Lecture
“Teacher,” said Sun Wu-kun. “I am a simple person and I don’t understand your city language.” What do the props to the wall mean?
“When people start building a house and want to make it strong and strong, they put supports between the walls.” But time passes, and the building collapses, which means that the props have rotted.
Wu Cheng-en. "Journey to the West," Chapter 2
In fact, the presentation of the structural style can not fit into the framework of one lecture. But this programming style (or rather, its version, based on cycles and arrays, slightly enriched with recursive procedures) is described and imposed as the only possible one in all currently offered textbooks on programming in traditional languages. In this regard, we have the right to assume that the student is familiar with him (moreover, he is familiar only with him, and we hope that he has not yet lost the ability to perceive other styles). And although you think that you have already become familiar with this version of the structural style, the features omitted in traditional expositions can completely change your view of this style.
We consider structured programming as an equal member of the community of alternative rival friends 1 .
* * *
Let's start with the fact that we turn to history.
In the theory of program schemes, it was noted that some cases of flowcharts are easier to analyze [16]. Therefore, it was natural to single out such a class of flowcharts, which the Italian scientists S. Bem and C. Djakopini did in 1966. They proved that any flowchart can be reduced to a structured form by using several additional Boolean variables. E. Dijkstra emphasized that programs in this form, as a rule, are easier to understand and modify, since each block has one input and one output.
As a method of structured programming, E. Dijkstra proposed using only the constructions of a cycle and a conditional operator, driving go to as conceptually contrary to this style.
Perhaps this is the first conceptual contradiction, clearly noted and taken into account in the theory and practice of programming (and even in the whole of modern science). But since there was not even a rough idea of the theory of non-formalizable concepts, and the experience of working with small formalizations was transferred to work with them, the structural contradiction was perceived as follows.
Unfortunately, the go to operator is formally compatible with other constructions of traditional (then they said, universal) algorithmic languages. But he really badly interacts with them. So he is bad in itself.
Structural programming is based mainly on the theoretical apparatus of the theory of recursive functions. The program is considered as a partially recursive operator [21] on library subroutines and source operations. Structural programming is also based on the theory of evidence, primarily on natural inference. The structure of the program corresponds to the structure of the simplest mathematical reasoning, which does not use complex lemmas and abstract concepts 2 .
Structured programming tools are primarily included in all traditional programming languages and in many non-traditional languages. They occupy the main place in educational programming courses and in theoretical works (for example, [1], [4], [9]).
With structured programming, assignments and local actions become an integral part of the program. It is enough to carefully monitor that each variable in the module is used for one specific purpose, and not to allow "economy", in which the unnecessary variable in this place is temporarily used for a completely different value. Such "savings" confuses the structure of information dependencies, which, with this style, should be well coordinated with the structure of the program.
Structural programming naturally arises in many classes of tasks, primarily in those where the task is naturally split into subtasks, and information into fairly independent data structures . Its main invariant is:
actions and conditions are local .
A necessary feature of a good implementation of a structured programming style is compliance with the consistency, and ideally and unity, of the following program components:
The structure of the information space . In essence, any task can be described as the processing of objects, the complete set of which is called the information space of the task.
The structured programming style requires the following. The task is divided into subtasks, and thus the tree of subtasks is built. The information space is structured in exact accordance with the nesting tree: for each subtask it consists of its local objects defined together with the subtask and for it, and so-called global objects defined as the information space of the directly embracing subtask. Thus, the information space of the entire task (subtasks of the highest level) expands as we move to subtasks at the expense of their local objects. For different child subtasks of one subtask, it has a common part - the information space of the parent subtask 3 .
Either loops or recursions are added to the structure statements.
Attention !
You will not find this alternative in the traditional presentations of structured programming. The conceptual contradiction between cycles and recursions is much softer than between structural programming operators and structural transitions, and it is noted only in the form of occasionally encountered pragmatic instructions (good wishes) not to mix them arbitrarily.
Ghosts . Often, even the program itself can not be explained through the concepts that are used inside it. More often this happens for her connections with the outside world. Understanding of the program is possible only after comparing real in-program objects with ideal extra-program objects. These ideal non-program objects (ghosts) are often not just unnecessary, but even harmful for the execution of the program 4 .
