Lecture
The task of the study was to determine the volume of passive vocabulary of speakers of the Russian language. The measurement was carried out using a test in which respondents were asked to mark familiar words from a specially composed sample. According to the rules of the test, the word was considered “familiar” if the respondent could define at least one of its meanings. The test method is described in detail here. To improve the accuracy of the test and to identify respondents who pass it carelessly, non-existent words were added to the test. If the respondent marked at least one such word as familiar, his results were not taken into account. The study involved more than 150 thousand people (of which passed the test carefully - 123 thousand).
First, let's analyze the effect of age on vocabulary.
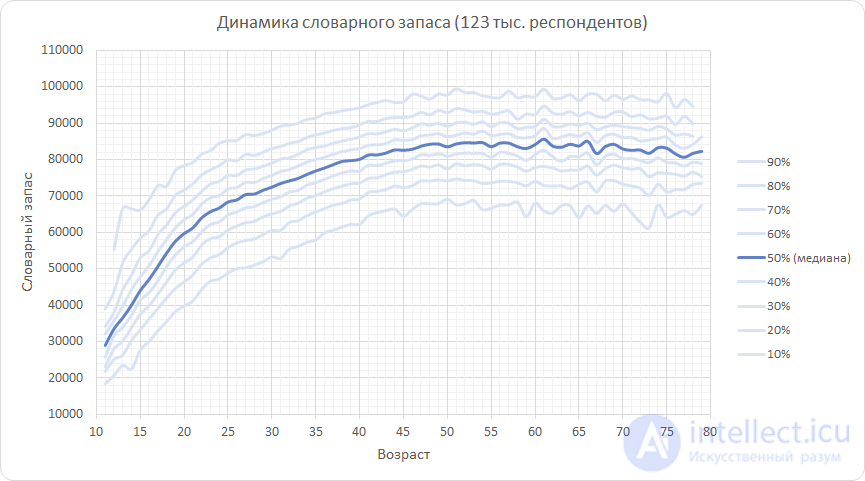
The graph shows the percentages of the resulting distribution. For example, the lowest curve (10th percentile) for 20 years gives 40 thousand words. This means that 10% of respondents of this age have a vocabulary lower than this value, and 90% have a higher vocabulary. The central curve (median) highlighted in blue corresponds to a vocabulary such that half of the respondents of the corresponding age showed a result worse, and half - better. The topmost curve - the 90th percentile - cuts off the result, above which only 10% of respondents showed with the maximum vocabulary.
The graph shows the following:
Now we will divide all respondents into groups according to the level of education. The following graph shows the median vocabulary of these groups. The curves start and end in different places due to the fact that the statistics for all groups are different - for example, there were not enough respondents with incomplete secondary education over 45 that the results were statistically significant, so we had to break the corresponding curve so early.
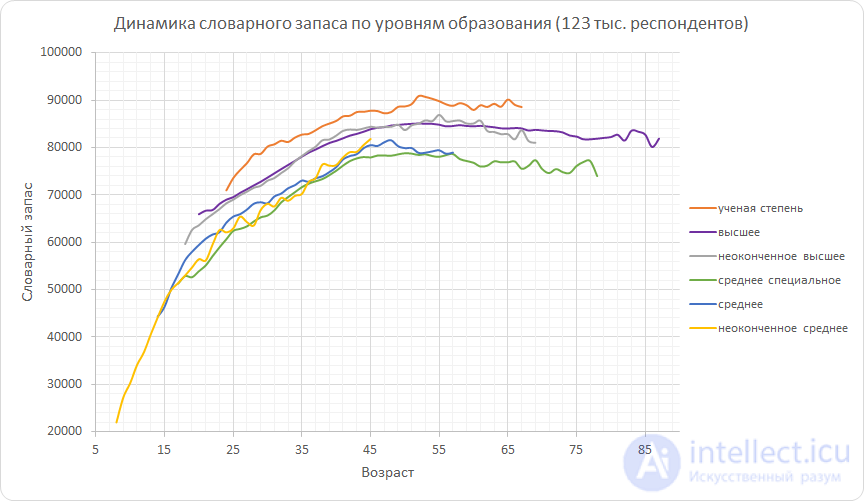
From the graph you can see that
Now exclude the influence of age, leaving only respondents older than 30 years in the sample. This will allow you to concentrate on education.
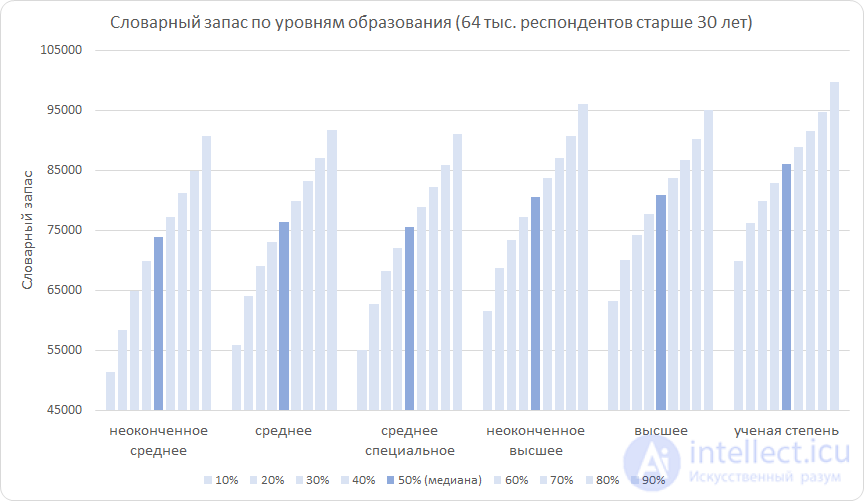
From the graph we see the following:
The resulting study of the magnitude of the vocabulary - tens of thousands of words - seems rather large. There are two reasons for this. First, passive vocabulary was measured (words that a person learns in the text or by ear), and not active vocabulary (words that a person uses in speech or in writing). These stocks differ many times - passive always much more. Estimated vocabulary writers, for example, are just active. Secondly, in the test all derived words were counted separately (for example, “work” and “work”, or “city” and “city”).
