Lecture
Testing is the process of executing a program to detect errors.
Testing is one of the most labor-intensive stages of creating a software product (from 30% to 60% of the total labor input). Moreover, the proportion of the cost of testing in the total cost of development tends to increase with increasing complexity of program complexes and increasing requirements for their quality.
It is necessary to distinguish between testing and debugging. Testing is the process of detecting failures due to errors in programs. Debugging is the process of identifying sources of failure, i.e. mistakes, and making relevant changes to the program.
Testing helps improve the quality of a software product by helping to identify problems early in the development process. No testing can prove the absence of errors in the program.
The initial data for testing are the specification, specification and structural and functional schemes of the software product developed at the previous stages.
To complete a program check, you need to perform testing. It requires you to check all the sets of source data and all options for their processing. In most cases this is not possible.
When testing it is recommended to observe the basic principles:
1. You can not plan testing on the assumption that errors will not be detected.
2. A test that has a high probability of detecting an unrevealed error is considered good . Successful is the test that detects an error that has not yet been identified .
Let's draw an analogy with visiting a sick doctor. If a laboratory study recommended by a doctor did not find the cause of the disease, then such a study is unsuccessful: the patient has spent money and time, and he is still sick. If the study showed that the patient has a stomach ulcer, then it is successful, because the doctor can prescribe the necessary course of treatment. The analogy here is that the program to be tested is similar to a sick patient.
3. Expected results must be known before testing.
Violation of this principle is one of the most common mistakes. Erroneous, but plausible results can be considered correct if the test results have not been previously determined. Therefore, the test should include two components: a description of the input data and a description of the exact and correct result corresponding to the set of input data.
4. Avoid testing the program by its author.
Most programmers can not effectively test their programs, because it is difficult for them to demonstrate their own mistakes. In addition, the program may contain errors associated with an incorrect understanding of the formulation or description of the problem by the programmer. Then the programmer will start testing with the same misunderstanding of his task.
It does not follow from this that a programmer cannot test his program. Many programmers quite successfully cope with this. But testing is more effective if performed by someone else. This does not apply to debugging, i.e., to the correction of already known errors. Debugging is more efficiently performed by the author of the program.
5. It is necessary to thoroughly study the results of applying each test.
This is the most obvious principle, but due attention is often not given to it. Errors should be detected as a result of a thorough analysis of the results of test runs.
6. It is necessary to check the program for incorrect data. Tests for incorrect and unforeseen input data should be designed as carefully as for the correct and provided.
When testing programs, there is a tendency to focus on the correct and stipulated input conditions, and to ignore incorrect and unforeseen input data. Many errors can be detected if the program is used in a new, not previously provided way. It is likely that tests that represent incorrect input data have a greater detecting power than tests that correspond to the correct input data.
7. It is necessary to check the program for unexpected side effects.
That is, it is necessary to check not only whether the program does what it is intended for, but also whether it does what it should not do.
This logically simply follows from the previous principle. For example, a payroll program that makes the correct payment checks will be wrong if it produces extra checks for workers or twice writes the first entry to the list of personnel.
8. The probability of undetected errors in a part of a program is proportional to the number of errors already found in this part.
This can be explained by the fact that errors can be grouped into parts of the program developed by low-skilled programmers or poorly developed ideologically.
This principle allows you to enter feedback into the testing process. If in any part of the program more errors are detected than in others, then additional efforts should be directed at testing it.
There are 2 main strategies for testing structural programs:
structural testing or “white box testing”;
functional testing or black box testing
The “ white box ” strategy , or the testing strategy managed by the program logic , or structural testing , allows you to explore the internal structure of the program, which in this case is known (Fig. 3.2).
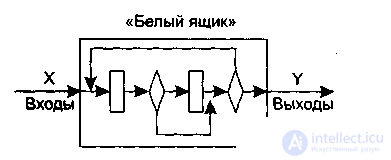
Figure 3.2. - Testing the "white box"
Test data is obtained by analyzing the program logic. The correctness of the construction of all program elements and the correctness of their interaction with each other is checked.
White-box testing is characterized by the degree to which tests perform or cover the logic (source code) of a program.
Coverage is a measure of the completeness of using the capabilities of a program by a set of tests.