The first drew attention to the need to introduce ghosts for the logical and conceptual analysis of the programs of G. S. Zeitin in 1971. In America, this "independently" was rediscovered in 1979, although the mentioned article of Zeitin was published in English in a publicly available edition. Even the name of the entities was given the same ... A separate lecture in the course “Foundations of programming” [21] is devoted to this most important and traditionally ignored concept.
The props are the opposite of ghosts. In fact, they are the form in which matter penetrates the program, and in this capacity they oppose the totality of ideal entities that generate the structure of the program: both real and illusory - and sometimes they distort it grossly. But without backups, the program simply will not work or will work inefficiently.
For structured programming, the requirement is very important:
All structures are subject to the structure of the information space .
This general requirement is specified in the following.
Structural programming is best described theoretically, but private descriptions are not consolidated into a single system. Some books interpret it from the point of view of a programmer, others from the point of view of a theorist. So even here, there is still no unified system of views, although, apparently, there are already all grounds for its formation.
Consider the basic data structure that appears during structured programming. Accounting for this structure allows you to convert good wishes about the consistency of information flows and the course of management transfers in a fairly rigorous method.
A data network can be formally described as an acyclic directed graph in which all co-paths (that is, paths taken the other way around) are finite and the vertices of which are assigned values .
Consider an example. A well-known standard method of programming in languages without multiple assignments - the exchange of two values through an intermediate
z: = second; second: = first; first: = z;
Corresponds to the following data network:
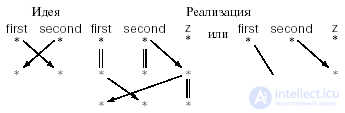
Here, first, second, z can be considered comments, and the data itself is omitted, since their specific values are not important.
This example shows that sometimes for better network structuring, it is advisable to introduce additional vertices corresponding to the conserved values. The edge leading from one such vertex to another is denoted by an arrow that looks like equality. It can be seen in the same way that matter acts on an idea, forcing to introduce additional operators and additional values. In this case, the variable z and the operators that include it are stubs, and, if excluded, the data network becomes simpler. But in common programming languages there are no multiple assignments like
first, second: = second, first;
Even if they were, imagine how uncomfortable it would be to read a long multiple assignment and understand what expression is assigned to a variable!
In the case of the program for calculating factorial 6, the network is potentially infinite downward, since any number can be an argument, but the structure is even simpler:
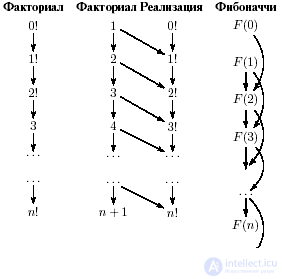
There are no cross dependencies between the parameters, therefore, two known factorial implementations are possible: cyclic and recursive. We will show them in different languages, for all the same in what traditional language to write them.
function fact (n: integer): integer;
var j, res: integer;
begin
res: = 1;
for j: = 1 to n do res: = res * j;
result: = res;
end;
int fact (int n)
{if (n == 0) return (1);
else return (n * fact (n-1));} The circuit for building a cyclic program is called stream processing . The values on the next iteration of the loop depend on the values on the previous one.
For the Fibonacci numbers (the same scheme (14.1.2)), the structure is somewhat more complicated than the previous ones, since each subsequent Fibonacci number depends on the two previous ones, but the stream processing method is applicable here.
int fib (int n)
{int fib1, fib2;
fib1 = 1; fib2 = 1;
if (n> 2) {
for (int i = 2; i <n; i ++) {
int j; j = fib1 + fib2; fib1 = fib2; fib2 = j;
}
};
return (fib2);
} So, in a stream, the structure of two elements changes. It could be directly described as a data structure, and this should have been done if the program were a little more complicated. Then, instead of the j-prop, we would have to introduce a new structure value as a backup.
There is another backup in the program - the cycle parameter i, which is needed only for the formal organization of the cycle.
Recursive implementation of Fibonacci numbers is written even easier and serves as a great example of how contemptible matter kills a beautiful, but shallow idea.
int fib (int n)
{if (n <3) return (1);
else return (fib (n-1) + fib (n-2));
} If n is large enough, each of the previous values of the Fibonacci function will be calculated many times, and without any use: the result will always be the same! But all the props removed ...
