Lecture
In this article I want to consider several well-known methods of protecting site content from automatic parsing. Each of them has its advantages and disadvantages, so you need to choose based on the specific situation. In addition, none of these methods is a panacea, and for almost everyone has their own workarounds, which I also mention.
The simplest and most common way to determine when a site is being parsed is to analyze the frequency and frequency of requests to the server. If requests from too many IP addresses are too frequent or too many, then this address is blocked and in order to unblock it it is often suggested to enter a captcha.
The most important thing in this method of protection is to find the border between the natural frequency and the number of requests and the scrapping attempts so as not to block all non-wine users. This is usually determined by analyzing the behavior of normal users of the site.
An example of using this method is Google, which controls the number of requests from a specific address and issues a corresponding warning with the blocking of an IP address and a suggestion to enter a captcha.
There are services (like distilnetworks.com) that automate the process of tracking suspicious activity on your site and even turn on user verification with captcha.
This protection is bypassed by using multiple proxy servers that hide the real IP address of the parser. For example, services like BestProxyAndVPN provide inexpensive proxies, and the SwitchProxy service, although more expensive, is specifically designed for automatic parsers and allows it to withstand heavy loads.
In this method of protection, access to data is performed only by authorized users. This makes it easier to control user behavior and block suspicious accounts regardless of the client’s IP address.
An example is Facebook, which actively monitors user activity and blocks suspicious ones.
This protection is managed by creating (including automatic) multiple accounts (there are even services that sell ready-made accounts for well-known social networks, such as buyaccs.com and bulkaccounts.com). A significant complication of the automatic creation of accounts may be the need to verify the account by means of a telephone with verification of its uniqueness (the so-called PVA-Phone Verified Account). But, in principle, this also costs by buying a variety of disposable SIM-cards.
This is also a common method of protecting parsing data. Here, the user is invited to enter the captcha (CAPTCHA) to access the site data. A significant disadvantage of this method is the inconvenience of the user to enter a captcha. Therefore, this method is best applied in systems where data is accessed by individual requests and not very often.
An example of using captcha to protect against the automatic creation of queries can be services for checking the position of a site in search results (for example http://smallseotools.com/keyword-position/).
Cost captcha through programs and services for its recognition. They fall into two main categories: automatic recognition without human intervention (OCR, for example, the GSA Captcha Breaker program) and recognition with the help of a person (when people are sitting somewhere in India and processing requests for image recognition online, for example, Bypass CAPTCHA). Human recognition is usually more effective, but payment in this case occurs for each captcha, and not once, as when buying a program.
Here, in the request to the server, the browser sends a special code (or several codes), which are formed by complex logic written in JavsScript. At the same time, often the code of this logic is obfuscated and placed in one or several loadable JavaScript files.
A typical example of using this method of protection against parsing is Facebook.
It does this by using real browsers for parsing (for example, using the Selenium or Mechanize libraries). But this gives this method an additional advantage: executing a JavaScript parser will manifest itself in site attendance analytics (for example, Google Analytics), which will allow the webmaster to immediately notice what’s wrong.
One of the effective ways to protect against automatic parsing is to frequently change the page structure. This may concern not only the change of names of identifiers and classes, but even the hierarchy of elements. This greatly complicates the writing of the parser, but on the other hand complicates the system code itself.
On the other hand, these changes can be made in manual mode about once a month (or several months). This will also significantly ruin the life of the parsers.
To bypass such protection, it is required to create a more flexible and “smart” parser or (if changes are not made often) simply by manually correcting the parser when these changes occurred.
This allows you to make the parsing of a large amount of data very slow and therefore impractical. At the same time, restrictions should be chosen based on the needs of a typical user, so as not to reduce the overall usability of the site.
This is done by accessing the site from different IP addresses or accounts (simulated by many users).
This method of content protection makes it difficult to automatically collect data, while retaining the visual access to it by the average user. Often email addresses and phone numbers are replaced with pictures, but some sites manage to replace even random letters in the text with pictures. Although nothing prevents you from displaying the entire contents of the site in the form of graphics (either Flash or HTML 5), however, its indexation by search engines may be significantly affected.
