Lecture
let's consider the implementation of the algorithm described by Zelenkov Yu. G. and Segalovich I.V. in the publication Comparative Analysis of Fuzzy Duplicate Detection Methods for Web Documents.
Let us describe the principle of algorithms of shingles, superstagles and megashings for comparing web documents in an accessible language.
In a publication about almost duplicate search algorithms, a version of the shingle algorithm is proposed, using a random sample of 84x random shingles.
Why exactly 84? Using 84x randomly selected checksum values will make it easy to modify the algorithm to a superswitch algorithm and megashingle, which are much less resource-intensive. I will describe them soon.
I recommend armed with a pen and a piece of paper and figuratively present each of the stages described below as a picture.
Let us examine the stages through which the text undergoes comparison:
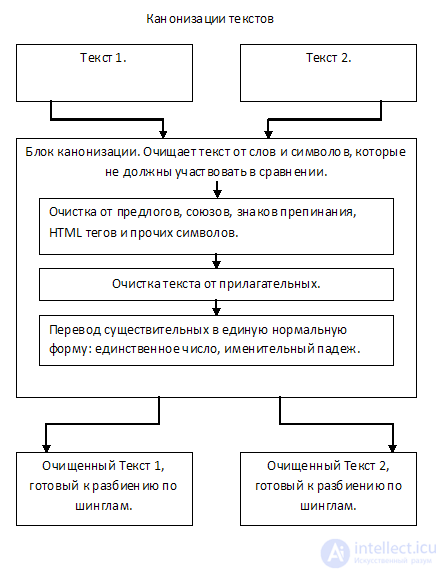
1. Canonization of the text
What is the canonization of the text I described in my last article on the Shingle algorithm. But in short I repeat. The canonization of the text leads the original text to a single normal form.
The text is cleared of prepositions, conjunctions, punctuation marks, HTML tags, and other unnecessary "garbage", which should not be involved in the comparison. In most cases, it is also proposed to remove adjectives from the text, since they do not carry a semantic load.
Also at the stage of canonization of the text, nouns can be reduced to the nominative case, the singular, or the roots can only be left from them.
With canonization of the text, you can experiment and experiment, the scope for action here is wide.
At the exit, we have the text, cleared of "garbage", and ready for comparison.
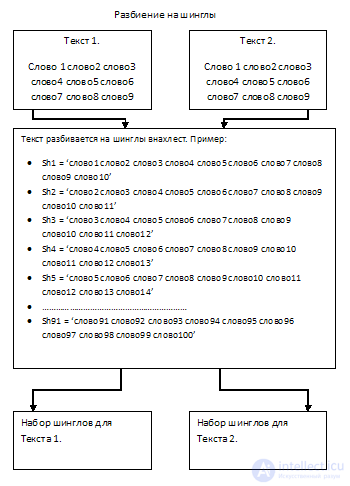
2. Sharing into shingles
Shingly (English) - scales, selected from the article subsequence of words.
It is necessary to distinguish between subsequences of subsequences of words, following each other in 10 pieces (the length of a shingle). Sampling is overlapping, not butt.
Thus, breaking the text into subsequences, we get a set of shingles in an amount equal to the number of words minus the length of the shingle plus one (number of words - length of the length + 1).
I remind you that actions on each of the points are performed for each of the texts being compared.
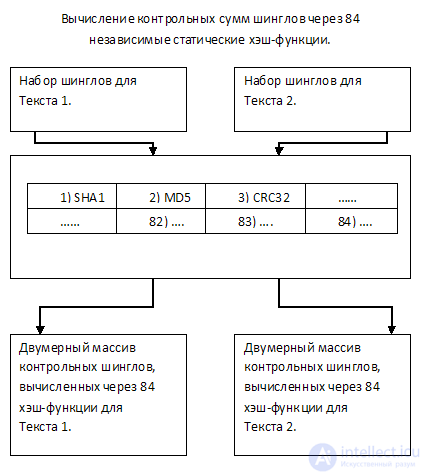
3. Calculation of shingles hashes using 84x static functions
This is the most interesting stage. The principle of the algorithm of shingles is to compare a random sample of checksums of shingles (subsequences) of two texts among themselves.
The problem of the algorithm is the number of comparisons, because it directly affects the performance. The increase in the number of shingles for comparison is characterized by an exponential growth of operations, which critically affect the performance.
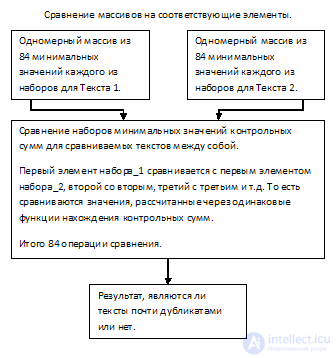
It is proposed to present the text in the form of a set of checksums calculated using 84x unique static hash functions.
