Lecture Tests
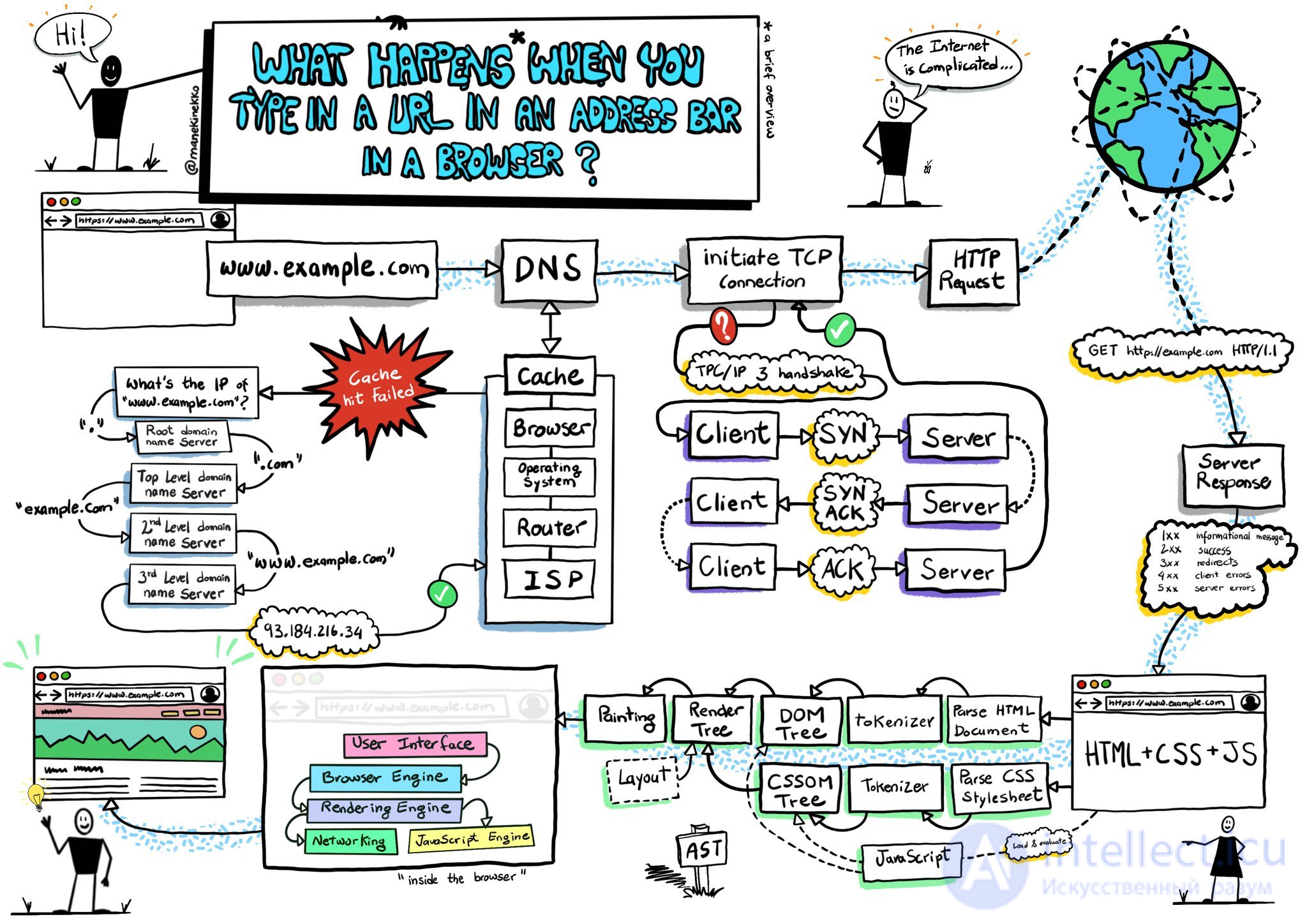
First, let's remember how the Internet works from the browser side
The browser operation consists of the following stages
DNS resolution
This process helps the browser know which server it should connect to when the user enters a URL. The browser contacts the DNS server and finds that google.com matches the set of numbers 1.52.201.130 - the IP address that the browser can connect to.
