Lecture

CAPTCHA (from English C ompletely A utomated P ublic T uring test to tell C omputers and H umans A part - a fully automated public Turing test to distinguish between computers and people) - a computer test used to determine who the system is : man or computer. The term appeared in 2000, the name captcha was settled in RuNet. The main idea of the test: to offer the user such a task that a person can easily solve, but which is incomparably more difficult for a computer to solve. CAPTCHA is a trademark of Carnegie Mellon University, which developed the test. As of 2013, approximately 320 million captchas are being introduced every day by users worldwide [1] .
In the most common captcha version, the user enters the characters shown in the figure (often with the addition of noise or translucency). According to generally accepted standards of Internet accessibility for people with poor eyesight, such a captcha should be complemented by an option based on speech recognition (audio captcha).
Other badly algorithmic tasks can also be applied: for example, find out what is in the picture, mark all the pictures with cats, or answer a question related to people's knowledge or mentality (for example, “a pear is hanging, you cannot eat”). Nevertheless, character recognition has become the standard: it is not tied to any culture (the main obstacle is poor eyesight), it works even on mobile browsers, and an experienced user quickly recognizes the image as a captcha.
HTML5 makes it harder for robots to use the Canvas element. In this case, the server does not load a picture, but a set of points (or a drawing algorithm), using which the browser draws a picture. [2]
Suppose a picture with numbers 1234 is called by a code.
Instead of passing captcha, the computer reads the URL and enters the answer 1234 .
If the web programmer is not sufficiently qualified, the robot can give an answer without passing the test. For example, for any information contained on the page, the computer itself, without human intervention, is able to correctly answer a question that only a person could supposedly answer. Either the person passes the test once, and the computer fabricates multiple requests with the same answer.
It is used primarily for "unconventional" captcha with a small number of response options (1000 or less). The robot sends random responses; some of them are true.
This approach is effective when questions are prepared by the administrator, and are not generated by automation. With the help of databases, you can go through many unconventional captcha variants: for example, check all the pictures with cats.