In the following example, the inefficiency of recursion compared to a well-organized cycle is even more obvious. Suppose you need to find a path where you can collect the maximum amount of gold, through a network of values similar to that shown in Fig. 14.1.
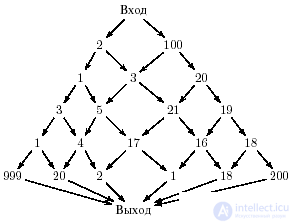
With the cyclical organization of calculations, we will have to calculate the value at each point of the mountain only once (to find the prey on the optimal path to this point). Here, the property of optimal paths is used, which makes possible the so-called wave or dynamic programming methods: each initial segment of a locally optimal path is locally optimal. This property is a ghost behind the efficient cyclic implementation of the algorithm, and numerous paths, respectively, are ghostly values that do not need to be calculated. In the recursive implementation, we do not take into account this ghost, and he ruthlessly takes revenge for the blatant ignorance of the theory.
Now consider the case when the recursive implementation is much more elegant cyclic, it is easier to generalize and not worse in efficiency 7
In this case, the path to obtain the result does not branch out, and we can only move along it in the right direction (from the target to the source data) and in fairly large steps.
function Euklides (n, m: integer) integer; {
assume m <= n}
begin
if n = m then resut: = n
else result: = Euklides (n mod m, m);
end; If we try to calculate the greatest common factor by moving from data to a target, then we will have to build a huge array of GCD values, only an insignificant part of the values in which will be needed to construct the result. The cost of calculating each individual element in this case is small, and in the opposite direction of the movement a second count does not arise.
In the simplest case, the Euclidean algorithm models the situation that appears in the tasks of processing recursive structures, such as lists. The fact that in some cases there is a repeated counting is a small evil, when these cases are rare and irregular. Repeated counting also occurs in cyclic programs, since it is sometimes harder to find matching elements in a large array than to re-calculate the values we need. That is why recursion turned out to be such an effective method of working with lists and allowed to build an adequate first-order foundation for modern functional programming.
Consider the two extreme cases of movement over the network. When a network is represented as a data structure, a method of lazy movement over the network naturally arises, when, after calculating the values at the next point, one of the points is selected, for which all previous values have already been calculated, and the values at this point are calculated. As can be seen, in particular, using the example of the golden mountain, this method is non-deterministic and can be largely parallelized. But in a particular algorithm, we will have to choose a specific way of lazy movement, and it can be extremely unsuccessful: for example, it will provoke a long movement into a dead end when we have a short path to the goal. Even in theoretical studies, it is necessary to impose conditions on the method of lazy movement in order to guarantee the achievement of a result (see, for example, the theorem on the completeness of semantic tables in the book [20]).
Another extreme case of movement on the network when the network is divided into identical layers. For example, in the network (14.1.4)
You can imagine a layer as a static array and seemingly completely forget about the network itself. Забытый призрак мстит за себя, в частности, при необходимости распараллеливания вычислений, и предыдущий случай отнюдь не эквивалентен следующему.
Конечно же большая сеть данных становится необозримой. Справиться с нею можно, лишь разбив сеть на подсети. Таким образом, блоки программы соответствуют относительно автономным подсетям.
Еще Э. Дейкстра в книге [ 11 ] предложил в каждом блоке описывать импортированные и экспортируемые им глобальные значения. Но такая "писанина" раздражала хакеров и в итоге так и не вошла в общепризнанные системы программирования. Сейчас индустриальные технологии требуют таких описаний, но из-за отсутствия поддержки на уровне синтаксического анализа все это остается благими пожеланиями, так что, если хотите, чтобы Ваша программа была понятна хотя бы Вам, описывайте все перекрестные информационные связи!
Резюмируя вышеизложенное, можно сделать следующие выводы.
Attention !