A program is considered to be fully verified, if using tests it is possible to execute this program along all possible routes for its execution, i.e. perform comprehensive testing of routes . For this, test variants are formed in which:
guaranteed check of all independent routes of the program;
branches of "truth" and "false" for all logical decisions;
all cycles are performed within their boundaries and ranges;
analyzes the correctness of internal data structures.
Disadvantages of the white box testing:
The number of independent routes can be very large. For example, if a cycle in the program is executed k times, and there are n branches within the loop, then the number of routes is calculated using the formula
With n = 5 and k = 20, the number of routes is m = 1014. We assume that 1 ms is spent on developing, executing and evaluating a test on one route. Then, when working 24 hours a day, 365 days a year, it will take 3170 years for testing.
Therefore, exhaustive testing is impossible in most cases.
Even an exhaustive number of routes does not guarantee the compliance of the program with the original requirements for it.
Some routes may be skipped in the program.
The method does not detect errors, the appearance of which depends on the data being processed.
The advantages of testing the "white box" is that this strategy allows you to take into account the features of software errors:
When encoding a program, syntax and semantic errors are possible;
The number of errors is minimal in the "center" and maximum in the "periphery" of the program;
Preliminary assumptions about the likelihood of a control flow or data in a program are often incorrect. As a result, a route can become typical, for which the computation model for which is poorly developed.
Some results in the program depend not on the initial data, but on the internal states of the program.
Each of these reasons is an argument for testing on the "white box" principle. Black Box tests cannot respond to these types of errors.
Functional testing or testing with data management , or testing with input-output control . When using this strategy, the program is considered as a black box, i.e. its internal structure is unknown (Fig. 3.3). Such testing is intended to clarify the circumstances in which the behavior of the program does not meet its specifications. The execution of each function of the program is checked over the entire domain.

Figure 3.3. - Testing the "black box"
In order to detect all errors in the program, it is necessary to perform exhaustive testing, i.e. testing on all possible sets of input data. As a rule, it is impossible. For example, if the program has 10 input values and each can take 10 values, then 1010 test cases will be required.
The black box principle is not an alternative to the white box principle; it detects other classes of errors. Functional testing does not respond to many software errors.
Testing the “black box” allows you to find the following categories of errors:
Structural Testing Methods
The structured testing strategy includes several testing methods:
Coverage is a measure of the completeness of the use of the program component’s capabilities by the test suite.
The operator coverage method uses the operator coverage criterion, which involves executing each program statement at least once. This is a weak criterion, so how to perform each operator once is a necessary but not sufficient condition for acceptable testing on the white box principle.
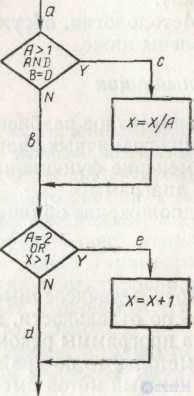
Figure 3.4 - Block diagram of a small program that needs to be tested.
Consider an example. In fig. 3.4 is a block diagram of a small program that needs to be tested.
An equivalent program written in C ++ has the form:
Void m (const float A, const float B, float X)
{if (A> 1) && Bb == 0)
X = X / A;
If ( A == 2) ïï ( X > 1)
X = X +1}
You can run each operator by writing a single test that would implement the ace path . That is, if the values A = 2 , B = 0 and X = 3 were set at point a, each statement would be executed once (in fact, X can take any value).
This criterion is not sufficient, since when using it, some possible errors will not be detected.
If, when writing a program in the first condition, write A > 1 || B = 0 , the error will not be detected.
If in the second condition instead of X > 1 X > 0 is written, then the error will not be detected.
There is an abd path in which X does not change at all. If there is an error, then it will not be detected.
Thus, the operator coverage criterion is so weak that it is used extremely rarely.
A stronger criterion for covering the logic of a program is the criterion for covering decisions . The solution is a logical function preceding the operator (A > 1 && B = 0 is the solution). To implement this criterion, such a number of tests is necessary so that each decision on these tests takes the value “true” or “false” at least once. In other words, each transition direction must be implemented at least once.
Solution coverage usually satisfies the operator coverage criterion. Since each operator lies on a certain path, outgoing either from the transition operator or from the program entry point, each operator must be executed at each transition direction.
In the program presented in Fig. 3.4, solution coverage can be performed by two tests covering either the ace and abd paths or the acd paths and a b e .
