Lecture
Hello!

So we gradually came to advanced machine learning methods. Today we will discuss how to approach training a model in general, if the data is gigabytes or tens of gigabytes. Let's discuss the techniques that allow you to do this: stochastic gradient descent (SGD) and feature hashing, let's look at examples of using the Vowpal Wabbit library.
UPD: now the course is in English under the brand mlcourse.ai with articles on Medium, and materials on Kaggle (Dataset) and on GitHub.
Video recording of a lecture based on this article as part of the second launch of the open course (September-November 2017).
List of Series Articles
Despite the fact that gradient descent is one of the first topics studied in optimization theory and machine learning, it is difficult to overestimate the importance of one modification of it - stochastic gradient descent, which we will often call simply SGD (Stochastic Gradient Descent).
Recall that the essence of gradient descent is to minimize a function by taking small steps towards the steepest decrease in the function. The name of the method was given by the fact from mathematical analysis that the vector of  partial derivatives of a function
partial derivatives of a function  sets the direction of the fastest increase in this function. Hence, moving towards the antigradient of the function, it is possible to decrease the values of this function the fastest.
sets the direction of the fastest increase in this function. Hence, moving towards the antigradient of the function, it is possible to decrease the values of this function the fastest.

This is me in Sheregesh - I advise everyone to ride there at least once in their life. A picture for soothing the eyes, but it can be used to explain the intuition of gradient descent. If the task is to snowboard down the mountain as quickly as possible, then you need to choose the maximum slope at each point (if it is compatible with life), that is, calculate the antigradient.
Example: Pairwise Regression
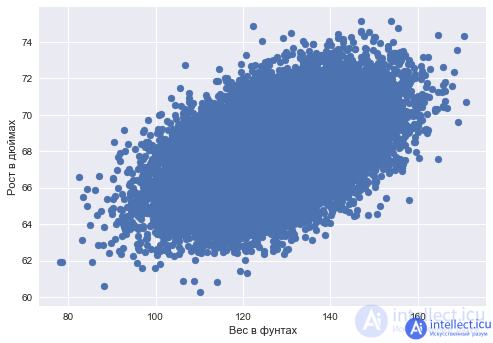
A simple pairwise regression problem can be solved using gradient descent. Suppose we predict one variable for another — height by weight — and postulate a linear relationship between height and weight.
Code for reading data and drawing a scatter plot
% matplotlib inline
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd
data_demo = pd.read_csv ('../../ data / weights_heights.csv')
plt.scatter (data_demo ['Weight'], data_demo ['Height']);
plt.xlabel ('Weight in lbs')
plt.ylabel ('Height in inches');
Given a vector of  length
length  - weight values for each observation (person) and
- weight values for each observation (person) and  - a vector of growth values for each observation (person).
- a vector of growth values for each observation (person).
The task: to find such weights  and
and  so that when predicting growth by weight in the form
so that when predicting growth by weight in the form  (where
(where  is the
is the  -th value of growth,
-th value of growth,  is the -th value of the weight), to minimize the squared error (you can also use the root-mean-square error, but the constant
is the -th value of the weight), to minimize the squared error (you can also use the root-mean-square error, but the constant  does not make the weather, but is set
does not make the weather, but is set  for beauty):
for beauty):

We will do this using gradient descent, calculating the partial derivatives of the function  with respect to the weights in the model - and . The iterative training procedure will be specified by simple formulas for updating the weights (we change the weights so as to make a small, proportionally small constant
with respect to the weights in the model - and . The iterative training procedure will be specified by simple formulas for updating the weights (we change the weights so as to make a small, proportionally small constant  , step towards the antigradient of the function):
, step towards the antigradient of the function):

If we turn to a pen and a piece of paper and find analytical expressions for partial derivatives, we get

And all this works pretty well (in this article we will not discuss the problems of local minima, selection of the gradient descent step, moment, etc. - much has been written about this, you can refer to the chapter "Numeric Computation" of the book "Deep Learning" ) until there is too much data. The problem with this approach is that the calculation of the gradient is reduced to the summation of some values for each object of the training set. That is, simply, the problem is that the algorithm requires a lot of iterations in practice, and at each iteration, the weights are recalculated according to a formula that contains the sum over the entire sample of the type  . But what if there are millions and billions of objects in the sample?
. But what if there are millions and billions of objects in the sample?

The essence of stochastic gradient descent is informal, throw out the sum sign from the weight conversion formulas and update them one object at a time. That is, in our case

With this approach, at each iteration, it is not at all guaranteed to move towards the steepest decrease in the function, and iterations may be required a couple of orders of magnitude more than in the case of ordinary gradient descent. But the recalculation of weights at each iteration is done almost instantly.
As an illustration, let's take a picture of Andrew Ng from his machine learning course.
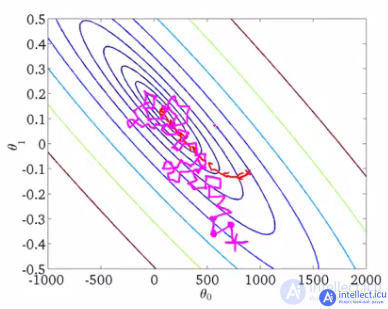
The lines of the level of some function are drawn, the minimum we are looking for. The red curve shows the change in the weights (in the picture  and
and  match , and in our example). According to the properties of the gradient, the direction of change at each point will be perpendicular to the level lines. With the stochastic approach, at each iteration, the weights change less predictably, sometimes it even seems that some steps are unsuccessful - they take them away from the cherished minimum - but in the end both procedures converge to approximately one solution.
match , and in our example). According to the properties of the gradient, the direction of change at each point will be perpendicular to the level lines. With the stochastic approach, at each iteration, the weights change less predictably, sometimes it even seems that some steps are unsuccessful - they take them away from the cherished minimum - but in the end both procedures converge to approximately one solution.
