Lecture
The manual contains information on one of the main aspects of the development of psychodiagnostic methods, namely, means of monitoring the reliability and validity of tests. Knowledge of the principles of construction and properties of the test as a research tool are of particular importance in the professional training of psychologists. Thanks to them, scientifically based use of psychodiagnostic methods and qualified interpretation of the data obtained with their help are provided. Together with a detailed interpretation of the indicators of validity and reliability Data are presented on some of the second fundamental characteristics of psychological tests.
The manual contains information on one of the main aspects of the development of psychodiagnostic methods, namely, means of monitoring the reliability and validity of tests. Knowledge of the principles of construction and qualities of the test as a research tool are of particular importance in the professional training of psychologists. Thanks to them, a scientifically based use of psychodiagnostic methods and a qualified interpretation of the data obtained with their help is ensured. At the same time, with a detailed interpretation of the indicators of validity and reliability, some other important characteristics of psychological tests are presented.
The manual is focused on the in-depth study of the course “Psychological Diagnostics” for students of the specialties “Psychology”, “Sociology” and “Teacher-Researcher” and may be useful for specialists who use psychological tests or psychodiagnostic information in their work, as well as for anyone interested. problems of measuring human personality.
Reviewers: V.A. Romanets, Acad. APS of Ukraine
N. N. Kornev, prof., Dr. Psychol. of science
content
Introduction
1. Reliability of psychological tests and methods for its determination
1.1. Determination of reliability as an indicator of the quality of a psychological test
1.2. Measurement accuracy and test reliability
1.3. Methods for determining the reliability of psychological tests
1.3.1. retest reliability
1.3.2. Reliability of parallel forms
1.3.3. The reliability of the parts of the test
1.4. Determination of the reliability of projective tests
2. The validity of the psychological test
2.1. content validity
2.2. empirical validity
2.2.1. validation criterion
2.2.2. initial validity
2.2.3. constructive validity
2.3. validity coefficients
2.4. obvious validity
2.5. The validity of projective tests
3. Internal consistency of test assignments
4. Discrimination of test assignments
5. Indicators of test severity
bibliography
Introduction
Practical psychodiagnosis refers to the leading branches of applied psychology; its goal is to develop tools for building and using methods for measuring personal qualities, ranking its properties, identifying the main features, psychological characteristics, features of mental processes, states, etc. This branch of psychology is almost the oldest tradition in the history of scientific psychology. Due to the development of psychological diagnostics over the past decades, many areas of psychological examination of the personality have been developed, new test procedures have emerged that are focused on an in-depth study of the structures and components of individuality. The main directions of the use of psychological tests in public practice are the areas of training, education and training, as well as the industry, medicine.
The widespread use of tools for measuring psychological individuality necessitates the training of qualified specialists in this specialty. The psychological test is an extremely complex research procedure. Only a specialist of the relevant profile can carry out scientifically grounded conclusions, an adequate analysis of psychodiagnostic information. Among the necessary special knowledge of the psychologist-diagnostician, the leading place belongs to knowledge of the theory and practice of controlling the diagnostic properties of existing and first developed test methods. Information on reliability, validity, limits of use, the effect of different conditions of the survey must necessarily include the use of a particular test. Knowledge of the essence of psychological indicators, what exactly the test measures and how well it does, allows not only mechanically to follow the instructions of the developers of the methodology, but to be conscious about the diagnosis.
The need for complex preparatory work prior to the practical use of the test was emphasized by the authors of the first psychometric procedures. The need for special psychometric training of a research specialist was especially emphasized. In this regard, it is advisable, in our opinion, to quote A. Schubert from the preface to the translation into Russian of the scale for the study of the mental development of the child of Binet-Simon: "... The apparent simplicity of the method often leads to great abuse, which Stern ironically called" binetization ". The work of which published in Germany in 1911, in which it is recommended to introduce the use of a scale in troops, serves as an extreme example of such a task, entrusts the study to non-commissioned officers. Any psychological research requires both sufficient psychological knowledge and experimental experience ... Using this method, Binet said, beware of all mechanization: “These are not scales on which everyone can weigh in a penny” (A. Schubert, 1927. - С 9-10).
This manual examines the structure of the reliability and validity of the psychological test, the basic means of determining them, the types of indicators that reflect these psychodiagnostic characteristics of tests. At the same time, an in-depth analysis of the reliability and validity of psychological procedures provides information on other main categories of monitoring the diagnostic quality of certain types of psychological tests (internal consistency, discriminative tasks, analysis of subjective difficulties in solving individual problems, moderators, test usage limits).
