Lecture
A very large place in the processing of information takes work with texts. Like many other things, text strings in the Java language are objects. They are represented by instances of the class string or the class stringBuffer .
At first, this is unusual and seems too cumbersome, but when you get used to it, you will appreciate the convenience of working with classes, not with character arrays.
Of course, it is possible to add text to an array of characters of type char or even to an array of bytes of type byte , but then you cannot use ready-made methods for working with text strings.
Why are there two classes in the language for storing strings? Objects of the string class store constant strings of unchanged length and content, cast in bronze, so to speak. This significantly speeds up the processing of strings and saves memory by dividing the line between objects that use it. The length of the lines stored in objects of the class stringBuffer can be changed by inserting and adding lines and symbols, deleting substrings or concatenating several lines into one line. In many cases, when you need to change the length of a string of type string , the Java compiler implicitly converts it to type stringBuffer , changes the length, then converts it back to type string . For example, the following action
String s = "This is" + "one" + "string";
the compiler will do this:
String s = new StringBuffer (). Append ("This"). Append ("one")
.append ("string"). toString ();
An object of class stringBuffer will be created, the strings of "It", "one", "string" will be added to it sequentially, and the resulting object of class StringBuffer will be converted to the type String by the toString () method.
Recall that characters in strings are stored in Unicode, in which each character occupies two bytes. The type of each character is char .
Class string
Before working with a string, you should create it. This can be done in different ways.
How to create a string
The easiest way to create a string is to organize a string type reference to a constant string:
String si = "This is a string.";
If the constant is long, you can write it in several lines of a text editor, connecting them with a clutch operation:
String s2 = "This is a long string," +
"written in two lines of source text";
Comment
Do not forget the difference between the empty string string s = "" , which does not contain a single character, and the empty reference string s = null, which does not point to any string and is not an object.
The most correct way to create an object from the point of view of OOP is to call its constructor in the new operation. The string class provides you with nine constructors:
If the offset indexes, encoding codes or encoding encoding are incorrectly set, an exception is thrown.
Constructors using the byteArray byte array are intended to create Unicode strings from an array of byte ASCII character encodings. This situation occurs when reading ASCII files, extracting information from a database or transferring information over a network.
In the simplest case, the compiler for getting double-byte characters Unicode will add to each byte the most significant zero byte. This will result in the range '\ u0000' - '\ u00ff' of the Unicode encoding corresponding to the Latin 1 codes. Texts in Cyrillic will not be displayed correctly.
If local settings are made on the computer, as they say in the jargon “locale is set” (in MS Windows this is done by the Regional Options utility in the Control Panel ), then the compiler, having read these settings, will create Unicode characters corresponding to the local code page. In the Russian version of MS Windows, this is usually the CP1251 code page.
If the original array with Cyrillic ASCII text was encoded in CP1251, then the Java string will be created correctly. Cyrillic will fall into its range '\ u0400' - '\ u04FF' in Unicode encoding.
But the Cyrillic alphabet still has at least four encodings.
For example, byte 11100011 ( 0xЕ3 in hexadecimal form) in the coding CP1251 represents the Cyrillic letter G , in the coding CP866 - the letter U , in the encoding KOI8-R - the letter C , in ISO8859-5 - the letter y , in MacCyrillic - the letter G.
If the original Cyrillic ASCII text was in one of these encodings, and the local encoding is CP1251, then the Unicode characters of the Java string will not correspond to Cyrillic.
In these cases, the last two constructors are used, in which the encoding parameter indicates which code table to use to the constructor when creating the string.
Listing 5.1 shows various cases of writing Cyrillic text. It creates three arrays of baito'v, containing the word "Russia" in three encodings.
Three lines are created from each array using three code tables.
In addition, the string s1 is created from the array of characters with [] , the string s2 is created from the array of bytes written in the CP866 encoding. Finally, a reference to the constant string is created.