The convergence of stochastic gradient descent to the same solution as gradient descent is one of the most important facts proven in optimization theory. Now, in the era of Deep Data and Big Learning, the stochastic version is often called simply gradient descent.
Stochastic gradient descent, being one of the optimization methods, provides a very practical guide to training classification and regression algorithms on large samples - up to hundreds of gigabytes (depending on the available memory).
In the case of pairwise regression, which we considered, you can store a training sample on disk  and, without loading it into RAM (it may simply not fit), read objects one at a time and update the weights:
and, without loading it into RAM (it may simply not fit), read objects one at a time and update the weights:
After processing all the objects of the training sample, the functionality that we optimize (the squared error in the regression problem or, for example, the logistic error in the classification problem) will decrease, but often it takes several tens of passes through the sample to decrease sufficiently.
This approach to model training is often referred to as online learning, a term that predates MOOCs and mainstreams.

In this article, we do not consider many of the nuances of stochastic optimization (you can fundamentally study this topic in Boyd's book "Convex Optimization"), but rather move on to the Vowpal Wabbit library, with which you can train simple models on huge samples using stochastic optimization and one more trick - feature hashing, which will be discussed below.
In Scikit-learn, stochastic gradient descent classifiers and regressors are implemented by the SGDClassifier and SGDRegressor classes from sklearn.linear_model.
The vast majority of classification and regression methods are formulated in terms of Euclidean or metric spaces, that is, they imply the presentation of data in the form of real vectors of the same dimension. In real data, however, categorical features that take on discrete values, such as yes / no or January / February /.../ December, are not so rare. We will discuss how to work with such data, in particular using linear models, and what to do if there are many categorical features, and even each has a bunch of unique values.
Consider a UCI bank sample, in which most of the features are categorical.
Library import and data load code
import warnings
warnings.filterwarnings ('ignore')
import os
import re
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, accuracy_score
from sklearn.metrics import roc_auc_score, roc_curve, confusion_matrix
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.datasets import fetch_20newsgroups, load_files
import pandas as pd
from scipy.sparse import csr_matrix
import matplotlib.pyplot as plt
% matplotlib inline
import seaborn as sns
df = pd.read_csv ('../../ data / bank_train.csv')
labels = pd.read_csv ('../../ data / bank_train_target.csv', header = None)
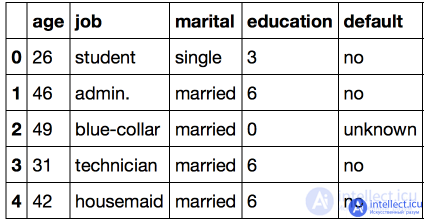
df.head ()
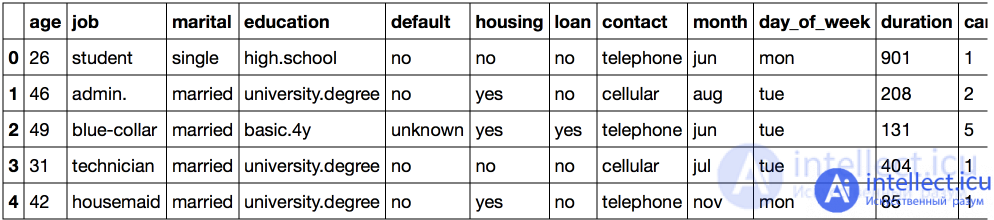
It is easy to see that quite a few features in this dataset are not represented by numbers. In this form, the data is not yet suitable for us: we will not be able to apply the vast majority of the methods available to us.
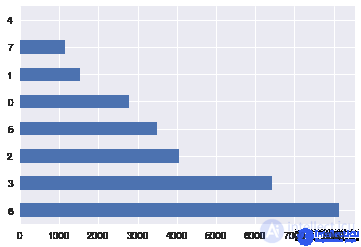
To find a solution, let's look at the education attribute:
Plotting code
df ['education']. value_counts (). plot.barh ();
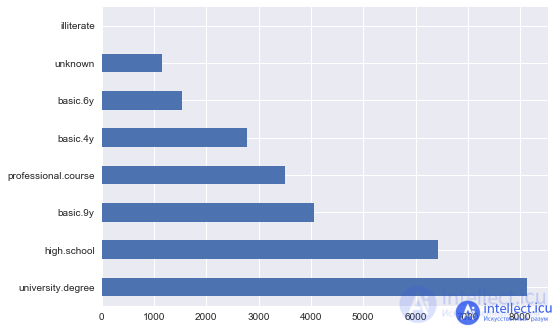
A natural solution to this problem would be to map each value to a unique number uniquely. For example, we could convert university.degree to 0, and basic.9y to 1. This simple operation has to be done often, so the LabelEncoder class is implemented in the preprocessing module of the sklearn library for this task:
The fit method of this class finds all unique values and builds a table to match each category to some number, and the transform method directly converts the values to numbers. After fit, label_encoder will have a classes_ field containing all unique values. You can number them and make sure that the conversion is correct.
