Lecture
1 Data Analysis Data Indexing and Request Processing
2 Plan of the lecture. Tasks and problems of indexation. Stages of text normalization. Preparation for ranking at the stages of normalization.

3 In the previous series ... Indexer CachingNormalizer Snippets Search Unavailable pages
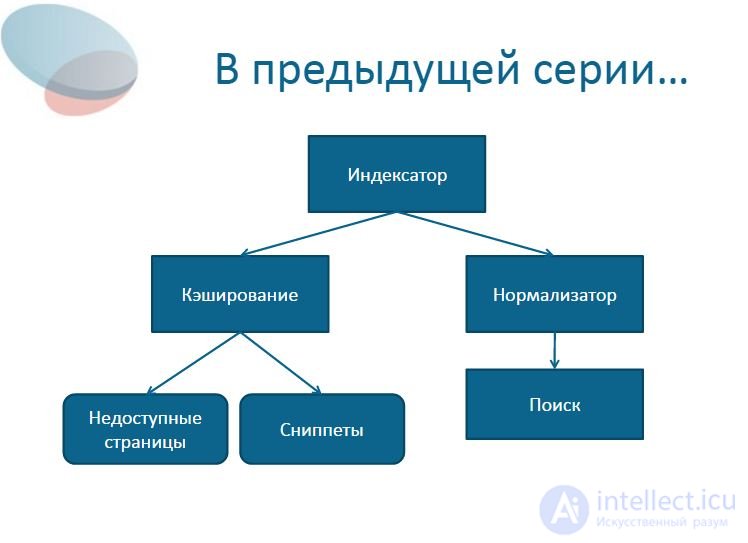
4 In the previous series ... The normalizer is a part of the indexer that converts a document into a convenient form for later search. The task of the normalizer is to convert unstructured information into structured

5 Convenient view It is necessary to find out in which documents the requested word is found Solution options: View the texts of all documents Make a list of documents in which the word is found

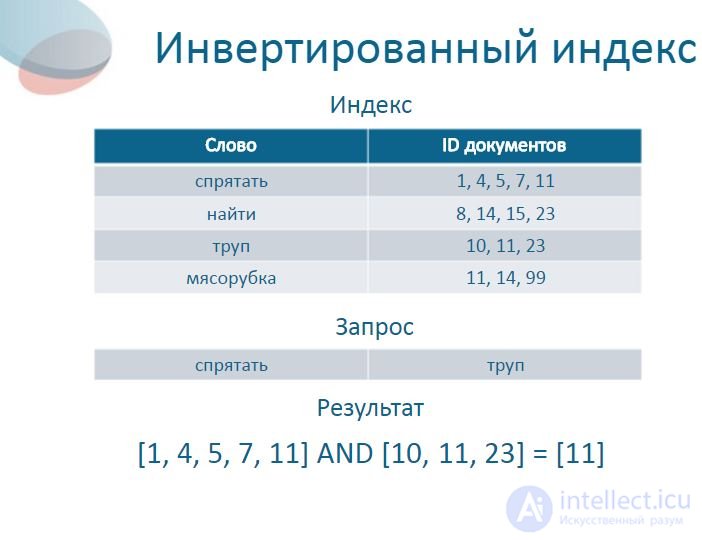
6 Inverted index Word ID of documents hide 1, 4, 5, 7, 11 to find 8, 14, 15, 23 dead bodies 10, 11, 23 meat grinders 11, 14, 99 Index Request to hide a corpse
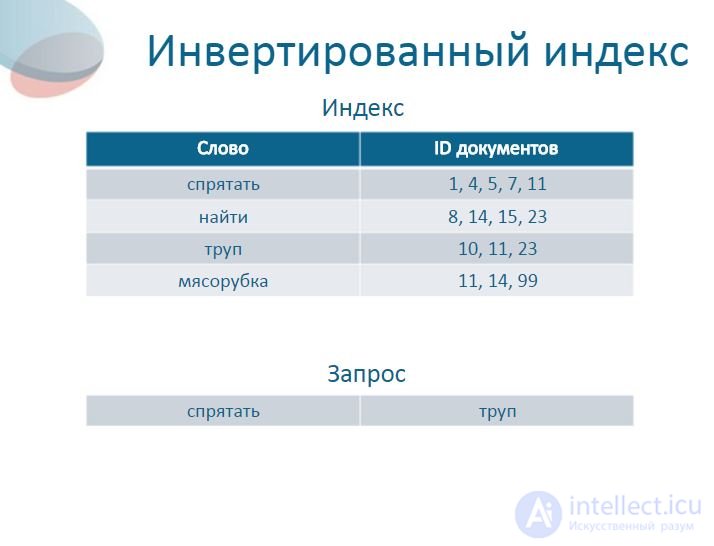
7 Inverted index WordID of documents hide1, 4, 5, 7, 11 to find8, 14, 15, 23 dead 10, 11, 23 meat grinder 11, 14, 99 Index Request to hide a corpse Result [1, 4, 5, 7, 11] AND [10, 11, 23] = [11]
8 Words Often it is important that the searched words go in a row. Need to take into account the position of words. Example: “It is better to hide jam from sunlight ... ... ... ... ... The jar was cold as a corpse.”

