Lecture
Это продолжение увлекательной статьи про конструирование психодиагностических тестов.
...
пространстве общих факторов, полученных методами факторного анализа исходного пространства признаков. И в той и в другой работе важное, если не решающее, значение придается психологическому осмыслению выделяемых группировок испытуемых. Возможность четкой интерпретации полученных группировок как определенных психологических типов служит достаточно веским доводом в пользу не случайного разбиения испытуемых на группы, которое могло бы произойти под действием какого-либо иррелевантного решаемой диагностической задаче фактора (отсюда, собственно, и проистекает название «типологический подход»).
The quality assessment of the diagnostic model obtained as a result of applying the typological approach is usually carried out by comparing with the usual linear diagnostic model built without dividing the objects of the training sample into groups. For example, the following indicator is used.
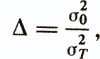
where σ20 is the residual variance of the usual linear regression model, and σ2T is calculated by the formula
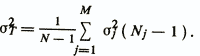
Here σ2j is the residual dispersion of the regression diagnostic model y j = y j ( x) for the group Gj, determined from the expression
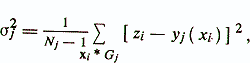
where N is the total number of subjects;
Nj - the number of subjects in the group Gj;
M is the number of groupings.
Also to test the hypothesis about the identity of a conventional linear regression model and a set of regression equations yj = yj (x), Fisher's F-criterion can be used / Eliseeva I. I. et al., 1977 /
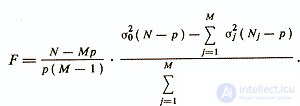
The effectiveness of a typological approach, for purely formal reasons, cannot be lower than the effectiveness of a conventional linear diagnostic model, which can be considered as a degenerate case of a piecewise linear model. At the same time, in addition to practical gain, the typological approach has a certain theoretical value - it reveals the relationship between the diagnosis of psychological features, as groups of characters, and psychological types, as groups of subjects. The ideal of the typological approach, notes B. V. Kulagin / 1984 /, is the development of such a method that will allow for each individual to choose the optimal diagnostic model.
The test result of the test person xi, calculated using the diagnostic model yi = y ( xi), is usually called the initial test score or, often, the “raw” score. For a better understanding of this result, among other results, it is further artificially transformed based on an analysis of the empirical distribution of test scores in a representative sample of subjects. The procedure for such a transformation is called standardization .
There are three main types of standardization of primary test scores: 1) reduction to normal form; 2) reduction to standard form; 3) quantile standardization / Melnikov V. M et al., 1985 /.
There are two main circumstances that explain the feasibility of artificially reducing the distribution of primary test scores to a normal form. Firstly, a significant part of the procedures of classical mathematical statistics was developed for random variables with Gaussian normal distribution. And, secondly, it makes it possible to describe diagnostic standards in a compact form.
To determine the method of conversion of y , histograms of the distribution of primary test estimates are usually considered. They allow you to identify left and right-sided asymmetry, positive or negative kurtosis and other deviations from normality. In psychological studies, logarithmic normal distributions of “raw” points are often encountered. In this case, the distribution of the distribution to the Gaussian form is achieved by logarithm y. On the contrary, trigonometric and power-law transformations of “raw” points are often used to normalize the distribution curves with a shallow left branch and a steep right one.
The use of computers allows you to automate the selection and fitting of the required conversion of primary test scores from a given class of analytical functions. Also, computers make it possible to quite simply implement the time-consuming, manual execution of the transition procedure to normally distributed estimates by digitizing the output test indicator. This procedure is usually simultaneously used to bring test scores to a standard form and will be discussed in detail below.
Under the standard form understand the linear transformation of the normal (or artificially normalized) test scores of the following type
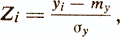
where Z i is the standard test score of the i-th subject;
yi is the normal score of the i-th subject;
tu and σ y is the arithmetic mean and the standard deviation of y.
Standard Z-scores are distributed according to the normal law with zero mean and unit variance. This is useful for benchmarking standard evaluations of various psychodiagnostic indicators. But since Z-scores can take fractional and negative values, which is inconvenient for perception, in practice weighted standard scores (Vi) are more often used.
Vi = a + bZi,
where a and b are the centering and proportionality constants, respectively. Parameter a makes sense in this case, the arithmetic mean value of the weighted standard estimate V, a b is interpreted as the standard deviation V.