Separately, I would like to note that the results obtained do not give an idea of the vocabulary of the “average” (if such exists) native Russian speaker. For example, the level of education of respondents who have passed the test is significantly higher than the all-Russian - 65% of respondents have a higher education, whereas in Russia only 23% of them (according to the all-Russian population census of 2010). Then, it is obvious that respondents who have passed the Internet test are mainly active Internet users, and this also makes the sample specific (mainly for the elderly). In the end, not everyone is interested in defining their vocabulary; among our respondents, it’s 100%. It is logical to assume that the vocabulary results obtained from such a particular sample should be somewhat higher than the “average”.
So, the data obtained revealed a strong dependence of vocabulary on age, and a weaker one on the level of education. Obviously, there are other factors that affect the vocabulary - reading, communication, work, hobby, lifestyle.
The purpose of this test is to determine your passive vocabulary (that is, the number of words you will learn when reading and listening). The only way to do this for sure is to take a thicker dictionary (thousands of words for a hundred words), mark all the words you know, and count them. There is hardly anyone willing to go for a similar test. The task, fortunately, is greatly simplified, if you make one reasonable assumption - the probability of knowing the words used in the language equally often is about the same. In other words, if you know the word “cat”, then you will also know the word “dog”, and if you don’t know what “ambivalence” is, then you do not know “transcendence” either. Thus, it is possible to group words by complexity - from the simplest to the rarest, and from each group choose one representative. If you know this word - you can assume that you know the whole group too. If there are a lot of groups (at least a hundred), then this method will allow you to determine the vocabulary quite accurately.
Technically, the vocabulary definition method is simple, but the devil, as always, is in the details.
So, the first task was to build a fairly complete frequency dictionary of the Russian language (unfortunately, the existing frequency dictionaries are too small to determine the vocabulary of a well-read Russian speaker). Two things are needed for this. The first is the fullest possible dictionary of the Russian language; The Ephraim Dictionary was used (136 thousand words, a small number of words were also taken from the Hagen dictionary), http://www.speakrus.ru/dict). The second is the Russian language corpus; The Russian National Corps was used (http://www.ruscorpora.ru). The corpus consists of a large number (86 thousand) of texts of various subjects - fiction, journalism, scientific and popular science, religious and philosophical texts, personal correspondence, diaries; total volume of texts - 230 million words. Due to the large volume and wide coverage, this corpus is a cast of modern (54% of all texts were created after 1950) of the Russian language. For each word from the Ephraim dictionary, using the corpus, its frequency was found - a measure of how often this word is used in the language (frequency is usually measured in terms of the number of words used per million corpus words). The resulting frequency dictionary was then sorted - from high-frequency (simple) words to low-frequency (complex).
The basic idea of a statistical approach to vocabulary assessment is that the probability of knowledge of a word to subjects depends on the frequency of the word (how often this word is found in texts or used in speech). This, however, is not entirely true. For example, the word “thinking” is found 100 thousand times more often than “thinking”, but if the subject knows one of them, then he most likely knows the other. We can say that there are some "vocabulary nests". Each nest consists of one main word, as well as its derivatives, which can be formed from the main one by simple rules using prefixes and suffixes. Knowing any word from the nest and possessing some linguistic flair, one can guess the meaning of all the other words of this nest. Frequency dictionary was regrouped taking into account such nests.
In the tests for vocabulary of the English language, such nests are called "word families", and knowledge of one word family is equal to knowledge of one word. Thus, the vocabulary assessment takes into account only the knowledge of the main words, but not their derivatives. There are generally accepted rules for the formation of word families (L. Bauer and P. Nation, Int. J. Lexicography (1993)). In Russian, unfortunately, no such rules have been developed. Because of this, it was decided to evaluate the vocabulary, taking into account not only the main, but also derived words, too.
The method of determining vocabulary is a two-step. At the first stage, the sorted words are divided into 40 groups (the first groups contain the simplest words, the last - the most complex). A test word is selected from each group; The resulting 40 test words form the first test set. The results of the answers can be approximately determine the lower and upper boundaries of vocabulary. Below the lower boundary, the subject knows almost all the words. Above the top - knows almost nothing. At the next stage, the sorted words in this approximate range are divided into smaller groups and a second test set is formed. The final vocabulary assessment is the sum of the words in all groups, the test words of which the subject has marked as known. The idea of adaptive testing in two stages was borrowed on the site http://testyourvocab.com.