9 Words Position ID documents hide1, 11, ... to find8 corpses11, 23 meat grinders11, 14 Index The closer the words to each other, the more relevant the document as a result

10 Stages of normalization. Splitting a page into text zones. Splitting text into words. Converting words to terms. Deleting stop words.

11 Splitting a page into zones Page Header Meta-data Headers of different levels First block of text Lists Other blocks of text

12 Splitting text into words What is a delimiter? Specific words Compound words

13 Word delimiter Whitespace Punctuation characters Problems in English: ONeill arent

14 Specific words Some “words” look unusual. C ++ 127.0.0.1 T-34 Understand according to separate rules, patterns

15 Compound words Some words need to properly divide the city of Rostov-on-Don flight Los Angeles-San Francisco monologue "to be or not to be" Solution: compilation of statistics on the stability of the use of words

16 Grouping of words Term - a class of equivalent words that have insignificant differences (in endings, prefixes, etc.) [I hide, hidden, hid] ~ hide

17 Getting the terms Stemming (stemming) - sequential removal of insignificant parts of words Lemmatization - morphological analysis of a word, reduction to normal form

18 Porter’s Stemmer 5 steps, the end deletion rule is applied at each. First step: Plus: getting the term fast Minus: for many languages, the term is poorly perceived by humans
Stemming (stemming) - cutting off a word from endings and suffixes so that the rest, called stem , is the same for all grammatical forms of the word. Of course, in this form, a stemmer can only work with languages that implement inflection through affixes. Examples of such languages are Russian and English.
Usually stemmer used to search for text with imitation of accounting morphology. By imitation is meant a unavoidably large number of errors and irrelevant results that arise if only a stemmer is used. In Russian, the source of errors during stemming is all sorts of changes to the root of the word - quick vowels, for example. Clearly, the problems associated with the use of a stemmera can be demonstrated for the Russian noun cat . The plural plural is cats . Thus, the longest common prefix of all forms of the noun cat is kosh . If you search the text for this prefix, then the results are likely to contain words such as a nightmare . I note that usually implementations of the stemmer go a little different way and make a different kind of error - they return the cat prefix during the stemming and thus the fragments of text with the shape of cats disappear from the search results.
As a solution to the problem of bad search results with a stemmer for the Russian language, you can use two additional modules of the grammar dictionary - lemmatizer and flexer (declination and conjugation). With the help of a lemmatizer, words can be reduced to a basic form, so after matching the word with a system, you can refine the result using lemmatization. The second module is a flexer that can produce all grammatical forms of a word based on the base. This allows you to refine the search results by checking the found fragments on a set of keyword forms.
Steamming errors can be classified as follows.
Errors of the 1st kind stemming - the system gives too much generalization and therefore is compared with the grammatical forms of more than one dictionary entry. This is the most numerous group of errors stemming. For example, if you are given you by steming, then further text search will give you a match with a feast . In Russian, it can be very difficult to completely eliminate these errors, for example, the verb to fall when conjugating gives the form paddy and has fallen , as a result Stemming gives pa , and this is a very large extension when searching. However, errors of this type can also be considered as a way to include single words in the search - in the example with a cat these can be adjective forms of feline . Compensation of errors of the first kind is successfully performed either by introducing a list of stop words, or more qualitatively, by a lemmatizer or flexer.
Staging errors of the 2nd kind - truncation of the form gives too long a system, which is not matched with some grammatical forms of the same word. Such errors are caused by the strimer developer’s desire to find a compromise with the 1st kind errors in the case when the word base changes during inflection. Such words are even in an extremely regular English language in terms of inflection, for example, a group of irregular verbs. In Russian, cases of changing the base are not even grounds for classifying a word as incorrect, as is often the case. As an example, on which many implementations of stemmer usually stumble, we can take the words cat and pack , which have the shape of cats and packs . Usually stemmers perform in these cases truncation to cats and birds , which are incomparable with the forms of the genitive and accusative case of the plural.
3rd kind stemming errors - it is impossible to build a system because of a change in the root of a word that leaves a single letter in the system. Either the inflection model implies the use of consoles. An example for the first case is a verb to stick in , having the form of a cry . The second case arises within the framework of a grammatical dictionary for a comparative degree of adjectives and adverbs in Russian - for example, more beautiful as a form of an adjective beautiful , or more slowly as a form of adverb slowly .