Testing LabelEncoder Conversion
label_encoder = LabelEncoder () mapped_education = pd.Series (label_encoder.fit_transform (df ['education'])) mapped_education.value_counts (). plot.barh () print (dict (enumerate (label_encoder.classes_)))
{0: 'basic.4y', 1: 'basic.6y', 2: 'basic.9y', 3: 'high.school', 4: 'illiterate', 5: 'professional.course', 6: ' university.degree ', 7:' unknown '}
What happens if we have data with other categories? LabelEncoder will swear that it does not know the new category.
Swearing LabelEncoder
try:
label_encoder.transform (df ['education']. replace ('high.school', 'high_school'))
except Exception as e:
print ('Error:', e)
Error: y contains new labels: ['high_school']
Thus, when using this approach, we must always be sure that the feature cannot take on previously unknown values. We'll come back to this problem a little later, but now we'll replace the entire education column with the transformed one:
Let's continue the conversion for all columns of type object - this is the type specified in pandas for such data.
Code
categorical_columns = df.columns [df.dtypes == 'object']. union (['education'])
for column in categorical_columns:
df [column] = label_encoder.fit_transform (df [column])
df.head ()
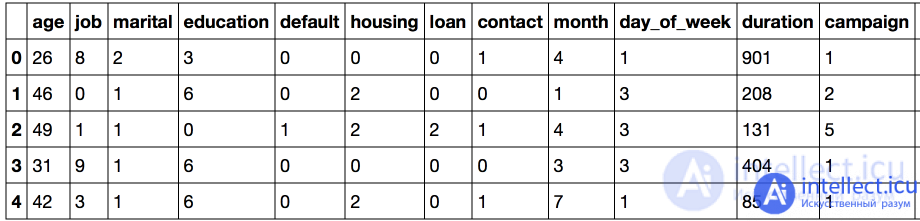
The main problem with this representation is that the numeric code has created a Euclidean representation for the data.
For example, we implicitly introduced algebra over work values - we can subtract client 1's work from client 2's work. The site https://intellect.icu says about it. Of course, this operation doesn't make any sense. But it is on this that the object proximity metrics are based, which makes it meaningless to use the nearest neighbor method on data in this form. Likewise, it would make no sense to use linear models. Let's see how logistic regression works on such data and make sure that nothing good comes out.
Logistic regression training
def logistic_regression_accuracy_on (dataframe, labels):
features = dataframe.as_matrix ()
train_features, test_features, train_labels, test_labels = \
train_test_split (features, labels)
logit = LogisticRegression ()
logit.fit (train_features, train_labels)
return classification_report (test_labels, logit.predict (test_features))
print (logistic_regression_accuracy_on (df [categorical_columns], labels))
precision recall f1-score support
0 0.89 1.00 0.94 6159
1 0.00 0.00 0.00 740
avg / total 0.80 0.89 0.84 6899
In order for us to be able to apply linear models on such data, we need another method called One-Hot Encoding.
Suppose that some feature can take 10 different values. In this case, One Hot Encoding implies the creation of 10 signs, all of which are zero except for one . We put 1 on the position corresponding to the numerical value of the feature.
This technique is implemented in sklearn.preprocessing in the OneHotEncoder class. By default, OneHotEncoder converts the data to a sparse matrix to avoid wasting memory for storing numerous zeros. However, in this example, the size of the data is not an issue for us, so we will use a dense representation.
Code
onehot_encoder = OneHotEncoder (sparse = False) encoded_categorical_columns = pd.DataFrame (onehot_encoder.fit_transform (df [categorical_columns])) encoded_categorical_columns.head ()
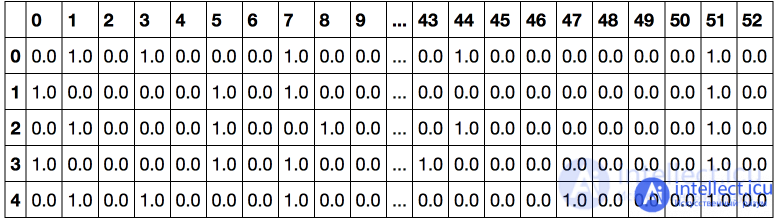
We got 53 columns - this is how many different unique values the categorical columns of the original sample can take. The data converted using One-Hot Encoding begins to make sense for a linear model - the accuracy for class 1 (who confirmed the loan) was 61%, completeness) - 17%.
Logistic regression training
print (logistic_regression_accuracy_on (encoded_categorical_columns, labels))
precision recall f1-score support
0 0.90 0.99 0.94 6126
1 0.61 0.17 0.27 773
avg / total 0.87 0.89 0.87 6899
Real data may turn out to be much more dynamic, and we cannot always expect that categorical features will not take on new values. All this makes it very difficult to use already trained models on new data. In addition, LabelEncoder implies a preliminary analysis of the entire sample and storing the constructed mappings in memory, which makes it difficult to work in big data mode.
To solve these problems, there is a simpler hashing-based approach to vectorizing categorical features known as the hashing trick.