Reliability (in the English-language psychological literature, the term “reliability” is equivalent) is a characteristic of the psychodiagnostic method, reflects the degree of accuracy of measurements carried out using this test, as well as the stability of the test results regarding the influence of extraneous random factors that are not objects of research. As evidenced by US standards for developing educational and psychological tests (Standards for Educational and Psychological Tests), reliability and validity are the most important characteristics of the methodology as a tool for psychodiagnostic research.
The result of psychological research is usually influenced by a huge number of unaccounted factors. For example, the state of the emotional sphere, the degree of fatigue of the subject, the motivational focus on research on the part of his subject, if these indicators are not included in the circle of specially tested subjects, as well as such random factors as indoor lighting, temperature and humidity, noise level, hour of the day and many others. Any change in the research situation enhances the influence of some or weakens the action of others. In the aggregate, the influence of unaccounted factors leads to scattering (dispersion) of the results of psychological measurement. The total dispersion of the results of a test survey can thus be considered the result of the influence of two categories of factors: the variability of the measured psychological phenomenon itself, personality traits, intelligence, etc. and instability of the measurement procedure itself.
In a broad sense, test reliability is an indicator of how much differences in test subjects are found in test subjects, which is a reflection of the present difference in measured psychological properties, and vice versa, to what extent they may be due to random errors and artifacts.
In a narrower sense, the concept of reliability, directly related to methods for determining the stability of test indicators, is reliability as a measure of the consistency of test results obtained during the initial and subsequent use of it for the same subjects at different points in time, or using different (but such which can be compared according to the results of sets of test tasks or under some other changes in the conditions of the study.
The distribution of assessments that have members of the sample for performing a test that measures any one psychological characteristic ideally coincides theoretically with the normal distribution. In this case, the variance can be considered as “pre-dark” (that is, such that reflects the variability of only the indicator that is being studied). Each test subject has its own place, which is determined by the test score, and theoretically this place is stable for each test subject from the sample. In this case, when you repeat the test with the same persons, we will observe the distribution of seats on the rating scale, identical to the previous one. Then the technique, as a tool for measuring a given psychological factor, is considered accurate and as reliable as possible. In actual circumstances, the grades and ranking of the subjects for each subsequent study may vary and the distribution of the ranking places to varying degrees from the primary. So, the dispersion of the new distribution is really higher than the “true” by the value of the variance of the measurement error. All this can be represented as a formula that characterizes reliability as the ratio of “true” to real (empirical) variance:
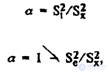
where a is the reliability of the test; S 2 t is the “true” variance; S 2 e is the error variance; S 2 x - empirical variance of test scores.
As you can see, the reliability of the test is closely related to the measurement error used to determine the range of possible fluctuations of the measured value under the influence of random and side factors. Size S 2 t / S 2 x acts as the main indicator of the reliability and stability of measurements and is called the test reliability coefficient (r t).
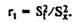
The measurement error is inversely related to the ratio of the confidence index (the wider the range of values in which the result of a certain experimental test is supposed to be recorded, the lower the measurement accuracy). The relative proportion of the variance of the error is easy, based on the equation
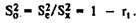
In most methods used in practice, it is rarely possible to achieve such safety factors that exceed the value of 0.7-0.8. At r t = 0.8, the relative proportion of the standard error of measurement is 0.45 = √ (1 - 0.8), and the empirical value of the deviation of the test score from its average value is overestimated. For the correction of empirical values in practical studies using the equation
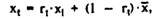
where x t - reliable value of the test score; X 1 - the empirical score of the test; r t is the reliability coefficient; x - the average value of the test scores.
For example, in the test subject, on a Wechsler scale, the assessment of the verbal IQ indicator is 107 points. The average value for the scale is 100, the reliability r t = 0.89. The likely value of x t will be, points:
X t = 0.89 * 107 + 0.11 * 100 = 106.2.
Of particular importance for the correct interpretation of test scores and given its reliability is the measure of measurement error. Let us dwell on the disclosure of the essence of this criterion.
Measurement error is a statistical indicator reflecting the degree of accuracy of specific measurements in the sample.
When conducting empirical psychological research, it is almost never possible to achieve complete coincidence of the values of measured parameters in various series of experiments, even when using a sample consisting of the same subjects. Of course, the value of the measured indicator fluctuates within certain limits. For example, repeatedly repeating the test to identify common abilities in the same child, you can find that the scores vary in a certain interval - say, from 108 to 115 points. Similarly, when re-analyzing one or more samples, the mean value (x) is also distributed in the interval on the x-axis.
