Lecture
Semaphore (English semaphore ) - an object that limits the number of threads that can enter a given piece of code. Definition introduced by Edsger Dykstra. Semaphores are used to synchronize and protect data transmission over shared memory, as well as to synchronize the work of processes and threads.
A semaphore is an object on which you can perform three operations.
Initializing the semaphore (set the initial value of the counter):
init (n):
counter: = n
Capture semaphore (wait until the counter becomes greater than 0, then reduce the counter by one):
enter ():
counter: = counter - 1
Semaphore release (increase counter by one):
leave ():
counter: = counter + 1
Suppose there is such a piece of code:
semaphore.init (5);
// .....
// .....
void DoSomething ()
{
semaphore.enter ();
// .......
semaphore.leave ();
}
Then no more than five threads can simultaneously execute the DoSomething() function.
More complex semaphores can use a queue; however, threads waiting for the semaphore to be released will pass through the semaphore in exactly the order in which they called enter() .
Some of the problems that semaphores can solve are:
The following example shows how to set up sequential access to the console.
semaphore.init (1);
// Stream 1:
semaphore.enter ();
cout << "Array Status:";
for (int i = 0; i
// Stream 2:
semaphore.enter ();
cout << "Esc is pressed. \ n";
semaphore.leave ();
This code will help prevent the appearance of output like
Array Status: 1 2 3 Esc. 4 5 6
First, you can write a program with a “semaphore leak” by calling enter() and forgetting to call leave() . Errors are less common when leave() is called twice.
Secondly, semaphores are fraught with interlocking threads. In particular, such code is dangerous:
// Stream 1:
semaphore1.enter ();
semaphore2.enter ();
// ...
semaphore2.leave ();
semaphore1.leave ();
// Stream 2:
semaphore2.enter ();
semaphore1.enter ();
// ...
semaphore1.leave ();
semaphore2.leave ();
Jeff Preshing (Jeff Preshing) - Canadian software developer, the last 12 years working in Ubisoft Montreal. He had a hand in the creation of such famous franchises as Rainbow Six, Child of Light and Assassin's Creed. In his blog, he often writes about interesting aspects of parallel programming, especially in relation to Game Dev. Today I would like to submit to the public the translation of one of Jeff's articles.
The flow must wait. Wait until you can get exclusive access to the resource or until the tasks for execution appear. One of the wait mechanisms in which the thread is not put to execution by the OS kernel scheduler is implemented using a semaphore.
I used to think that semaphores were long outdated. In the 1960s, when few people were still writing multi-threaded programs, or any other programs, Edsger Dijkstra proposed the idea of a new synchronization mechanism - a semaphore. I knew that with the help of semaphores, one can keep track of the number of available resources or create an awkward analogue of a mutex, but this, as I believed, limits their scope.
My opinion changed when I realized that using only semaphores and atomic operations, you can create all the other synchronization primitives:
All these primitives are lightweight in the sense that some operations on them are performed completely in userspace, and they can (this is an optional condition) spin for a while in a loop before requesting a thread blocking from the operating system (examples are available on GitHub.) my primitive library has a Semaphore class that wraps the system semaphores of Windows, MacOS, iOS, Linux and other POSIX-compatible OSs. You can easily add any of these primitives to your project.
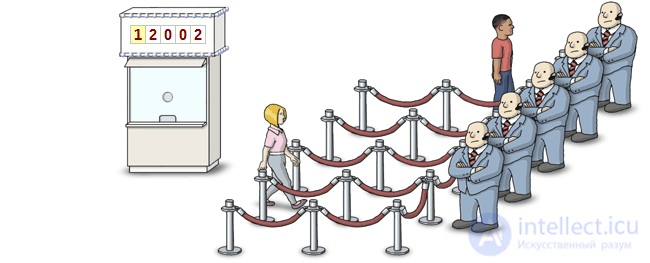
Imagine the many threads waiting to be executed, lined up, just like a line before entering a trendy nightclub. A semaphore is a bouncer in front of the entrance. He allows to go inside the club only when he is given the appropriate instructions.