If we choose the second floor, then the inputs of the two tests are:
A = 3, B = 0, X = 3
A = 2, B = 1, X = 1
Decision coverage is a stronger criterion than operator coverage, but it also has its drawbacks. For example, the path where X does not change (if ace and abd is selected) will be tested with a 50% probability. If there is an error in the second solution (for example, X <1 instead of X > 1 ), then the error will not be detected by the two tests in the previous example.
Condition coverage method
The best criterion in comparison with the previous one; is covering conditions. In this case, such a number of tests is recorded so that all possible results of each condition in the solution are performed at least once. Since this coverage does not always lead to the fulfillment of each operator, an additional criterion is required, which consists in the fact that each entry point into the program must be transferred at least once.
The given program has 4 conditions:
A > 1, B = 0, A = 2, X > 1
You need so many tests to implement the situation:
A > 1, A <= 1; B = 0, B ! = 0 at a ;
A == 2, A ! = 2; X > 1, X <= 1 at point b .
Tests satisfying this condition:
A = 2, B = 0, X = 4 ( ace )
A = 1, B = 1, X = 1 ( abd )
Although a similar number of tests for this example has already been created, coverage of conditions is usually better than solution coverage, since it can (but not always) cause solutions to be executed under conditions that are not implemented with solution coverage.
Applying the criterion for covering conditions at first glance satisfies the criterion for covering solutions, this is not always the case. The conditional coverage tests for our example cover the results of all decisions, but this is only a coincidence. For example, two alternative test
A = 1, B = 0, X = 3
A = 2, B = 1, X = 1
cover the results of all conditions, but only two of the four results of the decisions (they both cover the abe path and, therefore, do not fulfill the result of the “truth” of the first solution and the result of the “false ” of the second solution).
Solution / Condition Coverage Method
The solution to the above problem is to cover the solutions / conditions. It requires so many tests that all possible results of each condition in the solution are executed at least once, all results of each solution are executed at least once, and control is transferred to each entry point at least once.
The disadvantage of the solution / condition coverage criterion is the impossibility of its application to fulfill all the results of all conditions. This may be due to the fact that certain conditions are hidden by other conditions.
Combinatorial coverage method
The criterion that solves these and some other problems is the criterion of combinatorial coverage of conditions . It requires the creation of so many tests so that all possible combinations of the results of the conditions in each solution and all the entry points are performed at least once.
According to this criterion in the program fig. 3.4. The following eight combinations should be covered with tests:
1 . A> 1, B = 0;
2. A> 1, B! = 0 ;
3. A <= 1, B = 0 ;
4. A <= 1, B! = 0 ;
5. A = 2, X> 1 ;
6. A = 2, X <= 1 ;
7. A ! = 2, X > 1 ;
8. A ! = 2, X <= 1 .
In order to test these combinations, it is not necessary to use all eight tests. In fact, they can be covered by four tests. We give the input values of the tests and combinations that they cover:
1. A = 2, B = 0, X = 4 K: 1, 5 2. A = 2, B = 1, X = 1 K: 2, 6
3. A = 1, B = 0, X = 2 K: 3, 7 4. A = 1, B = 1, X = 1 K: 4, 8
That four tests correspond to four different paths in Fig. 3.4 is a coincidence. In fact, the tests presented above do not cover all paths; they skip the acd path .
Thus, for programs containing only one condition for each solution, the criterion is minimal, whose test suite
causes all the results of each solution to be executed at least once,
transfers control to each entry point at least once (to ensure that each program statement is executed at least once).
For programs containing solutions that each have more than one condition, the minimum criterion consists of a set of tests.
causing all possible combinations of the results of the conditions in each solution,
transmitting control to each program entry point at least once. (The word “possible” is used because some combination of conditions may not be feasible; for example, it is impossible to set K for combinations K <0 , K> 40. )
The base path testing method provides an estimate of the overall program complexity and uses this estimate to determine the required number of tests (test cases).
Test cases are developed for a basic set of paths (routes) in the program. They guarantee that each program statement is executed once.
With this testing method, the program is represented as a flow graph. A flow graph is a set of nodes (or vertices) and arcs (directed edges).
Nodes correspond to linear sections of the program; they include one or more program statements.
Closing parentheses of conditional statements and loop statements are treated as separate statements.
Arcs represent the flow of control in the program (control transfers between statements).
A distinction is made between statement and predicate nodes. A statement node has one arc, while a predicate node has two.