The disadvantage of this method is not only that not all content will be indexed by search engines, but also that the user’s ability to copy data to the clipboard is excluded.
Such protection is difficult, most likely you need to use automatic or manual recognition of images, as in the case of captcha.
Chaotic intensive requests heavily load servers and transport channels, significantly slowing down the site. Using a scan, cybercriminals copy the content of the sites and identify weaknesses in their protection, causing significant damage. In addition, requests to the site, made during the scanning process, also adversely affect performance. Most often, the problem of slow work sites relates to large portals with high traffic. But it can also affect small sites, since even with low traffic, the site may be subject to high traffic. High load is created by various robots, constantly scanning sites. At the same time, the work of the site may slow down a lot, or it may not be available at all.
Scanning the site is done by programs, third-party sites or manually. This creates a large number of requests in a short period of time. Site scans are most often used to search for vulnerabilities in it or to copy site contents.
A sufficiently effective measure to protect the site from scanning will be the separation of access rights to the resources of the site. The information about the site structure will help to hide the apache mod_rewrite module that changes the links. And to make link scanning ineffective and, at the same time, setting the time delay between frequent requests from one user will help reduce the load. In order to maintain effective protection against scanning and chaotic intensive requests, a regular audit of web resources is necessary.
Chaotic intensive requests are random or malicious numerous requests in a short period of time on the site pages by users or robots. For example, random intensive requests include frequent page refresh. Malicious numerous requests include spam on the site’s pages from users or DoS attacks. Chaotic intensive requests also include a brute force selection method. You can choose a password both manually and with the help of special programs. A manual password is selected only in cases where its possible options are known. In other cases, special programs are used that automatically select a login and password pair, i.e. programs for bruteforce.
Effective methods to protect a site from chaotic intense requests include: setting a time delay between requests for a certain period of time, creating black and white lists, setting the search engines for a time delay between requests for website pages in a robots.txt file, and setting the period for updating pages in a sitemap .xml.
I implemented one of the methods to protect the site from scanning and chaotic intensive requests, which consists in counting the number of requests in a certain period of time and setting the time delay when the threshold is exceeded. In particular, this method makes an inefficient or even useless way to crack a password by iterating, because the time spent on the search will be too large. Ready php script under the hood.
At present, in practice, various approaches are used to protect any computer information, including information available on the Internet resource. These approaches can be defined by the following characteristics:
- the presence of formalized requirements, both for the recruitment and for the parameters of all protection mechanisms, which are regulated by the majority of modern requirements for ensuring general computer security (in other words, the requirements defining what exactly should be provided by developers);
- the presence of real protection mechanisms that are implemented in the process of protecting any computer information. These protection mechanisms are primarily related to protection tools built into the operating system, for the simple reason that most of the scripts used on the web server use the protection mechanisms built into the operating system or inherit the methods used in them. It is on the basis of these mechanisms and the methods used in them that the overall level of protection of the entire web server is determined;
- existing statistics of various threats to the security of computer information. In particular, this is data about successful attacks already carried out on any information resources. Maintaining this statistic is intended to help determine how effective the measures taken are, as well as to assess the level of requirements for creating protection on a web server.
As already mentioned, the most effective method for countering site scans, as well as all kinds of chaotic intensive requests, is to set some time delay between requests originating from the same user. When identifying a user, the focus should be on his IP address, for the reason that cookies can be easily deleted. Of course, the user's IP address can also be changed, for example, using a proxy server or using reconnection, if the user's IP address is dynamic, although this operation can take quite a long time, which in its the queue will negate all the efforts of the attacker.
This method of site protection should be implemented by writing a php-script. Using this kind of script will help protect the contents of the site from scanning conducted with the help of crawler programs and, at the same time, will help to significantly slow down the scanning of the site “manually”. In addition, the use of such a script will provide excellent security for absolutely all pages of the site from various types of chaotic intensive requests, which in turn will make it possible to reduce the load on the web server equipment.