Let me explain: for each Shingle, 84 checksum values are calculated through different functions (for example, SHA1, MD5, CRC32, etc., a total of 84 functions). So each of the texts will be represented, one can say, in the form of a two-dimensional array of 84 lines, where each line characterizes the corresponding of 84 functions of checksums.
From the resulting sets, 84 values for each of the texts will be randomly selected and compared to each other according to the checksum function through which each of them was calculated. Thus, for comparison, it will be necessary to perform a total of 84 operations.
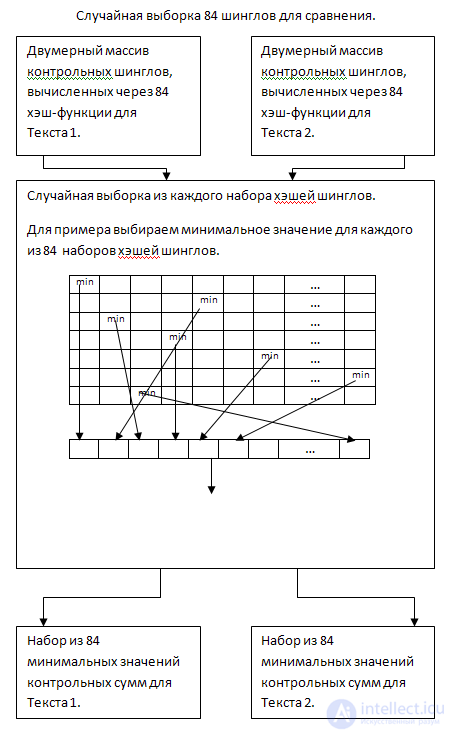
4. Random sample of 84 checksum values
As I described above, comparing the elements of each of the 84x arrays with each other is resource intensive. To increase performance, we will execute a random sample of checksums for each of the 84x rows of a two-dimensional array, for both texts. For example, we will select the lowest value from each row.
So, at the output we have a set of minimum checksum values of the shingles for each of the hash functions.
5. Comparison, determination of the result
And the last stage is a comparison. We compare the 84 elements of the first array with the corresponding 84yu elements of the second array, we consider the ratio of the same values, from this we get the result.
The Shingle algorithm is used to search for “similar documents” and determine the degree of similarity of two texts. For example, you have hundreds of texts (say, articles or news) and you need to find rewrites. Those. texts that are not absolutely identical with each other, but to some extent similar. The shingle algorithm can be used to find “reprints” of texts or, for example, to group news by subject (hi Yandex.News service). Despite the fact that in its basic version, the algorithm is quite simple, there are many ways to make it complex and many different variations - supershingly, megashingly ... We implement the basic version of this algorithm without special PHP problems.
So, we have two texts. We need to determine if they are similar. What are we doing?
Let's see how the algorithm works on a small example. Suppose we have two some text.
To have a slim figure, you must play sports and eat right. Come to the gym “Spark” - be healthy and beautiful!
Girls! Come to the sports club "Butterfly". We have a lot of simulators and experienced instructors who will tell you how to play sports and eat right to have a slender figure and cheerful spirit.
On the face of rewriting. The texts are not the same, but similar. Take the first text and clear it, you get the following:
to have a slim figure you have to play sports eat right come to the gym light be healthy healthy
girls come to the sports club butterfly us many simulators experienced instructors who will tell you to play sports eat right to have a slender figure cheerful spirit
We make shingly (sequences of words). Let one shingle we will consist of 3 words. Then for the first text we get the following sequences:
|
1 2 3 4 5 6 7 8 9 |
Array ( [0] => чтобы иметь стройную [1] => иметь стройную фигуру [2] => стройную фигуру вы [3] => фигуру вы должны [4] => вы должны заниматься // и так далее... ) |
Please note that my shingles go “overlapping” and not “butt”. The size of shingles (i.e. how many words in a sequence), “butt” or “overlapped”, if the latter, then how many words of the end will be entered at the beginning of the next shingle, these are all questions of customizing the algorithm for your tasks. And now we find the checksums for these shingles. We use the crc32 () functions and get the following:
|
1 2 3 4 5 6 7 8 9 |
Array ( [0] => 281830324 [1] => 1184612177 [2] => -30086073 [3] => -811305747 [4] => -308857406 // и так далее... ) |
The same is done with the second text, after which we look for the same checksums. In our case, the same sequences that are present in both texts will be:
|
1 2 3 4 5 6 |
Array ( [13] => заниматься спортом правильно // 964071158 [14] => спортом правильно питаться // 2144093920 [18] => иметь стройную фигуру // 1184612177 ) |
Thus, if we divide the number of identical shingles by their total number and multiply by 100, we get the percentage of identical shingles. In the example, this is 13.04%. Please note that this is a percentage of identical shingles, not a percentage of similarity of texts. There is a difference. This border of “similarity” you define yourself. I apply this algorithm, slightly modified, in the news monitoring system to group news by subject. In my case, it turns out that if the percentage is more than 10%, then the news about one event.