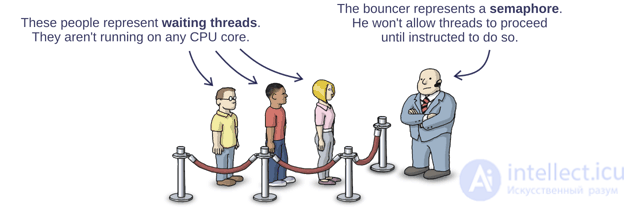
Each thread itself decides when to stand in this queue. Dijkstra called this operation P , which was probably a reference to some funny-sounding Dutch term, but in modern semaphore implementations, you will most likely find only a wait operation. In fact, when a thread calls the wait method, it becomes a queue.
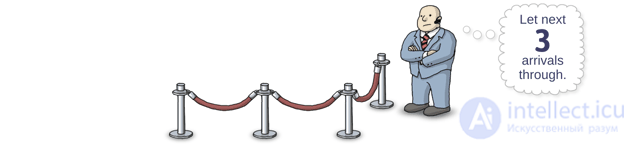
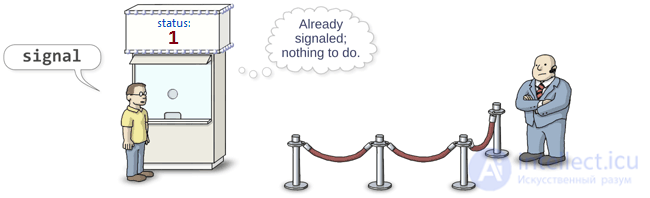
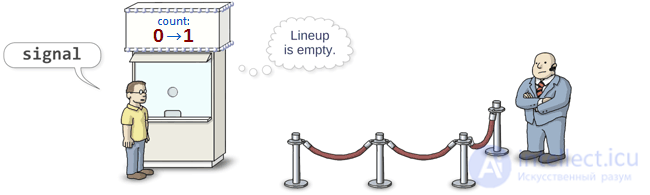
The bouncer, i.e. semaphore, should be able to do only one operation. Dijkstra called this operation V. To date, there is no agreement on how to call this operation. As a rule, you can meet the functions post , release or signal . I prefer signal . When this method is called, the semaphore “releases” one of the waiting threads from the queue. (It’s not necessarily the same thread that caused the wait before others.)
And what happens if someone calls signal when there are no threads in the queue? No problem: when any of the threads call wait , the semaphore will immediately skip this thread without blocking. Moreover, if the signal is called 3 times in a row with an empty queue, the semaphore will allow the next three threads that caused wait to bypass the queue without waiting.
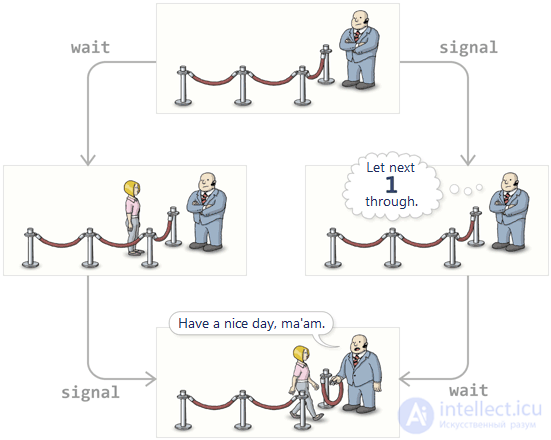
It goes without saying that the semaphore should count the number of signal calls with an empty queue. Therefore, each semaphore is provided with an internal counter, the value of which increases when the signal is called and decreases when the wait is called.
The beauty of this approach is that regardless of the order in which the wait and signal are called, the result will always be the same: the semaphore always misses the same number of threads for execution, and the same number of pending will always remain in the queue.
I have already told you how to implement your own lightweight mutex in a previous article. At that time, I did not know that this is only one example of the application of a common pattern, the main idea of which is to delegate decisions about blocking flows of some new entity - box office. Should the current thread wait in the queue? Should he pass the semaphore without waiting? Should we wake up some other thread?