Поскольку структурное программирование отработано и преподается лучше всего, здесь появилась возможность остановиться на гораздо более глубоких и принципиальных вопросах, чем в других стилях. В частности, призраки и подпорки возникают везде, они не являются спецификой структурного программирования, это важнейшие понятия для спецификации, документации и перестройки любой нетривиальной программы
Рассмотренные до сих пор сети данных представляли в первую очередь тот случай, когда в программе нет значительных альтернативных блоков. Условие было лишь средством проверки перехода от одного этапа вычислений к другому. Однако на самом деле, как правило,программа содержит выбор. Для представления выбора в языках программирования имеются условные операторы и операторы выбора. Рассмотрим, что же стоит за выбором.
Пример 14.3.1 . Пусть в некоторый момент исполнения программы Вам необходимо временно выбросить больший из двух хранимых в основной памяти обрабатываемых блоков на диск. Поскольку разница в длине менее 2 16 =65536) несущественна, мы можем записать выбор примерно в следующей форме.
if
length(A)-lengtn(B)>65536 -> {
Save(A); Dispose(A); A_present:=false;},
length (A) -lengtn (B) <65536 -> {
Save (B); Dispose (B); B_present: = false;}
fi We used this form to more clearly emphasize the conditions under which actions are performed.
The proposed form of recording is based on the concept of protected teams proposed by E. Deikstroy. The protected command is executed only under the condition that the guard is executed. But if this text is read by a programmer, he must understand that 'only' does not always mean that when the condition is met, the command will be executed. Dickstra's choice operator consists of many guarded commands. In a specific syntax, we use the form for them.
Guard -> Command
The relative location of the protected commands in the selection operator is indifferent 8 . One of the protected commands is executed , the security of which is true. The specific forms of conditional sentences and choice clauses available in languages are props for implementing protected commands.
It follows from the above that in its essence the choice is as non-deterministic as the execution of the structural program. If several guards are executed, from the point of view of the task, it doesn’t matter which of the actions to choose. However, the available programming tools 9 make us definitely make a choice, and of course, almost always we forget to write in the comments that the choice is in fact indifferent, and then with program modifications there are patches on supports, etc.
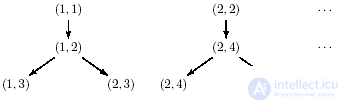
When there is a choice, we are forced to move from a data network to a more complex structure: & - 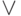 -graphs. Some vertices can be labeled as - vertices, which means that it is enough to get one of the results corresponding to the incoming arcs, and initiate only one of the performances corresponding to the outgoing arc. For the structured & - graph, it is necessary that it be a network that satisfies the following condition: there is an injection
-graphs. Some vertices can be labeled as - vertices, which means that it is enough to get one of the results corresponding to the incoming arcs, and initiate only one of the performances corresponding to the outgoing arc. For the structured & - graph, it is necessary that it be a network that satisfies the following condition: there is an injection 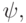 matching each -top
matching each -top  from which there are several arcs, -the vertex ψ (ν), from which only one arc goes, such that any path passing through the first vertex, passes through the second. This indigestible theoretical condition is merely stated in exact language, that-vertices should be grouped into structures of the following type, shown in Fig. 14.2 (the number of options can be any).
from which there are several arcs, -the vertex ψ (ν), from which only one arc goes, such that any path passing through the first vertex, passes through the second. This indigestible theoretical condition is merely stated in exact language, that-vertices should be grouped into structures of the following type, shown in Fig. 14.2 (the number of options can be any).
Now we will focus on the variant of structured programming, which focuses on loops and arrays.
First of all, it is necessary to dwell on the compatibility of structured cyclic programming with recursions. Experience shows that a procedure in which there is a recursive call inside a cycle is almost always erroneous, but theoretically it goes beyond primitive recursion (see the course of logic and theory of algorithms) and, as a result, becomes almost noncomputable. In order not to be trapped here, follow a simple rule.
Attention !
Не используйте рекурсивный вызов процедуры внутри цикла! Рекурсия и циклы должны быть "территориально разделены" !
Данное правило пригодно в подавляющем большинстве случаев. Оно является конкретизацией для структурного программирования известного политико-социологического наблюдения:
Самые яростные противоречия возникают либо между двумя близкими сектами, либо при борьбе двух фракций одной и той же секты .
Люди старшего поколения еще помнят, как во время ожесточенной вражды между китайскими и советскими коммунистами китайцы не переставая повторяли, что у них "из десяти пальцев девять - общие".
