflicts are dealt with using a number of special rules (for example: a verb has no preposition; the verb to “-ot” is used with a noun in the accusative case without a preposition; there is no union between the subject and predicate). Define parts of a sentence (an example of a rule is the addition - it is a noun with prepositions for in the genitive case, for the instrumental case, under the accusative case, without the genitive case, and so on). Identify the subjects and objects in the text and the existence of links between them. Objects and subjects form a problem model in their relationships. Bringing the issue to the model closes it. Now you can solve any inverse problems by asking questions to the text. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Questions can be 4 levels. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
PhonosemanticsThe word has two properties: the conceptual core and the halo. The conceptual core contains the meaning, the halo - the coloring of the word. For example, the words papa, papulechka, father carry one meaning (the parent is a man), but carry different emotional tints. But if the halo objectively exists, then it can be measured. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Take a group of people (for definiteness - 50 people.). And on a scale from 1 (very good) to 5 (very bad), we ask you to determine the grade for the given word. We measure the frequency of assessments. For example, if the following marks were given to the word "house": 1 (very good) - 35 people, 2 (good) - 10 people, 3 (neutral) -3 people, 4 (bad) - 2 people, 5 (very bad) - 0 people. We calculate the average - 1 * 35 + 2 * 10 + 3 * 3 + 4 * 2 + 5 * 0 = 72; 72/50 = 1.44; 1.44 - halo of the word "house". We measured halos of other words and put them on the scale. Different words took a different position on the scale. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
A total of about 75 scales were tested. They were called the Osgood scales. Of the 75 - three were found to be basic. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Sometimes, another scale of rhodocomfort is distinguished (female - male, round - angular, delicate - rough, etc.). |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
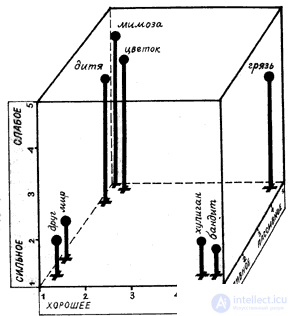
Three base scales were set aside in space - we got Osgood's cube. Any word has its own point in the Osgood cube. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
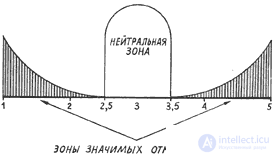
But some concepts may spread, have some area - for example, "rain". |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
In the 1960s, Yu. Orlov suggested that there is a correspondence between sound and meaning. Sounds are measurable on the Osgood scale. o - light; r-awesome; k - fast; w - slow, etc. By the presence of sounds, you can calculate the word and determine its location in the Osgood cube. The following features should be taken into account: the word needs to be laid out on sounds, but not letters (for example, Akno, yablako); it is required to distinguish which sound goes beyond the subject; need to be adjusted for stress; the first sound is the most important; Frequent sounds are barely noticeable. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The estimates given by people and the estimates obtained during the analysis of the word coincided. You can understand the meaning of the word by its sound. This theory explains the origin of the language. Language arose as onomatopoeia (rustle, roar, squeak, rustling, alarm, snoring, babbling, explosion). |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Sound flowerStudies (statistical surveys) showed that the sounds have a color: a - deep red, e - green, a - red, and - blue, u - bluish, etc. This means that the texts have a coloring. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AOEI - supporting letters and main colors (like RGB components). |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
If correspondences of the sounds of speech to certain colors exist, even if in the subconscious, then they should appear somewhere, the sound color should somehow function in speech. And perhaps, first of all, you need to look for the manifestation of sound-colored halos in poetry: where the sound side is especially important. The effect of sound color can play its role in the case when a certain color picture is created in the poem, and the vowel pattern of the verse should support, this picture with the sounds of the corresponding color. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
