Lecture
Это продолжение увлекательной статьи про имитация психологической интуиции с помощью искусственных нейронных сетей.
...
the vector of input signals is large and the learning time also leaves much to be desired, as it allows to reduce the dimension of the vector of input signals without degrading the learning of the neural network.
The following algorithm is proposed for solving this problem: after several cycles after the start of the neural network training, we include the procedure for calculating the significance indicators. It is advisable to select the moment of launching this procedure individually in each specific case, since in the first few training cycles the neural network somehow “scans” in search of the right direction and the significance indicators may change to diametrically opposite. Next, there are several cycles of training, during which the indicators of sensitivity accumulate in any norm.
one) 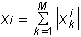

2) 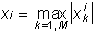
Where 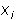 - the norm for the i-th signal,
- the norm for the i-th signal, 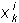 - assessment of the significance of the i-th signal in the k-th example, M - the number of cycles of significance counting. After indicators calculated, you can reduce the number of input signals. The reduction should be made on the assumption that the smaller the value the less it affects the learning process.
- assessment of the significance of the i-th signal in the k-th example, M - the number of cycles of significance counting. After indicators calculated, you can reduce the number of input signals. The reduction should be made on the assumption that the smaller the value the less it affects the learning process.
Thus, along with the calculation of significance indicators for assessing the degree of training of a neural network, the definition of groups of significant signals makes it possible at the early stages to screen out signals that have little effect on the learning process and the work of a trained neural network.
However, it should be noted that this algorithm does not insure that the parameter, which turned out to be unimportant at the start of training, will not become dominant during the final training of the neural network.
Based on such assumptions, the author calculated the parameters of the significance of the signals (questions) of the LOBI questionnaire. When selecting signals with the maximum significance, a list of issues that were important for determining this type was obtained, and it essentially coincided with the key sample for this type by LOBI. An interesting result was obtained by cutting off insignificant inputs - the quality of network training improved significantly (on 2 such networks, the result was 95.24% and 90.48%, or 20 and 19 correct answers from 21 test cases). What conclusion does this result allow to do?
From the roughest estimates of the required experimental sample size when creating a test procedure, it follows that if the dimension of the “key sequence” is N questions, then to calculate the weights for these questions, the necessary sample must be of the order of N * N examples. Just about the ratio (N - about 15, N * N - about 200) occurred in the described experiment. However, it should be remembered that the set of test questions, as a rule, is much wider than is necessary for the diagnosis of this trait, since most of the methods are designed to identify several signs. And, therefore, the following problem arises: to determine the parameters of the model, M * M examples are required, where M is the total number of questions. Apparently, it is worth recalling that for the LOBI technique, for example, M = 162, then the number of examples should be 26244, which is practically unrealistic for the practitioner to be single, with no powerful research center behind it.
In the case when the sample has an insufficient size, the phenomenon of “false correlations” arises - the model determines the effect on the output of those parameters that actually correlate poorly with it. It is these “false correlations” that cause errors when classifying the subjects as being of the presence or absence of a diagnosable type.
In the next series of experiments, a technique called “contrasting” was used. In the neuroimmitator "MultiNeuron" it is possible to disable some of the input signals. This is achieved by the fact that the synapse responsible for the switchable input is assigned a fixed value - 0, which cannot be changed in the learning process. Then this input does not affect the network learning process. In this experiment, the author proceeded from the fact that the inputs that have minimal significance in the field of tuning parameters, which corresponds to the trained state of the network, are not essential for the diagnosis of the type. Consequently, when they are disabled, the dimension of the input space is reduced, and therefore the required size of the training sample is reduced. The dramatic improvement in learning outcomes achieved after the contrast confirms this fact, because the volume of the experimental sample obtained from general ideas was just enough to train the contrasted network.
So, to the question asked above, we can answer: improving learning outcomes after analyzing and tuning inputs suggests that contrasting is a means of combating false correlations, and therefore reduces the amount of experimental sampling for multifaceted techniques.
In addition, a side effect of processing can be a set of questions that are essential for this type, which can give a subject for reflection to theoretical psychologists.
1. A fully connected neural network allows psychodiagnostics of the classical tests studied on the basis of questionnaires with a 95% correct response probability.
2. To create neural network expert systems, there is no need for maths to intervene; this technology allows the program to directly learn from the experience of psychodiagnostics.