HTTP exchange
Once the browser determines which server will serve our request, it will establish a TCP connection with it and start an HTTP exchange. It is nothing more than a way for the browser to communicate with the server it needs, and for the server it is a way to respond to browser requests.
HTTP is simply the name of the most popular protocol for communicating on the web, and browsers mostly choose HTTP when communicating with servers. HTTP exchange implies that the client (our browser) sends a request and the server sends a response.
For example, after the browser successfully connects to the server serving google.com , it will send a request that looks like this
GET / HTTP / 1.1
Host: intellect.icu
Accept
Let's parse the request line by line:
GET / HTTP / 1.1 : with this first line, the browser asks the server to fetch the document from the location / , then adding that the rest of the request will be done over HTTP / 1.1 (or you can also use version 1.0 or 2)
Host: intellect.icu: This is the only HTTP header required by the HTTP / 1.1 protocol. Since the server can serve multiple domains ( intellect.icu , intellect.us, etc.), the Client mentions here that the request was for that particular host.
Accept: * / * : An optional header in which the browser tells the server that it will accept any response. The server can have a resource available in JSON, XML or HTML formats, so it can choose whatever format it prefers
After the browser, acting as the client, completes its request, the server will send a response. This is what the answer looks like:
HTTP / 1.1 200 OK Cache-Control: private, max-age = 0 Content-Type: text / html; charset = ISO-8859-1 Server: gws X-XSS-Protection: 1; mode = block X-Frame-Options: SAMEORIGIN Set-Cookie: NID = 134; expires = Fri, 11-Jan-2022 11:22:07 GMT; path = /; domain = .intellect.icu; HttpOnly
In the body of the response, the server includes a representation of the requested document according to the Content-Type header . In our case, the content type was set to text / html , so we expect HTML markup in the response - and that's what we find in the body of the document.
This is where the browser really shines. It reads and parses the HTML code, loads additional resources included in the markup (for example, JavaScript files or CSS documents can be specified there for loading) and presents them to the user as soon as possible.
Once again, the end result should be something that is readable by the average user.
If you need a more detailed explanation of what actually happens when we hit the enter key in the browser address bar, I would suggest reading the article "What happens when ...", a very meticulous attempt to explain the mechanisms behind this process.
Since this series is about security, I'm going to give you a hint of what we've just learned: Attackers easily make a living with HTTP communication and rendering vulnerabilities. Vulnerabilities, malicious users, and other fantastical beasts can be found elsewhere, but a better approach to providing protection at these levels already allows you to make progress in improving your security posture.
In addition to fighting each other to increase their market penetration, vendors are also working with each other to improve web standards, which are sort of "minimum requirements" for browsers.
The W3C is the cornerstone of standards development, but it is not uncommon for browsers to develop their own functionality that eventually becomes web standards, and security is no exception.
For example, Chrome 51 introduced the SameSite cookies, a feature that allowed web applications to get rid of a specific type of vulnerability known as CSRF. Other vendors decided it was a good idea and followed suit, which led to the SameSite approach becoming the web standard: Safari is currently the only major browser without SameSite cookie support.
4. JS lifecycle concept
... Modern JavaScript engines implement / implement and significantly optimize this process.