Predicate nodes correspond to simple conditions in the program. Compound conditions are mapped to multiple predicate nodes. (Compound conditions are conditions that use 1 or more Boolean operations (OR, AND)). For example, a program fragment
if a or b
then X
else Y
end if
instead of being directly mapped into a flow graph of the type shown in Fig. 3.5, it is mapped into a transformed flow graph (Fig. 3.6).
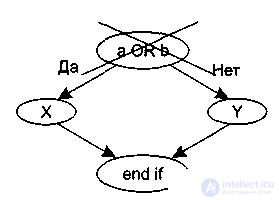
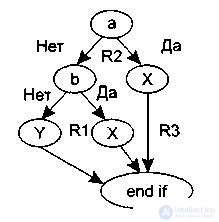
Figure 3.5. – Direct mapping to a flow graph. Figure 3.6. – Transformed flow graph.
6. Enclosed regions formed by arcs and nodes are called regions.
7. The environment surrounding the graph is considered an additional region (Figure 3.6).
To construct a flow graph, program text statements are numbered, then the numbered text is mapped to nodes and arcs of the graph according to the rules described above. Using the constructed graph, independent paths are identified. Each path (route) begins at a start node and ends at a stop node. A path that introduces a new processing statement or a new condition is called independent . That is, an independent path must contain an arc that is not included in any previously defined paths. The set of independent paths in the graph forms the basic path set.
The basic path set has a cardinality equal to the cyclomatic complexity of the flow graph. Cyclomatic complexity is a software metric that quantifies the logical complexity of a program. It determines the number of independent paths in the program's base set and an upper bound on the number of tests required to guarantee that all program statements are executed exactly once.
Cyclomatic complexity is calculated in one of three ways:
Cyclomatic complexity is equal to the number of regions in the flow graph;
By the formula V = E – N + 2,
where V is the cyclomatic complexity,
E is the number of graph arcs,
N is the number of graph nodes.
3. By the formula V = p + 1, where p is the number of predicate nodes in the graph.
By calculating cyclomatic complexity, one can determine the number of independent paths to search for in the graph.
Example.
Let's consider the compression procedure:
Compression procedure
1. Execute until EOF
one. Read the record;
2. If the record is empty
3. Delete the record:
four. Otherwise, if field a >= field b
five. Delete b;
6. Otherwise, delete a;
7a. End if;
7a. End if;
7b. End execute;
8. End compression;
It is mapped to the flow graph shown in Figure 3.7.
This flow graph has four regions. Therefore, four independent routes need to be defined. Typically, independent routes are formed in order from shortest to longest.
Let's list the independent paths for this flow graph:
path 1: 1 — 8.
path 2: 1 – 2 – 3 — 7а — 7b – 1 — 8.
path 3: 1 – 2 – 4 – 5 — 7а — 7b – 1 — 8.
path 4: 1 – 2 – 4 – 6 — 7а — 7b – 1 — 8.
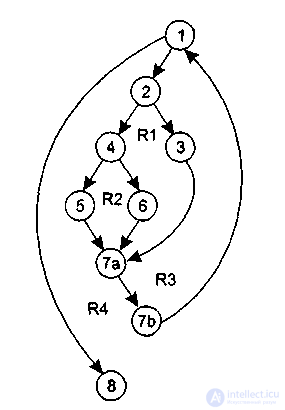
Figure 3.7. — Example of a flow graph
Basic path testing sequence.
A flow graph is generated based on the program text.
The cyclomatic complexity is determined (for each of the three formulas).
A basic set of independent paths is defined.
Tests are prepared to initiate the execution of each path. The test includes the initial data and expected results. The initial data is selected such that the predicate nodes ensure the required switches, i.e., the operators listed in a specific path are executed in the required order.
The actual results of each test are compared with the expected results.
The functional testing strategy includes the following testing methods:
Equivalent Partitioning Method;
Boundary Value Analysis Method;
Cause-Effect Analysis Method;
Error Guessing Method.
In this method, the program's input data domain is divided into equivalence classes.
An equivalence class is a set of data with common properties. An equivalence class includes a set of data values that are valid or invalid based on the input conditions. When processing different elements of the class, the program must behave identically, so one test case is developed for each equivalence class.
Equivalence classes can be defined in the program specification. For example, if a specification specifies 5-digit integers in the range 15,000 to 70,000 as valid input values, then the equivalence class of valid input data (the correct equivalence class) includes values from 15,000 to 70,000, and the two equivalence classes of invalid input data (the incorrect equivalence classes) are:
numbers less than 15,000;
numbers greater than 70,000.