Listing 5.1. Creating Cyrillic Strings
public class HelloWorld{
public static void main(String[] args){
String winLikeWin = null, winLikeDOS = null, winLikeUNIX = null;
String dosLikeWin = null, dosLikeDOS = null, dosLikeUNIX = null;
String unixLikeWin = null, unixLikeDOS = null, unixLikeUNIX = null;
String msg = null;
byte[] byteCp1251 = {
(byte)0xD0, (byte)0xEE, (byte)0xFl,
(byte)0xFl, (byte)0xE5, (byte)0xFF
};
byte[] byteCp866 = {
(byte)0x90, (byte)0xAE, (byte)0xE1,
(byte)0xEl, (byte)0xA8, (byte)0xEF
};
byte[] byteKOI8R = {
(byte)0xF2, (byte)0xCF, (byte)0xD3,
(byte)0xD3, (byte)0xC9, (byte)0xDl
};
char[] chars = {'К', 'а', 'п', 'у', 'с', 'т', 'а'};
String s1 = new String(chars);
String s2 = new String(byteCp866); // Для консоли
String s3 = "Капуста";
System.out.println();
try{
// Сообщение в Cp866 для вывода на консоль
msg = new String("\"Капуста\" в ".getBytes("Ср866") , "Cp1251");
winLikeWin = new String(byteCp1251, "Cp1251"); //Правильно
winLikeDOS = new String(byteCp1251, "Cp866");
winLikeUNIX = new String(byteCp1251, "KOI8-R");
dosLikeWin = new String(byteCp866, "Cp1251"); // Для консоли
dosLikeDOS = new String(byteCp866, "Cp866"); // Правильно
dosLikeUNIX = new String(byteCp866, "KOI8-R");
unixLikeWin = new String(byteKOI8R, "Cp1251");
unixLikeDOS = new String(byteKOI8R, "Cp866");
unixLikeUNIX = new String(byteKOI8R, "KOI8-R"); // Правильно
System.out.print(msg + "Cpl251: ");
System.out.write(byteCp1251);
System.out.println();
System.out.print(msg + "Cp866 : ");
System.out.write (byteCp866) ;
System.out.println();
System.out.print(msg + "KOI8-R: ");
System.out.write(byteKOI8R);
}catch(Exception e){
e.printStackTrace();
}
System.out.println();
System.out.println();
System.out.println(msg + "char array : " + s1);
System.out.println(msg + "default encoding : " + s2);
System.out.println(msg + "string constant : " + s3);
System.out.println();
System.out.println(msg + "Cp1251 -> Cp1251: " + winLikeWin);
System.out.println(msg + "Cp1251 -> Cp866 : " + winLikeDOS);
System.out.println(msg + "Cp1251 -> KOI8-R: " + winLikeUNIX);
System.out.println(msg + "Cp866 -> Cp1251: " + dosLikeWin);
System.out.println(msg + "Cp866 -> Cp866 : " + dosLikeDOS);
System.out.println(msg + "Cp866 -> KOI8-R: " + dosLikeUNIX);
System.out.println(msg + "KOI8-R -> Cpl251: " + unixLikeWin);
System.out.println(msg + "KOI8-R -> Cp866 : " + unixLikeDOS);
System.out.println(msg + "KOI8-R -> KOI8-R: " + unixLikeUNIX);
}
}
All this data is output to the MS Windows console, as shown in Figure. 5.1.
The first three lines of the console display byteCP1251 , byteCP866, and byteKOI8R byte arrays without conversion to Unicode. This is done using the write () method of the FilterOutputStream class from the java.io package.
The next three console lines display Java strings derived from an array of characters from [] , a byteCP866 array , and constant strings.
The following console lines contain converted arrays.
You can see that only the array in the CP866 encoding, written into a string using the code table CP1251, is correctly output to the console.
What's the matter? Here, a contribution to the problem of Russification brings a stream of characters to the console or to a file.
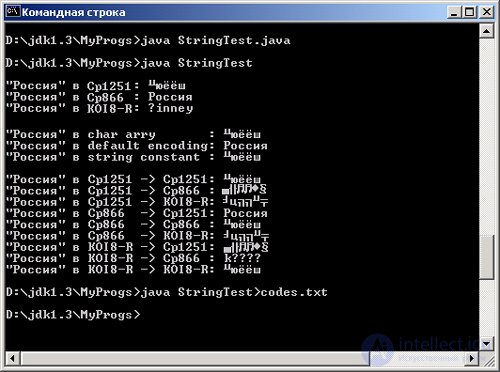
Fig. 5.1. Output Cyrillic string on the console MS Windows
As mentioned in Chapter 1, text is displayed in the CP866 encoding in the Command Prompt console window of the MS Windows operating system.