Variations in the measurement results in a specific range of values may be due to systematic or random factors. The category of factors causing systematic errors can include, in particular, some kind of constant and equal deviation from the test standard used by a particular researcher, inaccuracies in the procedure of processing primary information (for example, technical errors in the “keys”), etc. In these cases, the measurement results differ from the true ones by a more or less constant value. Random errors arise from a variety of - objective or subjective - causes. The magnitude of random errors and characterizes mainly the accuracy of the method.
With a large number of observations, individual estimates or their average values form their distribution, the statistical indicators of which reflect the measurement error characteristic of. this method.
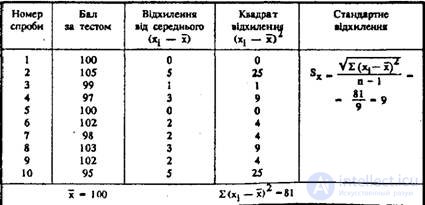
Measurement error is a statistical phenomenon, in the determination of which a role is played by regularities inherent in the law of normal distribution. Due to random errors, which depend on a huge number of different factors influencing the final result, the distribution of empirical estimates and their average for repeated observations has the form of a normal law. Based on the basic properties of the normal distribution, it can be calculated that approximately 68% of measurements are located in the range of ± σ, about 95% are in the range of ± 2σ, and 99% are in the range of ± 2.5σ distribution of the values of repeated observations. Thus, in order to establish within what limits and with what predetermined probability the real estimate will be, it is necessary to determine the standard deviation of such a distribution. In tab. 1 shows the data of a tenfold examination of one test subject using a general ability test. Standard deviation
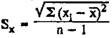
in this case is 3; it follows that with a probability of P = 0.05 (95% of the total number of measurements), it is possible to hope that a reliable value of the indicator will be within the range of 100 ± 6 points, or from 94 to 106 points on the scale of this test (average value of the measured indicator is 100).
Table 1. The distribution of the measurement error of the total test on the scale of Wexler
The reliability of the test can be defined as the standard error of measurement (σ m), which is also called standard error. In the case of the interpretation of individual indicators, this measure is more useful than the reliability coefficient (r t). Based on the reliability coefficient, the standard measurement error is determined by the formula
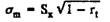
where S x - the standard deviation of the test results in the sample; r t is the reliability coefficient determined for the same sample.
An important aspect of using the measurement error criterion in psychological diagnostics is the assessment of the reliability of the method and the probability of error in analyzing and interpreting the differences between the data in the subjects. Presentation of the results in the form of interval possible values cautions against erroneous interpretation of different results as a reflection of the real dynamics of the measured property in experimental subjects, as well as an erroneous interpretation of the differences between the averages in the samples that are compared.
When comparing test scores - if there is information about standard error rates for one and the other tests (or subtests) - the standard error of the discrepancy can be defined as
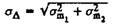
or the same with the reliability factor:
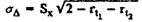
where S x is the standard deviation, in this case the same for the two tests.
To illustrate the above, we give an example. Suppose we need to make sure that a particular test subject has a discrepancy in the estimates of verbal and practical subtests on the Wechsler scale, or the difference in data may be related to measurement error. It is known that for D. Wexler's intelligence measurement scale, the r t value of verbal subtests is 0.96, the practical value is 0.93; the standard deviation value for both scales is 15. Then
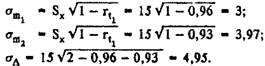
Thus, to establish the difference with a probability of 68%, a difference in the estimates is required (which will indicate a discrepancy in the results) of approximately 5 points. With a standard probability of P 0.05, the accepted limit for psychological research, the value of σ d is multiplied by 2 and we get about 10 points. In other words, if in the experimental one the score on the verbal scale is 105, and on the practical one - 115 points, then a hundredfold repetition of the study only 5 times is likely to happen that the scores on the scales will be the same. This will be enough for an assertion: a specific test subject can cope with the verbal tasks of the test better than with practical ones. If the difference in points is less than 10, such a statement will be considered unreliable.
Apparently, it is necessary to recognize that none of the existing psychodiagnostic procedures is ideal in terms of its reliability. The reliability of the test can vary significantly in the case of seemingly insignificant variations in test conditions, changes in the nature of test items, and also depending on the degree of complexity of the tasks for the test subject. The standard complex of information about psychodiagnostic methods has, of course, information about certain reliability indicators, but it is almost impossible to calculate or determine the criteria of the result stability for one case of using one or another test.