However, there are sometimes exceptions. Consider, for example, a search pattern in the tree.
int search (ELEMENT x)
ELEMENT y; int result;
if (good (x)) {
return id (x)}
else for (int i = 0; i <100; i ++)
{y = get_successor (x, i);
result = search (y);
if (result> 0) return result;
}
return 0;
} 14.4.1. Here, the recursion together with the cycle sets a traversal of the tree of possibilities, and there is no deadly reproduction of recursive calls. The reason for this exception is that the cycle in this program is just a backup for recursion. In ordinary programming, there are no LISP type mapcar type functionals that apply their first argument to all members of the second 10 .
Structural programming is based on the assumption of locality of actions and conditions, therefore, hierarchical division of the task into subtasks — the so-called descending planning — is especially suited for it in particular.
For downward planning, begin with the assumption that the problem is solved. Then they try to implement a solution to the general problem, highlighting those blocks that turned out to be non-elementary in the construction of the next level. As a result, we get the structure of the relationship between the structures of the second level and the specifications for each of these structures. If we implement each of the constructions in exact accordance with the obtained specification, then we will get a solution to the general problem.
In planning the processes of activity, each of the subtasks is the process most often implemented by an individual or a group of people, in designing technical systems, each of the subtasks gives a construction block, in programming it gives a module (in the most common fairly simple cases, a subprogram).
Top-down programming - specifying downstream design for programming needs. It has the following advantages.
No specific method of analysis or synthesis is not universal. Downstream programming, of course, is also not. The reasons for this, in particular, the following 11 .
This indicates the need for means to raise the level of concepts. Therefore, in the development of structural programs, an approach called upstream programming is also used. For example, when building a library, they are engaged in the task generalization. Parts allocated as library tools are chosen in such a way that they are applicable in different contexts.
When creating a global context, various styles can be used. For example, modules can be programmed in automaton programming style. If the division of styles into modules, packages and other autonomous structural units is carried out strictly, then there is no eclectic mixing of them.
Real Project 12 is a mixture of downward and upward approaches:
In both the downstream and upstream approaches, it is important to ensure that control flows and data flows are consistent. The main tool here can be a look at the program from the side of data networks. Since the cycle appears as the implementation of layer-by-layer movement over the network, and the array as the representation of the network layer, it is clear that in fact the main information structure of the cycle is the network layer. For example, in a cycle that implements Fibonacci numbers, it is a structure of fib1 and fib2. The structure representing the next network layer is called a real parameter (as opposed to a formal parameter dictated by a programming language and often a support) of a cycle. The real parameter we will simply call the parameter.
Further, since a cycle occurs during the repetition of homogeneous actions, and the actions are dictated by the properties of real objects of the program, in a loop there must be a common property that depends on the parameter and is called a loop invariant . For example, in a sorting loop, this is the ratio between the sorted and unassorted array fragments.
When formulating a cycle invariant, we almost inevitably come across the inventor's paradox, which forces us to introduce ghostly values, for example, an array partitioning tree into sorted subarrays in efficient sorting algorithms.
The technique of cyclic and recursive structured programming using invariants and non-determinism (but without explicit mention of data networks) is perfectly described in the Alagicch, Arbib, and Gris textbooks [1], [9]. Kormen et al. [MIT textbook] [13] should also serve as a reference book for a programmer, in which you can find many good examples of how to find the right software solutions and use props with taste.
We take one more step. Since the assignment from the point of view of the problem being solved is only a means to specify the elements of the new network layer, it makes sense to assume that during the whole iteration of the cycle the parameter is fixed, it changes only between the two iterations. Thus, to coordinate data flows and control flows, it is necessary to concentrate all assignments to real entities in one place: either at the end or at the beginning of the next iteration . Moreover, in principle (and even not entirely theoretical, but poorly supported by modern programming systems) assignments could be banished altogether, making the transition of the old value of the real loop parameter to the new implicit, just as it was done for the formal, say, in language Pascal.
And finally, it is necessary to note the following.
Attention !