3. The psychodiagnostic technique created on the basis of the technology of neural network expert systems is adaptive to changing sociocultural groups.
4. Using the capabilities of software neuromitters, you can perform a study of the parameters of psychodiagnostic methods and refine their structure.
In the work of practical psychologists dealing with the selection of personnel or exploring relationships within already established groups (an example of the first can be a counseling consultant for recruitment, an example of the second is an officer working with personnel in units, a class teacher in a school) and predicting interpersonal relationships in a group.
The relation in this work is understood as a psychological phenomenon, the essence of which is the emergence of mental education in a person, accumulating the results of knowledge of a specific object of reality (in communication is another person or group of people), integration of all the emotional responses to this object, as well as behavioral responses on him [24]. In addition, communication usually occurs in a particular situation: in the presence of other people who are subjectively significant for communicating to varying degrees, against the background of a particular activity, under the influence of any experimental factors.
In this paper, the task was to model and, if possible, predict the system of relationships in the group based on the state and behavior of the subjects, leaving aside such aspects of the formation of relationships between people, such as appearance, goals and motives ascribed to man [24]. Interpersonal “status-role” [79] relations in groups were evaluated and predicted. The assessment of the “person-to-person” and “group-to-person” compatibility was carried out by assessing the status of the subjects - individual (from each to each) and group (from group to a person).
The task of modeling and predicting the relationship of people in a group (team) is heterogeneous - it can be divided into the following subtasks:
- the prediction of the occurrence of the subject in the existing team;
- prediction of compatibility between the two studied.
In addition, when conducting experiments, it was intended to test the method for predicting interpersonal relations by using the method of intuitive prediction and bypassing the creation of the described (descriptive) [26] reality.
To determine the actual relationships in the studied groups, a sociometric method was used. This method allows to determine the position of the group in the interpersonal relations of the group to which it belongs, which is studied in the system. A sociometric study of a group is usually conducted when the group includes at least 10 people and exists for at least one year. All members of the study group are invited to evaluate each of the comrades (including himself) - the opportunity arises to study the self-esteem of the subjects). In the standard version of the methodology, the assessment is carried out on a three-step scale of preferences - “I accept - indifferent - I reject”. However, to obtain a higher resolution of the technique, the scale was modified to ten points. In the used variant of the sociometric study, the following task was applied: “Assess your comrades by asking yourself the question:“ How I would like to work with this person in the same group? ”. Put in the appropriate column a rating from 1 to 10 points according to the following principle: 1 - I don’t want to have anything in common with him, 10 - with this person I would like to work the hardest. ”
The result of the study for each of the subjects in the group was a wall assessment of status and expansiveness. Sten [20] is an averaged estimate, normalized on the assumption that the estimates are distributed according to the law of normal distribution and, therefore, the “three sigma” rule holds. The status refers to the wall score of all grades given to a given member of the group, and expansiveness is the wall mark of all grades given to all other members of the group given to subjects.
In the process of experiments, it was supposed to confirm (or reject) the hypothesis that a neural network allows to model relationships in a group based on the psychological characteristics of people (representatives of a group) and predict whether a new member will join the group and the relationships of two individuals. It was also supposed to estimate the quality of the forecast - the possible values of errors and their distribution.
A description of the personal qualities of the subjects was supposed to be obtained on the basis of a questionnaire compiled by A.G. Kopytov (PPF KSU). The questionnaire includes three subtests, each of which is composed of questions designed to determine the constant properties of the human personality - temperament, emotionality, contact, etc. The total number of questions is 90, in the first subtest - 29, in the second - 25 and the third is 36. For the text of the questionnaires, see Appendix 3.
The data was collected by conducting simultaneous questionnaires in student study groups using the questionnaire A.G. Kopytov and sociometric research. Then the results of sociometry were processed on a specially designed program (see Appendix 2), which calculates wall assessments of status and expansiveness.
Experiments on the training of neural networks were made on the MultiNeuron v2.0 neural network simulator in the predictor mode, that is, the neural network having a real number at the output (for a detailed description see [85], [87]).
In this series of experiments it was supposed to test how neural networks are able to simulate the entry into the group of an individual.