The test can be passed many times - because of the large number of test words (about 1200), they will be repeated quite rarely. The standard deviation of the assessment is about 4%. This means that in 68% of all passes, the estimate will lie within plus or minus 4% of the average, and in 96% of all passes, within plus or minus 8% of the average. In simple words - if you passed the test twice, the estimates may well differ by 10-15%, this is an inevitable consequence of the statistical approach.
The test is based on the assumption that the subject honestly and carefully notes familiar words. Unfortunately, this is not always the case. To recognize cases of careless passing, trap words were entered into the test. Such words sound like Russians, but they do not mean anything. They are not found in any dictionary; Moreover, even search engines do not find them on the Internet. If the subject marks such a word as familiar, his result is considered unreliable and is not included in the final vocabulary research of Russian speakers. However, the assessment that a person receives is not modified in any way (only a verbal warning is issued about the unreliability of the results).
The testing methodology is implemented in Python using the Flask web framework and the Zurb Foundation frontend.
As you have most likely seen (if passed the test) - the method of determining vocabulary works. At least, it gives some fairly reasonable estimate. To improve this assessment, I propose to move in two directions. I, as an author, will work on the methodology and improve its accuracy. And you can read a couple of serious books and pass the test again - you will definitely like the result.
The article presents the method of the first adaptive test for measuring passive vocabulary, developed for the Russian language. The stages of test preparation are disassembled: building a frequency dictionary, grouping vocabulary families, selecting test words, choosing the type of survey, introducing word-traps to the test to control the honesty and attentiveness of passing. A detailed review of the new vocabulary counting method, based on the measurement of the knowledge function and its subsequent integration, is considered. Validation and accuracy studies showed that the test reliability factor (0.95) is high enough to conduct research both at the group and at the individual level. The measurement error of vocabulary is within 7% for adults (> 18 years old) of respondents. The test is illustrated by preliminary data on the age dependence of the vocabulary of speakers of the Russian language, obtained from a sample of 123 thousand respondents.
Vocabulary is the basis of language proficiency. Its qualitative and quantitative characteristics reflect the level of linguistic competence, and also speak a lot about intelligence, psychological portrait, kind of activity, and even human habits. The study of these characteristics is important for the tasks of pedagogy (determination of the level of language skills and the quality of mastering subject vocabulary), as well as psychology and sociology. Unfortunately, vocabulary studies of speakers of the Russian language are practically not conducted. One of the reasons for this is the lack of the necessary tool. Indeed, one of the most common vocabulary learning methods is to measure its size. The theoretical foundations of such measurements are well developed using the example of English, for which there are several generally accepted tests [Read 1993; Schmitt, Schmitt, and Clapham 2001]. At the same time, similar tests for the Russian language until recently did not exist. The test presented in this paper fills this gap. Its task is to give researchers (teachers, psychologists, sociologists) a quick and accurate tool for quantifying the size of the subject's passive vocabulary.
The test method is based on the generally accepted statistical approach [Read 2000]. Its essence lies in the assumption that the respondent’s probability of knowing the words used in the language (in books, television programs, speeches) equally often is about the same. This allows the respondent to check not all the words of the language, which is obviously impossible, but only a small number of specially selected test words, each of which represents a whole group of words of approximately the same frequency. Technically, the test is carried out in two stages. At the first stage, the respondent receives 40 test words. The respondent’s task is to mark familiar words, that is, words for which he can explain at least by one meaning. According to the data obtained, an approximate vocabulary estimate is made. At the second stage, the respondent receives 80 new test words, which are selected on the basis of this rough estimate in such a way as to exclude too simple or too complex words. The respondent again marks familiar words.According to the data obtained (40 + 80 = 120 test words), a more accurate assessment of vocabulary is made. The method by which vocabulary is calculated in both the first and second stages of the test is based on the evaluation of the parameters of a certain knowledge function of the respondent and its subsequent integration. This method is new and has not been used in vocabulary tests before.
Настоящий тест задумывался как основной инструмент онлайн-проекта по изучению словарного запаса людей, говорящих на русском языке (www.myvocab.info). Проект был инспирирован следующими вопросами: сколько слов знает среднестатистический носитель языка? Какова динамика (рост и уменьшение) словарного запаса родного языка с возрастом? Какие факторы на нее влияют? Проект стартовал в апреле 2014 года и продолжается до сих пор. На настоящий момент в нём уже приняли участие более 800 тысяч человек, что даёт основания полагать, что пока это самый масштабный проект такого типа.
В основной части статьи будет детально рассмотрена методика теста, разобраны этапы, через которые пришлось пройти при его проектировании, проведены валидация, оптимизация и исследование точности теста. В конце будут представлены некоторые предварительные результаты онлайн-проекта, а именно возрастная динамика размера пассивного словарного запаса носителей русского языка.
The existing frequency dictionaries of the Russian language are limited in scope and do not contain the rare low-frequency words necessary for testing people with a large vocabulary. Thus, the frequency dictionary edited by L.N. Zasorina [Zasorina 1977] contains about 40 thousand lemmas, O. N. Lyashevskaya and S. A. Sharov [Lyashevskaya, Sharov 2009] - 52 thousand lemmas. Therefore, the first task of developing a test was to compile a more comprehensive frequency dictionary of the Russian language. For this purpose, the explanatory dictionary of t.V. Efremova [Efremova 2000], containing 136 thousand lemmas, and for each lemma its frequency was found in the National Corpus of the Russian Language (http://www.ruscorpora.ru). The corpus consists of a large number (86 thousand) of texts of various subjects - fiction, journalism, scientific and popular science, religious and philosophical texts,personal correspondence, diaries; total volume of texts - 230 million words. Due to the large volume and wide coverage, this corpus is a cast of modern (54% of all texts were created after 1950) of the Russian language.