19 Lemmatizer Parsing words by composition: (like at school, only automatically) Largest Russian lemmatizer: AOT.ru (py_morphy, PHPMorphy, ...) Pros: getting the term in a normal form, perceived by a person
The SQL schema of the dictionary contains separate tables designed exclusively for performing lemmatization:
LEXEMES_1 pairs of word-lemma, as well as an additional field - the number of alternative normal forms.
LEXEMES_N word-lemma pairs, unlike the previous table, there can be several records for each word.
LEMMAS - auxiliary table, a list of normal forms referenced by LEXEMES_1 and LEXEMES_N.
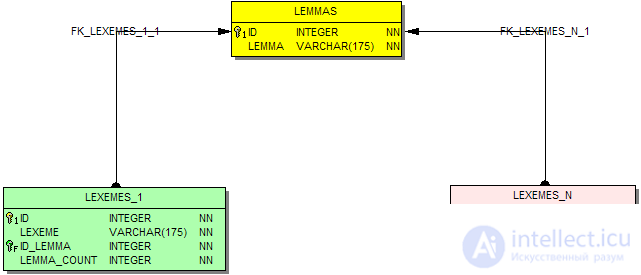
Using such a database query
SELECT lemma_ COUNT , COUNT (*) FROM lexemes_1 GROUP BY lemma_ COUNT
It is possible to determine how large the percentage of words in a natural language is that give ambiguous lemmatization, for example, for the Russian language:
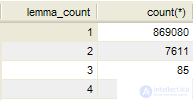
Thus, approximately 1% of the words of the Russian language can cause some difficulties in reducing to normal grammatical form. It should be noted that this distribution does not take into account the frequency of use of the corresponding words.
For example, such a query to the database of the dictionary
SELECT lexeme, lemma FROM lexemes_n, lemmas WHERE lemmas.id = id_lemma AND lexemes_n.lexeme = ' ROY '
will give such options lemmatization:
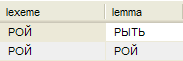
The expected result is that the imperative form of the verb to dig and the two case forms of the noun swarm textually the same.
The choice between fast, but sometimes incomplete lemmatization, and slow and exhaustive, depends on the problem being solved.
For example, in a search engine, the speed of indexing plays a decisive role, since the lemmatization of millions of lexemes becomes the main occupation of the processor. Therefore, the indexer with the command -index wordforms uses a simplified lemmatization - takes the first normal form, ignoring the other options.
On the other hand, a machine translator should carefully take into account all possible normal forms of translated words, therefore the speed of lemmatization is sacrificed for accuracy.
There are several calls in the API that allow directly or with additional steps to perform the conversion of a word to the basic form - lemmatization. Most of them work equally well with any of the languages supported in the project, of course with the appropriate vocabulary.
Two main challenges, designed specifically as lemmatizers:
sol_TranslateToBase
Simplified, but the fastest option. Looks for the single normal form of the word. If a word can be reduced to several basic forms, for example, there may be washing options and mine for mine , then any one of the alternatives is used at the discretion of the lemmatizer.
sol_TranslateToBases
A more complex and slower version of the previous procedure. If the input word can be lemmatized in more than one way, it returns all the options.
An example of using both procedures can be found in the source code of the demo program ... \ demo \ ai \ solarix \ Grammar_Engine \ Lemmatizer_Russian .
The following describes other API procedures that solve the same or close task.
sol_SeekWord
This is a quick search for dictionary entry id in any grammatical form. Like sol_TranslateToBase, the first version of the base form is taken if there are alternatives. An integer is returned - the key of the dictionary entry, which can be used for such operations as getting the name of the article, declension and conjugation, definition of the grammatical properties of the word.
sol_FindWord
Slow version of the search for a dictionary entry in any grammatical form.
sol_ProjectWord
Search for all possible vocabulary entries whose grammatical form is a word. The procedure will return a list, the elements of which allow you to get the integer id of the relevant dictionary entries. The peculiarity of this procedure is that its algorithm can, for an unknown word, try to pick up an article and a suffix prefix to find the original article. For example, a cat will be found for a supercot dictionary entry, as a productive super prefix is included in the number of checked.
sol_ProjectMisspelledWord
An extended version of the previous procedure allows you to search for dictionary entries in the form with possible misprints - omission of letters, substitutions, and extra letters.
In some applications, it is useful not only to lemmatize a word, but to get the noun from which the word is derived, for example, the terrible — fear . The API has a corresponding call:
sol_TranslateToNoun
There are several tables in the SQL schema of the dictionary that can be created and used offline, allowing you to search for basic forms of words.
For the Russian language, as already noted in the description of the lemmatization procedure through the grammar dictionary API, the main problem is the presence of ambiguities.
With the help of a simple query, you can see that there are a little more than 400 noun-verb pairs in the Russian lexicon, which have at least one grammatical form homonymous.
This query to the dictionary database:
SELECT DISTINCT E1.name AS "noun", E2.name AS "verb", F2.name AS "form"
FROM sg_form F1, sg_form F2, sg_entry E1, sg_entry E2
WHERE E1.id_class = 8 AND - Russian nouns
F1.id_entry = E1.id AND - their grammatical forms
F2.name = F1.name AND - the forms match
E2.id = F2.id_entry AND E2.id_class IN (13,14) - Russian verbs and infinitives
gives approximately the following table (several entries are shown):
| real | verb | the form |
|---|---|---|
| reality | to reveal | show |
| navigator | to storm | navigator |
| helmet | send | helmet |
| awl | to sew | awl |
| awl | to sew | sewed |
| awl | to sew | sewed |
| neck | to sew | the neck |
| shawl | to misbehave | shawls |
| imp | to draw | draw |
Now consider how to get the basic form of the word for any grammatical.
Query to the dictionary base is very simple:
SELECT DISTINCT Lower (sg_class.name), sg_entry.name
FROM sg_form, sg_entry, sg_class
WHERE sg_form.name = 'stumps' AND
sg_entry.id = sg_form.id_entry AND
sg_class.id = sg_entry.id_class - show part of speech
Please note that we do not fix the language of the words being processed.
The result of the above query, in which the basic forms for the word stumps are searched, is:

Stemmer is a simplified algorithm for morphological analysis of a word, optimized for the fastest possible finding of a prefix common to all grammatical forms of a given word. Typically, when stemming, the base includes the morphological root, along with the prefix. A stemmer always has a certain percentage of errors resulting from the inflectional characteristics of a natural language and the impossibility of reconciling the primitive idea of cutting off the "endings" with Russian inflection, and even more so with such linguistic phenomena as runaway vowels. In the Russian lexicon, approximately 1.7% of word forms have such a feature, for example, bag sacks , I will take it . Even such a regular language, like English, has an extensive set of exceptions to regular rules - irregular verbs and substantial verses that tend not to follow the general rule.
The undoubted plus of stemmera is the possibility of implementation without the use of an external database. For example, the software implementation of the stemming algorithm for the .NET platform is compiled as a single dll without additional dependencies and data files. To use it, it is enough to include the StemmerFX.dll assembly in the project - see the online example.
On the other hand, the vocabulary lemmatizer, available in the grammatical dictionary, allows with a much higher accuracy to find the basic form of a word from any grammatical one. From general considerations, it is clear that if we compare the result of the lemmatization of the desired keyword and the words read from the text, we will get just the text search taking into account the morphology. However, the lemmatization operation is slower than stemming, so the idea arises to combine both of these algorithms for a quick and relevant search for keywords. This approach is implemented in the StringLib library for the .NET platform. It allows you to search for a keyword by finding all occurrences of any grammatical form.
As noted above, the database of lemmatization rules is generated automatically by the dictionary compiler based on the vocabulary entries loaded into the lexicon and their grammatical forms. The generator is built with the widest possible assumptions on the lexical composition of the dictionary, so it is quite possible to obtain a module that returns the lemma for both Russian and English words.
The presence of a thesaurus focused on computer word processing allows you to implement more complex word transformations. For example, instead of a simple lemmatization, it is possible to return the basic form of the noun to which the dictionary entry is given in one request. For example, the adjective feline is a derivative of the noun cat . Можно приводить не только к форме существительного, но и к форме инфинитива, например причастие бегающий приводится к инфинитиву бегать . Более того, инфинитив бегать связан с существительным бег . Все эти связи, образующие сложную семантическую сеть, доступны для SQL запросов, пример одного из которых показан далее.
Итак, мы имеем несколько слов, принадлежащих к разным частям речи. Нам нужно для каждого из них выполнить лемматизацию, а затем по возможности найти форму существительного. Обратите внимание, что результат лемматизации может не допускать приведения к существительному - в этом случае мы вернем простую лемматизацию.
В справочнике типов связей можно найти числовой код нужного нам типа в_сущ=39 .
Составляем запрос к базе словаря:
SELECT DISTINCT COALESCE ( E2.name, E1.name )
FROM sg_form, sg_entry E1 LEFT JOIN sg_link ON id_entry1=E1.id
AND istate=39 -- тип связи <в_сущ>
LEFT JOIN sg_entry E2 ON E2.id=id_entry2
WHERE sg_form.name IN ( 'сияющими' , 'звенело' , 'по-кошачьи' )
AND E1.id=sg_form.id_entry
Результат его исполнения:

Лемматизатор может использоваться как автономно, так и загружаться в составе грамматического словаря. Параметры подключения и работы лемматизатора в этих случаях задаются в файле конфигурации словаряв отдельном XML-узле - см. здесь.
Кроме специализированного лемматизатора, описанного выше, нормализация текста может быть выполнена другими способами. Отметим из них два самых интересных.
Морфологический анализатор неявно дает на выходе информацию о леммах, так как он распознает для каждого исходного слова принадлежность к определенной словарной статье. У словарной статьи можно получить начальную форму слова, и таким образом решить задачу. Побочным эффектом такого алгоритма будет учет контекста слова и отбрасывание альтернативных вариантов распознавания.
Можно пойти дальше, и учесть информацию из тезауруса. Взяв результаты морфологического анализа предложения, можно для каждого слова проверить, не является ли оно уменьшительной ( котик ) или усилительной ( котище ) формой слова, и привести к нейтральной ( кот ). Более того, можно воспользоваться информацией о дериватах, к примеру выполнить приведение глаголов, деепричастий и причастий к форме абстрактного существительного движения или действия: изменять-изменение .
Далее представлено наглядное сравнение всех имеющихся видов лемматизации текста для одного и того же предложения.
Простая лемматизация:

Приведение к леммам как результат морфологического разбора предложения:

Глубокая нормализация текста с приведением к существительным с помощью тезауруса:


20 Стоп-слова Стоп-слово – слово, которое встречается во многих текстах, но никак текст не характеризует Примеры: союзы, междометия Запрос: «что делать с трупом он плохо пахнет»

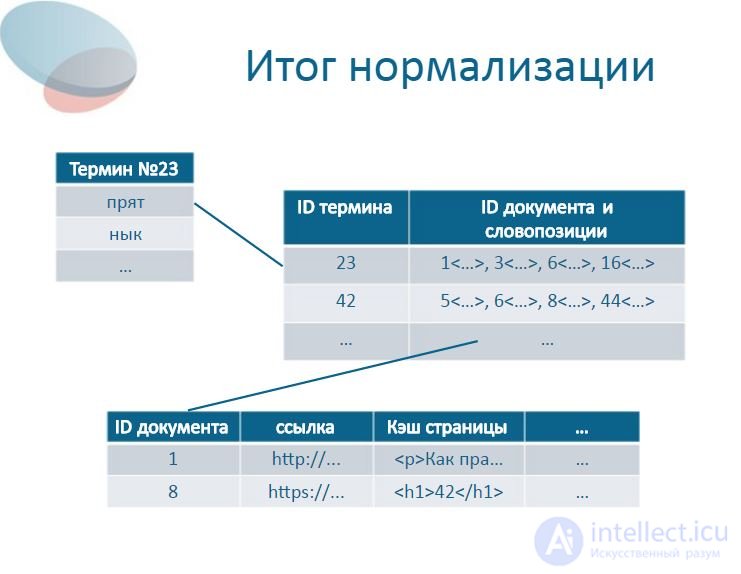
21 Итог нормализации Термин 23 прят нык … ID терминаID документа и словопозиции 231, 3, 6, 16 425, 6, 8, 44 …… ID документассылкаКэш страницы… 1http://... Как пра…… 8https://... 42 …
22 Нормализация и ранжирование Во время нормализации можно пытаться определить не только термины документа, но и их значимость для него Примеры: Орфографический словарь «Тихий Дон» на одной странице