In psychodiagnostics, the following centering and proportionality constants are most popular (General psychodiagnostics, 1987):
1. T-scale MacColl - a = 50, b = 10.
2. Scale IQ - a = 100, b = 15.
3. Stanine scale (integer values from 1 to 9 - standard nine) - a = 5.0, b = 2.
4. The “stanov” scale (standard ten) is a = 5.5, b = 2. As mentioned earlier, computers make it quite easy to nonlinearly normalize raw test values of y and move on to weighted standard estimates in any of the above scales. The procedure for such a transition is a new digitization of u and may look, for example, as follows. For any mark of the selected standard scale V , its percentile rank PR (Vk) = С is known . It is equal to the area under the theoretical normal distribution curve with the mean a and the standard deviation b calculated for V
An example of quantile standardization is the percentile standardization, when a new value of its percentile rank PR (y) is assigned to the “raw” scale y . Quantile is a general concept, special cases of which may be, for example, except percentiles, quartiles, quintiles and deciles. Three apartment marks (Q1, Q2, Q3 ) break the empirical distribution of test scores into 4 parts (quarts) in such a way that 25% of subjects are below Q1, 50% below Q2 and 75% below Q3. Four quintels (K1, K2, Kz, K4) divide the sample in the same way into 5 parts with a step of 20% and nine deciles (D1, ..., D9) divide the sample into ten parts with a step of 10%.
The corresponding quantile number is used as the new converted test score. The quantile scale differs in that its construction is in no way connected with the type of distribution of primary test scores, which may be normal or have any other form. The only condition for its construction is the possibility of ranking the subjects by the value of y. Quantile ranks have a rectangular distribution, that is, each interval of the quantile scale contains the same proportion of the examined persons / B. V. Kulagin, 1984 /. Standardizing test scores by translating them into a quantile scale erases the differences in the features of the distribution of psychodiagnostic indicators, since it reduces any distribution to a rectangular one. Therefore, from the standpoint of the theory of measurements, quantile scales refer to scales of order: they provide information on which of the subjects tested property is more pronounced, but they do not allow us to say anything about how much or how many times stronger.
The constructed diagnostic model can be considered a psychodiagnostic test only after passing comprehensive tests for the assessment of psychometric properties. The main psychometric properties of psychodiagnostic methods, except for standardization, are reliability and validity / Anastasi A., 1982; Gaida, V.K. et al., 1982; Gilbukh Yu. 3., 1982; 1986; Kulagin B.V., 1984; General Psychodiagnostics, 1987; Burlachuk LF, et al., 1989 /.
The reliability of the test is a characteristic of the technique, reflecting the accuracy of psychodiagnostic measurements, as well as the stability of the test results to the action of extraneous random factors / Burlachuk LF et al., 1989 /.
The result of psychological research is usually influenced by a large number of unrecorded factors (for example, emotional state and fatigue, if they are not included in the range of studied characteristics, light, temperature and other features of the room in which testing is carried out, the level of motivation of the subjects, etc.). Therefore, any empirically obtained estimate for the test yi is represented as the sum of the true estimate of y ¥ and the measurement error ε: yi = y ¥ + e. In order to analyze the reliability, the concept of “parallel tests” is introduced, which are tests that measure this property equally by means of the same actions and operations / Kulagin B. V., 1984 /. This concept is generalized, since parallel tests can be both parallel forms and repeated examinations of subjects with the same method. If one assumes that the properties measured by individuals change little over time, and the errors are completely random and non-systematic, then parallel tests give results with the same mean values, standard deviations, intercorrelations and correlations with other variables.
The reliability coefficient Ryy is defined as the correlation of parallel tests, which, in turn, is equal to
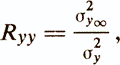
where σ2u ¥ Is the variance of the true estimate, and σ2у is the variance of the empirical estimate.
The correlation of parallel tests with any other variable z is determined by the ratio
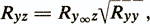
where is Ry ¥ z - correlation of true estimates of i> y ¥ with variable z. This formula shows that the correlation of the test with any external variable is limited by the reliability coefficient. For example, if the correlation of the true estimate of y ¥ with the variable z ( Ry ¥ z ) is 1.0, and the reliability coefficient (Ryy) is 0.70, then the empirical correlation (Ryz) will be 0.84.
The reliability coefficient is related to the standard measurement error (σε is the standard deviation of measurement errors ε)
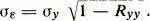
It follows that with an increase in the reliability coefficient Ryy , the error σε decreases.
Correlation of empirical and true Ryy ¥ estimates called the reliability index and is determined by the ratio
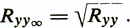
There are three main approaches to assessing the reliability of tests, which differ in factors taken as measurement errors.
