Lecture
Refal is a subject-equational method for determining functions on a free monoid with an additional unary operation.
(A. P. Beltyukov. Refal definition for pure mathematicians.)
Refal is a wonderful language! You can program anything on it, if, of course, you don’t know other languages.
UdSU student
Sentential programming occurs when the data has a clear and rather complex global structure, the actions are aimed primarily at restructuring this structure, and the task as a whole corresponds to the invariant:
actions are global, conditions are global . (5.1)
In this case, powerful means of recognizing global conditions are needed, which are naturally immersed in the model of language computation as atomic means. When formulating conditions, a programmer can afford not to think about how their recognition occurs, and focus on the most important part: the description of structure rearrangements.
In the existing two most advanced and alternative systems of the potential programming Prolog and Refal, while recognizing conditions, there is also the preparation of information for the application of adjustment. This feature is
preparation of information for action during condition recognition , (5.2)
Perhaps, is characteristic for potential programming. In particular, it separates those cases when it is better to use the programmatic programming, and those cases when event programming is advisable (see below). Prioritization checking and selecting the action with the highest priority as the active one is also hidden in the atomic actions of the software system, but the programmer doesn’t receive any useful information for performing the selected action when checking priorities.
Currently, a global verification of conditions in systems of potential programming is carried out by processing meta-expressions. Meta -expression differs from expression in that it contains variables. For example, if the small letters denote constants, and the big ones denote variables, then 1 + a is an expression, 1 + X is a meta expression. When checking, it turns out that it is possible to identify some meta-expressions with each other or with data, and at the same time a substitution is calculated, that is, a function that associates variables with their values. The substitution gives the necessary information for executing the program operation step In the example just given, when identifying, instead of X, a should be substituted.
This way of working is consistent with the formulation of global conditions in logic and in the theory of algorithms, but it cannot be considered a priori exhaustive. Further, other forms of global data validation may appear.
The Refal language was created by V.F. Turchin for programming symbolic transformations. He received the initial impetus from the idea of the Markov algorithms (see, for example, the theoretical appendix to the book [21]), but this idea was completely revised in the course of the work on creating the language. The ideological and mathematical level of language development is exceptionally high, but design issues are almost ignored.
The basis of the language is (a different case compared to the PROLOG language) special case of the operation of identification: concretization of the meta-expression.
By concretization is meant such a particular case of identification, in which variables are found only in metaexpression and the search for their values occurs by selection without recursion.
The Refal language is defined through three components: the data structure, the Refal machine that processes this data, and the actual syntax of the language itself.
The data processed by the Refal language is a sequence of atoms, structured by several kinds of brackets that are consistent with each other. For example, in some specific syntax, such an expression could be {a + [b- (c + d) ** 2] / 3} * (a + d). Two types of brackets are involved in the Refal-machine memory field: structural and functional.
Expressions of Refal.
In the specific syntax Refal functional brackets are denoted by <>, structural - (). Atoms are divided into:
The main part is allocated in the memory field, as well as the global data stacks - the buried data . Before each performance step, the active part is highlighted in the main part of the memory field - the field of view. The data in the field of view and the buried data have a common structure 1 , which is a substructure of the structure of the memory field. Since the program has almost the same structure 2 , in the course of language development a third data structure ( metadata ) appeared, expanding the memory field.
We give exact definitions.
An object expression is an expression that does not contain function brackets.
The minimal functional expression is an expression of the form <E>, where E is an object expression.
Refal-machine memory field is a set of expressions, one of which is called the main part . In the main part, at any moment, except for the moment of issuing the final result and stopping the program, there are functional brackets.
The field of view (active part) of the memory field is the first of the minimal functional expressions found in the main part of the memory field.
The determinative is the first character in the functional bracket.
The determinative is interpreted as the name of the function that processes the contents of the function brackets. This function should be defined statically, therefore, in the course of calculations, expressions like <<e.1> e.2> cannot be formed. In the overwhelming majority of cases, the determinative must be a name, but some ordinary characters, for example +, can also be used as determinants.