The basic idea of a statistical approach to vocabulary assessment is that the probability of knowledge of a word to subjects depends on the frequency of the word. This, however, is not entirely true. For example, the word “thinking” is found 100 thousand times more often than “thinking”, but if the subject knows one of them, then he most likely knows the other. Therefore, we can say that there are some "vocabulary families". Knowing any word from such a family and having some linguistic sense, one can guess the meaning of all the other words of this family. In the tests for vocabulary of the English language, such families are called "word families", and knowledge of one word family is equal to knowledge of one word. Thus, in the evaluation of vocabulary, knowledge of only basic words is usually taken into account, but not their derivatives.There are generally accepted rules for the formation of word families [Bauer and Nation 1993]. Unfortunately, for the Russian language such rules could not be found.
The task of combining words from the assembled frequency dictionary into vocabulary families was solved as follows. The word was added to the appropriate dictionary family, if with respect to at least one word from this family it was:
136 thousand words, thus, were distributed in 88 thousand vocabulary families. As an example, the following vocabulary families are obtained:
Необходимо заметить, что настоящий список правил представляет собой достаточно грубое приближение к решению проблемы составления словарных семей, если эта проблема вообще может быть решена. Действительно, лингвистическое чутье значительно отличается от человека к человеку и улучшается с увеличением словарного запаса. Поэтому для образованных и начитанных носителей языка словарные семьи должны быть больше, чем для только начинающих учить язык. Возможно, словарные семьи должны строиться экспериментально на основе тестирования большого количества респондентов с разным словарным запасом [Guy, Browne, and Culligan 2013]. Понимая приблизительность принятых нами правил построения словарных семей, мы решили подсчитывать словарный запас в словах, а не словарных семьях. Словарные семьи использовались только для перегруппировки частотного словаря. Слова в итоговом частотном словаре были отсортированы по суммарной частотности соответствующих словарных семей.
Возникает также вопрос о правомерности включения производных слов (например, уменьшительно-ласкательных форм) в подсчет словарного запаса. Он осложняется тем, что статус «производности» неоднозначен. Действительно, в зависимости от словаря, одни и те же слова могут быть представлены либо в рамках одной словарной статьи, либо в разных. В этом вопросе мы действовали по словарю Т.В. Ефремовой [Ефремова 2000], и включали в подсчет словарного запаса каждое слово, имеющее в этом словаре собственную словарную статью.
Идеальный тест на словарный запас должен проверять знание всех слов языка, что не представляется возможным. В реальном тесте используется ограниченное количество тестовых слов, где одно тестовое слово представляет собой целую группу близких по частоте слов. Тестовые слова должны быть максимально «нейтральны» и общеупотребительны, чтобы никакие респонденты не получили преимущества перед другими за счет специфических знаний. В противном случае такое «специфичное» слово будет нерепрезентативно группе, которую оно представляет. При отборе тестовых слов исключались:
Есть несколько общепринятых способов проведения тестов на словарный запас, отличающиеся способом опроса тестируемых. Рассмотрим только два наиболее часто встречающихся варианта. Первый – это тест с множественными вариантами ответа. Тестовое задание может выглядеть так:
«Бестия» - это
Второй – это «знаю/не знаю» тест, где испытуемого просят отметить слова, которые он знает. На первый взгляд, тест с множественными вариантами ответа предпочтителен, так как должен давать более точный результат. В этом варианте знание тестовых слов проверяется, тогда как в варианте «знаю/не знаю» честность ответов остается на совести испытуемого. В действительности оба варианта опроса имеют свои достоинства и недостатки [Meara and Buxton 1987]. Впрочем, эти недостатки могут быть минимизированы при аккуратном подходе к составлению теста. При правильном составлении тестовых заданий, а также достаточном количестве тестовых слов, оба типа тестов дают схожие результаты [Culligan 2015; Pellicer-Sanchez and Schmitt 2012]. Рассмотрим причины, по которым для разрабатываемого теста был выбран более простой «знаю/не знаю» вариант опроса.
Во-первых, на каждое тестовое задание у респондента уходит определенное время. Как будет показано дальше, для достаточно точного определения словарного запаса необходимо проверить знание около 120 тестовых слов. В случае теста «знаю/не знаю» это занимает около 5 минут. В случае теста с множественными вариантами ответа – в несколько раз больше, так как испытуемому требуется прочитать все варианты ответа и мысленно «взвесить» каждый из них. Для онлайн-теста время прохождения критично, потому что проходящие его люди в основном недостаточно мотивированы чтобы тратить много времени.
Во-вторых, составление тестовых заданий в случае теста с множественными вариантами требует серьезных усилий [Аванесов 2005]. Каждый вариант должен быть достаточно реалистичен, чтобы избежать угадывания методом исключения, а также достаточно прост, чтобы не ввести респондента в заблуждение, если он знает тестовое слово. В случае «знаю/не знаю» теста тестовые задания как таковые отсутствуют, что значительно экономит время подготовки теста и облегчает его составление.