In order to take this into account, the words "\" Russia \ "in" are converted into a byte array, containing characters in the CP866 encoding, and then translated into the msg string.
The penultimate line in fig. 5.1 redirected the output of the program to the codes.txt file. In MS Windows , text is output to a file in the CP1251 encoding. In fig. 5.2 shows the contents of the codes.txt file in the Notepad window.
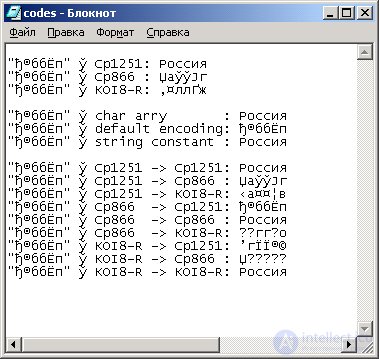
Fig. 5.2. Output Cyrillic string to file
As you can see, the Cyrillic alphabet looks completely different. Correct Cyrillic Unicode characters are obtained by using the same code table that contains the original byte array.
We will discuss Russification issues in Chapters 9 and 18, but for now, notice that when creating a string from a byte array, it is better to specify the same Cyrillic encoding in which the array is written. Then you get a Java string with the correct Unicode characters.
When outputting a string to the console, to a window, to a file, or when transmitting over the network, it is better to convert the Java string with Unicode characters according to the output rules in the right place.
Another way to create a string is to use two static methods.
copyValueOf (chart] charArray) and copyValueOf (char [] charArray, int offset, int length).
They create a string for a given array of characters and return it as the result of their work. For example, after executing the following program fragment
chart] c = ('С', 'и', 'м', 'в', 'о 1 ,' л ',' ь ',' н ',' с ',' ь '};
String s1 = String.copyValueOf (c);
String s2 = String.copyValueOf (s, 3, 7);
we obtain the string " Character " in the s1 object, and the string " free " in the s2 object.
String concatenation
With strings, you can perform the operation of concatenating strings (concatenation), denoted by the plus sign +. This operation creates a new line, just made up of matching first and second lines, as shown at the beginning of this chapter. It can be applied to both constants and variables. For example:
String attention = "Warning:";
String s = attention + "unknown character";
The second operation - assignment + = - is applied to variables on the left side:
attention + = s;
Since operation + is overloaded with adding numbers to concatenation of strings, the question of the priority of these operations arises. At the clutch of lines the priority is higher than that of addition, therefore, having written down "2" + 2 + 2 , we get the string " 222 ". But, having written down 2 + 2 + "2" , we get the string "42", since the actions are performed from left to right. If we write "2" + (2 + 2) , then we get "24" .
String manipulation
The string class has many methods for working with strings. Let's see what they allow to do.
How to know the length of the string
In order to find out the length of a string, i.e. the number of characters in it, you need to refer to the length () method:
String s = "Write once, run anywhere.";
int len = s.length {);
or even easier
int len = "Write once, run anywhere.". length ();
since the string-constant is a full-fledged object of class string . Note that the string is not an array, it does not have a length field.
Attentive reader who studied rice. 4.7, ready to disagree with me. Well, what, indeed, the characters are stored in an array, but it is closed, like all fields of the class string .
How to choose characters from string
The charAt (int ind) method can be used to select a symbol with the ind index (the index of the first character is zero). If the ind index is negative or not less than the length of the string, an exception occurs. For example, after determining
char ch = s.charAt (3);
the variable ch will have the value 't'
All characters in a string as an array of characters can be obtained by
toCharArray () , which returns an array of characters.
If it is necessary to include in the array of dst symbols, starting from the ind index of the array, the substring from the begin index inclusive to the end index is exclusive, then use the getChars (int begin, int end, char [] dst, int ind) type of void .
End - begin characters will be written into the array, which will occupy the elements of the array, starting with ind ind and ind + (end - begin) - 1 .