Example 5.2.3 . Consider an example of the Refal machine memory during calculations.
Memory field:
'aaxzACDE' <Sort < Perm 'G'1.5E5 > <Perm 115' F '> <Perm 112 -2.0E-5 >> <Sort AllRight Sort Perm' QRTS '>' XZ <(')
The field of view is highlighted in bold in the memory field. Note that in the memory field, you can select data that has already been processed and which will not change until the end of the program execution (those that are outside the program brackets; in our case, “aaxzACDE” and 'XZ <('). For characters representing brackets , there are 'ordinary' twins that do not necessarily have paired and do not affect the structuring of the expression.The first Perm atom is in the function position, and the last Perm atom is in the data position, so the function names can be dynamically formed 3 . if they are not inside character constants are ignored, except for those that separate one character from another (these spaces are simply omitted after playing the role of separators at the lexical analysis stage.) And finally, another subtlety. 123 is one atom, '123' - three atoms, -123.0 - again one atom, -123 - two atoms: the symbol '-', followed by a number.
In addition to the main part of the memory field, during the execution, several stacks of buried expressions may appear, for example:
Stack1 '=' 15 Stack2 '=' Perm BA
21 Perm C2 C1
-45 Perm 'X' 20
60 In principle, multiple stacks are redundant. But, since here stacks are considered as common areas of memory, it is better to have your own stack in each module. Unfortunately, there is no explicit connection between the stacks and the modules in Refal programs.
Suppose there is a string <AB (CD) (E) F>. In all Refal-systems known to us, it is represented by the bidirectional list shown in fig. 5.1. This presentation format has become common for Refal systems, starting with the implementation described in [25]. However, it is not mandatory.
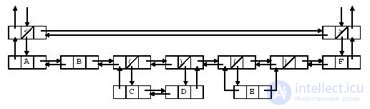
When implementing the Refal language, V. F. Turchin thought how to avoid too frequent appeals to some surrogates of the possibilities of traditional languages. He decided to describe in advance the algorithm for transforming expressions and choosing for him a suitable data structure. The algorithm described by him works well with a whole class of cases, including those that were not foreseen in advance, a distinctive feature of a conceptually thought-out solution. In the lecture relating to the PROLOG language, one can see what happens if the data structure is not well thought out at the early stages, and even more so to fix random intermediate results as a standard.
Moreover, the algorithm and data structures described by Turchin provide an excellent basis for accurately defining semantics based on abstract Refal syntax.
Conversion of expressions into a format for processing is done once, when entering information or when translating a program.
Consider a specific expression syntax.
Identifier - any sequence of numbers and letters, starting with a capital letter. The identifier is a character literal and represents a composite character. Characters enclosed in single quotes are character literals that represent themselves. A double-repeated quote represents a quote. Double quotes "" are used to limit the name of a compound character, not necessarily an identifier of 4 . If outside of quotes there is a character that is not a bracket, part of an identifier or a number, this is treated as an error.
The definition of a metaphor Refal is obtained from the definition of an expression by adding another basic case: a variable is a meta expression. Variables cannot be deterministic.
A metaexpression is called a pattern if it does not contain functional brackets.
In a specific syntax, the variable designation includes the type and the character of the variable, written as type.atom. In the standard Refat there are three types of variables: symbolic (s.First), thermal (t.Inner) and general (e.Last).
The value of a symbol variable is an atom, a term is a term (a symbol or expression in parentheses), and an arbitrary (perhaps empty) object expression is common.
Refal developed as a language of symbolic transformations in the widest sense of the word, and therefore it was possible to process its own programs. It provides standard metacoding functions that convert one-to-one meta-expression into one-to-one and one-to-one and vice versa. Thus, it becomes possible to create programs in the course of executing other programs and then execute them on the fly. This possibility, which is simply disastrous for programs in most systems and programming styles, in this case does not lead to any negative consequences due to the unique conceptual unity and thoughtfulness of the language 5 .
The main two steps in Refal calculations are specification of variables in a sample in accordance with the field of vision and substitution of the obtained values into another meta-expression. The language considers only a special case of specification.