У выбранного «знаю/не знаю» типа опроса есть и недостатки. Во-первых, «знание» слова может пониматься разными опрашиваемыми по-разному. Во-вторых, такой тест не позволяет проверить понимание различных значений одного и того же слова. Понимая эти ограничения, в обращении к опрашиваемым перед тестом мы специально оговорили, что следует понимать под знанием: «Считайте, что вы знаете слово, если можете дать определение хотя бы одному его значению. Не отмечайте слова, которые вы видели или слышали, но в значении которых не уверены до конца».
Вид опроса существенно влияет на то, что в итоге измеряет тест. Действительно, «знание» слова – явление многокомпонентное. Так, Пол Нэйшн [Nation 2013] выделил восемь аспектов знания:
The choice of the type of survey determines which aspect of knowledge is verified by the test. A survey of the "know / do not know" type involves checking only points 2 and 7 (the spelling of the word and its meaning). Other aspects of knowledge can also be explored, for which other types of surveys should be used [Webb and Sasao 2013].
Другая серьезная проблема «знаю/не знаю» тестов - невозможность проверки правдивости ответов. Опрашиваемый может отметить некоторые тестовые слова как знакомые по невнимательности или специально, чтобы увеличить результат. Для отслеживания таких некорректных ответов обычно вводят тестовые слова-ловушки. Эти слова похожи на настоящие, но не существуют в языке, например, «очудей», «онторология», «тибильга». В зависимости от количества «сработавших» слов-ловушек, результат теста может быть скорректирован [Anderson and Freebody 1983] – чем больше несуществующих слов отметил респондент, тем существеннее уменьшается его результат. Конкретная реализация такой коррекции, однако, вызывает разногласия [Pellicer-Sanchez and Schmitt 2012]. Действительно, невозможно понять, отметил ли респондент слово-ловушку как знакомое из-за невнимательности (прочитав его быстро и приняв за другое), или специально, чтобы увеличить результат. Коррекция в каждом из этих случаев должна быть разная. Из-за этой неопределенности (которую в рамках только «знаю/не знаю» теста вряд ли можно преодолеть) было решено не проводить коррекцию результата. Слова-ловушки, тем не менее, использовались (на 120 тестовых слов – 4 слова-ловушки). Результаты респондентов, отметивших хотя бы одно такое слово, исключались из проводимых исследований словарного запаса.
To evaluate the vocabulary, a previously unused algorithm was used. To clarify how it works, you need to make a conceptual digression. The main idea of all passive vocabulary tests is the representation of a fairly large group of words that are similar in frequency, with one test word. If the respondent knows the test word, it is considered that he knows the whole group, since the words in it are close in frequency to the test word. The same idea can be reformulated using the concept of rank — the ordinal number of a word in a dictionary sorted by frequency (the rank of the frequency word itself is thus equal to one). If the respondent knows a test word with a certain rank n, it is logical to assume that he also knows other words whose ranks are close to n. Using the language of physics, we can say that by presenting a test word with rank n and receiving a response from the respondent, we measure the likelihood of them knowing words with ranks close to n. Using the physical analogy further, we can assume that there is a certain function of the probability of knowing the words that we are trying to measure, and which depends on n - the rank of words. For each respondent, such a function will have its own, but its characteristic form, however, will be common - from one (probability of knowledge - 100%) for small n (simple words) to zero (probability of knowledge - 0%) for large n (complex, rare words). Each individual measurement is rather crude, since it gives either 0 or 1 (if the test word is marked as unfamiliar or familiar, respectively). If, however, many such measurements are taken, it is possible to measure the required knowledge function with sufficient accuracy. If this function is then integrated, then you get nothing more than a vocabulary estimate.
Since the characteristic form of the vocabulary function is the same for all respondents, you can try to describe it with some analytical formula that has the desired form - from one for small values of the argument to zero for large ones through a smooth transition. It is convenient to use the following two-parameter function:
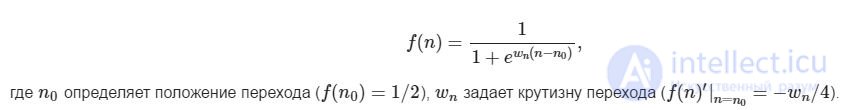
Evaluation of vocabulary (a definite integral of the probability function of knowledge of words), thus, can be expressed by the following formula:
The vocabulary evaluation algorithm was implemented as follows. Each test word (rank nini) gave one dimension of the function of vocabulary: fi = 1fi = 1, if the respondent marked the test word as familiar and fi = 0fi = 0 - if unfamiliar. The set of such measurements was approximated by the function (1) (1) using the least squares method. The approximation gave the values of the coefficients n0n0 and wnwn, which were substituted into formula (2) (2) to obtain a vocabulary estimate.
Measuring vocabulary using the method described has several advantages. First, the algorithm allows us to estimate the measurement error, as well as its quality. Indeed, approximation by the least squares method (or any other) allows estimating not only the values of unknown coefficients of the vocabulary function (n0n0 and wnwn), but also their variance. This, in turn, allows calculating the variance of vocabulary assessment. The approximation also allows you to calculate the coefficient of determination (also known as R-square), which shows how well the chosen model (that is, the type of vocabulary function) approximates the data. If the variance of the estimate is large, and the coefficient of determination is small - this is an indicator that either the selected type of function is incorrect, or there is not enough data to estimate, or the data contain anomalies. As it will be shown in the section “Checking the selected distribution function”, the first item can be excluded. Therefore, with a sufficient number of test words (which excludes the second paragraph), the algorithm allows to reveal anomalies in the data. Such anomalies may indicate inattentive passing of the test (in its extreme manifestation, the marking of test words at random).