If this is so, then it is natural to expect that when describing, for example, red objects and phenomena, the role of red A and Z will be emphasized in the text; они будут встречаться чаще, чем обычно, особенно в наиболее важных, наиболее заметных позициях (скажем, в ударных). Описание чего-либо синего будет сопровождаться нагнетением синих И, Ю, У; зеленого - нагнетением Е, Ё и т. д. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Стоило начать проверку этой гипотезы, как в сухих статистических подсчетах стала на глазах проявляться живая игра звукоцветовых ореолов поэтического языка, поражающая своей неожиданностью, своим разнообразием и точным соответствием понятийному смыслу и общему экспрессивно-образному строю произведений. Judge for yourself. У А. Блока есть стихотворение, которое он написал под впечатлением от картины В. Васнецова <Гамаюн, птица вещая>. Стихотворение о грозных пророчествах передает трагический колорит картины - мрачно-багровый цвет казней, пожаров, крови. А. БлокГамаюн, птица вещая
На гладях бесконечных вод, |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
В тексте стихотворения (включая заголовок) подсчитывается количество каждой из 10 звукобукв, перечисленных в таблице. Чтобы учесть особую роль ударных гласных, они при счете удваиваются. Так как Ё, Я, Ю, Й связываются лишь с оттенками основных цветов и еще потому, что встречаются они сравнительно редко, самостоятельного значения в звукоцветовой картине стиха они не имеют. Поэтому приплюсовываются к основным гласным. Поскольку звукобуква Ё оказалась двухцветной, то ее количество разделяется поровну между О и Е. Синева Й выражена слабо, поэтому количество Й сокращается наполовину и только затем приплюсовывается к И. Подсчитывается также количество всех букв с удвоением ударных (величина N ). |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Затем определяются доля (частотность) каждой гласной в тексте стихотворения ( Р к ) и единицы размаха колебаний этих частотностей для данного текста: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Полученные частотности сопоставляются с нормальными (среднестатистическими для языка), и вычисляются нормированные разности этих частотностей, чтобы установить, случайно или нет наблюдаемые в стихотворении частотности отличаются от нормальных и как именно отличаются. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Звукоцвет в стихотворении "Гамаюн, птица вещая"
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Как видим, звуков A и Я в обычной речи должно было бы встретиться 116 на тысячу, а в стихотворении их гораздо больше ( P k =0,159). При q =0,018 такое отклонение частотности (0,159 - 0,116 = 0,044 превышает случайное в 2,39 раза, то есть едва ли может быть случайным. Значит, поэт интуитивно нагнетал красные А и Я, чаще обеспечивая им ударные позиции (вещАет кАзней рЯд кровАвых). Вторым по превышению нормы идет Ы, придавая красному тону мрачное, трагическое звучание. Наконец, У (также с превышением частотности над нормой) добавляет звукоцветовой картине темные сине-зеленые и лиловые оттенки. Частотность всех остальных гласных ниже нормы. Если теперь изобразить в цвете игру доминирующих в стихотворении гласных, то получится картина в красно-багровой и черно-синей гамме, кое-где с темной прозеленью. А это и есть цветовая гамма картин Васнецова. Остается только поражаться, насколько точно талант поэта подсказал ему выбор и пропорции доминантных звукобукв. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Таким способом на компьютере "просчитано" много стихотворений. Для некоторых из них в общей табличке приведены итоговые величины ( Z ), чтобы можно было убедиться, что обнаруженные звукоцветовые соответствия - не парадокс статистики, не случайное совпадение цифр. Значимые превышения частотностей отмечены в табличке полужирным шрифтом. В последнем, восьмом столбце дана цветовая расшифровка полученных результатов. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
eight
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Studies have shown that the newspaper text, the text of instructions is gray, not pronounced, and conspiracies, songs, prayers are brightly colored. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The color of the work may change as the plot changes. Therefore, it is necessary to evaluate not the entire work, but in parts. A mixture of paint parts may give an unreasonably gray color. It is noticed that the more ingenious the poet, the more clearly the coloring of the work is expressed. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