According to the above methodology, three student groups were surveyed - of the third, fourth and fifth courses, the total number of questionnaires collected was 48 (19, 17 and 12 in groups, respectively). The results of the survey of each of the groups was composed of a problem book, which is a relational table that includes the following fields:
No - auto indexed record number, ID - test number according to the group list, w1_1 - w1_29 - answers to questions of the first subtest, w2_1 - w2_25 - answers to questions of the second subtest, w3_1 - w3_36 - answers to questions of the third subtest, to1 - to30 - ratings, exposed to these test group members (the line of the sociometric matrix), St is the value of the wall assessment of the status of the subject, Ex - expansiveness.
For the first and third subtests, for which the question had two possible answers ("Yes" / "No"), the answer was coded according to the principle 1 - "Yes", 2 - "No". The second subtest, which has three possible answers ("a", "b," c ") - 1 - option" a ", 2 -" b ", 3 -" c ".
When forming the structure of the task book, the fields w1_1 - w3_36 were designated as input, the field Ex - as output. In the process of learning, the neural network was supposed to acquire the ability to predict the status of a member of a group in response to the AG questionnaire. Kopytov.
Table 1. The results of experiments on the selection of optimal parameters of the neural network that solves the problem of predicting the status of the studied.
| №№ | Network characteristics | H select | |
| N neu | s | ||
| one | sixteen | 0.1 | 2.475 |
| 2 | sixteen | 0.4 | 2,791 |
| 3 | sixteen | 0.7 | 2,488 |
| four | 32 | 0.1 | 2.569 |
| five | 32 | 0.4 | 3,006 |
| 6 | 32 | 0.7 | 3,384 |
| 7 | 64 | 0.1 | 2,891 |
| eight | 64 | 0.4 | 2,703 |
| 9 | 64 | 0.7 | 2,676 |
At the first stage, experiments were carried out to determine the optimal parameters of a neural network designed to solve the problem of predicting the status of a member of a group. Because of the small number of samples, experiments were conducted in the “sliding testing” mode, when as many networks are trained to solve a problem as there are problems in a problem book. When training each of the networks, one task was excluded, and then the network was tested on it. To assess the quality of the prediction H, the average error modulus was used. 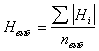 ,
,
The lower the value, the better the prediction. The results of this phase of the experiments are summarized in Table 1.
The values of the numbers of neurons - N neu - were taken from the following considerations: neural networks with fewer than 16 neurons were trained to solve the problem unstably, the optimization process constantly came to a standstill, and H select in all such experiments exceeded 3 (30% relative error). 64 is the maximum allowable value of the number of neurons for the program MultiNeuron v.2.0. The values of the characteristic numbers of neurons were distributed in the range from 0.1 to 0.7, since this interval is, according to experience accumulated in the NeuroComp group [32], [33], [34], [36], [39], [41] , [59], [84], [86], an interval in which, as a rule, the optimal characteristic numbers of neurons lie.
Thus, according to the results of this series of experiments, the number of neurons equal to 16, and the characteristic parameter of the neuron equal to 0.1 was considered optimal, since these values provide the best selective assessment of the quality of the forecast H select
The next stage of the work was a series of experiments, allowing to assess the accuracy of the prediction of the status of the studied within groups. For each of the groups, training was carried out on the networks for carrying out sliding control. Then the results of the sliding control were recorded and summarized in table. 2
Table 2. The results of experiments to establish the accuracy of the prediction of the status of the studied within groups
| No | The number of subjects | H select |
| one | nineteen | 2,587 |
| 2 | 17 | 2,854 |
| 3 | 12 | 2.475 |
However, from the experience of using neuromitters, it is known that on the same training samples the prediction produced by the network can vary significantly.
The reason for this is that the initial map of the synaptic scales is randomly generated. To overcome this problem in the practice of creating neural networks (see, for example, [36]), the prediction of responses by a group of networks trained on the same data — a consilium — is used.
It was decided to apply this method to this problem. When conducting a rolling control on the sample for each of the cases, not one neural network was trained, but ten.
The average sample values of the prediction status of each of the experts were recorded, and then the prediction error was estimated by the entire council.
