Lecture
Indexes in MySQL (Mysql indexes) is a great tool for optimizing SQL queries. To understand how they work, let's look at working with data without them.
There is no such thing as a file on a hard disk. There is a concept block. One file usually takes several blocks. Each block knows which block comes after it. The file is divided into pieces and each piece is saved in an empty block. 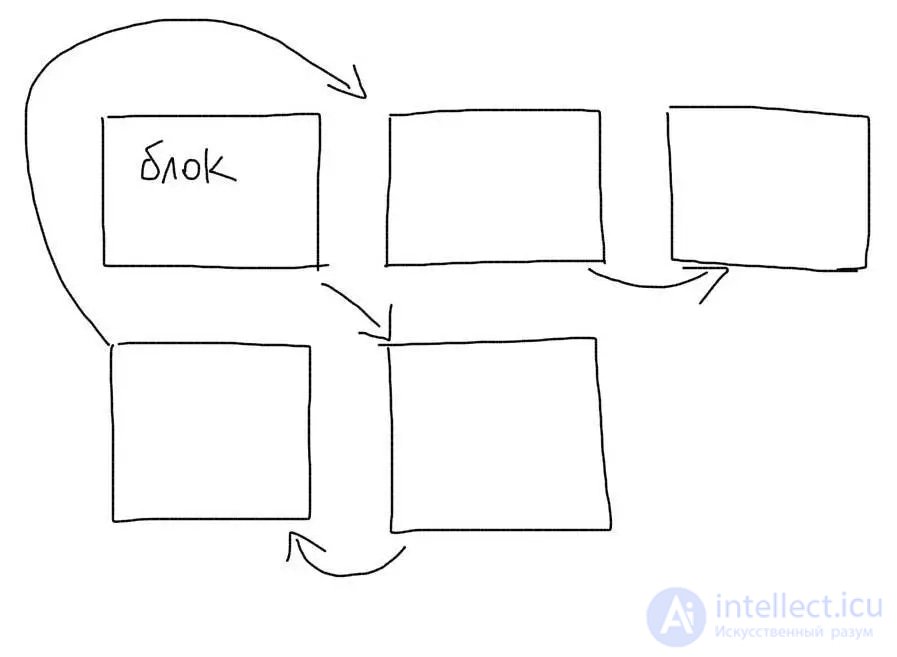
When reading a file, we in turn go through all the blocks and collect the file from the pieces. Blocks of one file can be scattered across the disk (fragmentation). Then reading the file will slow down, because need to jump different parts of the disk.
When we search for something inside the file, we need to go through all the blocks in which it is saved. If the file is very large, then the number of blocks will be significant. The need to jump from block to block, which may be in different places, will greatly slow down the search for data.
MySQL tables are ordinary files. Run a query like this:
SELECT * FROM users WHERE age = 29
MySQL opens the file where data from the users table is stored. And then - begins to sort through the entire file to find the necessary records.
In addition, MySQL will compare the data in each row of the table with the value in the query. Suppose you are working with a table with 10 entries. Then MySQL will read all 10 entries, compare the age column of each of them with the value 29 and select only the relevant data: 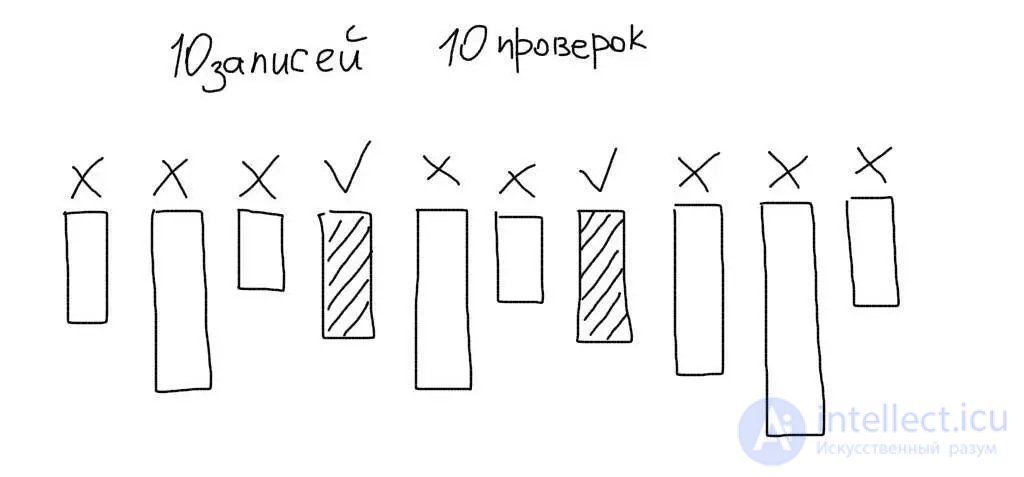
So, there are two problems with reading data:
Imagine that we sorted our 10 records in descending order. Then, using the binary search algorithm, we could select, in a maximum of 4 operations, the values we need: 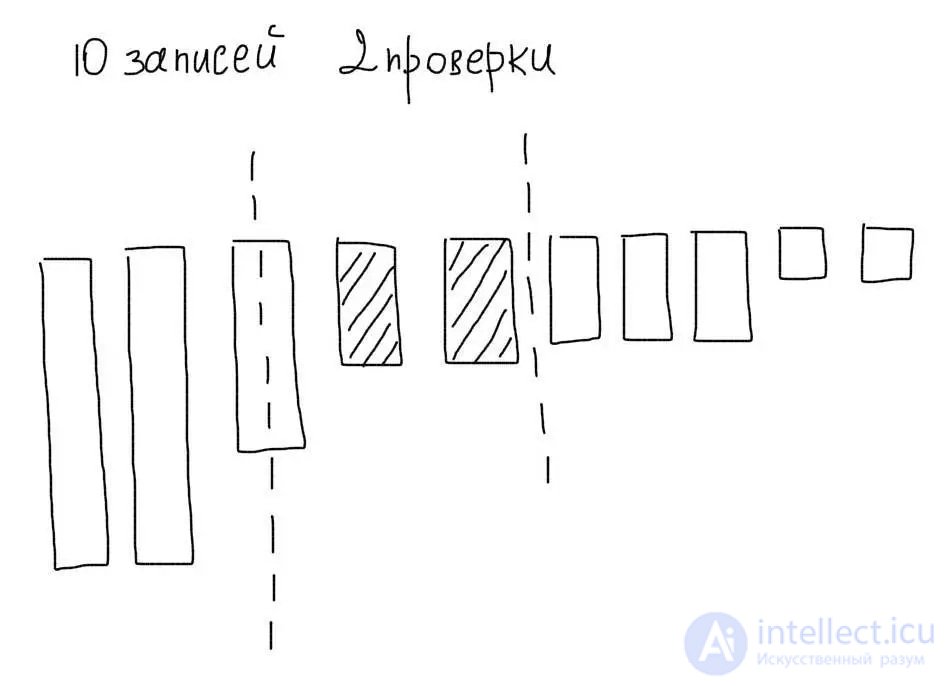
In addition to fewer comparison operations, we would save on reading unnecessary entries.