Hash functions can help us in the task of finding unique codes for different values of a feature, for example:
for s in ('university.degree', 'high.school', 'illiterate'):
print (s, '->', hash (s))
university.degree -> -5073140156977989958 high.school -> -8439808450962279468 illiterate -> -2719819637717010547
Negative values that are so large in absolute value will not work for us. Let's limit the range of values of the hash function:
hash_space = 25
for s in ('university.degree', 'high.school', 'illiterate'):
print (s, '->', hash (s)% hash_space)
university.degree -> 17 high.school -> 7 illiterate -> 3
Imagine that we have an idle student in the sample who was called on Monday, then his feature vector will be formed similarly to One-Hot Encoding, but in a single space of a fixed size for all features:
hashing_example = pd.DataFrame ([{i: 0.0 for i in range (hash_space)}])
for s in ('job = student', 'marital = single', 'day_of_week = mon'):
print (s, '->', hash (s)% hash_space)
hashing_example.loc [0, hash (s)% hash_space] = 1
hashing_example
job = student -> 6 marital = single -> 8 day_of_week = mon -> 16
It is worth noting that in this example, not only feature values were hashed, but also feature name + feature value pairs. This is necessary in order to divide the same values of different characteristics among themselves, for example:
assert hash ('no') == hash ('no')
assert hash ('housing = no')! = hash ('loan = no')
Could there be a collision of the hash function, that is, coincidence of codes for two different values? It is easy to prove that this rarely happens given a sufficient hash space, but even when it does, it will not significantly degrade the quality of the classification or regression.

You might ask, "What the hell is going on?" And it seems that common sense suffers when features are hashed. Possibly, but this heuristic is essentially the only way to work with categorical features that have many unique meanings. Moreover, this technique has proven itself well in practice. You can read more about learning to hash in this review, as well as in the materials of Evgeny Sokolov.
Vowpal Wabbit (VW) is one of the most widely used libraries in the industry. It is distinguished by high speed of work and support of a large number of different learning modes. Of particular interest for big and high-dimensional data is online learning - the library's greatest strength. Feature hashing is also implemented, and Vowpal Wabbit is great for working with text data.
The main interface for working with VW is shell. Vowpal Wabbit reads data from a file or standard input (stdin) in a format that looks like this:
[Label] [Importance] [Tag] | Namespace Features | Namespace Features ... | Namespace Features
Namespace = String [: Value]
Features = (String [: Value]) *
where [] denotes optional items and (...) * denotes an indefinite number of iterations.
For example, the following line fits this format:
1 1.0 | Subject WHAT car is this | Organization University of Maryland: 0.5 College Park
VW is a great tool for working with text data. Let's make sure of this using the 20newsgroups sample, which contains news from 20 different thematic mailings.
newsgroups = fetch_20newsgroups ('../../ data / news_data')
Each news item is related to one of 20 topics: alt.atheism, comp.graphics, comp.os.ms-windows.misc, comp.sys.ibm.pc.hardware, comp.sys.mac.hardware, comp.windows.x , misc.forsalerec.autos, rec.motorcycles, rec.sport.baseball, rec.sport.hockey, sci.crypt, sci.electronics, sci.med, sci.space, soc.religion.christian, talk.politics.guns , talk.politics.mideast, talk.politics.misc, talk.religion.misc.
Consider the first text document in this collection:
Code
text = newsgroups ['data'] [0]
target = newsgroups ['target_names'] [newsgroups ['target'] [0]]
print ('-----')
print (target)
print ('-----')
print (text.strip ())
print ('----')
----- rec.autos ----- From: lerxst@wam.umd.edu (where's my thing) Subject: WHAT car is this !? Nntp-Posting-Host: rac3.wam.umd.edu Organization: University of Maryland, College Park Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s / early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ---- ----
Let's convert the data to the Vowpal Wabbit format, while leaving only words no shorter than 3 characters. Here we do not perform many important procedures in text analysis (stemming and lemmatization), but, as we will see, the problem will be solved well anyway.
Code
def to_vw_format (document, label = None):
return str (label or '') + '| text' + '' .join (re.findall ('\ w {3,}', document.lower ())) + '\ n'
to_vw_format (text, 1 if target == 'rec.autos' else -1)
'1 | text from lerxst wam umd edu where thing subject what car this nntp posting host rac3 wam umd edu organization university maryland college park lines was wondering anyone out there could enlighten this car saw the other day was door sports car looked from the late 60s early 70s was called bricklin the doors were really small addition the front bumper was separate from the rest the body this all know anyone can tellme model name engine specs years production where this car made history whatever info you have this funky looking car please mail thanks brought you your neighborhood lerxst \ n '
Let's split the sample into training and test ones and write the documents converted in this way to a file. We will consider the document positive if it refers to the rec.autos car newsletter . This will build a model that differentiates car news from the rest.
Code
all_documents = newsgroups ['data']
all_targets = [1 if newsgroups ['target_names'] [target] == 'rec.autos'
else -1 for target in newsgroups ['target']]
train_documents, test_documents, train_labels, test_labels = \
train_test_split (all_documents, all_targets, random_state = 7)
with open ('../../ data / news_data / 20news_train.vw', 'w') as vw_train_data:
for text, target in zip (train_documents, train_labels):
vw_train_data.write (to_vw_format (text, target))
with open ('../../ data / news_data / 20news_test.vw', 'w') as vw_test_data:
for text in test_documents:
vw_test_data.write (to_vw_format (text))
Let's run Vowpal Wabbit on the generated file. We are solving the classification problem, so we will set the loss function to hinge (linear SVM). We will save the constructed model to the corresponding file 20news_model.vw.