Rules for forming equivalence classes.
If the input condition specifies the range n…m, then the following are determined:
one correct equivalence class: n ≤ x ≤ m
and two incorrect equivalence classes: x < n;
x > m.
2. If the input condition specifies a specific value a, then
one correct equivalence class is determined: x = a;
and two invalid equivalence classes: x < a;
x > a.
3. If the input condition specifies the value set {a, b, c}, then
one valid equivalence class is determined: x = a, x = b, x = c;
and one invalid equivalence class is determined:
(x a)&(x b)&(x c).
4. If the input condition specifies a Boolean value, such as true, then
one valid equivalence class {true}
and one invalid equivalence class {false} are determined.
After constructing the equivalence classes, test cases are developed. This process involves the following steps:
Each equivalence class is assigned a unique number,
Tests are designed, each covering as many uncovered correct equivalence classes as possible,
until all correct equivalence classes are covered by tests,
Tests are written, each covering one and only one of the uncovered incorrect equivalence classes, until all incorrect classes are covered by tests.
A disadvantage of the equivalence partitioning method is that it does not explore combinations of input conditions.
As a rule, most errors occur at the boundaries of the input domain, not in the center. Boundary value analysis involves generating test cases that analyze the boundary values. This testing method complements the equivalence partitioning method.
Let's formulate the rules for boundary value analysis.
1. If the input condition specifies a range of n…m, then test cases should be constructed:
for values n and m;
for values slightly to the left of n and slightly to the right of m on the number line.
For example, if the input range is -1.0…+1.0, then tests are created for the values -1.0, +1.0, -1.001, +1.001.
2. If the input condition specifies a discrete set of values, then test cases are created:
to test the minimum and maximum of the values;
for values slightly less than the minimum and slightly greater than the maximum.
Thus, if the input file can contain from 1 to 255 records, then tests are created for 0, 1, 255, and 256 records.
3. Rules 1 and 2 apply to output scope conditions.
Let's consider an example where a program needs to output a table of values. The number of rows and columns in the table varies. A test case for the minimum output is specified, as well as a test case for the maximum output (based on the table size).
4. If the program's internal data structures have prescribed boundaries, then test cases are developed that test these structures at their boundaries.
5. If the program's input or output data are ordered sets (e.g., a sequential file or table), then the processing of the first and last elements of these sets should be tested.
Most developers use this method intuitively. By applying the described rules, bounds testing will be more comprehensive, thereby increasing the likelihood of detecting errors.
An example of applying equivalence partitioning and boundary value analysis methods. We need to test a binary search program. The program's specification is known. The search is performed on an array of elements M, returning the index I of the array element whose value matches the search key Key .
Preconditions:
1) the array must be sorted;
2) the array must have at least one element;
3) the lower bound of the array (index) must be less than or equal to its upper bound.
Postconditions:
1) if the element is found, the Result flag is True, and the value I is the element's number;
2) if the element is not found, the Result flag is False, and the value I is undefined.
To form equivalence classes (and their boundaries), we need to construct a partition tree. The leaves of the partition tree will yield the desired equivalence classes. Let's define a partitioning strategy. At the first level, we will analyze the feasibility of the preconditions, and at the second level, the feasibility of the postconditions. At the third level, specific requirements derived from developer practice can be analyzed. In our example, we know that the input array must be ordered. Processing ordered sets of even and odd numbers of elements can be handled differently. Furthermore, it is common to distinguish a special case of a single-element array. Therefore, at the specific requirements level, the following equivalent partitionings are possible:
1) an array of a single element;
2) an array of an even number of elements;
3) an array of an odd number of elements greater than 1.
Finally, at the fourth, final level, the partitioning criterion can be an analysis of equivalence class boundaries. Obviously, the following options are possible:
1) working with the first element of the array;
2) working with the last element of the array;
3) working with an intermediate (neither the first nor the last) element of the array.
The structure of the partitioning tree is shown in Figure 3.8.