Specifying the sample Me in the object expression E is called the substitution of values instead of the variables Me, that after applying this substitution Me coincides with E.
Note that the same meta-expression can have many concretizations into the same object expression. For example, consider the metafield
e.Begin s.Middle e.End (5.3)
and object expression
AhAhAh 'OhOhOh' (Ugu ',' Udgu) '(((' Basta '!'
(5.4) There are 11 options for instantiation (5.3) to (5.4) (check!).
If meta-expression Me has many instantiations in E, then they are ordered by preference in the following order.
Let Env1 and Env2 be two instantiations of Me in P. Consider all occurrences of variables in Me. If Env1 and Env2 do not match, they assign different values to some variables. We find in P the very first occurrence of the variable to the left, to which Env1 and Env2 are assigned different values and compare the length of these values. The one of the instantiations in which the value attributed to a given occurrence of a variable is, in short, preceded by another and takes precedence over it.
For example, we associate an object expression (A1 A2 A3) (B1 B2) with a sample e.1 (eX sA eY) e.2. The result is the following set of matching options:
{e.1 =, eX =, sA = A1, eY = A2 A3, e.2 = (B1 B2)}
{e.1 =, eX = A1, sA = A2, eY = A3, e.2 = (B1 B2)}
{e.1 =, eX = A1 A2, sA = A3, eY =, e.2 = (B1 B2)}
{e.1 = (A1 A2 A3), eX =, sA = B1, eY = B2, e.2 =}
{e.1 = (A1 A2 A3), eX = B1, sA = B2, eY =, e.2 =} Example 5.1. Many matching options Matching options are listed according to their priorities, that is, the very first option comes first, and so on. The described method of ordering matching options is called left-to-right matching .
The specification algorithm that is used in Refal is called projection and is consistent with the order relation introduced by us. We describe it (the description is taken from the textbook Turchin). Notice how, in this case, the general and not always efficiently implemented operation is 'projected' onto its private implementation, which at the same time increases efficiency, preserves generality and prescribes programming methodology.
The occurrences of atoms, parentheses, and variables will be called expression elements . The gaps between the elements will be called nodes . The E: P mapping is defined as the process of mapping, or designing, the elements and nodes of the sample P onto the elements and nodes of the object expression E. A graphical representation of a successful mapping is shown in Fig. 5.2. Here nodes are represented by o signs.
The following requirements are an invariant of the matching algorithm and their implementation is ensured at each of its stages.
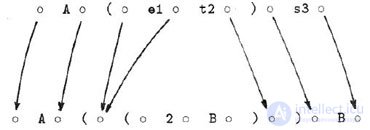
At the start of the mapping, it is assumed that the boundary nodes P are mapped to the boundary nodes E. The mapping process is described using the following six rules. At each step of displaying rules 1-4, determine the next element to be displayed; thus, each element from P gets a unique number when displayed.
In fig. 5.2 сопоставление производится следующим образом. Вначале имеется два жестких элемента с одним отображенным концом: 'A'и s.3. В соответствии с Правилом 3 отображается 'A', и этот элемент получает при отображении номер 1.Номера 2 и 3 будут назначены левой и правой скобкам согласно Правилам 3 и 1. Внутри скобок начинается перемещение справа налево, так как t.2 является жестким элементом, который может быть отображен, в то время как значение e.1 еще не может быть определено. На следующем шаге обнаруживается, что e.1 является закрытой переменной, чью проекцию не требуется обозревать для того, чтобы присвоить ей значение; что бы ни было между двумя узлами, это годится для присвоения (на самом деле, значение e.1 оказывается пустым). Отображение s.3завершает сопоставление. Расположение отображающих номеров над элементами образца дает наглядное представление описанного алгоритма:
1 2 5 4 3 6 'A' ( e.1 t.2 ) s.3
Этот сложный алгоритм упрятан в простые программные конструкции.