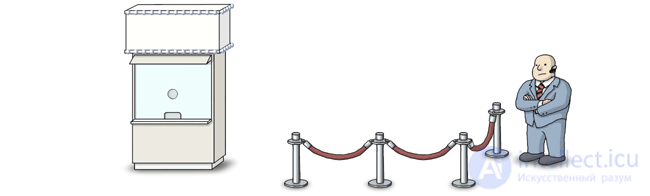
Box office does not know anything about the number of threads waiting in the queue, nor does it know the current value of the internal semaphore counter. Instead, he must somehow keep a history of his own states. If we are talking about the implementation of a lightweight mutex, then a single counter with atomic increment and decrement operations is enough to store the history. I called this counter m_contention , because it stores information about how many threads at the same time want to capture the mutex.
class LightweightMutex { private: std::atomic m_contention; // The "box office" Semaphore m_semaphore; // The "bouncer"
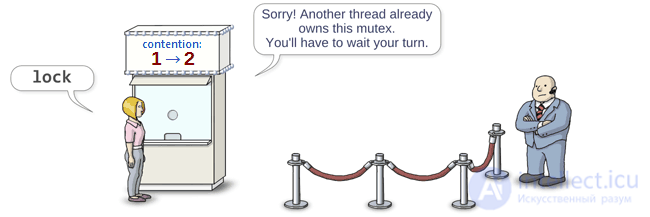
When a thread wants to capture a mutex, it accesses the box office, which in turn increases the value of m_contention .
public: void lock() { if (m_contention.fetch_add(1, std::memory_order_acquire) > 0) // Visit the box office { m_semaphore.wait(); // Enter the wait queue } }
If the counter value is zero, then the mutex is in an unmarked state. In this case, the current thread automatically becomes the owner of the mutex, bypasses the semaphore without waiting, and continues to work in the code section protected by the mutex.
If the mutex is already captured by another thread, then the counter value will be greater than zero and the current thread should wait for its turn to enter the critical section.
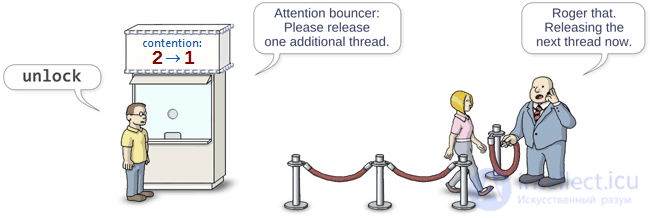
When a thread releases a mutex, box office reduces the internal counter value by one:
void unlock() { if (m_contention.fetch_sub(1, std::memory_order_release) > 1) // Visit the box office { m_semaphore.signal(); // Release a waiting thread from the queue } }
If the count before decrement was less than 1, then there are no waiting threads in the queue and the value of m_contention simply remains equal to 0.
If the counter value was greater than 1, then another thread or several threads tried to capture the mutex, and, therefore, are waiting for their turn to enter the critical section. In this case, we call the signal so that the semaphore will wake up one of the threads and enable it to capture the mutex.
Each call to the box office is an atomic operation. Thus, even if multiple threads call lock and unlock in parallel, they will always access the box office sequentially. Moreover, the behavior of a mutex is completely determined by the internal state of the box office. After accessing the box office, threads can call the semaphore methods in any order, and this will in no way break the consistency of the execution. (In the worst case, threads will fight for a place in the semaphore line.)
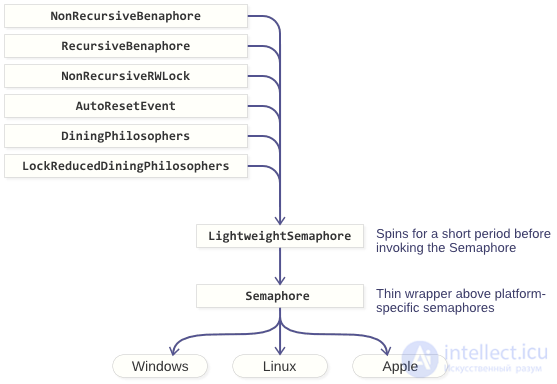
This primitive can be called "lightweight", since it allows the stream to capture the mutex without recourse to the semaphore, i.e. without making a system call. I published a mutex code on GitHub called NonRecursiveBenaphore, and there is also a recursive version of a lightweight mutex. Nevertheless, there are no prerequisites for using these primitives in practice, since most of the known implementations of mutexes are lightweight anyway. However, this code serves as a necessary illustration of the approach used for all other primitives described in this article.