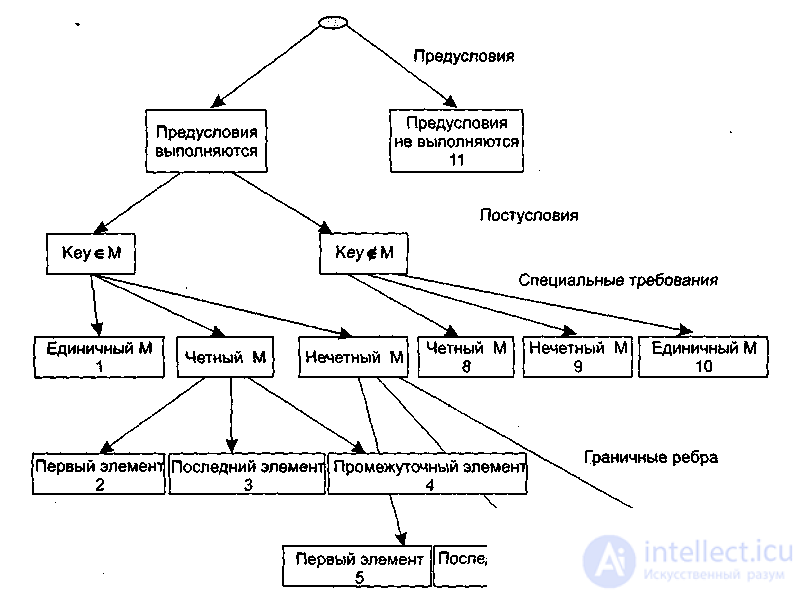
Figure 3.8. — Binary Search Source Data Partition Tree
This tree has 11 leaves. Each leaf defines a separate test case. We'll show the test cases based on the partitions performed (SD — source data, ER — expected result).
Test Case 1 (single array, element found) TB1:
SD : М=15; Кеу=15.
ER .: Resutt=True; I=1.
Test Case 2(even array, 1st element found)ТВ2:
SD : М=15, 20, 25,30,35,40; Кеу=15.
ER .: Result=True; I=1.
Test Case 3 (even array, last element found) ТВЗ:
SD : М=15, 20, 25, 30, 35, 40; Кеу=40.
ER :. Result=True; I=6.
Test Case 4 (even array, intermediate element found) ТВ4:
SD : М=15,20,25,30,35,40; Кеу=25.
ER .: Result-True; I=3.
Test Case 5 (odd array, 1st element found) ТВ5:
SD : М=15, 20, 25, 30, 35,40, 45; Кеу=15.
ER .: Result=True; I=1.
Test Case 6(odd array, last element found)ТВ6:
SD : М=15, 20, 25, 30,35, 40,45; Кеу=45.
ER .: Result=True; I=7.
Test Case 7(odd array, intermediate element found)ТВ7:
SD : М=15, 20, 25, 30,35, 40, 45; Кеу=30.
ER .: Result=True; I=4.
Test Case 8 (even array, element not found)ТВ8:
SD : М=15, 20, 25, 30, 35,40; Кеу=23.
Coolant . CUT : Result = False; I =?
Test version 9 (odd array, element not found) TV9;
SD : M = 15, 20, 25, 30, 35, 40, 45; Keu = 24.
ER : Result = False; I =?
Test version 10 (single array, element not found) TV10:
SD : M = 15; Keu = 0.
Coolant . CUT : Result = False; I =?
Test version 11 (preconditions violated) TV11:
SD : M = 15, 10, 5, 25, 20, 40, 35; Keu = 35.
OK CUT: Alarm Report: Array is not ordered.
The method of analysis of cause-effect relationships (APSS) allows you to systematically select highly effective tests.
The construction of tests is carried out in several stages.
When applying the method to large specifications, the specification is broken into work areas, because otherwise, the MSS tables will be very cumbersome (for example, when testing the compiler, you can consider individual language operators as a working area).
The specification defines many causes and many links. The reason is a separate input condition or a class of equivalent input conditions. The consequence is an output condition. Each cause and effect is assigned a separate number.
Based on the analysis of the semantic content of the specification, a truth table is constructed in which all possible combinations of causes are sequentially searched and the consequences of each combination of causes are determined. The table is provided with notes specifying constraints and describing combinations of causes and / or effects that are impossible due to syntax or external constraints. Similarly, a table is constructed for equivalence classes. When building a table, it is recommended to use the following techniques:
Each row of the truth table is converted to a test. It is necessary to try to combine tests from independent tables.
A person with practical experience often unconsciously applies a test design method called an error assumption. If there is a certain program, it intuitively assumes probable types of errors and then develops tests to detect them.