So, first we need the function of canonization, i.e. cleaning the text from any garbage. Here she is:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
function canonize($text) { $words = explode(' ', $text) ;
$result = array() ; foreach($words as $k=>$w) { $w = strtolower($w) ; $w = preg_replace(self::$filter, '', $w) ;
if(!empty($w)) { $result[] = trim($w); ; } }
return $result ; } |
And so, after running the text on this function, we have the text cleared of all garbage. Now you need to break it into shingles and find checksums for them. This is all in one function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
function shinglesGen(array $words) { $wordsLen = count($words) ; $shinglesCount = $wordsLen - (3 - 1) ;
$shingles = array() ; for($i=0; $i < $shinglesCount; $i++) { $sh = array() ; for($k=$i; $k < $i + 3; $k++) { $sh[] = $words[$k] ; } $shingles[] = crc32( implode(' ', $sh) ) ; } return $shingles ; } |
Well, now we have an array of checksums. We need to find the intersection of two such arrays (from two texts) in order to find common sequences.
|
1 |
$intersection = array_intersect($shingles1, $shingles2) ; |
In the $ intersection variable, we now have an array with sequences of words common to two texts. We can find the percentage of total sequences of their total number and give the percentage of “total”. If this percentage is large enough (you define the border yourself), then boldly call such texts similar. That's all. Finally, I give the full version of the entire code issued in the form of a class.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 |
class Shingles {
const SHINGLES_LEN = 3 ;
public static function analyze ($source1, $source2) { $words1 = self::canonize($source1) ; $shingles1 = self::shinglesGen($words1) ;
$words2 = self::canonize($source2) ; $shingles2 = self::shinglesGen($words2) ;
$intersection = array_intersect($shingles1, $shingles2) ;
$intersectionPercent = (count($intersection) / count($words1)) * 100 ;
return $intersectionPercent ; }
private static function canonize($text) { $words = explode(' ', $text) ;
$result = array() ; foreach($words as $k=>$w) { $w = strtolower($w) ; $w = preg_replace(self::$filter, '', $w) ;
if(!empty($w)) { $result[] = trim($w); ; } }
return $result ; }
private static function shinglesGen($words) { $wordsLen = count($words) ; $shinglesCount = $wordsLen - (self::SHINGLES_LEN - 1) ;
$shingles = array() ;
for($i=0; $i < $shinglesCount; $i++) { $sh = array() ; for($k=$i; $k < $i + self::SHINGLES_LEN; $k++) { $sh[] = $words[$k] ; }
$shingles[] = crc32( implode(' ', $sh) ) ; }
return $shingles ; }
private static $filter = array( '/,/', '/\./', '/\!/', '/\?/', '/\(/', '/\)/', '/-/', '/—/', '/:/', '/;/', '/"/',
'/^это$/', '/^как$/', '/^так$/', '/^в$/', '/^на$/', '/^над$/', '/^к$/', '/^ко$/', '/^до$/', '/^за$/', '/^то$/', '/^с$/', '/^со$/', '/^для$/', '/^о$/', '/^ну$/', '/^же$/', '/^ж$/', '/^что$/', '/^он$/', '/^она$/', '/^б$/', '/^бы$/', '/^ли$/', '/^и$/', '/^у$/' ) ;
} |
|
1 2 3 4 5 6 |
require_once "shingles.php" ;
$text = "Текст для сравнения номер один" ; $text2 = "Текст для сравнения номер два" ;
echo Shingles::analyze($text2, $text) ; // выведет 25 (25% общих последовательностей) |
That's all. Even in such a simple version, everything works fine.
If this is not enough, it is possible not only to remove prepositions and punctuation marks at the stage of canonization, but also to translate words into normal form — that is, in the nominative case, the singular. Verbs - in the infinitive.
The algorithm is quite resource-intensive. If you need to compare not two texts, but highlight a group of similar texts from 100 or 1000. Use your attention not to find Shingles again, if you have already done them for this text. Save to DB, for example.

Comments
To leave a comment
Natural language processing
Terms: Natural language processing