To do this, as an answer to each of the sliding control tasks, the average value of the responses of ten neural networks - experts was fed. The results of this experiment are presented in Table. 3
Table 3. Estimates of the errors in predicting the status of the groups studied by consilium networks.
| N isl | H 1 | H 2 | H 3 | H 4 | H 5 | H 6 | H 7 | H 8 | H 9 | H 10 | H cf | H select |
| nineteen | 3.02 | 3.68 | 3.88 | 4.13 | 3.14 | 3.38 | 4.09 | 3.46 | 2.82 | 3.32 | 3.49 | 2.83 |
| 17 | 3.32 | 4.80 | 4.33 | 4.50 | 4.46 | 3.15 | 3.72 | 4.31 | 3.20 | 4.51 | 4.03 | 3.84 |
| 12 | 2.20 | 2.68 | 3.23 | 2.59 | 3.86 | 2.96 | 2.82 | 3.28 | 3.52 | 2.58 | 2.97 | 2.41 |
Here N isl - the number of people studied in this group, H 1 - H 10 - average status prediction errors for each of the consilium networks, H cf - the average error value over all consilium networks, H select - the prediction error of the whole consilium.
Thus, in three groups the average error modulus is 3.08 (or, in relative numbers, the average error is 30.8%).
Such an error is satisfactory for the task of predicting the status of group members, since, as a rule, it does not remove the subject from the classification groups - “leader” - “middle peasant” - “outsider”, that is, reflects the tendency of the new person to join the group.
In addition, in a statistical study of experimental samples, the average distance was calculated 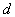 between random estimates
between random estimates 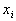 and
and 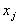
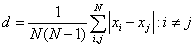 ,
,where N is the number of sample elements.
We can assume that characterizes the expectation of the distance between two random samples of the sample.
For experiments establishing the status of the test in the group 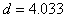 or 40.33%. Thus, it can be argued that the error obtained by the network (30.8%) is significantly different from the random error.
or 40.33%. Thus, it can be argued that the error obtained by the network (30.8%) is significantly different from the random error.
The next series of experiments was carried out in order to clarify how much one can predict the results of joining one group based on experience gained by the network in another group.
During the experiments, a consilium of ten neural networks was trained for each of the groups (their characteristics, as in the previous experiments, N neu = 16, s = 0.1). Here the task book was submitted for training in full, that is, the network was trained to predict the status of all members of the group. Then on the networks of this consultation two other groups were tested.
For smoothing the randomness factor in the generation of networks, the calculated values for the estimation of the status determination error were taken for each estimate of the average values from those calculated by the ten consilium networks. The results of this series of experiments are presented in table. four.
Table 4. Cross-Testing Results
| About. | TST | H 1 | H 2 | H 3 | H 4 | H 5 | H 6 | H 7 | H 8 | H 9 | H 10 | H cf | H select |
| one | 2 | 1.87 | 3.96 | 2.85 | 3.65 | 4.62 | 1.82 | 2.82 | 1.97 | 1.77 | 4.32 | 2.97 | 2.48 |
| one | 3 | 2.26 | 3.98 | 3.58 | 3.61 | 2.36 | 2.46 | 3.64 | 2.16 | 2.55 | 3.11 | 2.97 | 1.79 |
| 2 | one | 4.31 | 4.03 | 3.92 | 3.48 | 4.17 | 3.66 | 3.83 | 4.33 | 4.03 | 3.78 | 3.95 | 3.5 |
| 2 | 3 | 3.82 | 1.81 | 2.91 | 3.43 | 2.75 | 3.13 | 3.08 | 2.53 | 2.57 | 3.06 | 2.91 | 2.05 |
| 3 | one | 3.4 | 4.09 | 3.21 | 2.91 | 2.76 | 3.65 | 3.03 | 2.56 | 2.89 | 3.51 | 3.20 | 2.79 |
| 3 | 2 | 3.60 | 3.28 | 3.72 | 2.94 | 4.24 | 4.30 | 3.91 | 4.35 | 3.60 | 4.13 | 3.81 | 3.77 |
Here About. - the ordinal number of the group for which the neural networks of the consultation were trained, Tst. - The sequence number of the group for which networks were tested.
When analyzing this series of experiments, the following patterns are noticeable:
- the prediction of the social status of the subjects by neural networks trained in other groups (not according to those in which the status was determined during a sociometric survey) is somewhat worse in its quality than the same prediction made by neural networks trained in the same group;
- however, in most cases (in two thirds of the experiments performed), the quality assessment (average error modulus H of choice ) is acceptable (less than 3 points or, in relative values, less than 30%);
- it is clearly seen how the principle of creating reliable systems from unreliable elements, embedded in the concept of neural networks, is implemented when predicting the status of subjects in groups: a single neural network prediction error can be an unacceptably large amount, but a council of several neural networks solves the problem much better - a prediction error of a council of networks less than most of the errors of individual networks, it is also always less than the average of the errors of individual networks of the council.