The procedure for the error assumption method is difficult to describe, since it is largely intuitive. The main idea of it is to list in a list of possible errors or situations in which they may appear, and then based on this list, write tests. For example, this situation occurs when the value 0 at the input and output of the program. Consequently, it is possible to build tests for which certain input data have zero values and for which certain output data is set to 0. With a variable number of inputs or outputs (for example, the number of the required input records when searching in the list) errors are possible in situations such as "no" and “One” (for example, an empty list, a list containing only one search entry). Another idea is to define tests related to assumptions that a programmer can make while reading a specification (i.e., moments that were omitted from the specification by chance or because the specification author considered them obvious).
Since this procedure cannot be clearly defined, the best way to discuss the meaning of the method of assuming an error is to look at examples. Consider testing a sorting program as an example. In this case, you need to investigate the following situations:
In other words, it is required to list those special cases that may not be taken into account when designing a program.
The testing process combines various testing methods into a planned sequence of steps that lead to the successful construction of a software system. The PS testing technique can be presented in the form of an unrolling helix (Fig. 3.9).
At the beginning, testing of elements (modules) is performed , verifying the results of the PS coding phase. In the second step, integration testing is performed that focuses on identifying errors in the PS design phase. On the third turn of the helix, a correctness test is performed , verifying the correctness of the stage of analysis of requirements to the PS. At the final turn of the helix, system testing is carried out to identify defects in the PS system analysis stage.
We characterize each step of the testing process.
1. Testing items . The goal is an individual check of each module. Used methods of testing the "white box".

Figure 3.9. - Spiral testing process PS
2. Integration testing . The goal is to test the assembly of modules into a software system. Mostly used black box testing methods.
3. Testing correctness . The goal is to test the implementation of all functional and behavioral requirements in the software system, as well as efficiency requirements. Used exclusively testing methods "black box".
4. System testing. The goal is to verify the correctness of the combination and interaction of all elements of the computer system, the implementation of all system functions.
The organization of the testing process in the form of an evolutionary unfolding helix ensures maximum efficiency in the search for errors.
RUP regulates and describes many different types of tests that focus on various design issues.
Consider the main types of tests for RUP:
These types of tests will allow for comprehensive testing of the software product. RUP regulates all types of work, including the methodology for the preparation of test kits. It regulates such parameters as: purpose of testing, testing methodology, testing criteria, and also determines the specific conditions necessary for conducting comprehensive testing.
Let us consider in detail the main types of tests, additional testing conditions, test requirements and completion criteria.
The purpose of testing: to be in the proper functioning of the test object. The correctness of navigation through the object is tested, as well as input, processing and output of data.
Functional testing of the facility is planned and carried out on the basis of the requirements specified at the stage of determining the requirements. Requirements are use case diagrams, business functions and business rules. The purpose of functional tests is to verify that the developed components comply with the established requirements.
The basis of functional testing is the black box testing strategy. If necessary, at the stage of functional testing, you can use the strategy of testing the "white box". At this stage, the testing of the “white box” is not applied in its pure form - a combination of two types of testing is used.
Objective : to ensure the reliability of database access methods, in their proper execution, without violating the integrity of the data.
It is necessary to consistently try the maximum possible number of ways to access the database. Tests are made in such a way as to “load” the base with a sequence of both correct values and obviously false ones. Evaluate the correctness of the data and make sure that the database processes the incoming values correctly.
The purpose of testing: to check the correct functioning of the object of testing and related processes for compliance with the requirements of business models and schedules.
Testing business cycles should emulate actions performed in a project during a specific time interval. The period must be determined by a duration of one year. All events, actions and transactions that are expected to occur during this period with the application must be reproduced. Includes all daily, weekly, monthly cycles and events that are date sensitive.
The purpose of testing is to check the correctness of navigation on the test object (including interwindow transitions, transitions between fields, correct processing of the “enter” and “tab” keys, working with a mouse, functioning of accelerator keys and full compliance with industry standards);
Check objects and their characteristics (menus, dimensions, positions, states, input focus, etc.) for compliance with generally accepted standards for a graphical user interface.
Performance profiling is an estimate of the response time of an application or database, transaction speed, and other time-dependent parameters. The purpose of the profiling work is to make sure that the performance requirements of the application or database are met.
During performance profiling, functions of the performance of the test object are recorded depending on specific conditions (workload, hardware configuration, type of operating system).