Test retest reliability. The reliability coefficient (Ryy) is measured by re-examining the same subjects over a certain time period and is equal to the correlation coefficient of the results of the two tests. Measurement errors in this case are due to differences in the condition of the subjects, organization and conditions of repeated examinations, memorization of answers, the acquisition of skills to work with the test, etc. Test-retest reliability is also called reliability - sustainability.
Reliability of parallel test forms . The reliability coefficient is equal to the correlation of parallel test forms. Measurement errors in this case, in addition to the above factors, are associated with differences in the nature of the actions and operations inherent in parallel forms of the test. The high value of the correlation coefficient, in addition to the high reliability of the results of the compared tests, indicates the equivalence of the content of these tests. Therefore, the reliability coefficient for parallel forms of the test is another name - equivalent reliability.
Reliability as homogeneity of tests. In this case, reliability is estimated by calculating the intercorrelations of parts or elements of the method, considered as separate parallel tests. This approach is valid for the evaluation of tests, the construction of which used a diagnostic model based on the criteria of autoinformativeness of the system of initial features (based on the principle of internal consistency of test tasks). The most common procedure splitting the test into two parts: one includes, for example, the results of even tasks, and the other odd. To determine the reliability of the whole test, the Spearman-Brown formula is used:
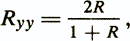
where R is the correlation between the dough halves.
Taking into account the fact that a test built on the principle of internal consistency of tasks can be split into parts in different ways, the Cronbach coefficient is often used in psychometrics to assess reliability
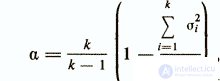
where a is the designation of the Cronbach coefficient;
k is the number of test tasks;
σ2 i is the variance of the i-ro test item;
σ2у —dispersion of the whole test.
If the answers to each item of the test are dichotomous variables, then the Cüder-Richardson formula, similar to the Kronbach coefficient, is used.
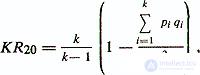
where KR20 is the traditional designation of this safety factor;
pi is the share of the 1st answer to the i-th question;
qi = (1 - pi) - the proportion of the second answer to the i-question.
Other safety factors for homogeneous tests are known. Most of the criteria underlying these coefficients are based on the fact that the matrix of the intercorrelation of tasks of a reliable test has a rank close to one. For example, the coefficient applied is called theta reliability of the test / General Psychodiagnostics, 1987 /:
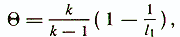
where k is the number of test items.
l1 is the largest eigenvalue corresponding to the 1st main component of the test point intercorrelation matrix.
The above formulas can be used only when each subject is working with all the elements of the test. This applies to techniques that do not have time limits. Regardless of the fulfillment of this condition, the reliability of individual psychodiagnostic test items is often assessed.
The reliability of individual test items. Retest reliability of the test as a whole depends on the stability of the answers of the subjects to individual test items. To test this robustness, a correlation is calculated between the answers of the subjects to the item being checked and the answers during repeated testing. For dichotomous items, the coefficient φ is usually used and the point is considered not sufficiently stable if φ <0.5.
Also, the so-called discriminativeness of test assignments is often checked / Burlachuk LF et al., 1989 /, which refers to the ability of individual items to differentiate the subjects with respect to the “maximum” or “minimum” test result as a whole. The procedure of checking the reliability of items is aimed at improving the internal consistency of the test and corresponds to the previously described method of contrasting groups. As a measure of the reliability point can be used the coefficient φ . In addition, the point-based bisterial correlation coefficient r rv, which in this case is called the discrimination coefficient (index), is often used.
In contrast to reliability, validity is a measure of the conformity of test evaluations to the ideas about the nature of properties or their role in a particular activity / Kulagin B.V., 1984 /. There are three main types of validity - content, empirical (criterial) and construct (conceptual).
Content validity characterizes the degree of representativeness of the content of the test tasks of the measured area of mental properties / Burlachuk LF et al., 1989 /. Traditionally, this characteristic has the greatest value for tests that investigate activities that are close to or coincide with real (most often academic or professional). Since this activity often consists of heterogeneous factors (manifestations of personality abilities, a complex of necessary knowledge and skills, specific abilities), the selection of tasks covering the main aspects of the phenomenon under study is one of the most important tasks of forming an adequate model of the activity being tested. The validity of the content is laid in the test already in the selection of tasks for the future methodology. This question is discussed above when it came to the formation of the initial set of diagnostic features. The conclusion about the substantive validity, as a rule, is made by experts, who make a judgment about the extent to which this test covers the declared properties and phenomena.