This method creates an exception in the following cases:
For example, after
char [] ch = ('K', 'o', 'p', 'o', 'l', '' '', '', 'l', 'e', 't', 'a'};
"Password is easy to find." GetChars (2, 8, ch, 2);
the result will be:
ch = ('K', 'o', 'p', 'o', 'l', 'ь', '', 'l', 'e', 't', 'a'};
If you need to get an array of bytes containing all the characters of a string in ASCII byte encoding, use the getBytes () method.
This method uses a local code table when translating characters from Unicode to ASCII.
If you need to get an array of bytes not in the local encoding, but in some other one, use the getBytes (String encoding) method.
This is done in Listing 5.1 when creating the msg object. The string "\ 'Tossia \" "was encoded into an array of CP866-bytes for correct output of Cyrillic to the Command Prompt console window of the Windows operating system.
How to choose a substring
The substring method (int begin, int end) selects the substring from the character with the begin index inclusively to the character with the end index exclusively. The length of the substring will be equal to end - begin .
The substring (int begin) method selects a substring from the begin index inclusively to the end of the string.
If the indices are negative, the end index is greater than the length of the string, or begin is greater than end , then an exception occurs.
For example, after
String s = "Write onse, run anywhere.";
String sub1 = s.substring (6, 10);
String sub2 = s.substring (16);
we get the value " once " in the string sub1 , and the value " anywhere " in sub2 .
How to compare strings
The comparison operation == matches only references to strings. She finds out if the links point to the same line. For example, for strings
String s1 = "Some string";
String s2 = "Other-string";
comparing s1 == s2 results in false .
The true value is obtained only if both references point to the same line, for example, after assigning si = s2 .
Interestingly, if we define s2 like this:
String s2 == "Some string";
then comparing s1 == s2 will result in true , because the compiler will create only one instance of the "Some string" constant and send all references to it.
You, of course, want to compare not the links, but the contents of the lines. There are several methods for this.
The equals (object obj) boolean method, redefined from the object class, returns true if the obj argument is not null , is an object of the string class, and the string contained in it is completely identical to the given string until the case of letters is identical. Otherwise, it returns false .
The logical method equalsIgnoreCase (object obj) works in the same way, but the same letters written in different registers are considered to be the same.
For example, s2.equals ("another string") will result in false , and s2.equalsIgnoreCase ("another string") will return true .
The compareTo (string str) method returns an integer of type int , calculated according to the following rules:
If the value of str is null , an exception is thrown.
Null is returned in the same situation in which the equals () method returns true .
The compareToignoreCase (string str) method makes a case-insensitive comparison; more precisely, the method is executed.
this.toUpperCase (). toLowerCase (). compareTo (
str.toUpperCase (). toLowerCase ());
Another method — compareTo (Object obj) creates an exception if obj is not a string. Otherwise, it works like the compareTo (String str) method .
These methods do not take into account the alphabetic location of characters in the local encoding.
Russian letters are located in Unicode in alphabetical order, with the exception of one letter. The capital letter E is located in front of all Cyrillic letters, its code is '\ u040l ', and the lowercase letter e is after all Russian letters, its code is '\ u0451 '.
If this arrangement does not suit you, specify your placement of letters using the RuleBasedCollator class from the java.text package.
You can compare the substring of the given string this with the substring of the same length len of the other string str by a logical method
regionMatches (int indl, String str, int ind2, int len)
Here ind1 is the index of the beginning of the substring of the given string this, ind2 is the index of the beginning of the substring of the other string str . The result is false in the following cases:
This method distinguishes characters written in different registers. If it is necessary to compare substrings without registering letters, then use a logical method:
regionMatches (boolean flag, int indl, String str, int ind2, int len)
If the first parameter flag is true , then the case of letters is not taken into account when comparing substrings, if false it is taken into account.
How to find a character in a string
Search is always case-sensitive.
The first appearance of the character ch in the given line this can be traced by the method indexOf (int ch) , which returns the index of this character in the string or -1 if the character ch is not in the string this .
For example, "Milk", indexOf ('o') will result in a 1 .
Of course, this method performs sequential comparisons of this.charAt in a loop (k ++> = = ch until it is true .
The second and the following occurrences of the character ch in this line can be traced using the indexOf method (int ch, int ind) .
This method starts searching for the character ch from the index ind . Если ind < о, то поиск идет с начала строки, если ind больше длины строки, то символ не ищется, т. е. возвращается -1.