The index is the sorted set of values. In MySQL, indexes are always built for a particular column. For example, we could build an index for the age column from the example.
In the simplest case, the index must be created for those columns that are present in the WHERE clause. 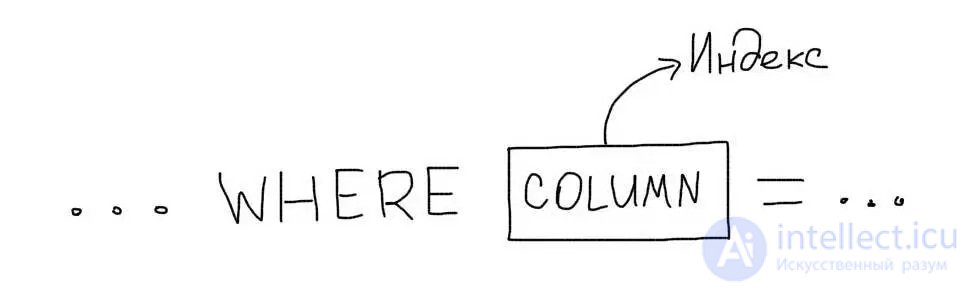
Consider the query from the example:
SELECT * FROM users WHERE age = 29
We need to create an index on the age column:
CREATE INDEX age ON users (age);
After this operation, MySQL will start using the age index to perform similar queries. The index will also be used for samples by value ranges of this column:
SELECT * FROM users WHERE age <29
For queries of this type:
SELECT * FROM users ORDER BY register_date
the same rule applies - we create an index on the column by which sorting takes place:
CREATE INDEX register_date ON users (register_date);
Imagine that our table looks like this:
id | name | age 1 | Den | 29 2 | Alyona | 15 3 | Putin | 89 4 | Petro | 12
After creating an index on the age column, MySQL will save all its values in sorted form:
age index 12 15 29 89
In addition, the link between the value in the index and the record that corresponds to this value will be saved. Usually the primary key is used for this:
age index and link to records 12: 4 15: 2 29: 1 89: 3
MySQL supports unique indexes. This is convenient for columns, the values of which must be unique throughout the table. Such indexes improve sampling efficiency for unique values. For example:
SELECT * FROM users WHERE email = 'info@intellect.icu';
On the email column you need to create a unique index:
CREATE UNIQUE INDEX email ON users (email)
Then, when searching for data, MySQL will stop after finding the first match. In the case of a normal index, another check will be necessarily carried out (the next value in the index).
