Lecture
This lecture introduces the problem of the precise definition of a programming language 1 only to the extent necessary for an understanding of the subsequent analysis of languages and styles. This problem is multifaceted, and its more detailed consideration is given in another course.
To create, test and transform programs, build programming systems, and also for many other needs, we need, if not a definition, then at least a description of an algorithmic language. This requires accurate descriptions of both texts and their interpretation. Consider the existing options.
That is how they tried to act at the dawn of programming, when, say, the legendary FORTRAN language was created simultaneously with the first translator from this language.
The first option is a completely unsatisfactory way, since any change in the program-translator can completely change the meaning of some constructions of the language with all the ensuing consequences.
The second option corresponds to the view of the language as a set of correctly constructed sequences of characters. If the sequence of characters belongs to the language, then it is considered syntactically correct. For a program, this means that the autotranslator on it does not generate an error. But syntactic correctness does not guarantee even the meaningfulness of the program. Thus, only one side of the language is defined here.
The third option only works together with the second, because the structural units must be connected into a syntactically correct system. He reveals another side of the language.
Thus, we see that each language has three sides: syntax (second variant), semantics (third variant), pragmatics (first variant).
The syntax of an algorithmic language is a set of rules that allows:
The semantics of an algorithmic language is the correspondence between syntactically correct programs and actions of an abstract performer, which allows to determine which sequences of actions of an abstract performer will be correct if we have a given program and its external environment.
The external environment refers to the characteristics of the machine on which the program is executed (the accuracy of the data, the amount of memory, other programs that can be used to perform this, and so on), and the input data streams entering the program during its execution.
The pragmatics of an algorithmic language is what binds the program to its concrete implementation. In this case, in particular, the following occurs.
Pragmatics are sometimes prescribed by the standard language, sometimes not. It depends on the purpose for which the language and its implementation are intended.
Language description requires precise definition of syntax and semantics. In practice, however, the more accurately and better the language is described for constructing a translator, the more usually this description is more cumbersome and less understandable for an ordinary person, and therefore accurate descriptions do not exist for all real programming languages. Even if they are available, in the form of standards, which are addressed only in extreme cases.
Syntax is the simplest and most developed part of the description of an algorithmic language.
A grammar is defined by a system of syntactic rules (most often in language descriptions called simply rules ). At the grammar level, concepts are defined, the sequential opening of which, called inference , ultimately gives their presentation in the form of sequences of characters . Symbols are also called terminal concepts , and all other concepts are non-terminal. Concepts are semantic , that is, linguistic constructions for which one or another action of an abstract calculator is defined, and auxiliary ones , which are necessary only for constructing a text, but having no independent meaning. Minimal semantic concepts correspond to lexemes . Some concepts are introduced only in order to make the text readable for humans. The minimal ones (they are like punctuation marks) are naturally considered to be auxiliary lexemes .
But even the task of a complete syntax description is quite complex and requires the allocation of subtasks.
The syntax is divided into two parts:
The concept of context-free grammar became the first strict concept in the descriptions of practical algorithmic languages. For the concept of a COP grammar with its external simplicity is quite a serious theory. This grammar is represented in many forms (syntactic diagrams, metalus-language formulas of Backus-Naur or extended metalinguistic formulas) and, as a rule, accompanies the systematized presentation of a specific language. Each such specific representation of a QS grammar is fairly simple, and can be studied from any programming textbook.
Substantively, you can characterize the COP grammar of a language as that part of its syntax that ignores questions related to the dependence of the lexemes on descriptions of names in the program .
Contextual constraints narrow down the set of correct programs. For example, the rule “all identifiers must have descriptions in a program” indicates that a program with undescribed names does not belong to the given language (although it is valid from the point of view of context-free syntax).
Repeated attempts to formally describe contextual dependencies in defining languages have shown that this task is much more complicated than setting context-free syntax. On top of that, even such natural rules, as just introduced, with a formal description become cumbersome and very difficult to understand a person. For this reason, manuals rarely resort to the formalization of descriptions of contextual dependencies (Algol 68 is one of the few exceptions).
Example 4.2.1 . The requirement that each name should be described (in particular, in the languages of Pascal and C) is specified in the following form.
Such a set of requirements is sufficient for a person to check the program text, as this name is understood in this place 3 .
In practical descriptions of languages and in programming courses, they are usually content with an informal, but fairly accurate description of contextual dependencies. Let us give an example of such a description.