Note Lane: in the original, the author called this primitive Auto-Reset Event Object, however, search engines for such a query give references to the C # class AutoResetEvent, whose behavior can be compared with std :: condition_variable with some assumptions.
At CppCon 2014, I noted for myself that conditional variables are widely used when creating game engines, most often for notifying one thread of another (possibly in standby mode) about the presence of some work for it ( comment: as such work perform the task of unpacking graphic resources and loading them in the GL context ).

In other words, no matter how many times the signal method is called, the internal counter of the condition variable should not become greater than 1. In practice, this means that you can queue tasks for execution by calling the signal method each time. This approach works even if a data structure other than queue is used to assign tasks for execution.
Some operating systems provide system tools for organizing conditional variables or their analogues. However, if you add several thousand tasks to a queue at a time, the signal method calls can greatly affect the speed of the entire application.
Fortunately, the box office pattern can significantly reduce the overhead associated with calling the signal method. The logic can be implemented inside the box office entity using atomic operations so that the semaphore is accessed only when it is necessary to make the thread wait for its turn.
I implemented this primitive and called it AutoResetEvent. This time the box office uses a different way of counting the number of threads waiting in the queue. With a negative m_status , its absolute value indicates the number of threads waiting on the semaphore:
class AutoResetEvent { private: // m_status == 1: Event object is signaled. // m_status == 0: Event object is reset and no threads are waiting. // m_status == -N: Event object is reset and N threads are waiting. std::atomic m_status; Semaphore m_sema;
In the signal method, we atomically increase the value of the m_status variable until its value reaches 1:
public: void signal() { int oldStatus = m_status.load(std::memory_order_relaxed); for (;;) // Increment m_status atomically via CAS loop. { assert(oldStatus <= 1); int newStatus = oldStatus < 1 ? oldStatus + 1 : 1; if (m_status.compare_exchange_weak(oldStatus, newStatus, std::memory_order_release, std::memory_order_relaxed)) break; // The compare-exchange failed, likely because another thread changed m_status. // oldStatus has been updated. Retry the CAS loop. } if (oldStatus < 0) m_sema.signal(); // Release one waiting thread. }
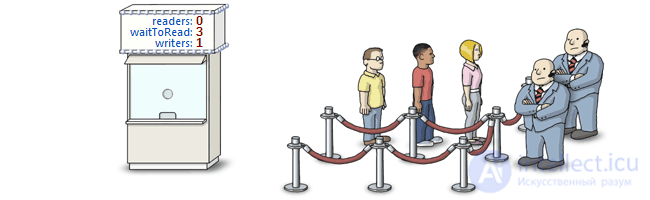
Using the same box office pattern, we can implement a primitive for read-write locks.
This primitive does not block threads in the absence of writers. In addition, it is a starvation-free for writers and readers, and, like other primitives, it can temporarily capture a spin lock before blocking the execution of the current stream. To implement this primitive, two semaphores are required: one for expecting readers, the other for writers.
With the help of the box office pattern, you can solve the problem of dining philosophers, and in a rather unusual way, which I have never met before. I do not really believe that the proposed solution will be useful for someone, so I will not go into the details of implementation. I included a description of this primitive only to demonstrate the versatility of the semaphores.
So, we assign each philosopher (stream) its own semaphore. Box office keeps track of who of the philosophers is currently taking food, who of the philosophers has asked for the start of the meal and the order of these requests. This information is sufficient for the box office to lead all philosophers through semaphores attached to them in an optimal way.
I offered two full implementations. One of them is DiningPhilosophers, which implements a box office using a mutex. The second is LockReducedDiningPhilosophers, in which each call to the box office is implemented as a lock-free algorithm.