MySQL can use only one index for a query . Therefore, for queries that use multiple columns, you must use composite indexes . 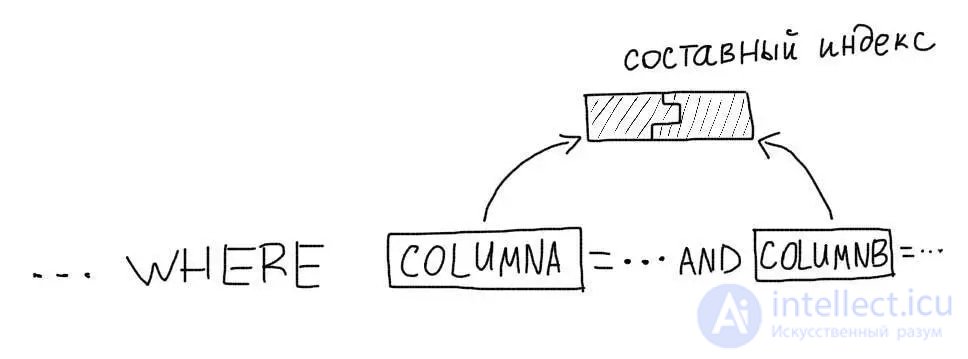
Consider this query:
SELECT * FROM users WHERE age = 29 AND gender = 'male'
We should create a composite index on both columns:
CREATE INDEX age_gender ON users (age, gender);
To properly use composite indexes, it is necessary to understand the structure of their storage. Everything works just like a regular index. But for values, the values of all incoming columns are used at once. For a table with such data:
id | name | age | gender 1 | Den | 29 | male 2 | Alyona | 15 | female 3 | Putin | 89 | tsar 4 | Petro | 12 | male
composite index values will be as follows:
age_gender 12male 15female 29male 89tsar
This means that the order of columns in the index will play a big role. Typically, columns that are used in the WHERE clause should be placed at the beginning of the index. Columns from ORDER BY - at the end.
Imagine that our query will not use a comparison, but a search by range:
SELECT * FROM users WHERE age <= 29 AND gender = 'male'
Then MySQL will not be able to use the full index, since gender values will be different for different values of the age column. In this case, the database will attempt to use part of the index (only age) to execute this query:
age_gender 12male 15female 29male 89tsar
First, all the data that matches the condition age <= 29 will be filtered. Then, the search by the value of "male" will be performed without using an index.
Composite indexes can also be used if sorting is performed:
SELECT * FROM users WHERE gender = 'male' ORDER BY age
In this case, we will need to create an index in a different order, since sorting (ORDER) occurs after filtering (WHERE):
CREATE INDEX gender_age ON users (gender, age);
This order of columns in the index will allow you to filter by the first part of the index, and then sort the result by the second.
The columns in the index can be larger if required:
SELECT * FROM users WHERE gender = 'male' AND country = 'UA' ORDER BY age, register_time
In this case, you should create the following index:
CREATE INDEX gender_country_age_register ON users (gender, country, age, register_time);
The EXPLAIN statement will show data about the use of indexes for a particular query. For example:
mysql> EXPLAIN SELECT * FROM users WHERE email = 'info@intellect.icu'; + ---- + ------------- + ------- + ------ + --------------- + ------ + --------- + ------ + ------ + ------------- + | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | + ---- + ------------- + ------- + ------ + --------------- + ------ + --------- + ------ + ------ + ------------- + | 1 | SIMPLE | users | ALL | NULL | NULL | NULL | NULL | 336 | Using where | + ---- + ------------- + ------- + ------ + --------------- + ------ + --------- + ------ + ------ + ------------- +
The key column shows the used index. The possible_keys column shows all indexes that can be used for this query. The rows column shows the number of records that the database had to read to fulfill this query (there are a total of 336 records in the table).
As you can see, in the example no index is used. After creating the index:
mysql> EXPLAIN SELECT * FROM users WHERE email = 'info@intellect.icu'; + ---- + ------------- + ------- + ------- + -------------- - + ------- + --------- + ------- + ------ + ------- + | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | + ---- + ------------- + ------- + ------- + -------------- - + ------- + --------- + ------- + ------ + ------- + | 1 | SIMPLE | users | const | email | email | 386 | const | 1 | | + ---- + ------------- + ------- + ------- + -------------- - + ------- + --------- + ------- + ------ + ------- +
Read only one entry, because index was used.
Explain will also help determine the proper use of a composite index. Check the query from the example (with an index on the columns age and gender):
mysql> EXPLAIN SELECT * FROM users WHERE age = 29 AND gender = 'male'; + ---- + ------------- + -------- + ------ + -------------- - + ------------ + --------- + ------------- + ------ + ---- --------- + | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | + ---- + ------------- + -------- + ------ + -------------- - + ------------ + --------- + ------------- + ------ + ---- --------- + | 1 | SIMPLE | users | ref | age_gender | age_gender | 24 | const, const | 1 | Using where | + ---- + ------------- + -------- + ------ + -------------- - + ------------ + --------- + ------------- + ------ + ---- --------- +
The key_len value indicates the used length of the index. In our case, 24 bytes is the entire index length (5 bytes age + 19 bytes gender).
If we change the exact comparison to a range search, we’ll see that MySQL uses only part of the index:
mysql> EXPLAIN SELECT * FROM users WHERE age <= 29 AND gender = 'male'; + ---- + ------------- + -------- + ------ + -------------- - + ------------ + --------- + ------ + ------ + ----------- - + | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | + ---- + ------------- + -------- + ------ + -------------- - + ------------ + --------- + ------ + ------ + ----------- - + | 1 | SIMPLE | users | ref | age_gender | age_gender | 5 | | 82 | Using where | + ---- + ------------- + -------- + ------ + -------------- - + ------------ + --------- + ------ + ------ + ----------- - +
This is a signal that the created index is not suitable for this query. If we create the correct index:
mysql> Create index gender_age on users (gender, age); mysql> EXPLAIN SELECT * FROM users WHERE age <29 and gender = 'male'; + ---- + ------------- + -------- + ------- + ------------- ---------- + ------------ + --------- + ------ + ------ + - ----------- + | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | + ---- + ------------- + -------- + ------- + ------------- ---------- + ------------ + --------- + ------ + ------ + - ----------- + | 1 | SIMPLE | users | range | age_gender, gender_age | gender_age | 24 | NULL | 47 | Using where | + ---- + ------------- + -------- + ------- + ------------- ---------- + ------------ + --------- + ------ + ------ + - ----------- +
In this case, MySQL uses the entire index of gender_age, since the order of the columns in it allows you to make this sample.
