Lecture
Teaching with partial involvement of the teacher
a pair of “situation, required solution” is set for a part of precedents, and for a part - only a “situation”
It is a small amount of data collected during training. Semi-supervised learning falls between unsupervised learning (without any labeled training data) and supervised learning (with completely labeled training data). There is a lot of data in it. This is a physical experiment or a physical experiment. Whereas the acquisition is not relatively cost-effective, it’s a relatively labeled training set. In such situations, semi-supervised learning can be of great practical value. Semi-supervised learning for a model for human learning.
As in the supervised learning framework, we are given a set of 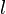 independently identically distributed examples
independently identically distributed examples 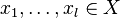 with corresponding labels
with corresponding labels 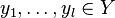 . Additionally, we are given
. Additionally, we are given 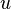 unlabeled examples
unlabeled examples 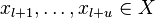 . It is not a problem to make a decision on how to use it.
. It is not a problem to make a decision on how to use it.
Semi-supervised learning may refer to either transductive learning or inductive learning. Inflaming data 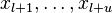 only. The correct mapping from
only. The correct mapping from 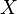 to
to 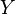 .
.
Intuitively, it can be solved in class. The teacher also provides a set of unsolved problems. There are some problems in particular. In the inductive setting, these will experience on the in-class exam.
It is unnecessary (and, according to Vapnik's principle, imprudent); however, in practice, formally designed algorithms for transduction or induction are often used interchangeably.
The data are subject to the data distribution. Semi-supervised learning assumptions. [one]
Points which are closest to each other. It is a preference for geometrically simple decision boundaries. In addition to the number of points in the case of semi-supervised children, it’s not a problem.
This is where you can see the label. This is a special case for learning how to use it with smoothing algorithms.
The data lie approximately on the bottom. In this case, you can try to learn how to use it. It can be used for distance learning.
It can be used when it comes to a number of degrees of freedom. For instance, human voice is controlled by a few vocal folds [2] , and images of various facial expressions are controlled by a few muscles. We would like to give you a chance to get rid of the problem, and you would like to have a problem.
This is the oldest approach to semi-supervised learning, [1] (see for instance Scudder (1965) [ 3] ).
The transductive learning framework was formally introduced by Vladimir Vapnik in the 1970s. [4] Interest in inductive learning using generative models also began in the 1970s. It is approximately correct to connect the seals to the galaxy. [5]
For example, there are data lines available for online use. For a review of recent work see a survey article by Zhu (2008). [6]
Approaches to statistical learning 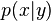 , the distribution of data points. The probability
, the distribution of data points. The probability 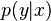 that a given point
that a given point 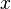 has label
has label 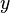 is then proportional to
is then proportional to 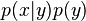 byBayes' rule. Semi-supervised learning (classification plus information about
byBayes' rule. Semi-supervised learning (classification plus information about 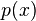 ) or as an extension of unsupervised learning (clustering plus some labels).
) or as an extension of unsupervised learning (clustering plus some labels).
Generative models assume that some distributions 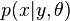 parameterized by the vector
parameterized by the vector 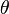 . It can be obtained from the labeled data alone. [7] However, if the assumptions are correct, then the unlabeled data necessarily improves performance. [five]
. It can be obtained from the labeled data alone. [7] However, if the assumptions are correct, then the unlabeled data necessarily improves performance. [five]
The distribution of individual-class distributions. There are different summed distributions. Gaussian mixture distributions are identifiable and commonly used for generative models.
The parameterized joint distribution can be written as 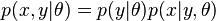 by using the Chain rule. Each parameter vector is associated with a decision function
by using the Chain rule. Each parameter vector is associated with a decision function 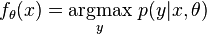 . The data is weighted by
. The data is weighted by 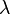 :
:
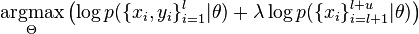
[eight]
There are few data points (labeled or unlabeled). One of the most commonly used vector algorithms, or TSVM (which, despite its name, may be used for inductive learning as well). It is a labeling of the data. In addition to the standard hinge loss 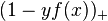 for labeled data, a loss function
for labeled data, a loss function 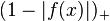 is introduced over the unlabeled data by letting
is introduced over the unlabeled data by letting 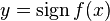 . TSVM then selects
. TSVM then selects 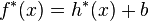 from a reproducing kernel Hilbert space
from a reproducing kernel Hilbert space 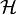 by minimizing the regularized empirical risk:
by minimizing the regularized empirical risk:
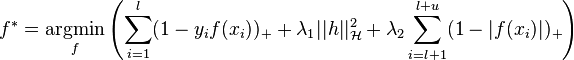
An exact solution is intractable due to the non-convex term , so research has focused on finding useful approximations. [eight]
Gaussian process models, information regularization, and entropy minimization (of which TSVM is a special case).
For example, it is possible to use the following examples: The graph may be constructed using domain knowledge or similarity of examples; two common methods  nearest neighbors
nearest neighbors  . The weight
. The weight 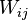 of an edge between
of an edge between 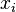 and
and 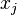 is then set to
is then set to 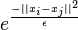 .
.
Within the framework of manifold regularization , [9] [10] the graph serves as a proxy for the manifold. The term is added to the ambient input space. The minimization problem becomes
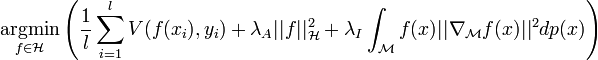 [eight]
[eight] where is a reproducing kernel Hilbert space and 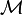 is the manifold on which the data lie. The regularization parameters
is the manifold on which the data lie. The regularization parameters 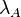 and
and 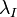 control smoothness in the ambient and intrinsic spaces respectively. The graph is used to approximate the intrinsic regularization term. Defining the graph Laplacian
control smoothness in the ambient and intrinsic spaces respectively. The graph is used to approximate the intrinsic regularization term. Defining the graph Laplacian 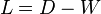 where
where 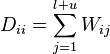 and
and 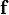 the vector
the vector 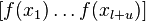 we have
we have
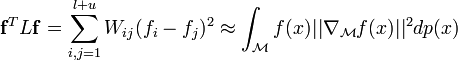 .
. It can be used to extend the semifinished squares and the Laplacian SVM.
It is not necessary to study the data, but it doesn’t make it possible to use it. For instance, the labeled and unlabeled examples 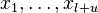 unsupervised first step. Then supervised learning proceeds from the labeled examples.
unsupervised first step. Then supervised learning proceeds from the labeled examples.
Self-training is a wrapper method for semi-supervised learning. It is a classifier based on the labeled data only. This is a classifier that has been applied to the supervised learning problem. There is no need for any label.
Co-training for those who have been trained in the field.
He added that he would like to give a response to the formal data (for a summary see [11] ). It is also possible to review the semi-supervised learning. The concept of the concept of a person during the childhood schooling combined with a large amount of unlabeled experience.
Human infants are sensitive to natural structures such as natural categories. [12] It’s not a problem. [13] [14]

Comments
To leave a comment
Machine learning
Terms: Machine learning