Программа на Рефале является последовательностью определений функций. Каждое описание функции в Рефале имеет вид
Имя функции {Последовательность сопоставлений} Каждое сопоставление имеет вид
Образец = Метавыражение;
Относительное расположение членов последовательности определений никакой роли не играет, и функции можно группировать из логических или технологических соображений. Относительное расположение сопоставлений внутри определения функции существенно.
Пример 5.3.2 . Рассмотрим пример Рефал -программы.
Pre_alph {
*one. Отношение рефлексивно
s.1 s.1 = T;
* 2. Если буквы различны, проверить, входит ли
* первая из них в алфавит до второй
s.1 s.2 = <Before s.1 s.2 In <Alphabet>>; }
Before {
s.1 s.2 In eA s.1 eB s.2 eC = T;
eZ = F; }
Alphabet {
= 'abcdefghijklmnopqrstuvwxyz'; } Листинг 5.3.1. Программа вычисления предиката предшествования одного символа другому в заданном алфавите Строки, начинающиеся с *, служат комментариями. Последняя из функций Alphabet введена для технологичности, чтобы определение алфавита было в одном месте и его легко было изменять. Так что функция с пустым образцом может пониматься как константное выражение. In является атомом-разделителем, заведомо не встречающимся в алфавите.
Последнее из правил сопоставления в Before применимо всегда. Такое сопоставление гарантирует, что предикат никогда не заканчивается неудачей.
Если взаимное расположение функций никакой роли не играет, то внутри функции расположение сопоставлений важно. Сначала применяется первое из сопоставлений, при неудаче переходят ко второму и так далее до последнего.
Заметим, что в языке Рефал отсутствие сопоставления, конкретизацией которого является текущая область зрения, означает аварийный останов программы с выдачей текущего поля памяти и закопанных данных. Пожалуй, это достаточно технологичное решение, поскольку для тех, кто сам желает обрабатывать ошибки, всегда имеется возможность поместить последней строкой в определение функции правило видаe.A=Обработка ошибки ;
Имеются также встроенные функции, в частности, функции работы с числами <'+' s.Number1 s.Number2> и подобные ей.
Рассмотрим связь между языком и программным окружением.
To run the Refal program, it is necessary to initialize the memory field. It is accepted that at the beginning of the execution of the program, the memory field has the form
<Go>
Thus, the Go function is first applied to the empty field of view. This function must be defined in the program by one matching with an empty sample and cannot be called by any other function. Since most often the program must process the original data in the file, in a typical case, the description of the Go function looks like this:
$ ENTRY Go {= <Prog <Open 'r' 1 'data.txt'> <Get 1>>}
В нашей программе 5.3.1 алфавит определен статически. Было бы хорошо иметь возможность заменять эту глобальную информацию. Для хранения динамической глобальной информации (чаще всего числовых характеристик либо словарей) в языке Рефал имеются стандартные функции работы со стеками закопанных данных. Function
<Br eN '=' e.Е >
рассматривает свой первый аргумент (который должен быть строкой символов, не включающей '=' ) как имя стека, и помещает свой второй аргумент на вершину этого стека. Если стек был пуст, то он создается. Соответственно, функция
<Dg eN>
выкапывает верхушку стека. Если стек пуст, то ошибки нет, просто выдается пустое выражение. Несколько других функций дополняют возможности работы с глобальной информацией. Cp копирует верхушку стека без ее удаления, Rp замещает верхушку стека на свой аргумент, DgAll выкапывает сразу весь стек.
Ввод-вывод организован в Рефале довольно лаконично, без излишеств. Имеется функция открытия канала ввода, которая открывает файл либо для ввода, либо для вывода (в этом случае первым аргументом служит 'r' и присваивает ему номер. Одна строка символов из файла читается с помощью функции Get, заменяющей свой вызов на прочитанную строку, одна строка пишется в файл путем функций
<Put s.Channel e.Expression>
or
<Putout s.Channel e.Expression>
The second function erases its field of view, and the first leaves the printed expression as a result.