Let's return to the request:
SELECT * FROM users WHERE age = 29 AND gender = 'male'
For such a query, you must create a composite index. But how to choose the sequence of columns in the index? Option two:
Both will do. But they will work with different efficiency.
To understand this, consider the uniqueness of the values of each column and the number of corresponding entries in the table:
mysql> select age, count (*) from users group by age; + ------ + ---------- + | age | count (*) | + ------ + ---------- + | 15 | 160 | | 16 | 250 | | ... | | | 76 | 210 | | 85 | 230 | + ------ + ---------- + 68 rows in set (0.00 sec) mysql> select gender, count (*) from users group by gender; + -------- + ---------- + | gender | count (*) | + -------- + ---------- + | female | 8740 | | male | 4500 | + -------- + ---------- + 2 rows in set (0.00 sec)
This information tells us this:
If the age column goes first in the index, then MySQL, after the first part of the index, will reduce the number of entries to 200. It remains to be sampled. If the gender column goes first, the number of entries will be reduced to 6000 after the first part of the index. Those. an order of magnitude more than in the case of age.
This means that the age_gender index will work better than gender_age.
The selectivity of a column is determined by the number of records in the table with the same values. When there are few records with the same value, the selectivity is high. Such columns should be used first in composite indices.
Primary Key (Primary Key) - is a special type of index, which is the identifier of records in the table. It is necessarily unique and is indicated when creating tables:
CREATE TABLE `users` ( `id` int (10) unsigned NOT NULL AUTO_INCREMENT, `email` varchar (128) NOT NULL, `name` varchar (128) NOT NULL, PRIMARY KEY (`id`), ) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8
When using InnoDB tables, always define primary keys . If there is no primary key, MySQL will still create a virtual hidden key.
Regular indices are nonclustered. This means that the index itself stores only references to table entries. When working with an index, only the list of records (more precisely, the list of their primary keys) matching the query is determined. After this, another request occurs — to retrieve the data for each record from this list. 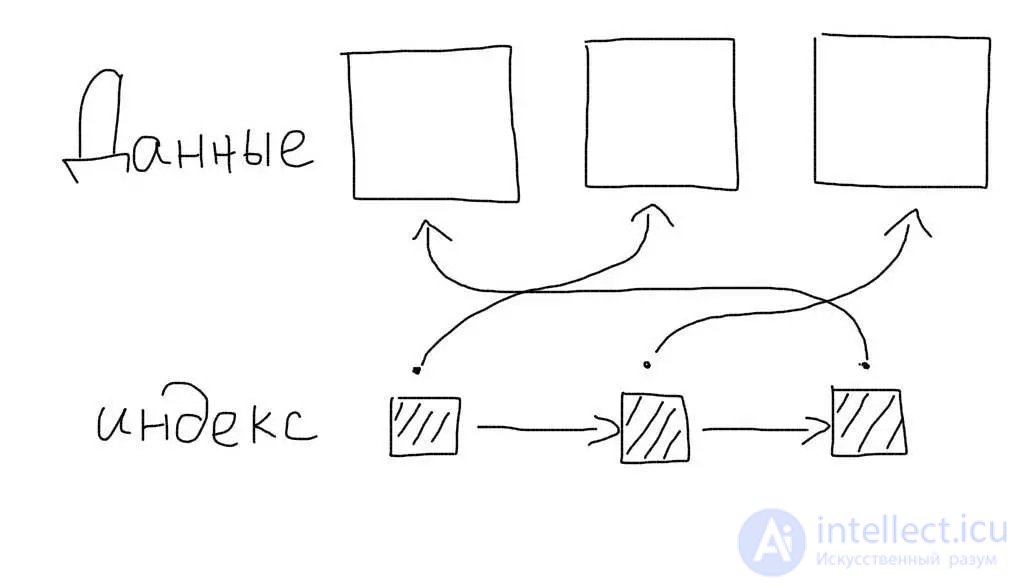
Clustered indexes store the data of records entirely, and not links to them. When working with such an index, no additional data reading operation is required. 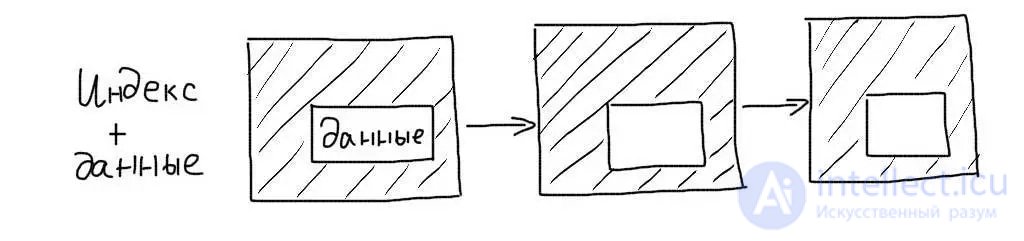
The primary keys of the InnoDB tables are clustered. Therefore, the samples for them are very effective.