Например, "молоко".indexof('о', indexof ('о') + 1) даст в результате 3. .
Последнее появление символа ch в данной строке this отслеживает метод lastIndexof (int ch). Он просматривает строку в обратном порядке. Если символ ch не найден, возвращается.-1.
Например, "Молоко".lastindexof('о') даст в результате 5.
Предпоследнее и предыдущие появления символа ch в данной строке this можно отследить методом lastIndexof(int ch, int ind) , который просматривает строку в обратном порядке, начиная с индекса ind .
Если ind больше длины строки, то поиск идёт от конца строки, если ind < о, то возвращается-1.
Как найти подстроку
Поиск всегда ведется с учетом регистра букв.
Первое вхождение подстроки sub в данную строку this отыскивает метод indexof (String sub). Он возвращает индекс первого символа первого вхождения подстроки sub в строку или -1, если подстрока sub не входит в строку this . Например, " Раскраска ".indexof ("рас") даст в результате 4.
Если вы хотите начать поиск не с начала строки, ас какого-то индекса ind , используйте метод indexOf (String sub, int ind). если i nd < 0 , то поиск
идет с начала строки, если ind больше .длины строки, то символ не ищется, т. е. возвращается -1.
Последнее вхождение подстроки sub в данную строку this можно отыскать методом lastindexof ( string sub ), возвращающим индекс первого символа последнего вхождения подстроки sub в строку this или (-1), если подстрока sub не входит в строку this .
Последнее вхождение подстроки sub не во всю строку this , а только в ее начало до индекса ind можно отыскать методом l astIndexof(String stf, int ind ). Если ind больше длины строки, то .поиск идет от конца строки, если ind < о , то возвращается -1.
Для того чтобы проверить, не начинается ли данная строка this с подстроки sub , используйте логический метод startsWith(string sub) , возвращающий true , если данная строка this начинается с подстроки sub , или совпадает с ней, или подстрока sub пуста.
Можно проверить и появление подстроки sub в данной строке this , начиная с некоторого индекса ind логическим методом s tartsWith(String sub),int ind). Если индекс ind отрицателен или больше длины строки, возвращается false .
Для того чтобы проверить, не заканчивается ли данная строка this подстрокой sub , используйте логический метод endsWitht(String sub) . Учтите, что он возвращает true , если подстрока sub совпадает со всей строкой или подстрока sub пуста.
Например, if (fileName.endsWith(". Java")) отследит имена файлов с исходными текстами Java.
Перечисленные выше методы создают исключительную ситуацию, если
sub == null.
Если вы хотите осуществить поиск, не учитывающий регистр букв, измените предварительно регистр всех символов строки.
Как изменить регистр букв
Метод toLowerCase () возвращает новую строку, в которой все буквы переведены в нижний регистр, т. е. сделаны строчными.
Метод toUpperCase () возвращает новую строку, в которой все буквы переведены в верхний регистр, т. е. сделаны прописными.
При этом используется локальная кодовая таблица по умолчанию. Если нужна другая локаль, то применяются методы toLowerCase(Locale l oc) и toUpperCase(Locale loc).
Как заменить отдельный символ
Метод replace (int old, int new) возвращает новую строку, в которой все вхождения символа old заменены символом new . Если символа old в строке нет, то возвращается ссылка на исходную строку.
Например, после выполнения " Рука в руку сует хлеб" , replace ('у', 'е') получим строку " Река в реке сеет хлеб".
Регистр букв при замене учитывается.
Как убрать пробелы в начале и конце строки
Метод trim о возвращает новую строку, в которой удалены начальные и конечные символы с кодами, не превышающими '\u0020 '.
Как преобразовать данные другого типа в строку
В языке Java принято соглашение — каждый класс отвечает за преобразование других типов в тип этого класса и должен содержать нужные для этого методы.
Класс string содержит восемь статических методов valueof (type elem) преобразования В строку примитивных типов boolean, char, int, long, float, double , массива char[] , и просто объекта типа object .
Девятый метод valueof(char[] ch, int offset, int len) преобразует в строку подмассив массива ch , начинающийся с индекса offset и имеющий len элементов.