The reliability characteristics, determined empirically, are greatly influenced by the nature of the sample, which is used to test the test for reliability indicators. Of particular importance here is the range of discrepancies in the estimates, more precisely in the ranking places of the experimental groups or their groups in the total sample. So, if the assessments of the subjects are localized in a relatively narrow range of values and will be close to each other, it is to be hoped that in the case of repeated research, these assessments will also be located in a dense homogeneous group. Possible changes in the ranking of individual subjects will be externally insignificant. The reliability factor in this case will be overestimated. The same groundless overestimate of coefficients may occur in the case of reliability analysis, carried out on the sample material, which consists of contrasting groups, for example, individuals who have the highest and lowest test scores. Then these distant ones do not overlap due to random factors.
In practical psychodiagnostics when developing guidelines and methodological materials for a test, the nature of the groups for which reliability indicators were determined is of course determined. Reliability indices are often calculated for contingents of subjects, which differ in gender, age, level of education, specialty, etc. In some cases, reliability indicators are calculated separately and for high and low test scores.
The variety of characteristics and reliability indicators of the test is as great as the variety of conditions that can affect the test result. In the still widely practical application received several methods characteristics of reliability. this:
Retest reliability is a means of determining the reliability of the psi method of diagnosis, in which the accuracy and stability of the results are determined by repeated research. Reliability in this case is established as a measure of the coincidence of the results of the first and repeated surveys or as the degree of safety of the ranking places surveyed in the sample by retest. The reliability coefficient r t is equal to the correlation coefficient between the data of such surveys. If a quantitative interval scale is used in the test for measuring psychological properties, then the Pearson correlation coefficient can be used in determining the results. For ordinal scales as a measure of the sustainability of the results when peretestuvanni, you can use the Spearman or Kendel rank correlation coefficient.
In determining the indicator of retest reliability, the choice of the retest interval, that is, the time that passes between the primary and the next experiment, is of particular importance. It is quite natural that with an increase in this interval, the indicators of correlation between these studies acquire a tendency to decrease. After the passage of a considerable amount of time for the retest, the likelihood of side effects increases significantly; the consequences of quite regular age-related changes in psychological properties measured by the test may also turn out to be certain events that affect the state and characteristics of the development of the studied psychological properties. For this reason, when determining retest reliability, they try to establish not very long time intervals (up to several months). In determining the reliability of techniques
used for examination of young children, such intervals should be even less due to the fact that in this group of subjects age changes of most of the psychological properties of the personality are carried out more intensively. Despite this tendency, when determining the quality of the test, repeated tests are conducted with a significant retest interval, which may be several years. This procedure is used to assess not so much retest reliability, as to determine the prognostic validity, elements of construct validity, especially those related to the so-called differentiation of test scores by age criterion.
These indicators will be discussed in subsequent chapters of the manual.
By definition, retest reliability, then, of course, is limited to the analysis of short-term random changes in the results, which characterize the test as a measuring procedure. Interval retest is selected only on the basis of determining the dynamics of the sustainability of the result of the technique for a certain time. Despite the apparent simplicity of determining retest reliability as a principle of analyzing the stability of test indicators, this method has significant drawbacks. We describe the most significant of them.
Repeated use of the same tasks, especially in a relatively short retest interval, makes it possible for experimental subjects to develop skills for working with this psychodiagnostic method. Improvement of indicators under the influence of the results that arise will differ in the degree of manifestation in individual subjects. individual characteristics .. This will lead to a noticeable change in the ranking places of individual subjects and, respectively, to an artificial decrease in the reliability coefficient. A certain influence on the results of the reliability analysis results in individuals remembering individual decisions or answers. In this case, the person reflects the preliminary distribution of correct and erroneous decisions in the re-study. For this reason, the results of both test cases will not be independent of each other, the correlation index between them will be artificial overpriced.
One of the ways to reduce the influence of the training factor on the assessment of retest reliability may be the preliminary formation of a stable skill to work with this method. But with this approach, the number of repetitions of the test will inevitably increase, which will lead to an increase in the number of solutions that are remembered by the test subject. Such measures can be recommended only for methods such as speed tests (speed test), consisting of a large number of seemingly identical tasks.
For other methods, the only acceptable way to reduce the effect of training is to increase the retest interval. However, as mentioned, an increase in this interval is in conflict with the definition of reliability as characteristics of the test, and not as a measure of the stability of the psychological construct itself.