It is important to remember that indexes involve additional write operations to the disk. Each time data is updated or added to a table, data is also recorded and updated in the index. 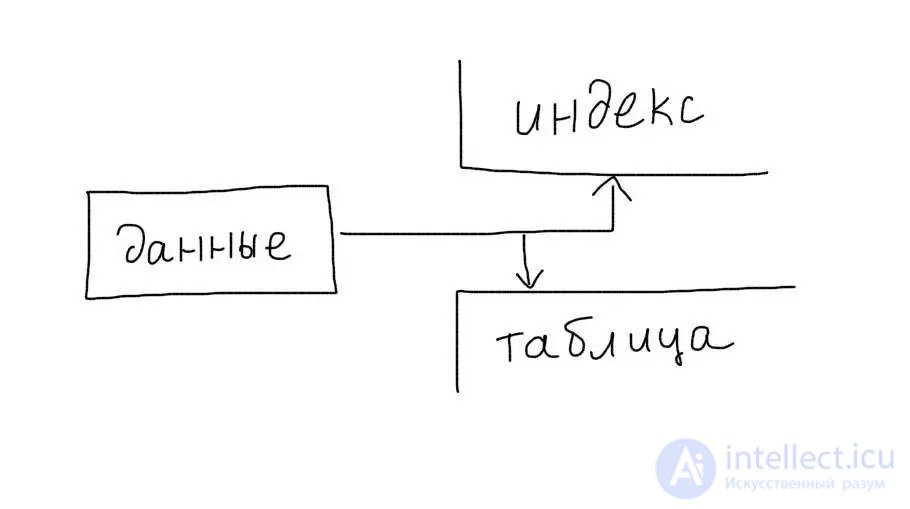
Create only the necessary indexes, so as not to waste server resources. Control index sizes for your tables:
mysql> show table status; + ------------------- + -------- + --------- + ---------- - + -------- + ---------------- + ------------- + ------- ---------- + -------------- + ----------- + ------------ ---- + --------------------- + ------------- + --------- --- + ----------------- + ---------- + ---------------- + --------- + | Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | Max_data_length | Index_length | Data_free | Auto_increment | Create_time | Update_time | Check_time | Collation | Checksum | Create_options | Comment | + ------------------- + -------- + --------- + ---------- - + -------- + ---------------- + ------------- + ------- ---------- + -------------- + ----------- + ------------ ---- + --------------------- + ------------- + --------- --- + ----------------- + ---------- + ---------------- + --------- + ... | users | InnoDB | 10 | Compact | 314 | 208 | 65536 | 0 | 16384 | 0 | 355 | 2014-07-11 01:12:17 | NULL | NULL | utf8_general_ci | NULL | | | + ------------------- + -------- + --------- + ---------- - + -------- + ---------------- + ------------- + ------- ---------- + -------------- + ----------- + ------------ ---- + --------------------- + ------------- + --------- --- + ----------------- + ---------- + ---------------- + --------- + 18 rows in set (0.06 sec)
Allocate enough time to analyze and organize indexes in MySQL (and other databases). This can take much longer than designing a database structure. It will be convenient to organize a test environment with a copy of real data and test different index structures there.
Do not create indexes for each column that is in the query, MySQL does not work that way. Use unique indexes where necessary. Always install primary keys.
Working with indexes in Mysql is a fundamental task for building systems with high performance. In this article, let's look at how Mysql uses indexes in JOIN queries.
Imagine that we have a simple system for counting statistics of article views. Data about the articles we store in one table:
+ ------- + -------------- + ------ + ----- + ------------- ------ + ----------------------------- + | Field | Type | Null | Key | Default | Extra | + ------- + -------------- + ------ + ----- + ------------- ------ + ----------------------------- + | id | int (11) | NO | PRI | 0 | | | ts | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP | | title | varchar (512) | YES | | NULL | | + ------- + -------------- + ------ + ----- + ------------- ------ + ----------------------------- +
Data with statistics is stored in another table with the following structure:
+ ------------ + --------- + ------ + ----- + ------------ + ---------------- + | Field | Type | Null | Key | Default | Extra | + ------------ + --------- + ------ + ----- + ------------ + ---------------- + | url_id | int (11) | NO | PRI | NULL | auto_increment | | article_id | int (11) | NO | | 0 | | | date | date | NO | | 0000-00-00 | | | pageviews | int (11) | YES | | NULL | | | uniques | int (11) | YES | | NULL | | + ------------ + --------- + ------ + ----- + ------------ + ---------------- +
Note that in the second table, the primary key is url_id. This is the ID of the article link. Those. one article may have several different links, and for each of them we will collect statistics. The article_id column corresponds to the id column from the first table. The statistics itself is very simple - the number of views and unique visitors per day.