It should be noted that these functions read and write exactly sequences of characters. When using them, the programmer must convert the sequence of numbers into numbers, and the brackets-symbols into structure brackets. Moreover, in the output part of the information is lost: it is impossible to distinguish between a sequence of letters and an identifier, a sequence of numbers and a number, structural brackets and brackets-symbols. Therefore, there is another set of functions that automate the transformation. Each of these functions processes an expression balanced by brackets. Entering this expression ends with an empty string.
<Input s.Channel> or <Input e.File-name>
<Xxin e.File-name> or <Xxin s.Channel>
<Xxout s.Channel e.Expr> or
<Xxout (e.File-name) e.Expr> The first of the functions is intended for manual input of files. The second and third - for the exchange of intermediate information with the disk.
The functions just listed, along with the Go function, require an explanation of the modularity tools in Refal. Refal-module - just Refal-program, not necessarily including Go. Functions provided to other modules are described by the $ ENTRY specifier as inputs. In turn, the using module must describe the external functions:
$ EXTRN F1, F2, F3;
The call of the program consisting of several modules is made by an operator of the following form:
refgo prog1 + functions + reflib
Модуль основной программы должен идти первым. Никаких средств включить требование вызова модуля в текст другого модуля нет, модули сопрягаются внешним образом. При конфликтах имен берется определение функции из первого в порядке подключения модуля.
В частности, только что описанные расширенные функции ввода-вывода определяются в стандартном модуле reflib.
Важнейшими средствами современного Рефала является работа с метавыражениями. Базовое ее средство — встроенная функция Mu, которая заключает свой аргумент в функциональные скобки и тем самым дает возможность вычислить динамически построенное выражение. По словам Турчина, Mu работает так, как работало бы определение
Mu { sF eX = <sF eX> }, если бы оно было синтаксически допустимо.
In particular, the standard Refal e (Evaluation) module works through Mu, making it possible to calculate the dynamically entered expression. It processes this expression through the Upd function, which must be added to the module where the dynamic evaluation of expressions is performed. For example, if you add a description
$ ENTRY Upd {eX = <Mu eX>;} then the refgo e + prog1 command line will lead to the requirement to write an expression. This expression will be made field of the program prog1 and calculated, and the result is displayed. For example, writing for program 5.3.1
<Alphabet>
we will get as a result
'abcdefghijklmnopqrstuvwxyz'
Naturally, the question arises of processing inside the language not only objective, but also arbitrary expressions. Standard functions Up and Dn are available for this. The first of them turns an object expression into an expression of an arbitrary type, the second encodes its field of view (by it, according to the semantics of the language, it can only be an object expression) in a form suitable for general expressions and even for expressions. In the standard Refal kit, there is even a sweep module, which allows you to input a statement to the input of the program and calculate it as much as possible without knowing the values of the variables.
When solving complex problems on Refal, the problem of representing a multi-hierarchical structure naturally arose. For the particular case of two independent hierarchies, one of which is considered the main one, and the second begins to work after the main one is exhausted, Refal has developed a multi-box representation of expressions. It is supported by library functions of encoding and decoding expressions and programs that translate a multi-box expression into its standard code and vice versa. For the particular case when the secondary hierarchy is our usual brackets, and the primary hierarchy is a link deep inside a bracket expression that implicitly defines a single-level bracket structure that is independent of the standard one, the coding algorithm is extremely simple. The expression is divided into two parts unbalanced by the brackets: left and right. In both parts, unpaired brackets are replaced by pairs) (. The opening bracket of the highest level is represented as ((, the place where the link leads to as)) (, closing the bracket of the highest level as)).
Finally, we will consider a rather complicated algorithm at Refal, which illustrates many programming techniques: storing intermediate information, error handling, input-output.
Suppose we have an expression with different paired brackets (in the specific case, we use the pairs '() [] {} <>', but the program is designed so that these pairs can be replaced at any time). To work effectively on Refal, this expression must be encoded using structural brackets. The code for the pair of left parentheses is the parentheses (left and right). Below is the encoding algorithm.