Most tests of general abilities are characterized by a gradual improvement in retest reliability in senior contingents of subjects. This is a result of careful control of the test conditions, of course, easier to implement when working with older subjects. Another factor leading to such changes in the computational indicators of retest reliability is the relative slowdown over time. When measuring reliability indicators by repeated testing in age groups, there are subject to relatively weak dynamic changes in the studied psychological trait, less random fluctuations of results will be recorded in the interval between experiments. The existence of this pattern requires separate definitions of retest reliability for different age groups of subjects. Especially significant is for tests intended for research in a wide age range. Such methods mainly include batteries of intelligence tests of general purpose (such as the Stanford-Binet scale, Wexler's children’s scales, Raven Matrices, R.Amthauer intelligence structure test, and some others). Note that the relative improvement of reliability indicators with the age of the examined is not a universal law. Quite naturally - this has to be considered when determining the reliability of tests intended for older people - the influence of factors of different rates of involutional changes, on the contrary, contribute to the deterioration of reliability indicators in older age groups.
Приведенные особенности и недостатки метода разрахунку надежности путем ретест приводят к тому, что такой подход может считаться пригодным лишь для ограниченного круга методик, для которых возможно многократное использование одного и того же комплекса задач. К таким методам можно отнести сенсомоторные пробы, уже упомянутые тесты скорости, а также ряд других, отличаются большим количеством тестовых заданий (например, Миннесотский многофакторный опросник личности).
An attempt to compensate part of the shortcomings of the method for determining reliability by retest led to the development of a means of reliability of parallel forms. This procedure is used. The same test subjects with a sample of the definition of reliability are examined with the main test variant, and then with some predetermined retest interval using an auxiliary set, which can be a parallel or joint form of the test. The concept of a parallel form of dough requires additional explanation. In this form, it is usually understood that the test is close to the primary one in terms of reliability and validity, as well as other psychodiagnostic characteristics. The latter is being developed with the goal of equivalently replacing the primary test. Development of several modifications of the same test, which differ in the specific composition of the test tasks,focused on increasing the feasibility of retesting the same subjects at short retest intervals. Let's give an example. Перед практическим психодиагностическим исследованием стоит задача выяснить характер психофармакологического действия разработанного препарата на эмоциональную сферу пациентов. Для этого перед приемом лекарств больным предлагается ответить на вопрос опросника, предназначенного для измерения некоторых особенностей эмоциональных состояний. Через некоторое время после начала действия препарата процедура обследования повторяется. При повторном использовании одних и тех же пунктов (заданий, вопросов) имеет место опасность проявления тенденции у испытуемых отражать в своих ответов не текущее состояние, а припоминание того что отвечалось на те же вопросы в предыдущем обследовании. Естественно, это приведет к искажению результатов. Использование в двух вариантах разных, но эквивалентных по определяемыми показателями наборов задач позволяет минимизировать негативное ретестовой влияние.
Несмотря на то, что параллельная форма теста добирается таким образом, чтобы оба варианта теста были максимально совместимыми с главными диагностическими характеристиками, выбранные варианты теста не всегда имеют одинаковые средние показатели и стандартное отклонение. В этом случае обязательным условием для параллельной формы теста является обеспечение возможности приведения показателей обеих форм друг к другу с помощью специальных коэффициентов, или таблиц евкивалентности.
Параллельные формы теста следует отличать от так называемых уравновешенных форм, состоящих из задач, которые попарно подбирают таким образом, чтобы был соблюден принцип наиболее возможной совпадения структуры и состава задач. Параллельные и уравновешенные формы, в свою очередь, следует отличать от эквивалентных форм. Последние могут состоять из различных по сути задач, но давать достаточно близки по количеству или по сути статистические выводы. Общий термин, объединяющий приведены варианты тестов - сопоставлены формы. В американской психологической литературе употребляются несколько иные наименования разновидностей сопоставленных форм - коррелированы (correlated), дублированные (dubiicated), уровни (equal) и подобные (similar).
Самые известные и распространенные в отечественной психологической диагностике методики, имеют Парал ;. ли формы - опросник личности Айзенка, тест R.Amthauer'a и некоторые другие.
The presence of one of the types of parallel forms is an important quality test, due to which greater convenience of its use in applied research is provided. At the same time, a certain range of methods does not require such forms. These include large-scale tests. By re-using such techniques, the influence of skills or the aforementioned answers becomes unobtrusive. Parallel forms are also not needed for speed tests.
Rather simple and common means of increasing the reliability of the results of re-research using techniques that do not have parallel forms, is the splitting of a set of items into paired and unpaired by their ordinal number. It is clear that such a division of test tasks into parts is possible in tests that are built on the principle of a scale, that is, each subsequent task for some more or less constant value should be heavier than the previous one. Then pair and unpaired tasks will be relatively balanced. By the way, the question of the subjective severity of test sets is important in the matter of designing, adapting and testing the psychodiagnostic qualities of psychological tests (we will dwell on this issue in more detail in the following chapters). It should also be borne in mind that the method of splitting, as a means of forming a pseudo-parallel form of the test, is absolutely unsuitable for the traditional use of personality questionnaires. First of all, this is explained by the fact that different items of the questionnaire have such discriminative indicators (see the following sections) do not coincide, but if we apply the principle of data processing based on calculating the indices of statistical significance of each answer relative to the final result, then from the total set of questions pick up sets will be balanced by diagnostic and discriminative qualities.