The script developed should have the ability to customize. In particular, it is necessary to foresee the possibility of changing part of the script parameters. In other words, the script should be:
- the ability to configure the time blocking the user's IP address;
- it is possible to set the time interval during which the user's activity will be checked, in other words, the time during which the number of requests from one specific user will be recorded;
- the ability to set the number of requests that one user can send to the pages of the site during a specified time interval;
- the possibility of creating a list of "always resolved IP addresses." The IP addresses listed in this list will never be blocked;
- the possibility of creating a list of "always denied IP addresses", i.e. The script will always block IP addresses that are listed.
The advantages of creating and using such a php script can be considered:
- a significant reduction in the number of requests sent to the database server;
- significant savings in incoming and outgoing traffic on the web server;
- availability of convenient and flexible configuration of the most important parameters of the script;
- the possibility of a significant reduction in the load on the web server by users;
- copying all the information posted on the site will be very difficult or even impossible if there are a lot of pages on this resource.
The logic of the work of the developed site security system created in the form of a php-script is shown in the figure:
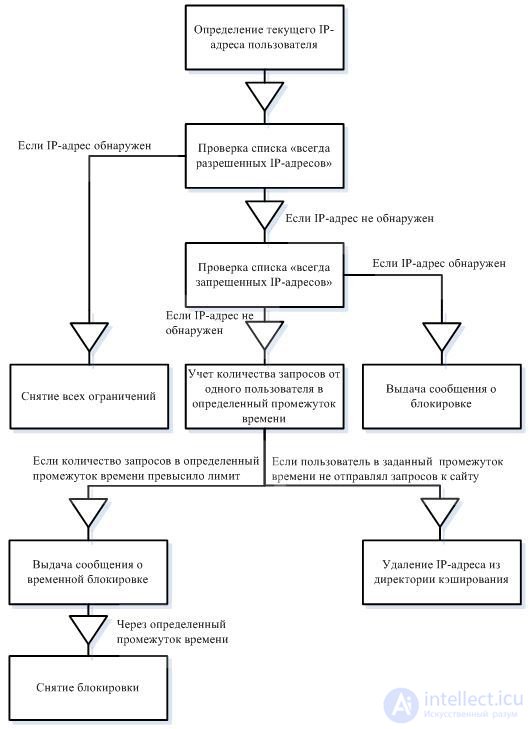
In the process of developing a script, an important point is the choice of how to store the information received. In our case, these are the IP addresses of current users. This information can be stored either in a database or on a hard disk. In order to speed up the work of the developed script, as well as to make it more stable, we will use caching directories to store the IP addresses of current users.
In one of these directories, the script will store the IP addresses of active, currently users, this directory will be called active. And in another directory we will add files, the name of which will include the IP addresses of temporarily blocked users (the block directory).
In addition to the IP-address, in the process of the script, you also need information about the user's activity. To do this, we will also enter the exact system time in the name of the file containing the IP address of the user, when he showed the “first”, at a specified time interval, activity, i.e. the first time in a certain (predetermined) period of time sent a request to the page of the site. If the user exceeded a predetermined number of sent requests to the site pages in a given time interval, the script will delete the file containing its IP address from the active users directory. After that, it will write a new file (the name of which will contain the IP address of the newly blocked user) in the directory containing the blocked IP addresses. Thus, in the caching directories (active and block), files with the following names will be temporarily stored: 127.0.0.1_12343242342 and the like.
The file name, before the bottom slash, will contain the IP address of the active user, and after the bottom slash, the exact system time will be entered in the file name, in which he was active (i.e. sent a request to the resource pages or was blocked).
Separately, it should be noted that for caching directories, i.e. the active and block folders, it is necessary to set the permissions of the owner of the file or 777. In other words, the attributes of the folder data specified on the server should give the script the right to write, read, and execute. Permissions 777 must be set for all user groups.
In addition, a separate exception should be provided in case the site administrator does not do this. Indeed, in such a situation, the work of the script will be impossible, which means that protecting the site from scanning and chaotic intensive requests will, at a minimum, be untenable. In other words, in the course of the script operation, the presence or absence of the possibility of reading and writing to any of the caching directories must be checked.