Secondly, this algorithm allows you to gradually increase the accuracy of vocabulary assessment. So, at the first stage of the test, the respondent is given 40 test words. From these data, the algorithm determines the approximate assessment of vocabulary. At the second stage, the respondent is given 80 test words, whose ranks are relatively close to a rough estimate. These new data are added to the old ones, and the algorithm gives a refined estimate for already 120 (40 + 80) test words.
Thirdly, vocabulary assessment is obtained not in abstract units (points), but in words, which makes the interpretation of results easier.
Validation test included several studies. First, it was checked how selected the type of function was (formula (1) "role =" presentation "style =" box-sizing: border-box; display: inline; line-height: normal; word-spacing: normal; word -wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; position: relative ; "> (1) (1)) corresponds to the real probability function of knowledge of words. Secondly, the gain in the accuracy of the method was justified when using testing in two stages (versus testing in one). Third, the accuracy of the test was evaluated. These research was based on the data of individual vocabulary of seven respondents, please Shih, advanced test 1200 test words (ie a full number of test words that are used in the test). Information about the respondents is shown in Table. 1. Also according to the method of splitting the classical test theory test reliability coefficient was calculated.
Tab. 1. Respondents who have passed the extended version (1200 words) of the test.
| Respondent | Age years | Education |
|---|---|---|
| A | 29 | Higher, physical |
| B | 29 | Higher, information technology |
| C | 27 | Higher, engineering |
| D | 29 | Candidate of Philosophy |
| E | thirty | Candidate of Physical and Mathematical Sciences |
| F | 54 | Higher, pedagogical |
| G | 55 | Higher, engineering |
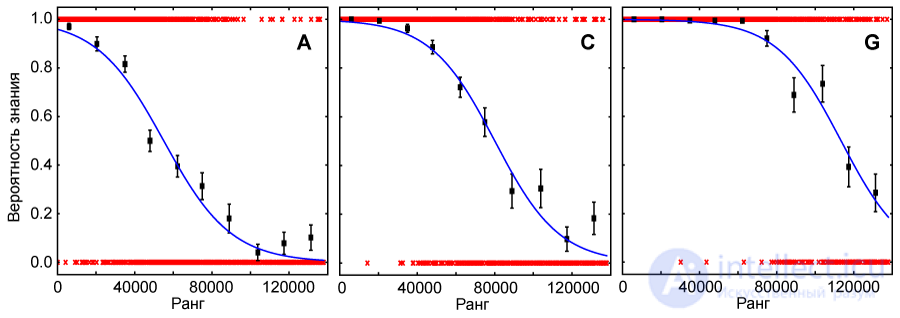
Fig. 1. Functions of the probability of knowing the words for three respondents (see Table 1). Red crosses - individual test words (0 corresponds to the answer "I do not know", 1 - "I know", only 1200 test words). Black squares are averaged probabilities; each square corresponds to approximately 120 test words. The blue curves are approximations of test data by the function given by the formula (1) "role =" presentation "style =" box-sizing: border-box; display: inline; font-style: normal; line-height: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; position: relative; "> (1) (1).
According to the method of the test being developed, it is necessary to integrate its knowledge function in order to obtain an assessment of the respondent’s vocabulary. In the usual version of the test (with 120 test words), it is impossible to measure the knowledge function with the required accuracy - that is why it is necessary to use an approximation. However, in the extended test version (with 1200 test words), the unknown knowledge function can be measured sufficiently qualitatively. Such a measurement is necessary to validate the selected type of approximation function.
The result of the three respondents who passed the extended version of the test is shown in Fig. 1. Each red cross corresponds to one test word (1 - if the respondent marked the word as familiar, 0 - if as unfamiliar). It can be seen that for low ranks (high-frequency test words) the density of red crosses on the value “1” is high - respondents know these words. As they move from small ranks to large (towards low-frequency words), red crosses appear on the value “0” more and more often - respondents know fewer test words. Black squares show the average probability of knowledge of test words (120 per square). The blue curves correspond to the approximation of the test data by the function (1) "role =" presentation "style =" box-sizing: border-box; display: inline; line-height: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; position: relative; "> (1) (1). The visually selected function well approximates the results obtained for all 7 respondents.
For a quantitative assessment of the quality of approximation, two vocabulary estimates were compared. One was obtained by integrating the measured knowledge function (black squares in Fig. 1), the other by integrating the approximating functions. The results are shown in Table. 2. The difference in ratings was no more than 6%, which can be considered a good result.