23 Нормализация и ранжирование Во время нормализации можно пытаться определить не только термины документа, но и их значимость для него Примеры: Орфографический словарь «Тихий Дон» на одной странице

24 Document frequency Document frequency - how many documents contain this term. Defines how important the term is. The more specific the term, the less documents it contains. Stop words contain almost all documents.

25 Reverse document frequency The ratio of the number of documents with a term to the total number of documents: How does this function behave? What can happen with increasing N?

26 Term Frequency The term frequency in a document (term frequency) is the ratio of the number of occurrences of a term to all terms. Determines how important the term is for this document.

27 Scaling tf What to do with a document in which there are 20 repetitions of a term of 100 words?

28 Метрика wf-idf Поведение: Максимальное значение, если термин встречается часто в нескольких документах Уменьшается, если термин встречается нечасто и во многих документах («размазан») Минимален, если это стоп-слово, то есть встречается почти в каждом документе

29 Итоговый вид нормализованного документа Векторная модель документа (VSM) – каждый термин является вектором, направление вектора – термин длина вектора - вес ID терминаID документа, вес, 23(1, 12.4, ), (3, 1, ) … 42(21, 13.5, ), (3, 11.1, ) … ……

30 Обработка запроса Запрос нужно привести к тому же виду, что и проиндексированные страницы (перевести в термины) Так как запрос значительно меньше текстов документа, можно и нужно применять более сложный анализ

31 Этапы обработка запроса Исправление опечаток Преобразование в термины Поиск полного набора терминов Разбиение запроса на подзапросы Поиск подзапросов

32 Исправление опечаток Расстояние редактирования – для случая, когда палец попал на неправильную кнопку или есть 1-2 орфографических ошибок Фонетические исправления – для случая, когда человек не знает, как пишется слово, но знает, как оно звучит (пример: фр. oiseaux)

33 Расстояние Левенштейна Расстояние редактирования – количество простых операций для превращения одной строки в другую Простые операции: вставка символа удаление символа замена символа другим

34 Индекс Soundex Кодируем слово в индекс Soundex. Созвучные слова имеют одинаковый индекс. Пример индекса: R163: Rupert, Robert Для русского языка Soundex не доработан. Можно переводить слово в транслит и пользоваться английским

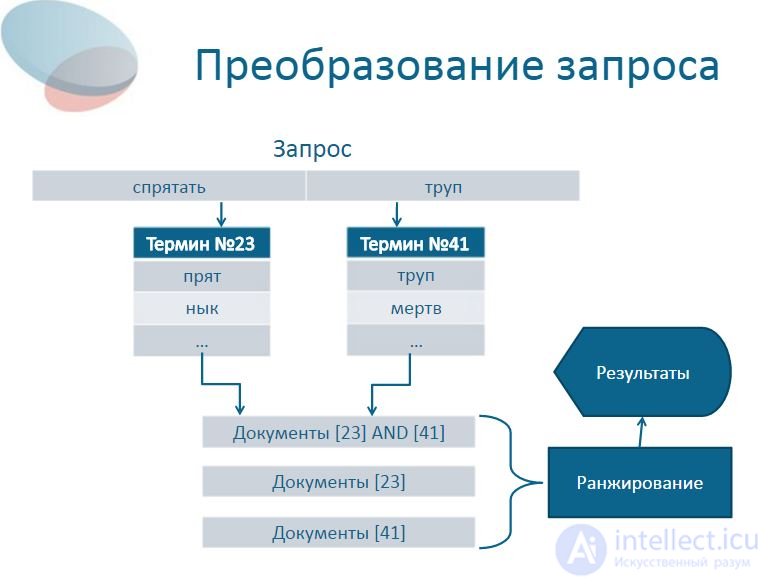
35 Query Transformations Term 23 are hidden ... Term 41 dead body ... Request to hide a corpse Documents [23] AND [41] Documents [23] Documents [41] Results Ranking

Comments