Content validity must be distinguished from obvious, facial, external validity, which is such from the point of view of the subject. Obvious validity means the impression about the subject of measurement, which is formed in the subjects when they get acquainted with the instruction and test material. It also plays a significant role in testing, since it primarily determines the attitude of the subjects to the examination. Therefore, the obvious validity is sometimes called trust validity. In some cases, the content and external validity coincide, in others - obvious validity is used to mask the true objectives of the study.
Empirical validity - a set of characteristics of the validity of the test, obtained using comparative statistical analysis. The indicator of empirical validity is expressed by a quantitative measure of the statistical relationship between the test results and the external criteria for evaluating the diagnosed property. As such criteria, expert assessments, experimental and “life” criteria, which have already been considered before, can be used. Empirical validity is most often expressed by the correlation coefficient of test results y with the criterion index z. It is known that the correlation of two variables depends on their reliability:
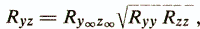
where Ry ¥ z ¥ is the correlation between the true values of the test and the criterion; Ryy - test reliability; Rzz - criterion reliability. This formula shows that the maximum possible validity is limited by the reliability values of the test and the external criterion.
Empirical validity may be represented by other indicators. For example, if the external criterion is characterized by a dichotomous variable, the percentage of persons whose assessments are in the overlap of the distribution of indicators by test in dichotomous groups can act as an indicator of empirical validity / Dunnette MD, 1966 /. Also a common way of presenting a statistical connection of test results is a tabular form in which the intervals of test scores are compared with the probabilities of the subjects belonging to different diagnostic classes.
When evaluating the empirical validity of tests, it is necessary to establish it in at least 2 groups, since the correlation between the test and the criterion may be due to factors specific to the sample and not have a common meaning / B. Kulagin, 1984 /. It is especially important that the validity of the test is determined on a sample of subjects, different from the one with which the selection of tasks was carried out / Anastasi A., 1982 /. To fulfill this condition, it is possible, for example, to split the available experimental material in half. At the same time, it is preferable to conduct several studies with subsequent analysis and synthesis of the data obtained.
Constructive validity is the validity of the test in relation to a psychological concept - a scientific concept (or their totality) about a measured mental property (state). It expresses the degree of validity of the individual differences found by the test from the standpoint of modern theoretical knowledge. A common method of determining the constructive validity of a test is its correlation with known methods, reflecting other constructs, presumably both related and independent of this one. An attempt is made to a priori predict the presence or absence of a connection between them. Tests that are supposedly highly correlated with a validating test are called converging, and non-correlating tests are discriminant. Conceptual validity can be considered satisfactory if the correlation coefficients of a validated test with a group of converging tests are statistically significantly higher than the coefficients of correlation with a group of discriminant tests. Confirmation of a set of expected relationships constitutes an important range of constructive validity and is also called “presumptive validity” in foreign literature.
In conclusion, the chapters will present in a compressed form all the stages of constructing a psychodiagnostic test and briefly describe the main operations at these stages. Modern methodology of psychological testing considers the most optimal rational-empirical strategy for solving this problem / General psychodiagnostics, 1987 /.
1) Formation of the initial version of the psychodiagnostic test.
- Theoretical analysis of the diagnosed construct, the development of the theoretical concept of the tested property. Identification (using literature) of a system of interrelated diagnostic constructs, within which a new diagnostic construct is characterized by certain structural and functional connections and relationships. Prediction of the results of correlation experiments to verify constructive validity.
- Isolation of the constituent parts of a theoretical construct, the formation of a system of "empirical indicators" (system of initial features) - operationally unambiguous indicators that fix the manifestation of the construct in various behavioral situations. Designing test items.
In case of borrowing of separate parts of a new test, well-known psychodiagnostic methods are used to select such methods (as a rule, multidimensional tests), some of which are theoretically capable of reflecting the required diagnostic property.
- Formulation of a relevant external criterion that will be used to verify the empirical validity of the test and can also be used in empirical-statistical data analysis to determine the parameters of the diagnostic model.
2 ) Conducting experimental surveys and determining the parameters of diagnostic models.
- Planning and conducting a survey of the original version of the psychodiagnostic test of a specially selected sample of subjects for whom the values of the criterion indicator are known (or will be known), as well as the results of related tests. If necessary, additional tests are carried out on these subjects in order to ensure further verification of the constructive validity of the new test (expert assessments in this case are considered as one of the parallel procedures for obtaining criteria or psychological information).
