Lecture
Content analysis (from the English. Contens content) - a method of qualitative and quantitative analysis of the content of documents in order to identify or measure various facts and trends reflected in these documents. The peculiarity of content analysis is that it examines documents in their social context. It can be used as the main research method (for example, content analysis of the text in the study of the political orientation of the newspaper), parallel, i.e. in combination with other methods (for example, in the study of the effectiveness of the functioning of the media), auxiliary or control (for example, when classifying answers to open-ended questionnaires).
Not all documents can be subject to content analysis. It is necessary that the analyzed content allows you to specify an unambiguous rule for reliable recording of the desired characteristics (the principle of formalization), as well as that the content of interest to the researcher meets with sufficient frequency (the principle of statistical significance). Most often, the objects of the content analysis study are press reports, radio, television, meeting minutes, letters, orders, orders, etc., as well as data from free interviews and open questions from questionnaires. The main directions of application of content analysis are: identifying what existed before the text and what was reflected in it in one way or another (text as an indicator of certain aspects of the object being studied - surrounding reality, author or addressee); the definition of what exists only in the text as such (various characteristics of the form — language, structure, genre of the message, rhythm and tone of speech); identifying what will exist after the text, i.e. after his perception by the addressee (evaluation of various effects of exposure).
There are several stages in the development and practical application of content analysis. After the topic, tasks and research hypotheses are formulated, the categories of analysis are determined - the most general, key concepts that correspond to the research tasks. The system of categories plays the role of questions in the questionnaire and indicates which answers should be found in the text. In the practice of domestic content analysis, a fairly stable system of categories has emerged - a sign, goals, values, a theme, a hero, an author, a genre, etc. The content analysis of mass media messages based on the paradigmatic approach, according to which the studied signs of texts (the content of the problem, the reasons for its occurrence, the problem-forming subject, the degree of tension of the problem, the ways to solve it, etc.) are considered as a certain organized structure.
Content analysis categories should be exhaustive (cover all parts of the content determined by the objectives of this study), mutually exclusive (the same parts should not belong to different categories), reliable (there should be no disagreement between coders on which parts of the content to one category or another) and relevant (to meet the task and the studied content). When choosing categories for content analysis, one should avoid extremes: choosing too numerous and fractional categories, almost repeating the text, and choosing too large categories, because This may lead to a simplified, superficial analysis. Sometimes it is necessary to take into account the missing elements of the text, which may be significant for content analysis.
After the categories are formulated, it is necessary to select the appropriate unit of analysis - the linguistic unit of speech or the element of content that serves in the text as an indicator of phenomena of interest to the researcher. In the practice of domestic content-analytical studies, the most commonly used units of analysis are a word, a simple sentence, a judgment, a topic, an author, a hero, a social situation, a message in general, etc. Complicated types of content analysis usually operate not with one, but with several units of analysis. The units of analysis taken in isolation may not always be correctly interpreted, so they are considered against the background of broader linguistic or meaningful structures indicating the character of the division of the text, within which the presence or absence of units of analysis is identified - contextual units. For example, for the unit of analysis “word” the contextual unit is “sentence”. Finally, it is necessary to establish a unit of account - a quantitative measure of the relationship between textual and extra-textual phenomena. The most common units of account are time-space (number of lines, square centimeters, minutes, broadcast time, etc.), the appearance of signs in the text, the frequency of their appearance (intensity).
What is important is the choice of the necessary sources subjected to content analysis. The sampling problem comprises the choice of the source, the number of messages, the date of the message and the content to be examined. All these sampling parameters are determined by the objectives and scope of the study. Most often, content analysis is carried out on a one-year sample: if this is the study of meeting minutes, then 12 minutes are enough (by the number of months), if the study of media reports is 12–16 numbers of a newspaper or of radio and radio. Typically, a sample of media messages is 200–600 texts.
A prerequisite is the development of a content analysis table - the main working paper with which the research is conducted. The type of the table is determined by the research stage. For example, when developing a categorical apparatus, the analyst creates a table, which is a system of coordinated and subordinated categories of analysis. Such a table outwardly resembles a questionnaire: each category (question) implies a number of signs (answers), according to which the text content is quantified. For the registration of units of analysis, another table is compiled - a coding matrix. If the sample size is large enough (over 100 units), then the encoder, as a rule, works with a notebook of such matrix sheets. If the sample is small (up to 100 units), then a two-dimensional or multi-dimensional analysis can be performed. In this case, each text must have its own coding matrix. This work is laborious and laborious; therefore, with large sample sizes, the comparison of the signs of interest to the researcher is carried out on a computer.
An important condition for content analysis is the development of instructions for the encoder - a system of rules and explanations for who will collect empirical information by coding (registering) the specified units of analysis. The instructions accurately and unambiguously set out the algorithm for the coder’s actions, give operational definitions of categories and units of analysis, rules for coding them, give specific examples from the texts that are the object of research, stipulate how to proceed in controversial cases, etc. The counting procedure for quantitative content analysis in general is similar to the standard classification techniques for the selected grouping ranking and association measurement. There are also special counting procedures applied to content analysis, for example, the formula of the Janis coefficient, designed to calculate the ratio of positive and negative (relative to the chosen position) estimates, judgments, arguments. In the case when the number of positive ratings exceeds the number of negative,
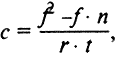
where f is the number of positive ratings; n is the number of negative ratings; r - the volume of the content of the text that is directly related to the problem under study; t - the total amount of the analyzed text. In the case when the number of positive ratings is less than negative,
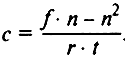
There are more simple ways to measure. The specific weight of a particular category can be calculated using the formula K = the number of units of analysis, fixing this category / total number of units of analysis.
Sources:

Comments
To leave a comment
Mathematical Methods in Psychology
Terms: Mathematical Methods in Psychology