Tab. 2. Validation of the choice of the function of word knowledge. Comparison of vocabulary estimates obtained through approximation (by the formula (2) "role =" presentation "style =" box-sizing: border-box; display: inline; font-style: normal; line-height: normal; word-spacing : normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px ; position: relative; "> (2) (2)) and direct integration of the knowledge function. Respondents are described in Table 1.
| Respondent | A | B | C | D | E | F | G |
|---|---|---|---|---|---|---|---|
| Estimation of vocabulary through approximation (by the formulas (1) "role =" presentation "style =" box-sizing: border-box; display: inline; line-height: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; position: relative; "> (1 ) (1) and (2) "role =" presentation "style =" box-sizing: border-box; display: inline; line-height: normal; word-spacing: normal; word-wrap: normal; white-space : nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; position: relative; "> (2) (2 )) | 55600 | 67800 | 79800 | 86600 | 96000 | 97900 | 110100 |
| Vocabulary assessment (integration without approximations) | 58900 | 72200 | 82400 | 87300 | 97000 | 99,000 | 110,500 |
| Difference of ratings | 5.6% | 6.1% | 3.2% | 0.8% | 1.1% | 1.1% | 0.4% |
The test method allows you to use any number of test words. At the same time, it is obvious that the more words are used - the more accurate the assessment is. However, not all test words give the same contribution to the measurement. For example, for a respondent with a large vocabulary, the probability of knowing very simple words is close to one, so using a large number of simple test words will not increase the accuracy of the test. The same is true and vice versa - for a respondent with a small vocabulary, the probability of knowing very complex words is close to zero, that is, it is meaningless for such a respondent to present complex test words. The test works in two stages. At the first stage, 40 test words are presented to the respondent. According to the results of this stage, an approximate vocabulary assessment is made. The second stage consists of 80 words, which are selected on the basis of a rough estimate - too simple or complex test words are not present at this stage. Thus, the test in two stages is adaptive, since the test words of the second stage are selected for each respondent individually.
In order to check whether such an adaptive approach is more optimal than a non-adaptive (in one stage), the following study was conducted. Using the results of the extended version of the test (1200 words), passed by respondent E (see Table 1), different versions of the test were modeled in two stages. At the same time, the number of questions at the first and second stage varied. The results are presented in Fig. 2). The vertical axis shows the total number of test words in two stages, the horizontal one - the number of words in the second stage. The color encodes the accuracy of the test (the standard deviation obtained from 1000 test implementations with randomly selected test words). The horizontal dashed line corresponds to a fixed total number of test words (120). The leftmost point on it corresponds, in fact, to a test in one stage (120 test words at the first stage, 0 - at the second), while moving along this line to the right, the number of test words at the second stage increases, at the first - decreases (the amount remains constant). The accuracy of the test along this line is variable and has a maximum in the region of about 80 test words in the second stage. Indeed, for a one-step test (120 words), the standard deviation of the assessment of vocabulary is 4.8%, for a two-step test (40 + 80 words), 4.1%. This difference can be interpreted differently. In order to ensure the accuracy of the test in two stages with the optimal number of words (40 + 80 = 120), a one-step test would be required, consisting of 150 test words, which is as much as 25% more.
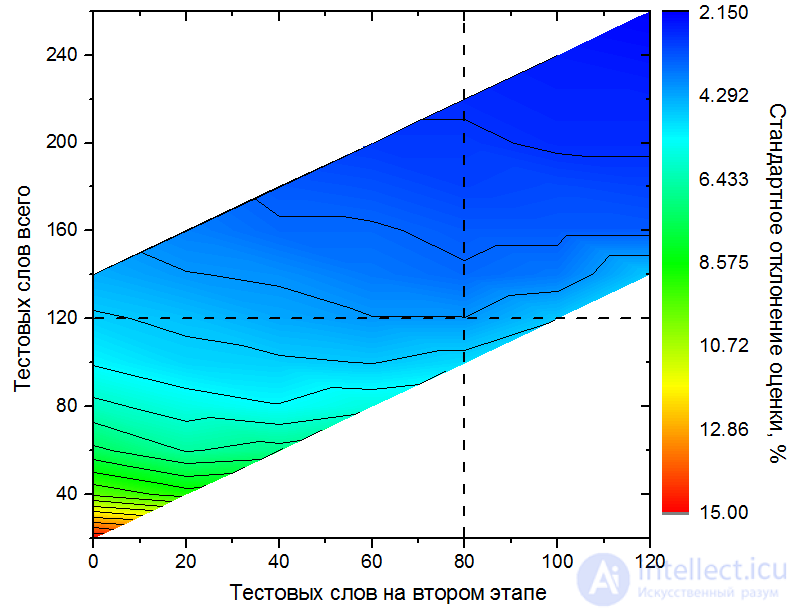
Fig. 2. Optimization of the number of test words in the first and second stages using the example of the respondent E results. Each standard deviation value of the vocabulary assessment is obtained from 1000 test passes with randomly selected test words. Solid lines mark the contours of the same standard deviation values.