! vw -d ../../data/news_data/20news_train.vw \ --loss_function hinge -f ../../data/news_data/20news_model.vw
final_regressor = ../../data/news_data/20news_model.vw Num weight bits = 18 learning rate = 0.5 initial_t = 0 power_t = 0.5 using no cache Reading datafile = ../../data/news_data/20news_train.vw num sources = 1 average since example example current current loss last counter weight label predict features 1.000000 1.000000 1 1.0 -1.0000 0.0000 157 0.911276 0.822551 2 2.0 -1.0000 -0.1774 159 0.605793 0.300311 4 4.0 -1.0000 -0.3994 92 0.419594 0.233394 8 8.0 -1.0000 -0.8167 129 0.313998 0.208402 16 16.0 -1.0000 -0.6509 108 0.196014 0.078029 32 32.0 -1.0000 -1.0000 115 0.183158 0.170302 64 64.0 -1.0000 -0.7072 114 0.261046 0.338935 128 128.0 1.0000 -0.7900 110 0.262910 0.264774 256 256.0 -1.0000 -0.6425 44 0.216663 0.170415 512 512.0 -1.0000 -1.0000 160 0.176710 0.136757 1024 1024.0 -1.0000 -1.0000 194 0.134541 0.092371 2048 2048.0 -1.0000 -1.0000 438 0.104403 0.074266 4096 4096.0 -1.0000 -1.0000 644 0.081329 0.058255 8192 8192.0 -1.0000 -1.0000 174 finished run number of examples per pass = 8485 passes used = 1 weighted example sum = 8485.000000 weighted label sum = -7555.000000 average loss = 0.079837 best constant = -1.000000 best constant's loss = 0.109605 total feature number = 2048932
The model is trained. VW outputs a lot of useful information as it learns (however, it can be suppressed by specifying the --quiet option). The output of diagnostic information is detailed in the VW documentation on GitHub - here. Please note that the average loss decreased as the iterations proceeded. VW uses examples not yet reviewed to calculate the loss function, so this estimate is generally correct. Let's apply the trained model on a test set, saving the predictions to a file using the -p option:
! vw -i ../../data/news_data/20news_model.vw -t -d ../../data/news_data/20news_test.vw \ -p ../../data/news_data/20news_test_predictions.txt
only testing predictions = ../../data/news_data/20news_test_predictions.txt Num weight bits = 18 learning rate = 0.5 initial_t = 0 power_t = 0.5 using no cache Reading datafile = ../../data/news_data/20news_test.vw num sources = 1 average since example example current current loss last counter weight label predict features 0.000000 0.000000 1 1.0 unknown 1.0000 349 0.000000 0.000000 2 2.0 unknown -1.0000 50 0.000000 0.000000 4 4.0 unknown -1.0000 251 0.000000 0.000000 8 8.0 unknown -1.0000 237 0.000000 0.000000 16 16.0 unknown -0.8978 106 0.000000 0.000000 32 32.0 unknown -1.0000 964 0.000000 0.000000 64 64.0 unknown -1.0000 261 0.000000 0.000000 128 128.0 unknown 0.4621 82 0.000000 0.000000 256 256.0 unknown -1.0000 186 0.000000 0.000000 512 512.0 unknown -1.0000 162 0.000000 0.000000 1024 1024.0 unknown -1.0000 283 0.000000 0.000000 2048 2048.0 unknown -1.0000 104 finished run number of examples per pass = 2829 passes used = 1 weighted example sum = 2829.000000 weighted label sum = 0.000000 average loss = 0.000000 total feature number = 642215
Let's load the obtained predictions, calculate the AUC and display the ROC-curve:
Code
with open ('../../ data / news_data / 20news_test_predictions.txt') as pred_file:
test_prediction = [float (label)
for label in pred_file.readlines ()]
auc = roc_auc_score (test_labels, test_prediction)
roc_curve = roc_curve (test_labels, test_prediction)
with plt.xkcd ():
plt.plot (roc_curve [0], roc_curve [1]);
plt.plot ([0.1], [0.1])
plt.xlabel ('FPR'); plt.ylabel ('TPR'); plt.title ('test AUC =% f'% (auc)); plt.axis ([- 0.05,1.05, -0.05,1.05]);
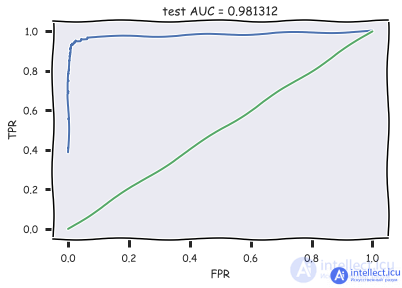
The obtained AUC value indicates a high quality of the classification.
We use the same sample as in the previous part, but we solve the problem of multiclass classification. Here Vowpal Wabbit is a little capricious - he likes the class labels to be distributed from 1 to K, where K is the number of classes in the classification problem (in our case, 20). Therefore, you will have to apply LabelEncoder, and even add one later (LabelEncoder converts the labels into the range from 0 to K-1).
Code
all_documents = newsgroups ['data'] topic_encoder = LabelEncoder () all_targets_mult = topic_encoder.fit_transform (newsgroups ['target']) + 1
The selections will be the same, but the labels will change, train_labels_mult and test_labels_mult are label vectors from 1 to 20.