Yes, that's right: with the help of the box office pattern and the semaphore we can implement ... another semaphore.
Why do we need to do this? Because then we get LightweightSemaphore. Such a semaphore has a very cheap signal operation when there are no waiting threads in the queue. Moreover, it does not depend on the semaphore implementation provided by the OS. When you call signal , the box office increases the value of its own internal counter, without referring to the underlying semaphore.
In addition, you can force the thread to wait for some time in a loop, and only then block it. This trick allows you to reduce the overhead associated with the system call, if the waiting time is less than some predetermined value.
In the GitHub repository, all primitives are implemented based on LightweightSemaphore. This class is implemented on the basis of Semaphore, which in turn is implemented on the basis of semaphores provided by a specific OS.
I ran a few tests to compare the speed of the presented primitives when using LightweightSemaphore and Semaphore on my PC running Windows. The corresponding results are shown in the table:
| Lightweightsemaphore | Semaphore | |
|---|---|---|
| testBenaphore | 375 ms | 5503 ms |
| testRecursiveBenaphore | 393 ms | 404 ms |
| testAutoResetEvent | 593 ms | 4665 ms |
| testRWLock | 598 ms | 7126 ms |
| testDiningPhilosophers | 309 ms | 580 ms |
As you can see, the work time is sometimes quite different. I must say, I am aware that not every environment will have the same or similar results. In the current implementation, the thread waits for 10,000 loop iterations before blocking on the semaphore. I briefly considered the possibility of using an adaptive algorithm, but the best way seemed to me unobvious. So I am open to suggestions.
Semaphores turned out to be much more useful primitives than I expected. Why then are they missing in C ++ 11 STL? For the same reason that they were absent in Boost: preference was given to mutexes and conditional variables. From the point of view of library developers, the use of traditional semaphores too often leads to errors.
If you think about it, the box office pattern is just an optimization of ordinary conditional variables for the case when all operations on conditional variables are executed at the end of the critical section. Consider the class AutoResetEvent. I implemented the AutoResetEventCondVar class with the same behavior, but using std: condition_variable. All operations on the conditional variable are performed at the end of the critical section.
void AutoResetEventCondVar::signal() { // Increment m_status atomically via critical section. std::unique_lock lock(m_mutex); int oldStatus = m_status; if (oldStatus == 1) return; // Event object is already signaled. m_status++; if (oldStatus < 0) m_condition.notify_one(); // Release one waiting thread. }
We can optimize this method in two iterations:
After these two simple optimizations, we get an AutoResetEvent.
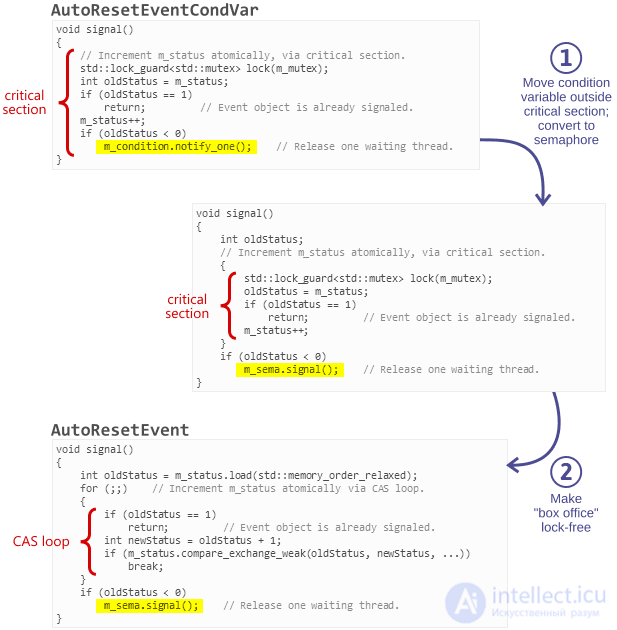
On my Windows PC, simply replacing AutoResetEventCondVar with AutoResetEvent increases the speed of the algorithm 10 times.

Comments
To leave a comment
Operating Systems and System Programming
Terms: Operating Systems and System Programming