After assessing the quality of the prediction between the groups, it was decided to test the hypothesis that the neural network can accumulate experience not only for a particular group, but also accumulate it for any given sequence of subjects. To test the hypothesis, the following series of experiments was undertaken: the data for all the groups were combined into one task book for which a sliding test was conducted by a consultation of ten expert networks. The results of this series of 480 experiments are presented in Table. five.
Table 5. Testing results of consultations of networks trained on the full sample.
| Expert number | H select |
| one | 3.02 |
| 2 | 2.56 |
| 3 | 2.88 |
| four | 3.04 |
| five | 2.94 |
| 6 | 2.88 |
| 7 | 2.74 |
| eight | 2.46 |
| 9 | 2.59 |
| ten | 3.12 |
| All consilium | 2.32 |
It can be seen that, as in the previous series of experiments, the error of each expert (and, at a minimum, the mathematical expectation of error) is higher than the error of the consultation, that is, the mathematical expectation of estimates for the consultation of networks is always (or rather, in most cases) closer to the correct answer than the estimates of individual experts.
In addition, it is easy to see that the prediction of the status of the subjects studied in the group improves with the accumulation of the sample — the estimate of the prediction error made by neural networks trained in the combined sample is better than in any other experiments.
In other words, neural networks have the ability to accumulate the experience of predicting the sociometric status of the subjects studied in a group, and this experience is not local — the skill gained on the studied ones of the same group is significant for the evaluation of the subjects belonging to other groups.
This result confirms the thesis given in [98] that the estimates of peers in the group are stable and, apparently, they are not affected by a change in the composition of the group.
The reason for this phenomenon, presumably, is that when predicting the status of the subjects, information about them is significantly limited - there is no history data, no data about their social status.
This practically excludes information on appearance, belonging to a socio-cultural or national group — that is, the entire social history of the individual and the collective as a whole, although it is known that these factors can cause a significant difference in the behavior of people with a similar personality type.
The information about constant psychological qualities of the subjects is relatively homogeneous from group to group, which allows the neural network to accumulate experience based on it.
The next stage of work on the prediction of the status of subjects in groups was to determine the significance of the questionnaire questions and exclude the least significant questions from it.
According to the results of Chapter 2, this may lead to an improvement in the quality of the forecast issued by the neural network. To solve this problem, the possibility of calculating the significance of the parameters incorporated in the MultiNeuron was used.
Five neural networks were trained on the basis of a problem book, including all three groups of subjects, then using MultiNeuron, numerical values of the significance of the signals corresponding to the questions of the questionnaire were determined.
After that, the list of questions was sorted by the mean value of significance. As a result, the following picture was obtained (questions are placed in descending order of importance):
1_6. Do you usually talk without hesitation?
1_23. Do you usually prefer to do simple things that do not require much energy from you?
1_7. Can you easily find other solutions to a known problem?
3_24. The hardest thing for you is to deal with yourself.
3_28. You tend to take things too close to your heart.
3_22. You can easily bring the animation to a rather boring company.
1_2. Is it easy for you to do work that requires long-term attention and great concentration?
1_1. Do you easily generate work-related ideas?
3_10. You have repeatedly noticed that strangers look at you critically.
3_8. Sometimes you have lost or lost voice, even if you do not have a cold.
2_3. Others know that I have a lot of different ideas, and I can almost always offer some kind of solution to the problem.
1_19. Do you usually prefer light work?
1_27. Do you sometimes shake hands during an argument?
3_20. Some like to command so much that you want to do everything in defiance, although you know that they are right.
2_25. It happens that I tell strangers about things that seem important to me, regardless of whether they ask me or not.
2_19. If the bosses or family members reproach me for something, then, as a rule, only for the cause
3_3. Forebodings always make excuses
2_24. I usually calmly endure complacent people, even when they brag or otherwise show that they have a high opinion of themselves.
2_11. Outdated law should be changed
3_29. Do you like to cook (food)
3_35. You kept a diary.