For a better visual representation of the Event loop operation ,
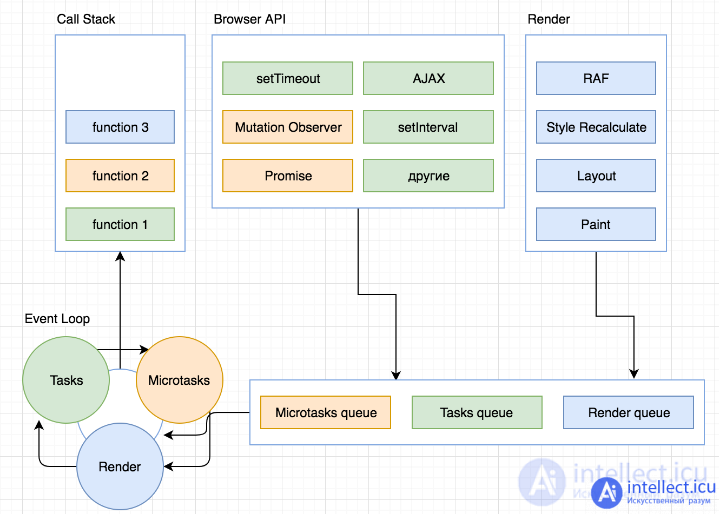
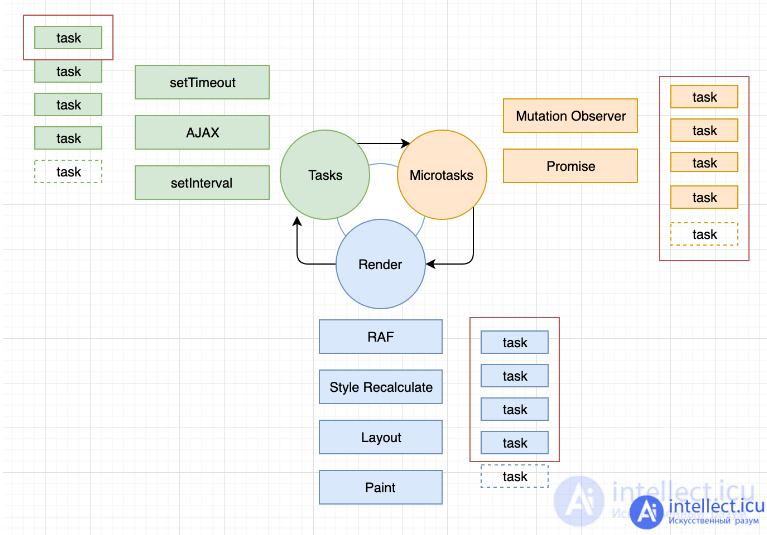
Any function call creates an Execution Context. When a nested function is called, a new context is created, and the old one is stored in a special data structure called the Call Stack.
function f (b) {
var a = 12;
return a + b + 35;
}
function g (x) {
var m = 4;
return f (m * x);
}
g (21);
When g is called, the first execution context is created, containing the arguments to g and local variables. When g calls f, a second context is created with the arguments to f and its local variables. And that execution context f is pushed onto the call stack above the first. When f returns, the top item is removed from the stack. When g returns, its context is also removed and the stack is empty.
Objects are allocated on the heap. The heap is just a name to refer to a large unstructured area of memory.
The JavaScript runtime contains a queue of tasks. This queue is a list of tasks to be processed. Each task is associated with some function that will be called to process this task.
When the stack is completely freed, the very first task is popped from the queue and processed. Processing a task consists in calling the associated function with the parameters recorded in this task. As usual, a function call creates a new execution context and is pushed onto the call stack.
Processing the task ends when the stack becomes empty again. The next task is removed from the queue and processing begins.
The event loop model is so named because it keeps track of new events in the loop:
while (queue.waitForMessage ()) {
queue.processNextMessage ();
}
queue.waitForMessage is waiting for tasks to arrive if the queue is empty.
Each task is completed in full before the next begins to be processed. Thanks to this, we know for sure: when the current function is executed, it cannot be suspended and will be completely completed before the execution of other code (which can change the data with which the current function works). This distinguishes JavaScript from a programming language such as C. Because in C, a function running on a separate thread can be stopped at any time to execute some other code on a different thread.
There are also disadvantages to this approach. If the task takes too long, then the web application cannot process user actions at this time (for example, scroll or click). The browser tries to mitigate the problem and displays the message "a script is taking too long to run" and suggests stopping it. It is good practice to create tasks that execute quickly and, if possible, split one task into several smaller ones.
In browsers, events are added to the queue at any time if an event occurs, as well as if it has a handler. If there is no handler, the event is lost. So, clicking on an element that has an event handler for the click event will add the event to the queue, and if there is no handler, then the event will not be added to the queue.
Calling setTimeout will add the event to the queue after the time specified in the second argument of the call. If the event queue is empty at that time, the event will be processed immediately, otherwise the setTimeout function event will have to wait for the remaining events in the queue to finish processing. That is why it is correct to consider the second argument to setTimeout not as the time after which the function from the first argument will be executed, but the minimum time after which it can be executed.
Zero latency does not guarantee that the handler will execute in zero milliseconds. A call to setTimeout with an argument of 0 (zero) will not complete in the specified time. Execution depends on the number of pending tasks in the queue. For example, the message `` this is just a message '' from the example below will be printed to the console before the cb1 handler is executed . This will happen because latency is the minimum amount of time it takes for the runtime to process a request.