In addition, we note that the reliability of parts of test tasks does not coincide with the reliability of its parts. Let us give the following analogy: in a complex mechanism, where a large number of parts interact, the probability of failure is higher than that of a simple device, where such parts are much smaller; also in the psychological test, consisting of a large number of tasks or other elements, the likelihood of a different answer when reused also increases significantly. Fortunately, we can calculate and also adjust the reliability indicators of the transition from the whole set to its parts using special equations (see Section 1.3.3).
Let us return to the question of reliability characteristics using the principle of using parallel forms. The first thing to note is the higher authenticity of the statement about the reliability of the test compared to the application of the principle of retest reliability. When using a parallel form, a relatively new set of tasks is presented to the test subjects. Thus, the effect of training and restoring in memory the already implemented solutions is significantly (but not quite) reduced. A significant advantage of the method of parallel forms is also the possibility of using a relatively small retest interval.
The main indicator of the reliability of parallel forms is the correlation coefficient between the results of the primary and repeated surveys. In this case, the coefficient reflects both the degree of stability of the test results for a certain time (reliability itself) and the degree of coincidence of the results of the two test forms. If the two forms are used directly one after the other, the coefficient is mainly focused on the degree of compatibility of parallel forms.
The most difficult problem that arises when analyzing the reliability of parallel forms is the nature of the relationship between these test forms. Both sets of tasks should be selected in such a way that, while meeting the same requirements, being oriented towards measuring identical indicators and delivering similar results, they would be relatively independent of each other at the same time. This requirement is, in fact, a contradiction. The practical achievement of this is probably not for all test tasks. The main disadvantage of the principle of determining reliability by the method of parallel forms is connected with this. The number of tests that have such forms is limited. Another disadvantage of the method is the presence in the reliability coefficient of the measure of the relationship between the main and parallel forms. Through the reasons given, the analysis of reliability by the method of parallel forms acquired in modern applied and theoretical psychological diagnostics a very limited use.
From consideration of the principles for determining the reliability of the psychological test described in previous chapters, we can conclude: the use of the method of reliability of parallel forms is mainly due to an attempt to maximally weaken the influence of the retest regularities of the analysis results. In fact, using a different set of paragraphs in terms of content reduces the role of a workout factor. But such a decline is not fundamental. As noted, it is extremely difficult to select various test tasks that would simultaneously measure the same psychological indicators. And yet the structure and essence of the tasks, the nature of their construction in parallel forms remain the same, and only the wording, the means of expression of the same content, change. Therefore, the material of the parallel form when re-examining is not completely new for the test subject. So again, we do not avoid the workout factor.
It can be concluded that the main drawback of retest reliability and reliability of parallel forms is the fundamental need for retests in one form or another. But is there such a need for a really fundamental one? At first glance, a re-study follows from the definition of reliability itself - as the stability of the results of the technique over time. But reliability can be considered as the stability of results in some test particles relative to others. In this sense, reliability acts as an internal relative equivalence of these elements of a set of test items.
Such an approach to the interpretation of reliability allows us to develop a completely different direction of qualification of the measure of the stability of the test as a measuring tool and bypass the main limitation associated with the need for retest.
Qualification of the reliability of parts of the test is a characteristic of the reliability of the psychodiagnostic method by analyzing the stability of the results of partial sets of test problems or single test items. The simplest and most common type of analysis of the reliability of parts of a test is the splitting method, the content of which is that the subject performs the tasks of two equal parts of the test. A theoretical justification of the method is the assumption that, in the case of a normal or close distribution of marks on the test as a whole, the performance of any random set of tasks from parts of the test gives a similar distribution (provided that the parts are homogeneous in the nature of the tasks, as well as on the outcome of the test in general ).
The simplest case is splitting the dough into two equivalent parts (this was already mentioned in the previous section). In addition to the distribution of equivalent halves over even and odd numbers, dividing items according to the principle of proximity or equivalent values of the indexes of gravity and discriminativeness (see the subsequent sections), it is possible to divide the tasks by the time required to complete them (this method is used in the case of dividing into equivalent parts of speed tests).
Directly, the procedure for obtaining empirical reliability estimates looks simpler than in previous cases of determining coefficients of retest reliability and reliability of parallel forms. Test subjects from a sample of reliability tests are examined only once after a complete set of test items. After that, the answers are evaluated separately in the curved parts of the test. These results correlate among themselves, the obtained correlation coefficient will be an indicator of r t, reflecting the degree of stability of the result during the execution of various parts of the test.