1_8. Are you ever late for a date or work?
2_5. To birthday, to holidays (I like to make presents / find it difficult to answer / I think that buying gifts is a somewhat unpleasant duty)
1_9. Do you often can't sleep because of arguing with friends?
2_21. With equal length of the day, it would be more interesting for me to work (carpenter or cook / I don’t know what to choose / as a waiter in a good restaurant)
1_3. Do you feel anxious about being misunderstood in conversation?
1_5. Do you have fast arm movements?
3_4. You are very often not aware of the affairs and interests of the people around you.
1_28. Do you have a craving for intense responsible activities?
3_7. Do you like April Fool's jokes?
1_17. Is it difficult for you to speak very quickly?
1_15. Would you always pay for transporting baggage if you were not afraid of checking?
3_25. At times, you like the agility of a criminal so much that you hope that he will not be caught.
1_10. Do you like to run fast?
3_33. Your parents and other family members often find fault with you.
2_2. I have such exciting dreams that I wake up
3_18. You do a lot of things that you regret later (more and more often than others)
2_10. I think it is more correct to say about me that I am (polite and calm / something in between / energetic and energetic)
3_34. At times when you feel bad, you are irritable.
3_12. Do you usually stay “in the shadows” at parties or in companies?
1_20. Are your movements slow when you do something?
3_2. Sometimes you really wanted to leave home forever.
3_31. You try to avoid conflicts and difficult situations.
3_16. Sometimes for several days you can not get rid of any trifling thoughts.
3_11. You know who is to blame for the majority of your troubles.
1_21. Do you usually prefer to perform only one operation?
1_18. Do you sometimes shake hands during an argument?
1_14. Are all your habits good and desirable?
3_14. Not all of your friends you like.
3_15. Do you prefer to have less buddies, but especially close to you.
3_13. Sometimes you are not inferior to people, not because the case is really important, but simply out of principle.
3_26. If you are not threatened with a fine, then you cross the street where you are comfortable, and not where it should be.
2_7. I like a variety of work related to frequent changes and travel, even if it is a bit dangerous
1_29. Do you like to talk fast?
3_9. It is embarrassing for you to enter the room where people have already gathered and are talking.
2_20. It happens that I tell strangers about things that seem important to me, regardless of whether they ask me or not.
3_21. You prefer not to talk to people until they themselves turn to you.
3_23. When you learn about the successes of a close friend, you get the feeling that you are a loser.
1_24. Do you suck under the spoon before a responsible conversation?
2_14. I enjoy doing risky things just for fun.
3_6. Sometimes it comes to mind that it is better not to tell anyone about them.
2_13. Sometimes an obsessive thought keeps me awake
2_8. I would prefer to have a cottage (in a lively holiday village / would prefer something in between / in a forest)
2_1. Do I prefer uncomplicated classical music to contemporary popular melodies?
2_22. When I try to command me, I purposely do the opposite.
3_17. You often worry about anything.
1_22. Does it ever happen that you talk about things that you don’t understand?
1_16. . Do you usually find it difficult to shift attention from one case to another?
2_4. I have such exciting dreams that I wake up
1_11. Do you have a constant thirst for activity?
3_19. At a party, you hold your desk better than at home.
3_36. You are easily embarrassed.
3_30. You do not judge the one who seeks to take from life everything that he can.
2_16. If I worked in the economic sphere, I would be more interesting
1_25. Do you consider your movements slow and unhurried?
3_32. Do you deal with the case better by thinking about it yourself, rather than discussing it with others.
2_12. If someone got mad at me (I would try to calm him down / I don’t know what I would do / it would irritate me)
1_12. Do you read aloud quickly?
3_5. Sometimes you insist on something that people lose patience.
2_18. I can usually work with concentration, not paying attention to the fact that people around me are very noisy
1_26. Is your speech usually slow and unhurried?
2_17. An evening spent with my hobby attracts me more than a lively party
2_15. I make harsh criticisms to people if it seems to me that they deserve
1_4. Do you like games at a fast pace?
1_13. If you promised to do something, do you always keep your promise whether it is convenient for you or not?
2_9. I spend a lot of free time, talking with friends about those previous events that we experienced together once.
2_6. Sometimes I have been upset over the fact that people spoke ill of me about my eyes for no reason.
3_27. You often experience new impressions, to shake things up, to experience excitement.