We have defined semantics as a correspondence between syntactically correct programs and abstract performer actions. But the question remains how to ask this correspondence. Semantics is most often defined by induction (recursion) by syntactic definitions.
The programmer’s goal is to get the effect he needs as a result of executing a program on specific hardware. But when composing a program, he thinks of the program as an abstract entity and most often does not want to know at all about the registers, the processor and other objects of the specific equipment. In accordance with the position of the programmer, the computing model of the programming language is natural to consider which abstract computer is defined by the language description. This position is also supported by the fact that translation and execution can be carried out on various specific calculators. Following this point of view, when we speak of a program model, we always mean its image in the form of commands of an abstract, rather than a specific, calculator.
The concept of a computational model of a language naturally extends to cases where program libraries are used. Libraries standardized by language description can be considered part of the language implementation, regardless of how library tools are implemented: in the language itself or not. In other words, library tools are additional commands for an abstract language calculator. Libraries that are independent of the language definition can be viewed as extensions of the language, that is, as the emergence of new languages that include the original language. And although there may be many such extensions, considering the computation model for a language together with its libraries is well in line with the style of thinking of the person constructing the program 4 .
The correspondence between the input data, the program and the actions given by semantics is, generally speaking, determined only by the full text of the program, including, in particular, all texts of the library modules used, but to understand the program and work on it, it is necessary that the syntactically complete program fragments can be interpreted autonomously from surrounding text. It should be noted that modern systems almost never meet this requirement. Too often, to understand the mistakes in the program, it is necessary to analyze the immense texts of the libraries.
Implemented language is always a pragmatic compromise between the abstract model of computing and the possibilities of its implementation.
So far, it has been about the definition of a language by its abstract calculator. Pragmatics sets the specification of an abstract calculator for this computing system. Most of the pragmatics are spread over the text of the documentation on the implementation of the language (the programmer cannot vary this part of the pragmatics). For example, it is pragmatic to note that the Longint type in a Visual C ++ system is defined as a 32-bit binary fixed-point number occupying a memory word.
That part of the pragmatics that a programmer can vary requires separate syntactic design. In Pascal, there are so-called pragmatic comments , for example, {$ I +}, {$ I-} (on / off I / O control). Many of these comments in almost all versions are the same. In the language standard itself, only their external form is explicitly prescribed: {$ ...}.
Even if the language is focused on implementation in a single operating environment (for example, it is some kind of scripting language for a microprocessor embedded in a dog collar), to understand the essence of what relates to actions, and what to optimize them, pragmatics should be distinguished at least in the documentation for programmers.
Two types of programming language pragmatics are fundamentally different: syntactic and semantic.
Syntactic pragmatics are the rules for shortening a record, one might say, cursive for a given language. An example that can be considered as syntactic pragmatics is the increase and decrease commands by one. In C / C ++, they are represented by operators.
++; or ++ ;
and
-; or - ;
In C / C ++, such commands should be attributed to the model of language computation, since it is postulated that the language is machine-oriented and reflects the architecture features of computing equipment, and the increase and decrease commands per unit are provided to the programmer at the equipment level quite often.
In Turbo Pascal and Object Pascal, these commands are expressed as follows:
Inc ()
and
Dec ()
respectively. If we consider Turbo Pascal as a correct extension of the standard Pascal language, which does not contain the commands under discussion, then these commands are just a hint to the translator how to program this calculation. Therefore, these operators for this language can be attributed to pragmatics 5 .
Another example is the possibility of writing in the Prolog language instead of calling + (X, Y) the expression X + Y.
Semantic pragmatics is the definition of what is left in the description of a language at the discretion of the implementation or is prescribed as computational options.
For example, the Pascal language standard states that when using a variable with an index at the level of calculations, the output of the index is controlled beyond the range of acceptable values. However, in object code, constant checks of this property may seem overhead and redundant (for example, when the program is written so well that the corresponding index values can be guaranteed). The language standard for such cases provides for an abbreviated, i.e. without checks, computation mode. The choice of modes is controlled by the user with the help of pragmatic instructions for the translator, expressed in a specific syntax as pragmatic comments {$ R +} and {$ R-} 6 .
Programming system developers should make special efforts to ensure that the pragmatic level is clearly highlighted. Without this, there may be a false idea of both the proposed computation model and its implementation. In addition, the programmer’s ability to apply abstraction methods is severely limited. We illustrate this.