(function () {
console.log ('this is the start');
setTimeout (function cb () {
console.log ('this is a msg from call back');
});
console.log ('this is just a message');
setTimeout (function cb1 () {
console.log ('this is a msg from call back1');
}, 0);
console.log ('this is the end');
}) ();
// "this is the start"
// "this is just a message"
// "this is the end"
// "this is a msg from call back"
// "this is a msg from call back1"
Web Worker or cross domain frame has its own stack, heap and event queue. Two separate event streams can communicate with each other only by sending messages using the postMessage method. This method adds a message to the other's queue if it accepts them, of course.
A very interesting property of the event loop in JavaScript is that, unlike many other languages, the thread of execution never blocks. I / O handling is usually done through events and callbacks, so even when an application is waiting for a request from IndexedDB or a response from XHR, it can handle other processes, such as user input.
There are well-known exceptions like alert or synchronous XHR, but it is considered good practice to avoid using them.
The following sections explain physical keyboard actions and OS interrupts. When you press the "g" key, the browser receives the event and the autocomplete features are enabled. Depending on the algorithm of your browser, if you are in private / incognito mode or not, you will be presented with different suggestions in the dropdown under the URL bar. Most of these algorithms sort and prioritize results based on search history, bookmarks, cookies, and popular Internet searches in general. As you type "google.com", many blocks of code are run , and the suggestions will be refined with each key press. It may even suggest "google.com" before you finish typing it.
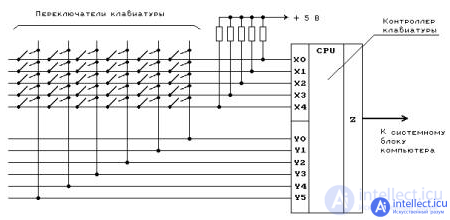
Figure 2.1. Simplified keyboard layout
To select a zero point, let's press the Enter key on our keyboard by clicking the bottom of its range. At this point, the electrical circuit specific to the enter key is closed (directly or capacitively). This allows a small amount of current to flow into the keyboard logic that scans the state of each rocker switch, removes the electrical noise from the fast intermittent switch, and converts it to a key code integer, in this case 13. The keyboard controller then encodes the key code for transmission to the computer. Nowadays this is almost universally done over a Universal Serial Bus (USB) or Bluetooth connection, but historically it is done over PS / 2 or ADB connections .
In the case of a USB keyboard:
In case of virtual keyboard (as in touchscreen devices):
The keyboard sends signals in its interrupt request line (IRQ), which is converted to an interrupt vector (integer) by the interrupt controller. The site https://intellect.icu says about it. The CPU uses an Interrupt Descriptor Table (IDT) to map interrupt vectors to interrupt handlers that are provided by the kernel. When an interrupt arrives, the CPU indexes the IDT using the interrupt vector and starts the appropriate handler. Thus, the kernel is introduced.
The HID transport passes the KBDHID.sys keypress event to the driver, which converts the HID usage to scan code. In this case, the scan code is VK_RETURN (0x0D). These KBDHID.sys driver interfaces with KBDCLASS.sys (keyboard class driver). This driver is responsible for safely handling all keyboard and keyboard input. It then calls Win32K.sys (after potentially passing the message through installed third-party keyboard filters). All this happens in kernel mode.
Win32K.sys figures out which window is the active window through the GetForegroundWindow () API. This API provides a handle to the browser address field window. Then the main Windows "message pump" SendMessage (hWnd, WM_KEYDOWN, VK_RETURN, lParam) calls. lParam is a bitmask that specifies additional information about keystrokes: number of repetitions (in this case 0), actual scan code (may be OEM dependent, but usually not for VK_RETURN), extended keys (e.g. alt, shift, ctrl) also pressed (they were not) and some other state.
Windows SendMessageAPI is a simple function that adds a message to the queue for a specific window handle (hWnd). Later, the main message handling function (called a WindowProc) assigned to hWnd is called to process each message in the queue.
hWnd The active window window () is actually an edit control, and WindowProc, in this case, has a message handler for WM_KEYDOWN messages. This code looks at the 3rd parameter that was passed to SendMessage (wParam) and since it VK_RETURN knows that the user pressed the ENTER key.