Code
train_documents, test_documents, train_labels_mult, test_labels_mult = \
train_test_split (all_documents, all_targets_mult, random_state = 7)
with open ('../../ data / news_data / 20news_train_mult.vw', 'w') as vw_train_data:
for text, target in zip (train_documents, train_labels_mult):
vw_train_data.write (to_vw_format (text, target))
with open ('../../ data / news_data / 20news_test_mult.vw', 'w') as vw_test_data:
for text in test_documents:
vw_test_data.write (to_vw_format (text))
Train Vowpal Wabbit in multi-class classification mode by passing the oaa parameter (from "one against all") equal to the number of classes. We will also list the parameters that can be adjusted, and on which the quality of the model can depend quite significantly (for more details, see the official Vowpal Wabbit tutorial):
regularization (-l1) - here you need to pay attention to the fact that in VW the regularization is calculated for each object, therefore the regularization coefficients are usually taken small, about 
Additionally, you can try the automatic configuration of Vowpal Wabbit settings with Hyperopt. So far, this only works with Python 2.
Code
%% time ! vw --oaa 20 ../../data/news_data/20news_train_mult.vw \ -f ../../data/news_data/20news_model_mult.vw --loss_function = hinge
final_regressor = ../../data/news_data/20news_model_mult.vw Num weight bits = 18 learning rate = 0.5 initial_t = 0 power_t = 0.5 using no cache Reading datafile = ../../data/news_data/20news_train_mult.vw num sources = 1 average since example example current current loss last counter weight label predict features 1.000000 1.000000 1 1.0 15 1 157 1.000000 1.000000 2 2.0 2 15 159 1.000000 1.000000 4 4.0 15 10 92 1.000000 1.000000 8 8.0 16 15 129 1.000000 1.000000 16 16.0 13 12 108 0.937500 0.875000 32 32.0 2 9 115 0.906250 0.875000 64 64.0 16 16 114 0.867188 0.828125 128 128.0 8 4 110 0.816406 0.765625 256 256.0 7 15 44 0.646484 0.476562 512 512.0 13 9 160 0.502930 0.359375 1024 1024.0 3 4 194 0.388672 0.274414 2048 2048.0 1 1 438 0.300293 0.211914 4096 4096.0 11 11 644 0.225098 0.149902 8192 8192.0 5 5 174 finished run number of examples per pass = 8485 passes used = 1 weighted example sum = 8485.000000 weighted label sum = 0.000000 average loss = 0.222392 total feature number = 2048932 CPU times: user 7.97 ms, sys: 13.9 ms, total: 21.9 ms Wall time: 378 ms
%% time ! vw -i ../../data/news_data/20news_model_mult.vw -t \ -d ../../data/news_data/20news_test_mult.vw \ -p ../../data/news_data/20news_test_predictions_mult.txt
only testing predictions = ../../data/news_data/20news_test_predictions_mult.txt Num weight bits = 18 learning rate = 0.5 initial_t = 0 power_t = 0.5 using no cache Reading datafile = ../../data/news_data/20news_test_mult.vw num sources = 1 average since example example current current loss last counter weight label predict features 1.000000 1.000000 1 1.0 unknown 8 349 1.000000 1.000000 2 2.0 unknown 6 50 1.000000 1.000000 4 4.0 unknown 18 251 1.000000 1.000000 8 8.0 unknown 18 237 1.000000 1.000000 16 16.0 unknown 4 106 1.000000 1.000000 32 32.0 unknown 15 964 1.000000 1.000000 64 64.0 unknown 4 261 1.000000 1.000000 128 128.0 unknown 8 82 1.000000 1.000000 256 256.0 unknown 10 186 1.000000 1.000000 512 512.0 unknown 1 162 1.000000 1.000000 1024 1024.0 unknown 11 283 1.000000 1.000000 2048 2048.0 unknown 14 104 finished run number of examples per pass = 2829 passes used = 1 weighted example sum = 2829.000000 weighted label sum = 0.000000 average loss = 1.000000 total feature number = 642215 CPU times: user 4.28 ms, sys: 9.65 ms, total: 13.9 ms Wall time: 166 ms
with open ('../../ data / news_data / 20news_test_predictions_mult.txt') as pred_file:
test_prediction_mult = [float (label)
for label in pred_file.readlines ()]
accuracy_score (test_labels_mult, test_prediction_mult)
We get about 87% of correct answers.
As an example of analyzing the results, let's see what topics the classifier confuses atheism with.
Code
M = confusion_matrix (test_labels_mult, test_prediction_mult)
for i in np.where (M [0 ,:]> 0) [0] [1:]:
print (newsgroups ['target_names'] [i], M [0, i],)
rec.autos 1 rec.sport.baseball 1 sci.med 1 soc.religion.christian 3 talk.religion.misc 5
These topics are rec.autos, rec.sport.baseball, sci.med, soc.religion.christian, and talk.religion.misc.
In this part we will deal with the binary classification of movie reviews published on the IMDB site. Note how fast Vowpal Wabbit will run.
We use the load_files function from sklearn.datasets to load movie reviews from here. Download the data and specify your path to the imdb_reviews directory (it should contain the train and test directories ). Unzipping can take several minutes - there are 100 thousand files. In the training and test samples, 12.5 million good and bad reviews for films. Let's separate the data (actually, the texts) from the tags.