In the previous section, we have already emphasized the warning about the non-equivalence of the reliability indicators of the test as a whole and its parts.
The Spearman-Brown equation allows to take into account the effect of an increase or decrease in the number of test tasks on the coefficient
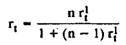
where r t is the safety factor for the complete set of tasks; r 1 t - its value changes the number of tasks; n is the ratio of the number of tasks to the original (if the number of tasks of the full test is 100, and its parts obtained by splitting into half are 50, then n = 0.5).
So for the full test
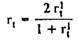
The given formulas make sense for cases of identical standard deviations of both halves of the test (σ Xi = σ X2). If σx1 differs from σ X2, the Flanagan formula is used to determine the reliability coefficient :
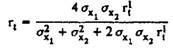
The same indicator for small samples is calculated using the Christoph formula:
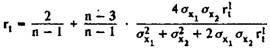
When determining r t (the full volume of the dough, you can use the Rülon formula:
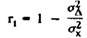
where σ 2 d - the variance of the difference between the results of each experimental for the halves of the test; σ 2 x - the variance of the total results. In this case, the reliability coefficient is calculated as part of the true variance of the test results.
In splitting speed tests, a special task grouping procedure is used. Determine the minimum time interval t m | n required to complete the test as a whole. After that, half and a quarter of this time is counted. All the test subjects work for half the minimum time, after which they make a mark against the task, were performed at the time of the control time, and continue to work for another quarter of the minimum time. The reliability coefficient in this case will be equal to the correlation index between the number of tasks solved 0.5 t min and 0.25 t min.
Splitting test assignments into equivalent halves is only a special case of analyzing the reliability of parts of the test. Indeed, splitting into three, four or more parts is possible. In the limiting case, the number of such parts is equal to the number of test items. Then reliability analysis, in essence, becomes an analysis of internal consistency.
When dividing the structure of test assignments into any number of groups, the correct determination of the reliability of parts of the test depends largely on compliance with the condition of equivalence of such groups. Therefore, when determining the reliability coefficient by the method of analyzing internal consistency, it is necessary to take into account that the selected tasks must be homogeneous, that is, homogeneous in content and severity. When comparing heterogeneous tasks, the value of r t is, of course, lower than the present.
The most common means of assessing the reliability of individual tasks is to calculate the Küder-Richardson coefficient:
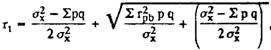
where σ 2 x - the variance of the primary estimates of the test; p is the index of severity, which is defined as the proportion of U T / 100 (see the section “The severity of test tasks”); q = lp; r pb - discrimination rates (see section 4).
To simplify calculations, the Guliksen formula can be used :
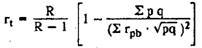
where R is the number of tasks in the test.
This equation can be simplified as follows:
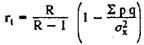
In the absence of a discrimination factor, the following variant of the Küder-Richardson formula is acceptable for use :
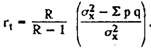
We give an example of calculating r t, according to the method of Küder-Richardson (Table 2).
The results of the calculation of the reliability coefficient can be used in cases where the assessment is graded by a dichotomous scale (that is, a scale constructed according to the “completed - not performed” principle). For cases with more differentiated estimates, the formula “alpha coefficient” can be used:
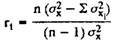
where Σσ 2 Xi is the sum of the variances of the results of individual tasks.
Table 2. Determination of the safety coefficient by the method of Kuder-Richardson (n = 50; σ 2 x = 8.01, R = 16)
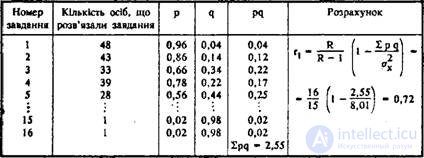
In the practice of psychological diagnostics it is considered: the test is sufficiently reliable if the indicator r t is greater than or equal to 0.6.
The reliability coefficient has a certain confidence interval, the determination of which is especially important due to the large number of factors that may affect its value. The confidence interval for r t is defined as
Er t = Z (r) + Z crit σ rt
where σ rt is the standard error of the reliability coefficient 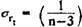
(Z r -Z) - Fisher transform (determined using statistical tables). In practice, only the lower limit r t is taken into account (Z crit with v = 0.05, a = 0.01 - 2.58).