An interrupt signal fires an interrupt event in the I / O set keyboard kext driver. The driver converts the signal into a keycode that is passed to the WindowServer to the OS X process. As a result, it dispatches the event to WindowServer to any suitable (eg, active or listening) applications through their Mach port , where it is placed in an event queue. Events can then be read from this queue by threads with sufficient privileges to call the mach_ipc_dispatch function. This is most often done and handled in the NSApplication main event loop using the NSEvent object of the NSEventType KeyDown.
When using the X server GUI, the generic evdev event driver will be used to receive the X key press. Remapping keycodes to scan codes is done using X server-defined key layouts and rules. When the display of the scan code of the pressed key is complete, it X server sends the character to the window manager (DWM, metacity, i3, etc.), so the window manager, in turn, sends the character to the focused window. The graphics API of a window that accepts a character prints the corresponding font character in the appropriate focus field.
If no protocol or valid domain name is specified, the browser proceeds to feed the text specified in the address field to the browser's default search engine. In many cases, the URL has a special piece of text added to it to tell the search engine that it came from the URL bar of a specific browser.
To send ARP (Address Resolution Protocol) broadcasts, the network stack library needs a target IP address to look up. It also needs to know the MAC address of the interface that it will use to send ARP broadcasts.
The ARP cache is first checked for an ARP entry for our target IP. If it is in the cache, the library function returns the result: Target IP = MAC.
If the entry is not in the ARP cache:
ARP Request:
Sender MAC: interface: mac: address: here Sender IP: interface.ip.goes.here Target MAC: FF: FF: FF: FF: FF: FF (broadcast) Target IP: target.ip.goes.here
Depending on the type of equipment between the computer and the router:
Direct connection:
Hub:
Switch:
ARP Reply:
Sender MAC address: target: mac: address: here Sender IP: target.ip.goes.here Target MAC: interface: mac: address: here Target IP: interface.ip.goes.here
Now that the network library has the IP address of either our DNS server or the default gateway, it can resume the DNS process:
Once the browser obtains the target server's IP address, it takes that and the given port number from the URL (HTTP default is port 80 and HTTPS is port 443) and makes a call to the system library function named socket and requests a TCP socket stream - AF_INET / AF_INET6 and SOCK_STREAM.
At this point, the packet is ready for transmission via:
For most home or small business Internet connections, the packet will go from your computer, perhaps through your local network, and then through a modem (MOdulator / DEModulator) that converts digital ones and zeros into an analog signal suitable for transmission over telephone, cable etc. or connecting to wireless telephony. At the other end of the connection is another modem that converts the analog signal back into digital data, which will be processed by the next network node, where the sender and recipient addresses will be analyzed further.
Most large enterprises and some new residential connections will have fiber optic or direct Ethernet connections, in which case the data remains digital and is sent directly to the next network node for processing.
Eventually, the packet will reach the router that controls the local subnet. From there, it will continue to travel to the Autonomous System (AS) border routers, other ASs, and finally to the target server. Each router along the way extracts the destination address from the IP header and routes it to the appropriate next hop. The Time to Live (TTL) field in the IP header is decremented by one for each router passing through. The packet will be dropped if the TTL field reaches zero, or if the current router has no room in the queue (possibly due to network congestion).
This send and receive happens multiple times after the TCP connection stream:
The server receives a SYN and if it is in a good mood:
The client confirms the connection by sending a packet:
Data is transferred as follows:
To close the connection:
If the web browser you are using was written by Google, instead of sending an HTTP request to get the page, it will send a request to try and negotiate with the server an "upgrade" from HTTP to SPDY.
If the client uses the HTTP protocol and does not support SPDY, it sends a request to the form server:
GET / HTTP / 1.1 Host: intellect.icu
Connection: close [other titles]
where [other headers] refers to a series of colon-separated key-value pairs, formatted according to the HTTP specification and separated by a single newline. (This assumes that the web browser being used has no bugs that violate the HTTP specification. This also assumes that the web browser is using HTTP / 1.1, otherwise it cannot include the Host header in the request and the version specified in the GET request or will HTTP / 1.0 or HTTP / 0.9.)