When recording this algorithm, another Refal -5 option is used. After the sample, a comma can be followed by an arbitrary expression, including the free variables of the sample, and then another sample. In the second sample, we identify the auxiliary expression without changing the values of the variables inherited from the previous sample. If after the second sample there are curly brackets, then we define an unnamed function inside the function. If they are not, then this identification is considered as an additional condition for the success of the first identification. This nesting hierarchy can go on for several levels, with the variables of the external levels at the internal levels remaining connected, without changing the values.
Hierarchically nested functions and conditions are not necessary in principle for Refal, but their use allows reducing and, more importantly, better structure the text of the program.
$ ENTRY Go {= <Init>;}
$ EXTRN Xxout;
* Initialization of the field of view and constants
Init {= <Open 'r' 1 'Input.txt'> <Trans <Acquire (<Get 1>) ";}
Acquire {
e.Got () = e.Got;
* End of input - empty line
e.Got (e.New) = <Acquire e.Got e.New (<Get 1>)>;
}
Brackets {= ('()') ('[]') ('') ('<>');}
Trans {
eA = <Result <Pairing () eA>>;
}
Pairing {
* The first parenthesis contains the sequence of all unclosed
* brackets along with data segments to be placed
* in this pair of brackets;
* each data segment is also enclosed in brackets
(e.Unclosed (e.LastUn) (s.Lbrack e.Middle)) s.Rbrack e.Last,
<Brackets>: eA (s.Lbrack s.Rbrack) eB =
* The right bracket met, the last unclosed pair;
* we throw out the waste segment from sight
<Pairing (e.Unclosed (e.LastUn (s.Lbrack e.Middle s.Rbrack))) e.Last>;
((s.Lbrack e.Middle)) s.Rbrack e.Last,
<Brackets>: eA (s.Lbrack s.Rbrack) eB =
* Steam room unclosed, located inside another unclosed
(s.Lbrack e.Middle s.Rbrack) <Pairing () e.Last>;
(e.Unclosed (e.LastUn) (s.Lbrack e.Middle)) s.Rbrack e.Last,
<Brackets>: eA (s.Lbrack1 s.Rbrack) eB =
* Unpaired brackets
<Prout "Brackets Mismatch!"> Error;
(e.Unclosed) s.Lbrack1 e.Last,
<Brackets>: eA (s.Lbrack1 s.Rbrack) eB =
* Another opening bracket; create new data group
<Pairing (e.Unclosed (s.Lbrack1)) e.Last>;
() s.Lbrack e.Last,
<Brackets>: eA (s.Lbrack s.Rbrack) eB =
* First opening bracket
<Pairing ((s.Lbrack)) e.Last>;
() s.Rbrack e.Last,
<Brackets>: eA (s.Lbrack s.Rbrack) eB =
* First bracket - closing
<Prout "Extra right bracket"> Error;
* Neutral character outside parentheses
() s.Other e.Last = s.Other <Pairing () e.Last>;
* Expression and brackets exhausted - success
() =;
* The expression has been exhausted, but the brackets are not.
(e.Unclosed (e.Lastun)) = <Prout "Not all brackets are closed" Error;
* Neutral character in regular bracket
(e.Unclosed (e.Lastun)) s.Other e.Last =
<Pairing (e.Unclosed (e.Lastun s.Other)) e.Last>;
}
Result {
* If there was an error, exit
eA Error =;
* Otherwise display the result for further use.
eA = <Xxout ('output.rdt') eA>;
} Listing 5.4.1. Multi-box expression: Refal In order to more clearly see the influence of style on software solutions, compare this program with the development of the program in the traditional style given in § 11.5 of the book [22]. This program is much more expressive, shorter, easier to modify and not less effective than program 11.5.3 of the specified paragraph.
In the practice of working with students, the author had to deal with the situation when the program for the same task, written in the traditional language, was more than five times longer than the program at Refal. So the use of specialized tools pays off (naturally, when they are applied in suitable cases).
From the literature on the Refal language, one can recommend textbooks [37], the first of which is available in a public Russian translation, in particular, on the website http://www.refal.ru/diaspora.html.

Comments