Ghosts and invariants must be aware before writing the text of a working program. If you leave it for later, you will surely confuse the props, which will occupy the main part of mental resources at the final stage of realization, with entities. Moreover, paradoxically, it is usually harder to restore the justification for the text of a finished program than to build it in advance (the fact that in any case it is not easier to restore it was even theoretically justified; see the last chapter of the book [20] ) .
Structural programming came into general use after E. Dijkstra, who popularized his work, which, unfortunately, did not even hint at its limitations. The limitations of structured programming derive from both its very essence and the Bem-Jakopini theorem. The use of structural transitions, which D. Knut introduced into practice and theory (having dug up the original work of Bem-Jakopini and clearly outlined the limitations of the Daktrow structural approach 13 ), eliminates many of the shortcomings inherent in the Dijkstra technique. Structural transitions - transitions only forward and to a higher level of the structural hierarchy of management, in no case do not take us beyond the limits of this module.
/ * Examples of structural goto. * /
. . .
do {y = f (x, y)};
if (y> 0) break;
x = g (x, y);
} while (x> 0);
. . .
{. . .
{
if (All_Done) goto Success;
}
. . .
Success: Hurra;} 14.5.1. Structural transitions are now also included in common programming languages. Their use gradually penetrates into training courses.
Structural transitions are palliative. They arose because of the need to express the idea that the success or failure of the global process can be revealed within one of the solvable subtasks, and further work on the current task and the entire sequence of nested subtasks becomes simply meaningless. In this case, not even transitions are necessary, but operator completion. But they in many common languages act only one level of hierarchy up, and even theoretically this is not enough. 14 It is worth noting that between the idea and its correct implementation often take many years. Now in the common Java language, trailers are finally implemented more or less correctly.
There is one limitation of structural transitions known since the 80s. Of the twentieth century (cf. [20]), at least once reliably damaging the creators of the domestic Elbrus series of machines, in which structural and functional programming was maintained at the hardware level. Structural transitions (including trailers) are incorrect when they take us out of the parameter function of calling another function. The irony is that an absolutely clear and complete realization of the finaliters, even before realizing the need for this tool, and even more so long before realizing the limits of its applicability, was done exactly where they are generally incorrect (in the LISP language). In it, as we have seen, procedures are full values, can be parameters and results of other procedures. The most obvious case of incorrectness (though, caught by the Common Lisp dynamic error detection system), is when we inside the created procedure complete the block that existed at the time the procedure was created, but ceased to exist at the moment it was called. Surely, many people stumbled upon the incomprehensible behavior of programs with finalizers, but in accordance with the common "positive" thinking, they did not pay attention to this phenomenon.
There is one more, at first glance exceptionally attractive, opportunity. In conventional programming languages, it is often annoying that the value worked out once cannot be used immediately in the next statement, and, moreover, for some obvious nonsense, the completely harmless concept used in Algol 60, like
if x = 0 then sin (y) else tan (y)
It turned out to be thrown out of some common languages (maybe because in this case the else part is required). In the same LISP language, where there was (quite a unique case in programming) a clear and rather closed system of concepts was created (not a single discrepancy that could be diagnosed at the then state of theory and practice could not be found in it), each operator gives the value which can be used by the ambient operator.
This concept was tried to be transferred to the traditional language in the Algol 68 language. At first glance, it was very beautiful. For example, the operator
if x> 0 then a1 else a2 fi [if y> 0 then j else i fi]: = if z> 0 then sin (u) else tan (u) fi
the sequence of conditional statements that you have to write in Pascal or C ++ is much more compact and beautiful. But the concept of the value produced is in a conceptual contradiction with the assignment operator and with joint calculations. For example, according to the semantics of Algol 68, the following entry
(x: = 3, y: = x + y, z: = x + y)
is a program block in which all three assignments are executed together. But it is obvious that in this case the result of the calculations is ambiguous. At the same time, since the values are not forgotten, the same construction is an image of an array of three elements or a record with three fields.
Therefore, if we extend the system of values to all structured programming operators, then unstable expressions are formally admissible and seductive for hacker stunts. An expression that changes its context (in particular, an assignment) should not produce a value, so that it is not tempted to put it in an environment where it will cause a difficult to diagnose ambiguity.

Comments
To leave a comment
Programming Styles and Techniques
Terms: Programming Styles and Techniques