HTTP / 1.1 defines a "close" connection option for the sender to indicate that the connection will be closed when the response is complete. For example,
Connection: close
HTTP / 1.1 applications that do not support persistent connections MUST include a "close" connection option in every message.
After sending the request and headers, the web browser sends a single empty newline to the server indicating that the content of the request has been completed.
The server responds with a response code indicating the status of the request, and responds with a response in the form:
200 OK [response headers]
This is followed by one newline character, and then the www.google.com HTML content payload is sent. The server can then either close the connection or, if the headers sent by the client requested it, leave the connection open for reuse for further requests.
If the HTTP headers sent by the web browser included enough information for the web server to determine if the version of the file cached by the web browser has changed since the last checkout (i.e., if the web browser has enabled the ETag header), it may instead respond with a request of the form:
304 Not changed [response headers]
and no payload, and the web browser fetches HTML from its cache instead.
After parsing the HTML, the web browser (and server) repeats this process for every resource (images, CSS, favicon.ico, etc.) that the HTML page links to, except instead of a GET / HTTP / 1.1 request would be GET / $ (URL relative to www.google.com) HTTP / 1.1.
If the HTML links to a resource on a different domain, www.google.com, the web browser goes back to the steps for resolving the other domain and goes through all the steps up to that point for that domain. The Host request header will show the corresponding server name, not google.com.
Server HTTPD (HTTP Daemon) is a server that handles requests / responses on the server side. The most common HTTPD servers are Apache or nginx for Linux and IIS for Windows.
The server splits the request into the following parameters:
After the server provides the browser with resources (HTML, CSS, JS, images, etc.), it goes through the following process:
The functionality of the browser is to present the web resource of your choice by requesting it from the server and displaying it in the browser window. A resource is usually an HTML document, but it can also be a PDF file, image, or some other type of content. The location of the resource is specified by the user using a URI (uniform resource identifier).
How the browser interprets and renders HTML files is specified in the HTML and CSS specifications. These specifications are maintained by the World Wide Web Consortium (W3C), the Internet standards organization.
Browser user interfaces have a lot in common with each other. Common user interface elements include:
Browser top-level structure
Browser Components:
The rendering engine begins to receive the content of the requested document from the network layer. This is usually done in 8K chunks.
The main task of an HTML parser is to convert HTML markup into a parse tree.
The output tree ("parse tree") is a tree of DOM elements and attribute nodes. DOM is short for Document Object Model. It is an object representation of an HTML document and an interface for HTML elements to the outside world such as JavaScript. The root of the tree is the Document object. Before any manipulation with scripting, the DOM has an almost unambiguous relationship to markup.
Parsing algorithm
HTML cannot be parsed with regular top-down or bottom-up parsers.
The reasons:
Can't use normal parsing techniques, the browser uses a dedicated parser to parse HTML. The parsing algorithm is detailed in the HTML5 specification.
The algorithm consists of two stages: tokenization and tree building.
Post-parsing actions
The browser starts to receive external resources associated with the page (CSS, images, JavaScript files, etc.).
At this point, the browser marks the document as interactive and begins to parse scripts that are in "lazy" mode: those that need to be executed after parsing the document. The state of the document is set to completed and the loading event is fired.
Note that the HTML page never contains an invalid syntax error. Browsers fix any invalid content and continue.
1. What is the main function of a web browser?
2. Which element is used to send requests to the server?
3. What process occurs when you enter a URL in the browser's address bar?
4. What happens after sending an HTTP request to the server?
5. What protocol is typically used to transfer data between a browser and a server?
6. What response does the server send to the browser after successfully processing a request?
7. What information does an HTTP header contain?
8. Which web page element is responsible for the structure and content?
9. What type of request is used to send data to the server?
10. What is caching in the context of a browser?
11. Which component of a browser is responsible for executing JavaScript code?
12. Which of the following elements can be part of a URL?
13. Which HTTP header is used to determine the content type?
14. What is the 404 status code?
15. Which method is used to retrieve data from the server?
16. What happens when the server cannot process a request?
17. Which of the following elements determines how the browser should display a page?
18. Which component is responsible for data transfer security?
19. Which element of the URL points to a specific resource on the server?
20. Which of the following processes occurs after receiving a response from the server?

Comments
To leave a comment
Fundamentals of Internet and Web Technologies
Terms: Fundamentals of Internet and Web Technologies