We will take information about current users (in particular, about their IP addresses) from the $ _SERVER [] superglobal array. This array is created by the web server.It contains the values of various environment variables. To work with users' IP addresses, we need to use the following environment variables contained in the $ _SERVER [] superglobal array:
- $ _SERVER ['HTTP_X_FORWARDED_FOR'];
- $ _SERVER ['HTTP_CLIENT_IP'];
- $ _SERVER ['HTTP_X_CLUSTER_CLIENT_IP'];
- $ _SERVER ['HTTP_PROXY_USER'];
- $ _SERVER ['REMOTE_ADDR'].
The $ _SERVER ['HTTP_X_FORWARDED_FOR'] environment variable allows us to determine the client’s IP address if it uses a proxy server. The $ _SERVER ['HTTP_CLIENT_IP'] environment variable allows you to get the client's IP address, if it does not use a proxy server, for browsing the Internet. The $ _SERVER ['HTTP_X_CLUSTER_CLIENT_IP'] environment variable allows you to get the client's IP address if the site does not use the SSL cryptographic protocol that provides a secure connection between the server and the client. The $ _SERVER ['HTTP_PROXY_USER'] environment variable allows you to determine the IP address of the client that the proxy server uses.
The $ _SERVER ['REMOTE_ADDR'] environment variable allows you to get the remote user's IP address. During testing on a local machine, this IP address will be 127.0.0.1. At the same time, in the network, this variable will return either the IP address of the client or the IP address of the last proxy server used by the user (with which this client got to the web server). Thus, using simultaneously many different environment variables from the $ _SERVER [] array (all the variables used are listed above), we will be able to determine the real IP address of the user, even if he tries to “mask” him with or proxy server.
For the stable operation of the script on any of the pages of the site, regardless of its nesting level, we will use the ability to bring to absolute form the paths to the caching directories (active and block). Using this approach will give us the opportunity to run the script from any page of the site and at the same time do not fear that the relative paths to the caching directories on any of the pages initially specified in the script will be incorrect.
As already mentioned, the script being developed must be customizable. In particular, it is necessary to foresee the possibility of changing part of the script parameters (the blocking time of the user's IP address, the time interval that takes into account the number of requests sent to resource pages, as well as the number of allowed requests in a given time interval). These parameters will initially be set in the script using constants.
In particular, such parameters in the script will indicate the following parameters:
- the blocking time of the user's IP address is specified in seconds (const blockSeconds);
- the time interval in which requests from one user to the site pages will be taken into account. This interval will also be specified in seconds (const intervalSeconds);
- the number of requests to the pages of the website that can be sent by one user over a specified time interval (const intervalTimes).
Separately, in the script, you should define such arrays containing string data:
- an array of values of those IP addresses that are included in the “list of always allowed IP addresses” (public static $ alwaysActive = array ('') array declaration);
- an array of values of those IP addresses that are included in the "list of always denied IP addresses" (public static $ alwaysBlock = array ('') array declaration).
It’s not a problem. It will also help to ensure that there is no need for additional information. These include:
- active flag (const isAlwaysActive);
- flag to connect always blocked users (const isAlwaysBlock).
The developed script contains one class TBlockIp. This class includes the following methods:
- checkIp (). This method implements the ability to check the user's IP address for its blocking or for activity. At the same time, the IP addresses listed in the "always allowed IP addresses" list are ignored, and the IP addresses listed in the "always denied IP addresses" list are blocked on the contrary. If the user's IP-address is not found in the array of possible IP-addresses - the script will create the identifier of the new active IP-address;
- _getIp (). This method allows you to get the current IP-address of the user, selected from all possible IP-addresses (filtering is performed before identifying the desired client IP-address). The method returns the received IP address.
Ultimately, the developed script can be considered as an effective tool that will help counteract the process of scanning the site, and will also be a preventive measure for all kinds of chaotic intensive requests. In the developed script there is a setting of some time delay between requests originating from the same user. When identifying a user, the focus is on his IP address. The reason for this is simple - the fact is that cookies can be easily deleted from the attacker's computer, which means that you cannot build resource protection using them.
Of course, the user's IP address can also be changed, for example, using a proxy server. In order to exclude such an opportunity for an attacker, the script uses environment variables, which in turn help to identify the real IP address of the user. It is this IP-address, if the user exceeds the established limit of requests to the site pages within a certain period of time, it will be blocked. The developed script performs all the functions assigned to it, related to the protection of the site from scanning, as well as from chaotic intensive requests.