Evaluation of the accuracy of the test was carried out using the following procedure. For each respondent who passed the extended version of the test, the standard test version was modeled - 40 test words at the first stage, 80 - at the second. The number of test words used in the standard test version is ten times less than the total number in the test base, so each pass is unique. Even if the same person passes the test time after time, the test words will be repeated quite rarely. If such passages led to significantly different evaluations, this would indicate either the inoperability of the method or a poor choice of test words. 5,000 such passages were modeled by each respondent, so that the test words were included in the test in different combinations. The obtained distribution of estimates turned out to be normal (Gaussian), for them the mean values and standard deviations were calculated. These values were compared with accurate estimates of the vocabulary of each respondent, obtained from the extended version of the test (1200 words). The comparison results are shown in Table. 3
Tab. 3. Comparison of the accuracy of vocabulary estimates obtained from the extended test version (1200 words) with the estimates obtained from the standard test version (two stages, 40 + 80 words). To calculate the mean and standard deviations, the standard test was modeled 5000 times for each respondent.
| Respondent | A | B | C | D | E | F | G |
|---|---|---|---|---|---|---|---|
| Accurate vocabulary assessment (1200 words) | 55600 | 67800 | 79800 | 86600 | 96000 | 97900 | 110100 |
| Assessment of vocabulary for the first stage (40 words) | 57700 | 70100 | 80200 | 89700 | 96100 | 97300 | 110300 |
| Standard deviation of the first stage estimate,% | 14 | 13 | ten | ten | ten | eight | 7 |
| Difference in an exact assessment and an assessment at the first stage,% | 3.6 | 3.3 | 0.5 | -0.8 | 0.1 | -0.5 | 0.1 |
| Assessment of vocabulary in two stages (40 + 80 words) | 56000 | 67800 | 79200 | 87600 | 92500 | 95600 | 108800 |
| Standard deviation of assessment in two stages,% | 7.0 | 6.1 | 4.2 | 4.2 | 4.1 | 3.1 | 2.7 |
| Difference in accurate assessment and evaluation in two stages,% | 0.7 | -0.1 | -0.7 | -3.0 | -3.6 | -2.2 | -1.2 |
The following conclusions can be drawn. The first stage of the standard test version - 40 words - leads to an unbiased assessment of vocabulary. The difference between the average value of this estimate and the exact value was within 4%. The standard deviation of this estimate is large - up to 14%. This means that by passing the test several times, the same respondent can get significantly different results. In other words, the accuracy of this estimate is low. This is easy to understand, since the number of test words used is small. The estimate obtained in two stages is also unbiased (the difference with a precise estimate is within 4%). However, the standard deviation of this estimate (it is also the test accuracy) is much better - within 7%. The obtained values of standard deviations as a function of the amount of vocabulary are shown in Fig. 3
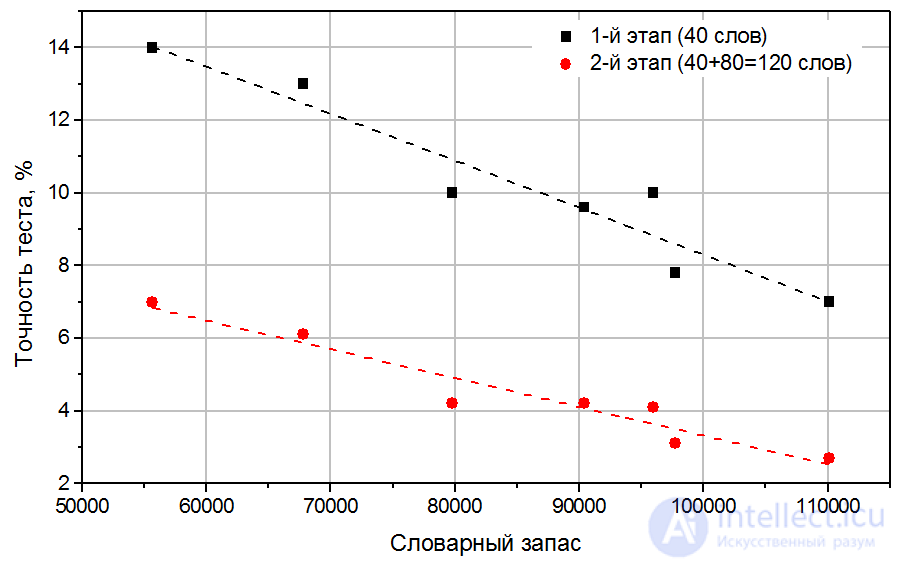
Fig. 3. Accuracy of the assessment (standard deviation) of vocabulary, assessed by the 1st stage of the test (40 words, red), and by two stages (40 + 80 words, blue). Each point corresponds to one respondent (AE from smaller values of vocabulary to large values, see Table 3).
The absolute accuracy of the test, as it turned out, is in the range from 3000 to 4000 words. This means that with a probability of 67%, the score obtained from the test will lie within plus or minus 4000 words from the actual meaning of the vocabulary; with a probability of 95% - within plus or minus 8000 words.
The classical theory of tests allows you to calculate the test reliability factor - an indicator characterizing both the repeatability and the accuracy of its results. For a fairly large (19 thousand) representative sample of respondents who passed the test (and did not mark a single word-trap), the test splitting method was used [Kim 2007]. For each respondent there was a list of 120 test words, as well as his answers. This list was split into two equal halves, for which the vocabulary was independently assessed. Thus it turned out 19 thousand pairs of ratings. The correlation coefficient between these estimates turned out to be 0.90. Since the estimate obtained from half (60) of the test words has underestimated accuracy, the correlation coefficient was adjusted using the Spearman-Brown method. The final safety factor was equal to 0.95. Such a high reliability value confirms that the test
продолжение следует...
Часть 1 vocabulary of a foreign language and native
Часть 2 Preliminary results - vocabulary of a foreign language and native

Comments
To leave a comment
Creation of electronic dictionaries, thesauruses, ontologies
Terms: Creation of electronic dictionaries, thesauruses, ontologies