Example 4.4.1 . The C language standard prescribes that programming systems on it should provide a special tool for processing program texts, which is called a preprocessor . The preprocessor makes a lot of useful transformations. As already mentioned, it takes upon itself the task of connecting external (library) files to the program, it can be used to hide tedious programming details, to achieve a number of necessary effects that are not provided for in the main language tools (for example, named constants). It is postulated that a C program is what is obtained after the preprocessor works with the text (of course, if the result of such work turns out to be correct). Therefore, the use of the preprocessor is a syntactic pragmatist of the language. But this is contrary to the practice of the programmer: he is simply unable to write a meaningful program that can be translated without using a preprocessor. The work of the preprocessor does not make it very difficult to understand the resulting program if, when programming in C, you are limited to using preprocessor commands to include definition files and define constants. But when, for example, conditional preprocessor constructions are used, the appearance of chimera programs is possible, the visually perceptible text of which is misinforming about their real structure.
Let it be written
if (x> 0) Firstmacro else PerformAction;
It seems that the action is performed if x 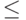 0, but the first macro is expanded as
0, but the first macro is expanded as
PrepareAction; if (x <= 0) CancelAction
Even the author of this program after a while will not understand why she behaves this way.
Strange as it may seem, such constructions are used in the practice of C programming: they are used to specify several variants of executable programs in one text, which are delimited by the work of the preprocessor, i.e. before execution.
Overlaying preprocessor commands on a program text is a mixture of two computational models: one of them is the model of the base language C, the other is the model of the preprocessor 7 . As a result, the programmer is forced to think at two levels at once while compiling and studying programs, and this is difficult and provokes errors.
From the very beginning, C and C ++ developers did not think about respecting conceptual integrity. This led to the fact that with the development of the language, it became increasingly eclectic.
Во многих языках, в частности в Object Pascal, для подобных целей используется более концептуально подходящее средство, так называемая условная компиляция . Суть его в том, что программисту дана возможность указать, что некоторый фрагмент компилируется, если при компиляции задан соответствующий параметр, и не компилируется в противном случае. При этом оказывается исключенной ситуация, приведенная в предыдущем примере, поскольку чаще всего способ задания фрагмента привязан к синтаксическим конструкциям языка (т. е.условную компиляцию можно задавать не для произвольных фрагментов, а лишь для тех, которые являются языковыми конструкциями). При условной компиляции проверяется корректность синтаксиса и, что не менее существенно, зримый образ программы явно отражает ее вариантность (именно это свойство нарушено в примере 4.4.1).
Even conceptually holistic systems often result in eclecticism as a result of development. In this regard, it is instructive to discuss the development of the Pascal language line Turbo.
Модель вычислений стандартного языка Pascal изначально была довольно целостна, поскольку в ней четко проводились несколько хорошо согласованных базовых идей и не было ничего лишнего. Но она не во всем удовлетворяла практических программистов. В языке Pascal, в частности, не было модульности, и требовалась значительно более глубокая проработка прагматики, что стало стимулом для развития языка, на которое повлияла конкретная реализация: последовательность версий Turbo Pascal. Разработчики данной линии смогли сохранить стиль исходного языка вплоть до версии 7, несмотря на значительные расширения. В этом им помогло появление нового языка Modula, построенного как развитие языка Pascal в направлении модульности. Идея модульности и многие конкретные черты ее реализации, созданные в Modula, были добавлены к языку Pascal.
Далее пришел черед модных средств ООП, которые также были интегрированы в язык с минимальным ущербом для его концептуальной целостности.
Таким образом, создатели линии Turbo Pascal успешно решили трудную задачу расширения языка при сохранении концептуального единства и отделения прагматики от развивающейся модели вычислений.
Однако со столь трудной проблемой не удалось справиться тем же разработчикам, когда они взялись за конструирование принципиально новой системы программирования Delphi и ее языка Object Pascal. Одним из многих отрицательных следствий явилась принципиальная неотделимость языка от системы программирования. А далее история Delphi с точностью до деталей повторяет то, что было с языком С/С++. В последовавших версиях системы, вынужденных поддерживать преемственность, все более переплетаются модель вычислений ипрагматика. Заметим, что "прагматизм" не принес никакого прагматического выигрыша: все равно Delphi плохо поддерживает современные системы middleware, ориентированные на C++ и Java.