Let's make a choice of statistics for one article:
SELECT s.article_id, s.date, SUM (s.pageviews), SUM (s.uniques) FROM articles a JOIN articles_stats s ON (s.article_id = a.id) WHERE a.id = 4 GROUP BY s.date;
Statistics for articles with id = 4
At the exit we get views and unique visitors for this article for each day:
+ ------------ + ------------ + ------------------ + ---- ------------ + | article_id | date | SUM (s.pageviews) | SUM (s.uniques) | + ------------ + ------------ + ------------------ + ---- ------------ + | 4 | 2016-01-03 | 28920 | 9640 | ... ... | 4 | 2016-01-07 | 1765 | 441 | + ------------ + ------------ + ------------------ + ---- ------------ + 499 rows in set (0.37 sec)
The request worked in 0.37 seconds, which is rather slow. Look at EXPLAIN:
+ ---- + ------------- + ------- + ------- + -------------- - + --------- + --------- + ------- + -------- + ----------- ----------------------------------- + | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | + ---- + ------------- + ------- + ------- + -------------- - + --------- + --------- + ------- + -------- + ----------- ----------------------------------- + | 1 | SIMPLE | a | const | PRIMARY | PRIMARY | 4 | const | 1 | Using index; Using temporary; Using filesort | | 1 | SIMPLE | s | ALL | NULL | NULL | NULL | NULL | 676786 | Using where | + ---- + ------------- + ------- + ------- + -------------- - + --------- + --------- + ------- + -------- + ----------- ----------------------------------- +
EXPLAIN shows two records — one for each table in our query:
In JOIN queries, Mysql will use an index that will filter the most records from one of the tables.
Therefore, we need to make sure that Mysql will quickly execute a query of this type:
SELECT article_id, date, SUM (pageviews), SUM (uniques) FROM articles_stats WHERE article_id = 4 GROUP BY date
According to the index selection logic, we construct an index using the article_id column:
CREATE INDEX article_id on articles_stats (article_id);
Check the use of indexes in our first query:
EXPLAIN SELECT s.article_id, s.date, SUM (s.pageviews), SUM (s.uniques) from the article a join article_stats s on (s.article_id = a.id) where a.id = 4 group by s.date ;
And see that Mysql now uses indexes for two tables:
+ ---- + ------------- + ------- + ------- + -------------- - + ------------ + --------- + ------- + ------ + ---------- ------------------------------------ + | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | + ---- + ------------- + ------- + ------- + -------------- - + ------------ + --------- + ------- + ------ + ---------- ------------------------------------ + | 1 | SIMPLE | a | const | PRIMARY | PRIMARY | 4 | const | 1 | Using index; Using temporary; Using filesort | | 1 | SIMPLE | s | ref | article_id | article_id | 4 | const | 677 | Using where | + ---- + ------------- + ------- + ------- + -------------- - + ------------ + --------- + ------- + ------ + ---------- ------------------------------------ +
This will significantly speed up the request (after all, in the second case, Mysql processes 1000 times less data).
The previous example is more laboratory in nature. A query closer to practice is a selection of statistics on several articles at once:
SELECT s.article_id, s.date, SUM (s.pageviews), SUM (s.uniques), a.title, a.ts FROM articles a JOIN articles_stats s ON (s.article_id = a.id) WHERE a.id IN (4,5,6,7) GROUP BY s.date;
However, in this case, Mysql will behave the same way. He will evaluate which indexes can be used from each table. EXPLAIN will show:
+ ---- + ------------- + ------- + -------- + ------------- - + ------------ + --------- + ------------------- + ---- - + ---------------------------------------------- + | id |select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | + ---- + ------------- + ------- + -------- + ------------- - + ------------ + --------- + ------------------- + ---- - + ---------------------------------------------- + | 1 | SIMPLE | s |range | article_id | article_id | 4 | NULL |2030 | Using where; Using temporary; Using filesort | | 1 | SIMPLE | a |eq_ref | PRIMARY | PRIMARY | 4 | test.s.article_id | 1 | Using index | + ---- + ------------- + ------- + -------- + ------------- - + ------------ + --------- + ------------------- + ---- - + ---------------------------------------------- +
Таблицы будут обработаны в другом порядке. Сначала будет сделана выборка всех подходящих значений из таблицы статистики. А затем из таблицы с названиями.
Mysql решил, что сначала выбрав статистику по всем нужным статьям, он затем быстрее сделает выборку из таблицы articles. Порядок в этом случае не имеет особого значения, ведь в таблице articles выборка происходит по первичному ключу.