Viewing and subsequent testing of written code is one of the most important stages in the development of php scripts. This stage is often missed by developers programming for the Web. The fact is that it is very easy to run a written script two or three times and note that it works fine. At the same time, this is a common mistake. After all, the created script must be thoroughly analyzed or tested.
The main difference between the developed php scripts and application programs is that an extremely wide circle of people will work with Web applications. In this situation, you should not rely on users to understand the use of various Web applications. Users can not provide a great guide or a quick reference. That is why the developed Web applications must be not only self-documenting, but also self-evident. When implementing a developed php-script, it is necessary to take into account various ways of using it, as well as to test its behavior in various situations.
It is often difficult for an experienced user or programmer to understand the problems that arise for inexperienced users. One way to solve the problem is to find testers who will represent the actions of typical users. In the past, the following approach was used: first, a beta version of the developed Web application was released to the market. After most of the errors were supposedly corrected, this application was published for a small number of users, who, respectively, would create a small amount of incoming traffic. After conducting this kind of test, developers get a lot of different combinations of data and use cases of the developed system, which its developers didn’t even guess [13, p. 394].
The created php-script should do exactly what, strictly speaking, it was created for. With regard to the php script developed and created in this work, you can say this: if the user can send for a certain period of time (15 seconds by default) more than the specified number of requests (3 requests by default) to the site pages and the script will not block its IP the address means an error has crept into the work of the written Web application. In general, testing is an activity that is aimed at identifying such inconsistencies that exist between the expected behavior of a written php script and its actual behavior. By identifying inconsistencies in the behavior of the script, as well as its incorrect behavior even during development, the developer has the opportunity to significantly reduce the likelihood that the user will encounter this kind of script behavior. You can test the program (in our case, written php-script) either manually or with the help of specialized online services.
When testing a written php script manually, we need to check whether the script performs the tasks assigned to it. In particular, does the number of requests to the pages of the site originating from the same user limit in the event that their frequency exceeds the allowable limit in a certain period of time. To test the performance of the script, we first need to embed it in the site code. To do this, you can use the following language construct:
include "block / index.php";
When enabled, the script should be located in the block folder. It should be noted that if the content management system of the site uses the creation of a so-called Friendly URL for the pages, i.e. web addresses that are convenient for human perception (in this case means creating some multi-level structures, for example, / news / sport / 2003/10 /), or loading pages with an address different from the root of the folder (for example, / news /sport.php), it will be necessary to correctly specify the address to the script. In such a situation, the absolute path to the script may well be indicated.
In itself, testing the written php-script will be to send requests to the pages of the site. In the process of testing, we need to check whether the created script passes the specified maximum number of requests (3 requests by default) for a certain period of time (15 seconds by default). First of all, we need to check how the script handles its main function, i.e. direct blocking of intensive requests to the site pages originating from the same user. Checking the number of requests that can be sent to the pages of the site showed that during the allotted fifteen seconds to send more than three requests to the pages of the site. In particular, if a user sends more than three requests, then he receives a temporary blocking message shown in the figure:
Thus, testing has shown that the script works exactly as expected: it blocks the user for a certain time (by default - for one minute) if, during a certain time interval, the number of requests from one user exceeds the specified rate (by default - 3 requests ). The next stage of testing will be the verification of the performance of individual functions written php-script. In particular, you need to check how the script will work if the IP address of the testing user is added to the list of "always allowed IP addresses". You also need to check how the script will behave if the testing user’s IP address is added to the “always denied IP addresses” list.
After adding the IP address of the testing user to the list of “always allowed IP addresses”, the restriction on the number of requests sent to the site’s pages was removed, and it was possible to follow the links (or refresh the page) an unlimited number of times. In other words, the function that the “always allowed IP addresses” list should perform correctly works. After adding the IP address of the testing user to the list of “always denied IP addresses”, it was not possible to send at least one request to the website page. Instead of the contents of the web resource, a blocking message appears in the browser, shown in the figure:
In other words, the function that the “always denied IP addresses” list should perform correctly. This function completely blocks the user whose IP address is included in the list of "always denied IP addresses." Thus, the access control functions that are implemented with the presence of a list of "always allowed IP addresses", as well as the presence of a list of "always denied IP addresses" work correctly and the script behaves exactly as originally intended. In other words, the script provides unrestricted access to the pages of the site for those users whose IP addresses are included in the list of "always allowed IP addresses" and completely denies access to those users whose IP addresses are found in the list of "always denied IP addresses". Testing a written php script manually showed that all functions of the script, and therefore the script itself, work correctly, i.e. exactly as originally conceived.