2_23. People treat me less favorably than I deserve by my kind attitude towards them.
3_1. Do you often go to the other side of the street to avoid meeting someone you know?
To determine the significance of the test subtests, the average significance was calculated for the questions of each of them. Subtests were distributed in the following order: the most significant - the 1st, then - the 3rd and the least significant - the 2nd. This distribution can be illustrated with a histogram (Fig. 1). To construct this histogram, all questions, sorted in descending order of importance, were divided into nine dozen, and then for each of them the number of questions belonging to the first, second and third subtests was calculated.
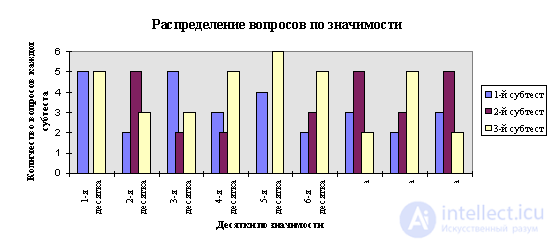
Fig. 1. Diagram of the distribution of test questions according to their significance for predicting the status of subjects.
For questions of the first subtest, the excess of distribution is visible in the direction of greater importance, the second in the direction of the lesser, and the questions of the third are relatively evenly distributed throughout the interval.
A series of experiments was carried out in order to find out the questionnaire volume sufficient for the neural network. At each stage, half of the questionnaire questions were excluded.
With the exclusion of half of the questions, the moving control of a consilium of networks trained on a sample for all groups gave an average error of 24%, with the exclusion of three-quarters of questions — in 28% and finally, with the exclusion of seven-eighths, neural networks could not learn.
Thus, about half of the questions from the initially minimized test turned out to be excessive for the neural network, even leading to a deterioration in the prediction quality assessment. The best question is a questionnaire out of half the questions that are maximal in importance for the neural network, since the test results are better for it than for all other options, including the full set of questions.
The difference between the initial (given by the psychologist) and the required neural network for the successful solution of the problem by the volume of the questionnaire can be estimated from the standpoint of information theory [95].
The initial amount of information contained in the test can be estimated based on the fact that the questions of the first and third tests are binary (the answer options are “Yes” and “No”, the probability of each occurring is 0.5), and the answers to the questions of the second can with equal probability correspond to the onset of one of three events that we will consider equally probable (answer choices "A", "B" and "C", p = 0.333). Then, based on the Shannon formula
and taking into account that the number of questions in the first subtest is 29, in the second 25 and in the third 36 we can calculate the total amount of information contained in the answers to the test question:
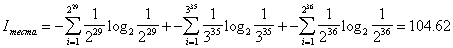 .
.After excluding half of the questions because of their low importance for the neural network, in the optimized questionnaire there are 16 questions left of the first subtest, 9 the second and 20 the third. Amount of information remaining after optimization:
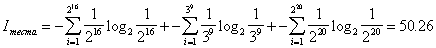 ,
,that is, the amount of information during optimization has been reduced somewhat more than twice.
In this series of experiments, it was supposed to establish whether the neural networks are able to reproduce the relationship between a pair of subjects.
The training samples had the following structure: № - example number, ID_From - evaluator number, ID_From - evaluator name, ID_To - estimated number, Name_To - evaluator name, w1_1_From - w3_36_From - answers to the questionnaire A.G. Kopytova, data evaluating, w1_1_To - w3_36_To - answers to the questions of the questionnaire A.G. Kopytov, data estimated, Ocen - this assessment.
The task book included lines corresponding to all cells of the sociometric matrix except the diagonal ones, which are responsible for the self-assessment of the subjects.
A task book was created for the 5th year group. It includes 132 examples for which the corresponding number of networks were trained using the sliding control method.
By virtue of the large laboriousness of the task of training for sampling of such volume and dimension (training of one network takes about 40 minutes) training of
продолжение следует...
Часть 1 Imitation of psychological intuition using artificial neural networks
Часть 2 1.7 Neural networks - Imitation of psychological intuition using artificial
Часть 3 Chapter 3. Intuitive Neural Network Prediction of Relationships - Imitation
Часть 4 LITERATURE - Imitation of psychological intuition using artificial neural networks

Comments
To leave a comment
Mathematical Methods in Psychology
Terms: Mathematical Methods in Psychology