На практике приходится иметь дело с дополнительными фильтрами в запросах. Например, выборка статистики только за определенную дату:
SELECT s.article_id, s.date, SUM(s.pageviews), SUM(s.uniques), a.title, a.ts FROM articles a JOIN articles_stats s ON (s.article_id = a.id) WHERE s.date = '2017-05-14' GROUP BY article_id
В этом случае, Mysql снова не сможет подобрать индекс для таблицы статистики:
+ ---- + ------------- + ------- + -------- + ------------- - + --------- + --------- + ------------------- + ------- - + ------------- + | id |select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | + ---- + ------------- + ------- + -------- + ------------- - + --------- + --------- + ------------------- + ------- - + ------------- + | 1 | SIMPLE | s |ALL | article_id | NULL | NULL | NULL |676786 | Using where | | 1 | SIMPLE | a |eq_ref | PRIMARY | PRIMARY | 4 | test.s.article_id | 1 | | + ---- + ------------- + ------- + -------- + ------------- - + --------- + --------- + ------------------- + ------- - + ------------- +
The logic for choosing an index here is the same as in the previous example. It is necessary to choose an index that allows you to quickly filter the statistics table by date:
CREATE INDEX date ON articles_stats (date);
Now the query will use indexes on both tables:
+ ---- + ------------- + ------- + -------- + ------------- ---- + --------- + --------- + ------------------- + ----- - + ---------------------------------------------- + | id |select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | + ---- + ------------- + ------- + -------- + ------------- ---- + --------- + --------- + ------------------- + ----- - + ---------------------------------------------- + | 1 | SIMPLE | s |ref | article_id, date | date | 4 |const | 2996 | Using where; Using temporary; Using filesort | | 1 | SIMPLE | a |eq_ref | PRIMARY | PRIMARY | 4 | test.s.article_id | 1 | | + ---- + ------------- + ------- + -------- + ------------- ---- + --------- + --------- + ------------------- + ----- - + ---------------------------------------------- +
В еще более сложных случаях выборки включают дополнительные фильтры либо сортировки. Допустим, мы хотим выбрать все статьи, созданные не позднее месяца назад. А статистику показать для них только за последний день. Только для тех публикаций, у которых набрано более 15 тыс. уникальных посещений. И результат отсортировать по просмотрам:
SELECT s.article_id, s.date, SUM(s.pageviews), SUM(s.uniques), a.title, a.ts FROM articles a JOIN articles_stats s ON (s.article_id = a.id) WHERE a.ts > '2017-04-15' AND s.date = '2017-05-14' AND s.uniques > 15000 GROUP BY article_id ORDER BY s.pageviews
# Запрос отработает за 0.15 секунд, что довольно медленно
Mysql будет искать индексы, которые позволят отфильтровать максимум значений из каждой исходной таблицы. В нашем случае это будут:
+----+-------------+-------+--------+---------------+---------+---------+-------------------+-------+----------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+--------+---------------+---------+---------+-------------------+-------+----------------------------------------------+ | 1 | SIMPLE | s | range | date | date | 4 | NULL | 26384 | Using where; Using temporary; Using filesort | | 1 | SIMPLE | a | eq_ref | PRIMARY | PRIMARY | 4 | test.s.article_id | 1 | Using where | +----+-------------+-------+--------+---------------+---------+---------+-------------------+-------+----------------------------------------------+
Индекс date позволит отфильтровать таблицу статистики до 26 тыс. записей. Каждую из которых придется проверить на соответствие другим условиям (количество уникальных посетителей более 15 тыс.).
Сортировку по просмотрам Mysql будет в любом случае делать самостоятельно. Индексы тут не помогут, т.к. сортируем динамические значения (результат операции GROUP BY).
Поэтому наша задача — выбрать индекс, который позволит максимально сократить выборку по таблице articles_stats используя фильтр s.date = '2017-05-14' AND s.uniques > 15000.
Создадим индекс на обе колонки из первого пункта:
CREATE INDEX date_uniques ON articles_stats(date,uniques);
Тогда Mysql сможет использовать этот индекс для фильтрации таблицы статистики:
+----+-------------+-------+--------+---------------+--------------+---------+-------------------+------+----------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+--------+---------------+--------------+---------+-------------------+------+----------------------------------------------+ | 1 | SIMPLE | s | range | date_uniques | date_uniques | 9 | NULL | 1681 | Using where; Using temporary; Using filesort | | 1 | SIMPLE | a | eq_ref | PRIMARY,ts_id | PRIMARY | 4 | test.s.article_id | 1 | Using where | +----+-------------+-------+--------+---------------+--------------+---------+-------------------+------+----------------------------------------------+
# При таком индексе Mysql обработает в 10 раз меньше записей для выборки
В ситуациях, когда невозможно выбрать подходящий индекс, следует подумать о денормализации. В этом случае стоит пользоваться правилом:
Лучше много легких записей, чем много тяжелых чтений
Следует создать таблицу, оптимизированную под запрос и синхронно её обновлять. Однако убедитесь, что ваш сервер хорошо настроен. В качестве срочных мер рассмотрите возможность кешировать результаты тяжелых запросов.
Указатели индекса дают информацию оптимизатора о том, как выбирать индексы во время обработки запросов. Указания индекса применяются только к SELECTоператорам. (Они принимаются парсером для UPDATE операторов, но игнорируются и не действуют).
Индексные подсказки указываются после имени таблицы. (Общий синтаксис для указания таблиц в SELECTинструкции см. В разделе 13.2.9.2, «JOIN Syntax» .) Синтаксис для обращения к отдельной таблице, включая подсказки индекса, выглядит следующим образом:
tbl_name [[AS] alias ] [ index_hint_list ]
index_hint_list :
index_hint [ index_hint ] ...
index_hint :
USE {INDEX|KEY}
[FOR {JOIN|ORDER BY|GROUP BY}] ([ index_list ])
| IGNORE {INDEX|KEY}
[FOR {JOIN|ORDER BY|GROUP BY}] ( index_list )
| FORCE {INDEX|KEY}
[FOR {JOIN|ORDER BY|GROUP BY}] ( index_list )
index_list :
index_name [, index_name ] ...