Code
# change your way path_to_movies = '/Users/y.kashnitsky/Yandex.Disk.localized/ML/data/imdb_reviews/' reviews_train = load_files (os.path.join (path_to_movies, 'train')) text_train, y_train = reviews_train.data, reviews_train.target
print ("Number of documents in training data:% d"% len (text_train))
print (np.bincount (y_train))
Number of documents in training data: 25000 [12500 12500]
The same is with the test sample.
reviews_test = load_files (os.path.join (path_to_movies, 'test'))
text_test, y_test = reviews_test.data, reviews_train.target
print ("Number of documents in test data:% d"% len (text_test))
print (np.bincount (y_test))
Number of documents in test data: 25000 [12500 12500]
Examples of reviews:
"Zero Day leads you to think, even re-think why two boys / young men would do what they did - commit mutual suicide via slaughtering their classmates. It captures what must be beyond a bizarre mode of being for two humans who have decided to withdraw from common civility in order to define their own / mutual world via coupled destruction. It is not a perfect movie but given what money / time the filmmaker and actors had - it is a remarkable product. In terms of explaining the motives and actions of the two young suicide / murderers it is better than 'Elephant' - in terms of being a film that gets under our 'rationalistic' skin it is a far, far better film than almost anything you are likely to see. Flawed but honest with a terrible honesty. "
It was a good review. But the bad one:
'Words can \' t describe how bad this movie is. I can \ 't explain it by writing only. You have too see it for yourself to get at grip of how horrible a movie really can be. Not that I recommend you to do that. There are so many clich \ xc3 \ xa9s, mistakes (and all other negative things you can imagine) here that will just make you cry. To start with the technical first, there are a LOT of mistakes regarding the airplane. I won \ 't list them here, but just mention the coloring of the plane. They didn \ 't even manage to show an airliner in the colors of a fictional airline, but instead used a 747 painted in the original Boeing livery. Very bad. The plot is stupid and has been done many times before, only much, much better. There are so many ridiculous moments here that i lost count of it really early. Also, I was on the bad guys \ 'side all the time in the movie, because the good guys were so stupid. "Executive Decision" should without a doubt be you \ 're choice over this one, even the "Turbulence" -movies are better. In fact, every other movie in the world is better than this one. '
We will use the previously written to_vw_format function. Let's prepare training (movie_reviews_train.vw), deferred (movie_reviews_valid.vw) and test (movie_reviews_test.vw) samples for Vowpal Wabbit. We will leave 70% of the original training sample for training, 30% for deferred sampling.
Code
train_share = int (0.7 * len (text_train))
train, valid = text_train [: train_share], text_train [train_share:]
train_labels, valid_labels = y_train [: train_share], y_train [train_share:]
with open ('../../ data / movie_reviews_train.vw', 'w') as vw_train_data:
for text, target in zip (train, train_labels):
vw_train_data.write (to_vw_format (str (text), 1 if target == 1 else -1))
with open ('../../ data / movie_reviews_valid.vw', 'w') as vw_train_data:
for text, target in zip (valid, valid_labels):
vw_train_data.write (to_vw_format (str (text), 1 if target == 1 else -1))
with open ('../../ data / movie_reviews_test.vw', 'w') as vw_test_data:
for text in text_test:
vw_test_data.write (to_vw_format (str (text)))
Let's train a Vowpal Wabbit model with the following arguments:
! vw -d ../../data/movie_reviews_train.vw \ --loss_function hinge -f movie_reviews_model.vw --quiet
Let's make a prediction for lazy sampling using the trained Vowpal Wabbit model by passing the following arguments:
! vw -i movie_reviews_model.vw -t -d ../../data/movie_reviews_valid.vw \ -p movie_valid_pred.txt --quiet
We calculate the forecast from the file and calculate the proportion of correct answers and ROC AUC. Let's take into account that VW displays estimates of the probability of belonging to the class +1. These estimates are distributed over [-1, 1], so the binary answer of the algorithm (0 or 1) will simply be the fact that the estimate is positive. We get an AUC of 88.5% and a share of correct answers - 94.2% on the test sample and about the same on the test sample.
Code
with open ('movie_valid_pred.txt') as pred_file:
valid_prediction = [float (label)
for label in pred_file.readlines ()]
print ("Accuracy: {}". format (round (accuracy_score (valid_labels,
[int (pred_prob> 0) for pred_prob in valid_prediction]), 3)))
print ("AUC: {}". format (round (roc_auc_score (valid_labels, valid_prediction), 3)))
! vw -i movie_reviews_model.vw -t -d ../../data/movie_reviews_test.vw \ -p movie_test_pred.txt --quiet
with open ('movie_test_pred.txt') as pred_file:
test_prediction = [float (label)
for label in pred_file.readlines ()]
print ("Accuracy: {}". format (round (accuracy_score (y_test,
[int (pred_prob> 0) for pred_prob in test_prediction]), 3)))
print ("AUC: {}". format (round (roc_auc_score (y_test, test_prediction), 3)))
Accuracy: 0.88 AUC: 0.94
Let's try to improve the forecast by using bigrams. The quality improves slightly - up to 89% AUC and 95% correct answers.