Testing a written php-script with the help of online services will provide an opportunity to find out the exact amount of traffic needed to load the pages of the site, as well as help to establish the exact “throughput” of the written php-script for requests that will be sent by various automatic services or programs. The last parameter is very important, because one of the tasks of the script is to protect the site from scanning with the help of crawler programs. This kind of testing will not only help to conclude about the required amount of traffic and CPU time, but also about whether the information presented on the website will be available for software tools that request pages automatically. To begin, let us estimate the average loading time of the site pages, at different connection speeds. We also estimate the size of the pages uploaded by the user To conduct this type of testing, we will use the online service located at analyze.websiteoptimization.com. The sizes of the loaded pages, determined by the service, are shown in the figure:
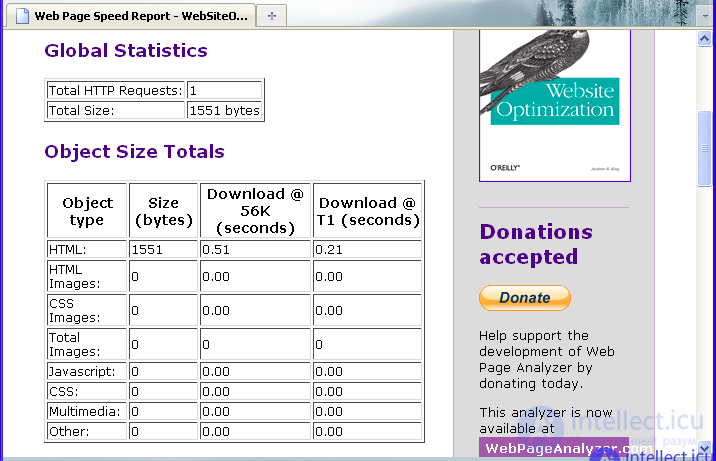
Given that the site we are testing consists of only one page, which is 1511 bytes in size, it will load in 0.51 seconds (at a connection speed of 56 K) or in 0.21 seconds (at a connection speed of a user of 1.44 Mbps) . The speed of loading pages at different user connection speeds is shown in the picture:
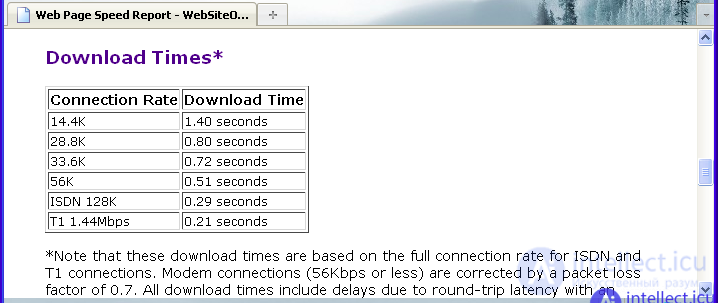
As can be seen from the information given in the figure, even at the lowest connection speed (14.4 K), the site page loads fairly quickly - in 1.4 seconds. At the same time, if the user’s connection speed is quite high (in particular, 1.44 Mbps), then the page will be loaded literally instantly (in 0.21 seconds). Note that the low download speed at this resource is adjusted by the packet loss rate (this factor is 0.7). Also taken into account is the delay time equal to 0.2 seconds on average per page load. It is these parameters that explain why a significant increase in connection speed does not lead to an equally significant reduction in page load time. Note that this service, in addition to assessing the basic parameters of loading pages, also provides general results of site analysis and, of course, recommendations aimed at improving all parameters of loading pages. The results of the analysis and recommendations of the service are shown in the figure:

As can be seen from the figure, all indicators of the tested site for all analyzed parameters are within the normal range. In particular, the service states that the number of pages on the site, the objects on them, as well as the sizes of these pages and objects are within acceptable limits. Based on the obtained data, optimization of the tested site is not required, because the site complies with the standards for all analyzed parameters. In other words, the amount of information downloaded from the site (or pages of the site) is rather small and allows saving resources of both the web server and the user. Those. the developed script does not load the site and, in fact, its presence is not noticeable. What underlines the testing. Checking the speed of loading pages of the site, as well as their availability for other scripts can be performed using an online service such as www.pr-cy.ru. The result of the test done using this online service is shown in the figure:
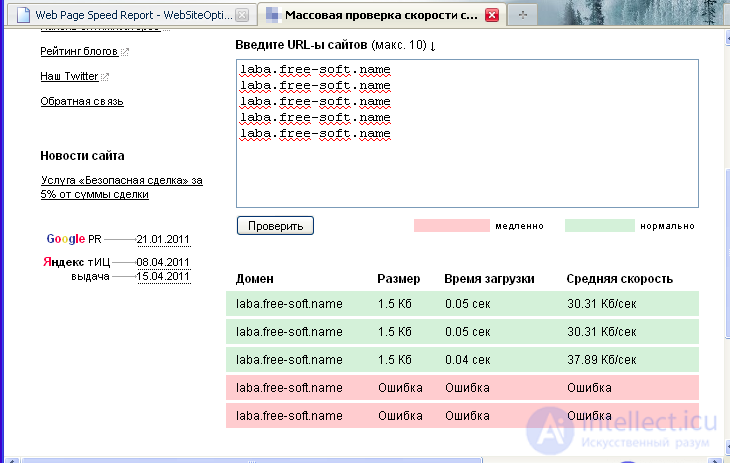