Совет подсказывает MySQL использовать только один из названных индексов для поиска строк в таблице. Альтернативный синтаксис говорит MySQL не использовать какой-либо определенный индекс или индексы. Эти подсказки полезны, если показано, что MySQL использует неверный индекс из списка возможных индексов. USE INDEX ( index_list )IGNORE INDEX ( index_list )EXPLAIN
FORCE INDEXНамек действует как с добавлением , что сканирование таблицы считается очень дорогим. Другими словами, сканирование таблицы используется только в том случае, если нет способа использовать один из названных индексов для поиска строк в таблице. USE INDEX ( index_list )
Каждому подсказку нужны имена индексов, а не имена столбцов. Чтобы обратиться к первичному ключу, используйте имя PRIMARY. Чтобы увидеть имена индексов для таблицы, используйте SHOW INDEXоператор или INFORMATION_SCHEMA.STATISTICS таблицу.
index_name Значение не должно быть полное имя индекса. Это может быть однозначный префикс имени индекса. Если префикс неоднозначен, возникает ошибка.
Examples:
SELECT * FROM table1 USE INDEX (col1_index,col2_index) WHERE col1=1 AND col2=2 AND col3=3; SELECT * FROM table1 IGNORE INDEX (col3_index) WHERE col1=1 AND col2=2 AND col3=3;
Синтаксис для подсказок индекса имеет следующие характеристики:
Это синтаксически правильным опустить index_list для USE INDEX, что означает « использовать не индексов. » Опуская index_list для FORCE INDEXили IGNORE INDEXошибка синтаксиса.
Вы можете указать область подсказки индекса, добавив FORпредложение к подсказке. Это обеспечивает более тонкий контроль над выбором оптимизатора плана выполнения для различных этапов обработки запросов. Чтобы повлиять только на индексы, используемые, когда MySQL решает, как найти строки в таблице и как обрабатывать соединения, используйте FOR JOIN. Чтобы влиять на использование индекса для сортировки или группировки строк, используйте FOR ORDER BYили FOR GROUP BY.
Вы можете указать несколько подсказок для индекса:
SELECT * FROM t1 USE INDEX (i1) IGNORE INDEX FOR ORDER BY (i2) ORDER BY a;
Нельзя назвать один и тот же индекс несколькими подсказками (даже в пределах одного и того же намека):
SELECT * FROM t1 USE INDEX (i1) USE INDEX (i1,i1);
Тем не менее, это ошибка для смешивания USE INDEX и FORCE INDEXдля одной и той же таблицы:
SELECT * FROM t1 USE INDEX FOR JOIN (i1) FORCE INDEX FOR JOIN (i2);
Если подсказка индекса не содержит FORпредложения, объем подсказки должен применяться ко всем частям оператора. Например, этот намек:
IGNORE INDEX (i1)
эквивалентно этой комбинации подсказок:
IGNORE INDEX FOR JOIN (i1) IGNORE INDEX FOR ORDER BY (i1) IGNORE INDEX FOR GROUP BY (i1)
В MySQL 5.0 область подсказок без FORпредложения заключалась в применении только для поиска строк. Чтобы заставить сервер использовать это более старое поведение, когда нет FORпредложения, включите oldсистемную переменную при запуске сервера. Позаботьтесь о включении этой переменной в настройку репликации. При двоичном протоколировании, основанном на операторах, наличие разных режимов для ведущего устройства и ведомых устройств может привести к ошибкам репликации.
Когда индекс подсказка обрабатываются, они собраны в одном списке по типу ( USE, FORCE, IGNORE) и объемом ( FOR JOIN, FOR ORDER BY, FOR GROUP BY). For example:
SELECT * FROM t1 USE INDEX () IGNORE INDEX (i2) USE INDEX (i1) USE INDEX (i2);
эквивалентно:
SELECT * FROM t1 USE INDEX (i1,i2) IGNORE INDEX (i2);
Затем подсказки индекса применяются для каждой области в следующем порядке:
{USE|FORCE} INDEXприменяется, если присутствует. (Если нет, используется набор индексов с оптимизатором).
IGNORE INDEXприменяется в результате предыдущего шага. Например, следующие два запроса эквивалентны:
SELECT * FROM t1 USE INDEX (i1) IGNORE INDEX (i2) USE INDEX (i2); SELECT * FROM t1 USE INDEX (i1);
Для FULLTEXTпоисков подсказки индексов работают следующим образом:
Для поиска в режиме естественного языка подсказки индекса молча игнорируются. Например, IGNORE INDEX(i1)игнорируется без предупреждения и индекс все еще используется.
Для поиска в булевом режиме индексированные подсказки с FOR ORDER BYили FOR GROUP BYмолча игнорируются. Индексные подсказки с модификатором FOR JOINили без него FORвыполняются. В отличие от того, как подсказки применяются для не- FULLTEXTпоиска, подсказка используется для всех этапов выполнения запроса (поиск строк и поиск, группировка и упорядочение). Это справедливо, даже если подсказка указана для неиндекс FULLTEXT.
Например, следующие два запроса эквивалентны:
SELECT * FROM t USE INDEX (index1) IGNORE INDEX (index1) FOR ORDER BY IGNORE INDEX (index1) FOR GROUP BY WHERE ... IN BOOLEAN MODE ... ; SELECT * FROM t USE INDEX (index1) WHERE ... IN BOOLEAN MODE ... ;
Query analyzer is not ideal. An optimizer that chooses the wrong plan can cause serious performance problems.
However, this does NOT mean that you should always use the force index hint.

Comments
To leave a comment
Databases - MySql (Maria DB)
Terms: Databases - MySql (Maria DB)