Lecture
Inverted index (eng. Inverted index ) is a data structure in which for each word of the collection of documents in the corresponding list all documents in the collection in which it is found are listed. Inverted index is used for text search.
There are two variants of the inverted index:
We describe how to solve the problem of finding documents in which all the words from the search query are found. When processing a one-word search query, the answer is already in the inverted index - just take the list corresponding to the word from the query. When processing a verbose query, lists are taken that correspond to each of the words of the query and overlap.
Usually in search engines after building up with the help of an inverted index a list of documents containing words from a query, the documents from the list are ranked. An inverted index is the most popular data structure used in information retrieval [2].
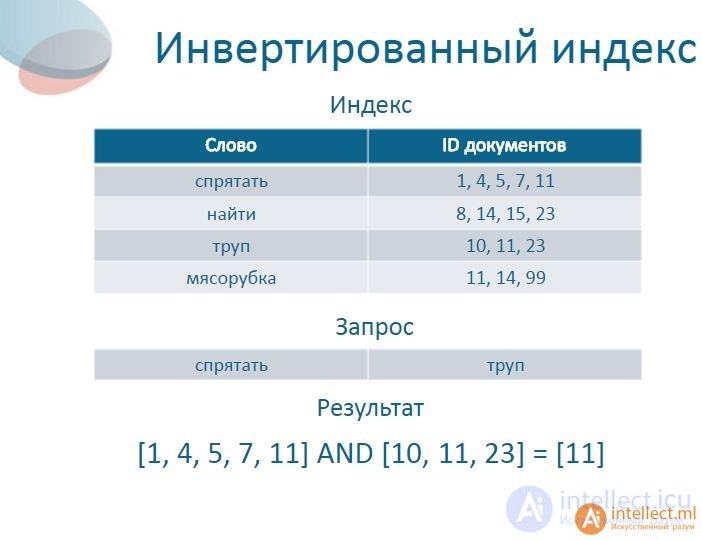
Suppose we have a body of three texts  "it is what it is",
"it is what it is",  "what is it" and
"what is it" and  "it is a banana", then the inverted index will look like this:
"it is a banana", then the inverted index will look like this:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
Here the numbers denote the numbers of texts in which the corresponding word was encountered. Then working out the search "what is it" query will give the following result  .
.
You have thousands-hundreds of thousands of pages on a website that can be processed and saved in three tables as an inverted index.
document table
- Docid (PC, FK)
- URL
- charactercount
- Word count
Charactercount and wordcount help me identify a long document from a short one that I can use later.
table word
- Wordid (PK, FK)
- word
- doc_freq
- inverse_doc_freq
To calculate inverse_doc_freq, I use a fictional large number (100000000) to prevent a general recalculation of documents.
LOC
- wordid
- Docid
- word_freq
- weight
(Wordid & docid uniquely combined)
Weight is an estimate calculated on a simple basis, for example, a word in the title + a word in url + a word frquency, etc.
To search you need to do the following
The request must be aggregated at the document table level.
.
SELECT d.docid, d.url, sum (weight) AS weight
FROM document d
JOIN loc l on d.docid = l.docid
JOIN word w on w.wordid = l.wordid
WHERE w.word in ('word1', 'word2', 'word3')
GROUP by d.docid
ORDER by weight DESC;
In the list of occurrences of a word in documents, in addition to id documents, factors are also usually indicated (TF-IDF, binary factor: “a word fell into the heading or not”, other factors) that are used in ranking. The index can be built not on all word forms, but on lemmas (on canonical forms of words). Stop words can be eliminated and do not build an index for them, assuming that each of them is found in almost all documents of the corpus. To speed up the calculation of intersections, skip-pointer heuristics are used. When processing queries containing many words, the quorum function is used, which skips to the next stage of ranking a part of the documents in which not all the words from the query were encountered.

Comments