Determining reliability by dividing a test into parts has significant advantages over retest reliability and reliability of parallel forms, mainly due to the absence of the need for a second study. This explains the spread of the method in modern psychological diagnostics. However, the method has certain disadvantages. These include the inability to establish the reliability of the test results for a period of time. This requires combining the definition of reliability using the splitting method with the means of retest reliability and reliability of parallel forms.
Concluding consideration of the golornyh means for determining the reliability of the psychodiagnostic test, we once again emphasize the exceptional importance of these criteria in the matter of professional and scientifically based application of existing psychological tests. A researcher who interprets empirical data should have a clear idea of the degree of accuracy and possible limits of the actual result that is achieved by a specific measurement procedure.
Unfortunately, it should be recognized that psychological tests are generally marked by relatively low reliability. It must be remembered: because of this circumstance, an individual result (that is, a qualitative or quantitative statement about the severity of a particular psychological characteristic of a particular person) will always be inferior to statistical conclusions based on a sample study. The more such a sample will be, the more homogeneous its composition will be, the more reliable psychodiagnostic information will be.
In conclusion, we add: different types of psychodiagnostic methods have relatively different reliability indicators. Objective tests have the highest value of safety factors. Significantly lower than these figures for personality questionnaires. It is very difficult to determine the quantitative indicators of the reliability of projective techniques, where we do not calculate, but judge reliability in qualitative form, although the principles for determining the reliability of projective techniques are generally the same as any other psychodiagnostic methods.
The reliability of projective tests is usually problematic. This is mainly due to the inadequate standardization of indicators and their interpretations, which are characteristic of projective tests, and the frequent absence or inadequacy of regulatory data. Basically, the ambiguity of interpretation of indicators of projective tests significantly limits the use of means of quantitative statistical analysis of reliability.
Along with objective tests and personality questionnaires, the reliability of projective tests can be determined using the principles outlined in the previous sections. But in this case one should pay attention to the inherent in projective tests of the procedure for determining reliability. So, along with the need to establish the traditional qualities and reliability of the method as a measuring procedure (general and partial dispersions, measurement errors, stability relative to retest, etc.) A special form is also needed - interpretative reliability. According to A. Anastasi (1982), interpretations and reliability are a measure of consistency with which different experimenters determine the same personality traits for a particular subject based on the interpretation of identical protocols. Based on this definition, there may exist at least the following levels of control of interpretative reliability:
Определение этих критериев надежности может опираться на эмпирическую процедуру сопоставления выводов, которые делаются различными экспериментаторами в отношении одной выборки определения надежности. В случае большого расхождения в толкованиях отдельных показателей средством повышения объективности психодиагностической информации является совершенствование стандарта проведения теста. В случае невозможности однозначного толкования отдельных показателей они должны быть исключены из интерпретативной схемы.
Определение надежности как внутренней согласованности для проективных тестов достаточно проблематично. Даже для таких методик, как PP Study С.Розенцвейгом, теста Роршаха, TAT и некоторых других, имеющих разделение на отдельные задачи, коэффициенты согласованности обычно низкие. Это свидетельствует об ограниченной возможности сравнения отдельных задач проективного теста из-за того, что в отдельных испытуемых они могут актуализировать различные аспекты личности. Для тестов свободной изобразительной продукции ( «Рисунок семьи», «Нарисуй человека» Ф.Гудинаф, тест дерева К.Коха и др.) Использование модели анализа надежности как внутренней согласованности имеет еще меньшее значение. Единственным путем является сравнение результатов в различных вариантах инструкции (например, в случае теста дерева: рисунок обычного дерева, рисунок «сумасшедшего» дерева, рисунок «фантастического» деревья и т.д.). Следует отметить, что здесь существует противоречие с известным эффектом, в котором устанавливаются значительные изменения в показателях даже при несущественных изменениях в инструкции испытуемым. Очевидно, при изменении инструкции мы часто имеем новый тест, связь которого с предыдущим еще предстоит выяснить.
At the same time, with the problem of determining the retest interval, which is traditional for retest reliability (with a small interval, repeating the previous performance due to memorization, with a large interval, characteristics may change as a result of the dynamic development of the studied construct), there is an additional problem — a relatively small number of identical indicators in the primary and subsequent experiments. This eliminates the use of simple means of correlative analysis. In addition, the repetition of results with the retest is generally almost not peculiar to projective techniques. When the experimenters, when re-tested, demanded that the TAT stories be
продолжение следует...
Часть 1 Means of control of the diagnostic qualities of psychological tests
Часть 2 2.1. content validity - Means of control of the diagnostic
Часть 3 2.4. obvious validity - Means of control of the diagnostic

Comments
To leave a comment
Mathematical Methods in Psychology
Terms: Mathematical Methods in Psychology