Attention !
Есть большая опасность, связанная с добавлением новых возможностей к хорошей системе без глубокой концептуальной проработки. Сплошь и рядом то, что хорошо работало раньше, после таких модификаций перестает устойчиво работать.
При рассмотрении приемов программирования и примеров на разных языках необходимо как можно больше отвлекаться от частных особенностей и учиться видеть за ними общее с тем, чтобы оставшиеся различия были бы уже принципиальными. Отделить существенное от несущественного помогает, в частности, соотношение между синтаксисом и семантикой. Например, оказывается, что некоторые синтаксические особенности КС-грамматики языка не нужны для описания его семантики.
Обычное синтаксическое определение языка задает конкретные синтаксические правила построения программы как строки символов. При этом определяется, какие структурные элементы могут быть выделены в тексте программы (конкретное представление программы).
Действия абстрактного вычислителя определяются на структурном представлении программы и не зависят от многих особенностейконкретного синтаксиса. Например, для присваивания важно лишь то, что в нем есть получатель и источник, сам по себе знак присваивания ( =, := или, скажем, LET ) совершенно не важен. Более того, неважно, в каком порядке расположены составные части присваивания в тексте программы. Например, конструкция языка COBOL
MOVE X+Y TO Z
выражающая присваивание получателю Z значения выражения X+Y, совершенно аналогична обычному оператору присваивания.
In order to clearly distinguish a specific representation from an essential structure, it is worth considering a concrete and abstract syntax. For example, the abstract syntax of all the listed forms of an assignment operation is the same.
Similarly, the three operators
X = a * b + c * d; X = (a * b) + (c * d); (4.1) X = ((a * b) + (c * d));
and similar to them are completely equivalent from the point of view of abstract syntax, whereas from the point of view of textual representation they are different.
Таким образом, нужна структура синтаксических понятий, которая соответствует некоторому алгоритмически разрешимому 8 (см., напр. [ 20 ] ) понятию эквивалентности программ. Но это понятие эквивалентности должно быть исключительно простым, поскольку теоретические результаты показывают, что нетривиальные понятия эквивалентности программ неразрешимы. Выбранное понятие эквивалентности определяет структурное представление синтаксиса, используемого для задания абстрактного вычислителя ( абстрактно-синтаксическое представление ).
Фрагментом абстрактно-синтаксического представления является чаще всего применяемый на практике ход. Задают понятие синтаксической эквивалентности, которое очевидным образом согласуется с функциональной эквивалентностью. Так, например, предложения, перечисленные в примере 4.1, могут описываться следующим понятием синтаксической эквивалентности: скобки вокруг подвыражений, связанных операцией более высокого приоритета, чем операция, примененная к их результату, могут опускаться. В данном смыслеприсваивание рассматривается как операция, имеющая более низкий приоритет, чем любая из арифметических операций. Таким образом, например, определяется эквивалентность выражений в языке Prolog. Подвыражение X + 3, скажем, является в нем всего лишь другим вариантом записи для +(X,3), и при вычислении характеристик выражения оно прежде всего преобразуется в форму без знаков операций.
Еще одну возможность, открываемую переходом к абстрактно-синтаксическим определениям, можно увидеть, если определитьэквивалентность подвыражений для сложения и умножения

Здесь абстрактная эквивалентность выражает свойство самой операции. Опыт показывает, что дальше учета ассоциативности и коммутативности в абстрактном синтаксисе двигаться весьма опасно.
Пример на рис. 4.1 иллюстрирует вызов функции:
printf ("\nX1 = %f, X2 = %f\n", X1, X2);
Показанная на рисунке структура абстрактного синтаксиса данного оператора показывает, как можно ликвидировать привязку конструкции языка к конкретному синтаксису: остались только имя функции, строка и два параметра.
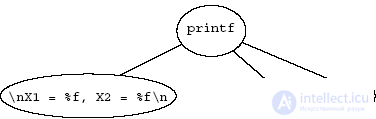
Рассмотрим более сложный пример, показывающий родство абстрактного синтаксиса традиционных языков. In fig. 4.2 shows the abstract representation of a text fragment of the following program:
. . .
if (D> 0)
{
D = sqrt (D);
Example 4.5.1. Text of some program

Comments
To leave a comment
Programming Styles and Techniques
Terms: Programming Styles and Techniques