Currently, there is no unequivocal answer to the question about the size of the sample being surveyed. At least, such a response cannot be given a priori until an exploratory statistical analysis is carried out and the type of distributions of the variables studied are established. The study of a large number of real-world problems of multidimensional data analysis shows that the bulk of the experimental data tables used contained from 30 to 200 objects and the median of the empirical distribution of the sample size was 100 / V. V. Aleksandrov and others, 1990 /. Depending on the sample size, different statistical criteria are used. The problem of small sampling in the construction of linear decision rules is considered, for example, in / Raudis S. et al., 1975 /.
- Determination of the parameters of diagnostic models (selection of informative test items, finding weighting factors) is performed using the methods of multivariate statistical analysis described in this chapter. These methods are fully implemented in almost all known software packages for statistical data processing such as STATGRAPHICS, SPSS, BMDP, which operate on personal computers. However, as noted above, the specificity of psychological measurements (high dimensionality, nominal and qualitative character of the initial features) leaves its mark on the use of these methods in psychodiagnostics. Often it is impractical, and even impossible to use the classic version of a method. Often, it makes sense for a researcher to limit himself to simplified models of these methods and to focus on their implementation in the form of feature selection and the most approximate assessment of weights for test items that are included in the rule for calculating the resulting psychodiagnostic indicator.
3) Analysis of the distribution of test points, the construction of test standards and verification of their representativeness.
Table. Methods for determining the parameters of diagnostic models
Open the table »» »
When building test norms, the psychologist must perform the following actions / General Psychodiagnostics, 1987 /.
- Form a sample of standardization (random or stratified by any parameter) from the population on which the test is supposed to be applied. Conduct a test on every test subject in a short time (to eliminate the irrelevant variation caused by external events that occurred during the survey).
- To group the "raw" points based on the selected quantization interval.
- Build the distribution of frequencies of test points (for given intervals) in the form of a table and in the form of the corresponding graphs of the histogram and cumulates.
- To calculate the average and standard deviations, as well as asymmetry and kurtosis. Test hypotheses about the significance of asymmetry and kurtosis. Compare test results with visual analysis of distribution curves.
- Check the normality of the distribution of frequencies of test points using, for example, the Kolmogorov criterion or using other more powerful criteria.
- If the hypothesis of normal distribution is rejected, perform a percentile normalization with translation to the selected standard scale. Check the stability of the distribution by splitting the sample into two random halves. If the normalized scores match for half and for the whole sample, consider the normalized scale to be stable.
- Check the uniformity of distribution with respect to the variation of a given population trait (gender, profession, etc.) using the Kolmogorov criterion. Construct in combined coordinates histogram graphs and cumulates for complete and private samples. With significant differences in these graphs, split the sample into heterogeneous samples.
- Build tables of percentile and normalized test norms (for each interval of "raw" points). If there are heterogeneous samples, each of them has its own table.
- Determine the critical points (upper and lower) for the confidence intervals (at the level of -P - Discuss the configuration of the obtained distributions taking into account the proposed mechanism for solving one or another test. - In case of negative results - lack of stability of norms for a scale with a given number of gradations (with a given accuracy) - carry out a survey of a wider sample or abandon the plan for using this test. 4) Reliability analysis. - For tests built on the principle of internal consistency (without using external criteria), the reliability coefficients are calculated using the formulas 2.69-72. - If there are results of the standardization sample survey with parallel test forms, then the correlation coefficients of these results with the points obtained using the new test are calculated. - Testing reliability as resistance to retesting is absolutely necessary in the diagnosis of properties, in relation to which, invariance in time is theoretically expected. The analysis of retest reliability can be (as well as the analysis of reliability - consistency) combined with the study of the informativeness of individual items. 5) Analysis of validity. The correlation coefficients of the constructed test with the relevant external criterion are calculated, as well as with the results of additional tests for the evaluation of construct validity. The requirements for a psychometrist who develops a psychodiagnostic test are set forth in / Burlachuk LF et al., 1989 /. It also sets out the requirements for the use of computers in psychodiagnostics. LITERATURE продолжение следует... Продолжение:
Часть 1 Designing psychodiagnostic tests: traditional mathematical models and algorithms
Часть 2 Contrast group method - Designing psychodiagnostic tests: traditional mathematical models
Часть 3 6. Standardization and testing of diagnostic models - Designing psychodiagnostic
Часть 4 - Designing psychodiagnostic tests: traditional mathematical models and algorithms

Comments
To leave a comment
Mathematical Methods in Psychology
Terms: Mathematical Methods in Psychology