One message in different languages has a similar color. This explains the unity of origin of languages. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Swadesh formulaFor mathematics experts, we present a formula that determines the divergence time in glottochronology:C (A, B) = r t , whence t (A, B) = log C (A, B): log r, where t is the time in millennia, the age of divergence between languages A and B; C - the share of common for languages A and B words from Swodesh’s 100-word list (from 0 to 1); r is the index of preservation of the basic dictionary for one millennium (for a 100-word list, r = 0.86, log r = -0.0655). |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
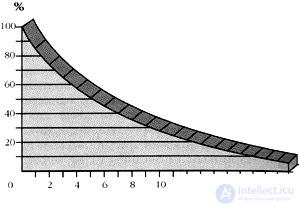
It can be calculated that if, for example, only seven of the basic 100 words do not match, the languages separated about 500 years ago; if 26 - then the separation occurred about 2 thousand years ago, and if only 22 words out of 100 coincide, then 10 thousand years ago, etc. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The graph shows how, according to Swadesh, the percentage of matching words depends on the time (t) when the languages have spread. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Language tree |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Suggestive LinguisticsWith the help of sound messages you can control a person. Widely used in religion and advertising campaigns. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The mechanism is as follows - the sound has a color, the color affects emotions, strong emotions provoke actions. It is known that words affect the brain, the nervous system. It is not surprising that toothache can be "talked about", since pain is the excitation of a certain part of the brain. With the help of words, you can change the picture of foci of excitation in the brain. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Suggestive linguistics is a conscious entrance to the subconscious, a purposeful influence on the subconscious. We can speak of suggestive linguistics as suggestion, i.e. as a verbal impact, perceived without criticism (as opposed to persuasion). |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Many researchers have analyzed text indicators to identify patterns - what exactly acts on a person as a suggestion. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Lexico - stylistic indicatorsN is the number of lexical units in the text;L is the number of words in the text that have occurred in the text at least once; Lf 1 - words that met only once in T; Lf k - the number of words that are in T with a frequency of> 1. Lr 1 - the maximum frequency of the word. 1. C - distribution index (the more this value is, the richer the dictionary); C = (f r1 2 + L 2 ) 1/2 2. I i - the iteration index (the index of the repetition of words in the closed text); I i = n: l 3. I e - the index of exclusivity (specificity) of vocabulary; I e = 20 * Lf 1 : N 4. P - predictability index (the less P, the more attractive the text); P = 100 - (Lf 1 * 100): N 5. I q - text density index. It is proportional to the number of repeated words in T and the length of T. (the richer the subject, the higher I q , the more uniform the subject, the I q lower ); 6. I ext - the volume of extensiveness of the dictionary. Proportional to the breadth of vocabulary, diversity of expression. 7. I f - stereotype index. The length of the interval of the middle part of the repeated words. If I f is more, then the main thing is not the form, but the content (for fluent reading, non-stylized, spontaneous speech). I f less in artistic texts, fiction. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
With a positive installation, the length and depth of sentences, the number of complex sentences is greater than with a negative installation. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Conspiracy rates |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
An example of conspiracy "on blood": "There was a woman on the river, she led the bull on a string, the thread broke, blood was carried away. I will become a servant of God for arable land, my blood will not drip, I will become a brick, blood will be jammed. Fasten my words with twelve keys, strong locks. Amen. " |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Prayer rates |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Color - blue (azure, sky - in the pictures). Highs more. The word length is longer. Index prayers are close to conspiracies (genetic proximity). |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
An example of a prayer: "Our Father, behold the Spirit in Heaven! Hallowed be Your name, Thy kingdom come, Thy will be done, as in heaven and on earth. Give daily bread to us, as we leave our debtor, and do not lead us into temptation, but deliver us from the onion. " |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

Comments
To leave a comment
Artificial Intelligence
Terms: Artificial Intelligence