After the cut-off, a random pattern is formed on the letters, so there is no one hundred percent guarantee that all characters will be identified (in PWNtcha this CAPTCH rating is 99%). But the remaining one percent is completely unimportant.
The new lineup of the phpBB forum (3.xx) uses the improved captcha using the GD library by default.
There are programs (for example, PWNtcha) that recognize specific implementations of captcha. In addition, it is possible to connect modules from general-purpose text recognition programs (for example, FineReader, OmniPage) to third-party programs for captcha image recognition.
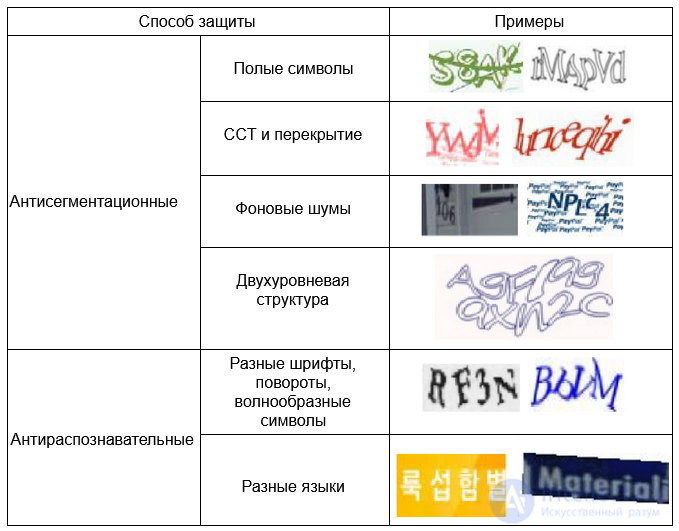
With respect to automated recognition, there are the concepts of “weak captcha” and “strong captcha”. Among the "weaknesses" - a fixed font, a fixed position of characters, no distortion, separation of characters from the background using a color key or Gaussian blur, easy separation of characters from each other, etc. However, sometimes it happens that a strong captcha is difficult to recognize and for man. Occasionally there is a captcha, easily readable by a computer and with great difficulty - by a person (for example, with a low-contrast picture).
If the generated image is unreadable, the user, as a rule, has the opportunity to get a new one. Strong captcha should produce a picture with a different answer [3] .
Many unconventional captcha variants also turned out to be weak. [4] [5]
There is a way of “recognition”, in accordance with the proverb “ stranger heat, ” using human resources from highly visited sites.
There are also specialized sites for exchanging or selling captchas.
Captcha by itself cannot stop spammers (1000 people recognize about $ 1). On the other hand, this method of protection can create great inconvenience to people.
In addition, captcha is abused, for example, file hosting, which brings to the masses the services of captcha recognition and makes it even more inefficient. [6]
reCAPTCHA is a project that uses an illegible OCR word as a work item for user responses to a captcha request, which is one of many distorted fragments of scanned books in addition to a computer-generated word. This service takes into account the techniques of use and the possibility of digitizing the text books. For reliability, the same word is proposed to several users of different sites. When different users responded equally to a CAPTCHA request, it is assumed that they entered the correct word.
CAPTCHA (Fully Automated Public Turing Test for Computer and People Differences) is a trademark of Carnegie Mellon University, a computer test used to determine whether a user is by computer. The term appeared in 2000. The main idea of the test: to offer the user such a task that a person can solve, but which is extremely difficult to teach how to solve a computer. Basically, these are tasks for character recognition.
CAPTCHA check algorithm
Briefly consider the algorithm CAPTCHA-visitor, focusing on protection from vulnerabilities that are not related to the actual recognition of the image:
The user visits the protected page, we create a session for it. It is best of all if the CAPTCHA-picture itself (or rather, the script that issues it) will create this session.
The script generates a random text, writes it into the session and gives a picture with this text to the visitor. Then, when checking, the response entered by the visitor is compared with the standard stored in this session.
It is important that the encoded text is not calculated from the data transmitted to the browser. For example, a bad idea is not to store the text in a session on the server, but to transfer it (even if in encoded form) with an argument (through the address line or cookie) to the image script, so that the script decodes the text and produces the corresponding image - guess the encoding principle not that hard, really. Then, if this text is not stored on the server, but is transmitted with requests, it is quite possible to replace it.
If a random text is generated not when issuing a picture, but when issuing a page with a form, there is a danger that the bot will make several requests to the script of the picture in order to get several variants of the same text (if the picture is issued with random distortions - that is, different times to time, albeit with the same encoded text). Recognizing text if there are several options is much easier.
Generating the code with the picture itself allows you to implement the function "get another code if this is not readable by the user" - it will be enough to update only the picture.
A common mistake is that when checking the correctness of the entered text, it is simply taken from the session and compared with the response of the visitor. The problem is that an attacker can give us the number of a nonexistent session and enter an empty verification text. And this empty text will be equal to the empty text from a non-existent session - everything, the barrier is passed.
It is important to clear the session after each check (whether successful or not). Do not rely on the fact that when updating the page the script of the picture will generate a new text - the bot may simply not request the picture, but enter the same answer, which the attacker himself read and informed the bot.
If you pay attention to these moments, your CAPTCHA will be protected from bots that do not use recognition.
Alternative Protection
Alternative ways to protect against bots can be divided into two parts: those that require some kind of action from the visitor, and those that do not. The effectiveness of these methods depends on the complexity of creating a recognition algorithm, and on the prevalence of one or another solution, because most likely they will not get involved with a burglary even a primitive, but unusually protected site of average popularity.
There are many ideas of CAPTCHA protection that are different from the classic "enter the code shown in the picture." They can also be divided into two main parts: tasks that refer to the user's “reflexes” (for recognition-recognition), and tasks that refer to his logic (questions, tasks). The first ones are more pleasant for the user, since they do not make him think.
Audio CAPTCHA
Audio CAPTCHA prompts the user to listen to a phrase and then enter it. Usually the phrase consists of spoken numbers, usually with varying tone, pauses and background noise. The advantage of an audio captcha is that a visually impaired user can answer this question. Disadvantages - the visitor must have equipment to play sound on the computer; speech recognition is not so difficult, so the degree of security for such a solution is usually low. In addition, the implementation of sound distortion is quite demanding on the qualifications of the programmer and server resources. This leads to the fact that the audio CAPTCHA is used quite rarely and only as an alternative for blind users.
Mathematical examples
It may seem to some that the question “how much will be 23 + 75” can be a good solution, since “the bot will have to guess that the numbers should not only be recognized, but also added”. With sound reasoning, it is clear that this solution can provide some kind of protection only because of its novelty and low prevalence. In fact, something, and the computer can add and subtract numbers much better than a person. But for the person himself, conducting mathematical operations in his mind (especially if the numbers in numbers are not 1–2, but more) will be tedious and difficult. The sum of one-two-digit numbers can be guessed by brute force with a relatively small number of attempts. Thus, in mathematical examples as a way to protect against bots, there is no point, there is even a deterioration in security.
Word problems
A person is asked a question or riddle to which he must give an answer. The answer must either be selected from the list or entered in the field. Since when selecting from the list, the probability to give a correct answer at random is quite large (1 / n, where n is the number of options), usually the user is forced to answer a series of questions, because the probability of guessing the correct answers to several questions will be the product of the probabilities of answering each of them. That is, for example, 1/5 * 1/6 * 1/4 = 1/120.
Advantages: verification is available for people with visual impairments, as well as for those who use clients who do not display images.
Disadvantages:
- The user must be familiar with the language in which questions are asked (and often with the realities and mentality of the native speakers).
- If ready-made questions are used, their number is obviously, of course, so an attacker can form the basis of questions with answers.
You can try to combine a text task with a recognition task, for example, “enter the first, third and fourth letters of the proposed caption,” but this is an extensive path leading to the seemingly increasing complexity of the test.
Item Recognition
Here the user is asked to find out the items shown in the picture (people, animals). He is either shown the item and asked to enter his name (or select it from the list), or, conversely, write the name, and from several proposed items are asked to choose the requested one (s). Implementation details may vary to reduce the likelihood of guessing at random, you may be asked to specify the required items in a specific order, etc.
The implementation of exactly where the pictures are the answers to the question ("specify all cats") as opposed to "what is shown in the picture" seems to be more promising, because the user is less annoying, does not need to think about synonyms when entering the answer manually and does not require tedious search among text answer choices.
Advantages: it may be easier for the user to distinguish a cat from a dog, than to distinguish, for example, the strongly distorted and noisy letters "N" and "H". Botu, on the other hand, letters, as simpler images, will be easier to distinguish.
Disadvantages:
- The user should be familiar with the objects and their names.
- The base of the pictures should be quite significant so that it is impossible to recognize through comparison with the standards. Either it will be necessary to attend to good algorithms for distorting or even generating images.

Comments