Кроме того, в каждом классе есть метод tostring () , переопределенный или просто унаследованный от класса Object . Он преобразует объекты класса в строку. Фактически, метод valueOf о вызывает метод tostring() соответствующего класса. Поэтому результат преобразования зависит от того, как реализован метод tostring ().
Еще один простой способ — сцепить значение elem какого-либо типа с пустой строкой: "" + elem. При этом неявно вызывается метод elem. toString ().
Класс StringBuffer
Объекты класса StringBuffer — это строки переменной длины. Только что созданный объект имеет буфер определенной емкости (capacity), по умолчанию достаточной для хранения 16 символов. Емкость можно задать в конструкторе объекта.
Как только буфер начинает переполняться, его емкость автоматически увеличивается, чтобы вместить новые символы.
В любое время емкость буфера можно увеличить, обратившись к методу ensureCapacity(int minCapacity)
Этот метод изменит емкость, только если minCapacity будет больше длины хранящейся в объекте строки. Емкость будет увеличена по следующему правилу. Пусть емкость буфера равна N. Тогда новая емкость будет равна
Мах(2 * N + 2, minCapacity)
Таким образом, емкость буфера нельзя увеличить менее чем вдвое.
Методом setLength(int newLength) можно установить любую длину строки.
Если она окажется больше текущей длины, то дополнительные символы будут равны ' \uOOOO' . Если она будет меньше текущей длины, то строка будет обрезана, последние символы потеряются, точнее, будут заменены символом '\uOOOO' . Емкость при этом не изменится.
Если число newLength окажется отрицательным, возникнет исключительная ситуация.
Board
Будьте осторожны, устанавливая новую длину объекта.
Количество символов в строке можно узнать, как и для объекта класса String , методом length () , а емкость — методом capacity ().
Создать объект класса stringBuf fer можно только конструкторами.
Конструкторы
В классе stringBuffer три конструктора:
stringBuffer () — создает пустой объект с емкостью 16 символов;
stringBuffer .(int capacity) — создает пустой объект заданной емкости capacity ;
StringBuffer (String str) — создает объект емкостью str . length () + 16, содержащий строку str .
Как добавить подстроку
В классе stringBuffer есть десять методов append (), добавляющих подстроку в конец строки. Они не создают новый экземпляр строки, а возвращают ссылку на ту же самую, но измененную строку.
Основной метод append (string str) присоединяет строку str в конец данной строки. Если ссылка str == null, то добавляется строка "null".
Шесть методов append (type elem) добавляют примитивные типы boolean, char, int, long, float, double, преобразованные в строку.
Два метода присоединяют к строке массив str и подмассив sub символов,
преобразованные в строку: append (char [] str) И append (char [.] , sub, int offset, int len).
Десятый метод добавляет просто объект append (Object obj). Перед этим объект obj преобразуется в строку своим методом tostring ().
Как вставить подстроку
Десять методов insert () предназначены для вставки строки, указанной параметром метода, в данную строку. Место вставки задается первым параметром метода ind . Это индекс элемента строки, перед которым будет сделана вставка. Он должен быть неотрицательным и меньше длины строки, иначе возникнет исключительная ситуация. Строка раздвигается, емкость буфера при необходимости увеличивается. Методы возвращают ссылку ни ту же преобразованную строку.
Основной метод insert (int ind, string str) вставляет строку str в данную строку перед ее символом с индексом and . Если ссылка s tr == null вставляется строка "null".
Например, после выполнения
String s = new StringBuffer("Это большая строка"). insert(4, "не").toString();
П ОЛУЧИМ s == "Это небольшая строка".
Метод sb.insert(sb.length о, "xxx") будет работать так же, как метод
sb.append("xxx") .
Шесть методов insert (int ind, type elem) вставляют примитивные типы boolean, char, int, long, float, double, преобразованные в строку.
Два метода вставляют массив str и подмассив sub символов, преобразованные в строку:
i nsert(int ind, chart] str)
insert(int ind, char[] sub, int offset, int len)
Десятый метод вставляет просто объект :
insert(int ind, Object obj)
Объект obj перед добавлением преобразуется в строку своим методом
toString ().
Как удалить подстроку
Метод delete tint begin, int end) удаляет из строки символы, начиная с индекса begin включительно до индекса end исключительно, если end больше длины строки, то до конца строки.