Code
! vw -d ../../data/movie_reviews_train.vw \ --loss_function hinge --ngram 2 -f movie_reviews_model2.vw --quiet
! vw -i movie_reviews_model2.vw -t -d ../../data/movie_reviews_valid.vw \ -p movie_valid_pred2.txt --quiet
with open ('movie_valid_pred2.txt') as pred_file:
valid_prediction = [float (label)
for label in pred_file.readlines ()]
print ("Accuracy: {}". format (round (accuracy_score (valid_labels,
[int (pred_prob> 0) for pred_prob in valid_prediction]), 3)))
print ("AUC: {}". format (round (roc_auc_score (valid_labels, valid_prediction), 3)))
Accuracy: 0.894 AUC: 0.954
! vw -i movie_reviews_model2.vw -t -d ../../data/movie_reviews_test.vw \ -p movie_test_pred2.txt --quiet
with open ('movie_test_pred2.txt') as pred_file:
test_prediction2 = [float (label)
for label in pred_file.readlines ()]
print ("Accuracy: {}". format (round (accuracy_score (y_test,
[int (pred_prob> 0) for pred_prob in test_prediction2]), 3)))
print ("AUC: {}". format (round (roc_auc_score (y_test, test_prediction2), 3)))
Accuracy: 0.888 AUC: 0.952
Now let's see how Vowpal Wabbit actually handles large samples. There are 10 GB of StackOverflow questions - data link, there are exactly 10 million questions, and each question can have multiple tags. The data is pretty clean and don't call it bigdata even in the pub.

Of all the tags, 10 are selected, and the problem of classification into 10 classes is solved: according to the text of the question, one of 10 tags must be put, corresponding to 10 popular programming languages.
Data volume output
# change the data path PATH_TO_DATA = '/Users/y.kashnitsky/Documents/Machine_learning/org_mlcourse_ai/private/stackoverflow_hw/' ! du -hs $ PATH_TO_DATA / stackoverflow_10mln _ *. vw
1.4G /Users/y.kashnitsky/Documents/Machine_learning/org_mlcourse_ai/private/stackoverflow_hw//stackoverflow_10mln_test.vw 3,3G /Users/y.kashnitsky/Documents/Machine_learning/org_mlcourse_ai/private/stackoverflow_hw//stackoverflow_10mln_train.vw 1.9G /Users/y.kashnitsky/Documents/Machine_learning/org_mlcourse_ai/private/stackoverflow_hw//stackoverflow_10mln_train_part.vw 1.4G /Users/y.kashnitsky/Documents/Machine_learning/org_mlcourse_ai/private/stackoverflow_hw//stackoverflow_10mln_valid.vw
This is how the lines that Vowpal Wabbit will train on looks like. 10 means grade 10, then a vertical bar and just the text of the question.
10 | i ve got some code in window scroll that checks if an element is visible then triggers another function however only the first section of code is firing both bits of code work in and of themselves if i swap their order whichever is on top fires correctly my code is as follows fn isonscreen function use strict var win window viewport top win scrolltop left win scrollleft bounds this offset viewport right viewport left + win width viewport bottom viewport top + win height bounds right bounds left + this outerwidth bounds bottom bounds top + this outerheight return viewport right lt bounds left viewport left gt bounds right viewport bottom lt bounds top viewport top gt bounds bottom window scroll function use strict var load_more_results ajax load_more_results isonscreen if load_more_results true loadmoreresults var load_more_staff ajaxload_more_staff isonscreen if load_more_staff true loadmorestaff what am i doing wrong can you only fire one event from window scroll i assume not
Let's train the Vowpal Wabbit model with the following arguments on the training part of the sample (3.3 GB):
 features, which in this case is more than the number of unique words in the sample (but then bi- and trigrams will appear, and limiting the dimension of the feature space will start working)
features, which in this case is more than the number of unique words in the sample (but then bi- and trigrams will appear, and limiting the dimension of the feature space will start working)
VW training
%% time ! vw --oaa 10 -d $ PATH_TO_DATA / stackoverflow_10mln_train.vw \ -f vw_model1_10mln.vw -b 28 --random_seed 17 --quiet
CPU times: user 592 ms, sys: 220 ms, total: 813 ms Wall time: 39.9 s
The model was trained in just 40 seconds, for the test sample, it made predictions in another 14 seconds, the share of correct answers was almost 92%. Further, the quality of the model can be improved by several passes through the selection, using bigrams and setting parameters. This, together with data preprocessing, will be the second part of the homework.
VW quality rating
%% time ! vw -t -i vw_model1_10mln.vw \ -d $ PATH_TO_DATA / stackoverflow_10mln_test.vw \ -p vw_valid_10mln_pred1.csv --random_seed 17 --quiet
CPU times: user 198 ms, sys: 83.1 ms, total: 281 ms Wall time: 14.1 s
import os
import numpy as np
from sklearn.metrics import accuracy_score
vw_pred = np.loadtxt ('vw_valid_10mln_pred1.csv')
test_labels = np.loadtxt (os.path.join (PATH_TO_DATA,
'stackoverflow_10mln_test_labels.txt'))
accuracy_score (test_labels, vw_pred)
0.91868709729356979
Actual homework assignments are announced during the next session of the course, you can follow it in the VK group and in the course repository.
As a consolidation of the material, we propose to independently implement the algorithms for online training of the classifier and regressor. Fill in the missing code in the Jupyter notebook and select the answers in the web form (which will also contain the solution).

Comments
To leave a comment
Machine learning
Terms: Machine learning