The goal of testing is to check the performance behavior of the specified transactions or business functions during the expected load and the expected load in the worst case.
Used test kits designed for functional testing or testing business cycles. It is necessary to constantly modify data files to increase (complicate) the number of transactions.
Load testing is used to determine the behavior of the test object in varying workloads, to assess the ability of an object to function correctly in changing conditions. The purpose of load testing is to determine and ensure the correct operation of all system functions beyond the maximum workload. In addition, this type of testing provides an assessment of the characteristics of the test object (response time, transaction time, as well as any time sensitive operations)
Tests designed for functional testing or business cycle testing are used. It is necessary to change the composition of the data, their number and complexity to increase the response time.
Stress testing - a subtype of load testing, the purpose of which is to find errors that are caused by a shortage of resources (insufficient amount of free RAM or disk space, or insufficient network bandwidth). This type of testing will effectively catch errors that do not occur during normal, normal testing.
It is also convenient to use this type of testing to obtain information about peak loads, after which the application under test stops working (or does not work correctly)
Tests created for load testing and performance testing are used;
For effective testing, the testing machine must intentionally have a limited number of available resources.
The goal of volumetric testing is to find the limits of the size of the transmitted data. Volumetric testing also identifies a continuous maximum load or amount of information that can be processed in a given time interval (for example, a test object processes a set of records for generating a report, and volumetric testing will allow you to use large test databases and test how the program operates. whether she is the right message).
Verifies that the test object functions correctly in the following scenarios:
connected or simulated maximum number of clients;
long-term business functions are correctly executed;
the maximum database size is reached, and multiple queries and reports are executed simultaneously.
Tests created for load testing and performance testing are used;
Simulates the maximum number of clients to pass the worst scenario of the system;
It creates a maximum base and supports customer access to it for a long time.
This type of testing focuses on the performance of two key security levels:
security at the application level, access to data or business functions;
security at the system level, registration (authentication) or remote login;
Security at the application level should ensure that the actors are limited in certain functions or in the data available to them. For example, all users can perform operations to add data to the database, but only managers or administrators can delete them.
Security at the data level ensures that user number one can only see financial information about the client, and user number two, only demographic.
Security at the system level ensures that only those users who have access to it and only through appropriate gateways will gain access to the system.
The purpose of testing is: (application-level security) to verify that the user can access only those functions or data to which he has access.
(Security at the system level). Check that only those users who are logged in (application) are allowed to perform various operations.
The list of users and functions (or data) to which everyone has access, access is determined;
Tests are created for each user object access tests with validation of transactions;
Custom types are modified (constraint input) and re-passed through tests.
This type of testing is conducted to confirm that the application under test can be successfully restored with the same functionality after a hardware or software failure.
The data loss tolerance test should show that the test object is able to correctly recover lost data (for example, restore from a backup copy) if a loss occurred.
The hardware stability test should demonstrate that the test object successfully handles such errors as: an input / output error, system failures, and invalid system database pointers.
The goal of testing is to verify that the recovery processes (manual or automatic modes) properly restore the data, the application itself, and the system.
The following types of states should be taken into account when creating tests:
As soon as the above steps are completed, you need to call the procedure for restoring the object under test or wait for the automatic activation of the corresponding mechanisms.
A special type of testing aimed at checking the compatibility of the test object with various hardware and software.
Configuration testing is necessary to ensure compatibility of the test object with the highest possible equipment to ensure reliable operation. Also, configuration testing should take into account the type of operating system.
RUP has an extensive mechanism for planning and simultaneously running configuration tests on different platforms simultaneously.
The test should take into account such criteria as: installed software (and their versions), availability and versions of hardware drivers, availability of hardware (in arbitrary combinations).
The purpose of testing is to verify the object of testing for compatibility with the equipment, operating systems and third-party software products declared in the specification.
Used tests of functional testing. Before testing, open the maximum number of well-known applications. Тестирование проводится на разных платформах.
This is the last type of testing on the list, but the first function with which the user will begin familiarizing themselves with the software product.
This type of testing verifies the ability of the test object to install correctly and without failures on the user's computer, handling all possible exceptions (insufficient space, power failure).
Testing Goal: To ensure that the test object installs correctly on a system that meets all the hardware and software requirements specified in the installation instructions.
Particular attention is paid to the following types of installation:

Comments