As can be seen, from the data obtained at an average download speed of 30.31 Kb / sec, the page loading time is 0.05 seconds. At the same time, with an average speed of 37.89 Kb / sec, the page loading time is already 0.04 seconds. At the same time, testing showed that the script developed in this work blocks more than three requests to site pages originating from a single IP address and thus reduces the overload and makes it very difficult to try or even make it impossible to find a password to the site.
The tests showed that the developed php-script perfectly copes with the functions initially assigned to it to protect the site from scanning, as well as from chaotic intensive requests and brute-force attempts from one user. In particular, testing the site manually showed that the script blocks requests to pages of the site that originate from the same IP address, if the number of these requests during a specified time interval exceeds the predefined limit. In addition, this testing showed that all the functions of the script work fine, in particular, the functions for working with lists of “always allowed IP addresses” and “always denied IP addresses”. In other words, the developed script provides unrestricted access to all pages of the site for those users whose IP addresses are included in the list of “always allowed IP addresses” and completely denies access to those users whose IP addresses are found in the list of “always denied IP addresses ".
Testing of the site, in which the developed php-script was implemented, showed that all indicators of the tested site for all analyzed parameters are within the normal range. In particular, the service states that the number of pages on the site, the objects on them, as well as the sizes of these pages and objects are within acceptable limits. Based on the obtained data, optimization of the tested site is not required, because the site complies with the standards for all analyzed parameters. In other words, the amount of information downloaded from the site (or pages of the site) is rather small and allows saving resources of both the web server and the user. Previously, the script was used on sites to learn English and English words, but later more serious protection measures were taken. However, at first, this script significantly reduced the load on inexpensive hosting and allowed to turn sites with an attendance of 5000+ hosts per day.
In addition, testing the site showed that the download speed of the pages of the test site is quite high. Also, the script blocked the testing of the site when the number of requests sent from the IP address of this online service exceeded the limit in the developed script (the maximum number of requests from one IP address set in the script is three requests in 15 seconds).
In other words, protecting the site from scanning and chaotic intensive requests works exactly as it was originally intended. In other words, if the number of requests originating from the same IP address (if the user's IP address is not in the list of "always allowed IP addresses" or in the list of "always denied IP addresses"), exceeds the allowed limit of a certain time interval, the user's IP address will be temporarily blocked regardless of whether requests were sent using a browser, a program, and whether a proxy server was used when sending requests (to disguise the user's real IP address).

Comments