Например, после выполнения
String s = new StringBuffer("Это небольшая строка").
delete(4, 6).toString();
will get s == "Это большая строка".
Если begin отрицательно, больше длины строки или больше end , возникает исключительная ситуация.
Если begin == end, удаление не происходит.
Как удалить символ
The deieteCharAt (int ind) method removes the character with the specified index ind . The length of the string is reduced by one.
If the index ind is negative or greater than the length of the string, an exception is thrown.
How to replace a substring
The replace method (int begin, int end. String str ) removes characters from a string, starting with the begin index inclusively to the index end exclusively, if end is greater than the length of the string, then to the end of the string, and inserts the string str instead.
If begin is negative, greater than the length of the string or greater than end , an exception occurs.
Of course, the replace () method is a consistent execution of methods.
delete () and insert ().
How to flip a string
The reverse about method reverses the order of characters in a string.
For example, after
String s = new StringBuffer ("This is a small string"),
reverse (). toString ();
we get s == "actions elobene from EE".
Parsing a string
The task of parsing the entered text - parsing - is the eternal task of programming, along with sorting and searching. There are a lot of parser programs that parse the text for various reasons. There are even programs that generate parsers according to specified parsing rules: YACC, LEX, etc.
But the challenge remains. And now another programmer, desperate to find something suitable, takes up the development of his own parsing program.
The java.utii package includes a simple stringiokenizer class that makes it easy to parse strings.
Class StringTokenizer
The StringTokenizer class from the java.utii package is small, it has three constructors and six methods.
The first constructor, StringTokenizer (String str), creates an object that is ready to break the string str into words, separated by spaces, tab characters '\ t', line feed '\ n' and carriage return '\ r' . Separators are not included in the number of words.
The second StringTokenizer constructor (String str. String delimeters) sets the delimiters with the second deiimeters parameter, for example:
StringTokenizer ("Execute, not possible: no spaces", "\ t \ n \ r,: -");
Here the first separator is a space. Then come the tab character, the line feed character, the carriage return character, a comma, a colon, a hyphen. The order of the separators in the deiimeters string does not matter. Separators are not included in the number of words.
The third constructor allows you to include delimiters in the number of words:
StringTokenizer (String str, String deiimeters, boolean flag);
If the flag parameter is true , then delimiters are included in the number of words, if false is not. For example:
StringTokenizer ("a - (b + c) / b * c", "\ t \ n \ r + * - / (), true);
Two methods are actively involved in parsing word strings:
The nextToken () method returns the next word as a string;
the hasMoreTokens () boolean method returns true if there are still words in the string, and false if there are no more words.
The third method countTokens () returns the number of remaining words.
The fourth method nextToken (string newDeiimeters) allows you to change separators on the fly. The next word will be highlighted by new delimiters newDeiimeters; new delimiters act further instead of the old delimiters defined in the constructor or the previous nextToken () method.
The remaining two methods, nextEiement () and hasMoreEiements (), implement the Enumeration interface. They simply refer to the nextToken () and hasMoreTokens () methods .
The scheme is very simple (Listing 5.2).
Listing 5.2. Breaking a string into words:
String s = "The string we want to break into words";
StringTokenizer st = new StringTokenizer (s, "\ t \ n \ r ,.");
while (st.hasMoreTokens ()) {
// Get the word and do something with it, for example,
// just display
System.out.println (st.nextToken ());
}
The resulting words are usually entered into some collection class: Vector, Stack, or another container most suitable for further text processing. Collection classes will be covered in the next chapter.
Conclusion
All the methods of the classes presented in this chapter are written in the Java language. Their source code can be viewed, they are part of the JDK. These are very useful activities. After reviewing the source code, you get a complete picture of how the method works.
In the latest versions of JDK, source files are stored in a src.jar file packed with a jar archive located in the root directory of the JDK, for example, in the D: \ jdk l.3 directory.
To unpack them, go to the jdk l.3 directory:
D:> cd jdkl.3
and call the jar archiver as follows:
D: \ jdkl.3> jar -xf src.jar
The src subdirectory appears in the jdkl.3 directory, and the subdirectories corresponding to the packages and subpackages of the JDK with the source files appear in it.

Comments
To leave a comment
Object oriented programming
Terms: Object oriented programming