Lecture
l The dog ate.
l Salespeople sold the dog biscuits.
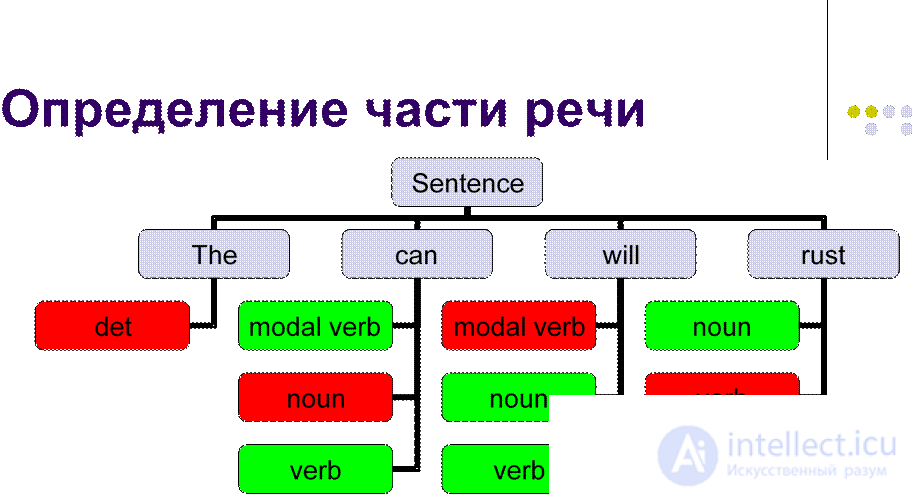

l Blunt - 90%
l Modern - 97%
l Man - 98%
l Apply a dumb algorithm.
l There is a set of rules:
l Change the word tag X to tag Y, if the tag of the previous word - Z.
l Apply these rules a number of times.
l Work faster
l HMM vs. training TT training
(No starting base)
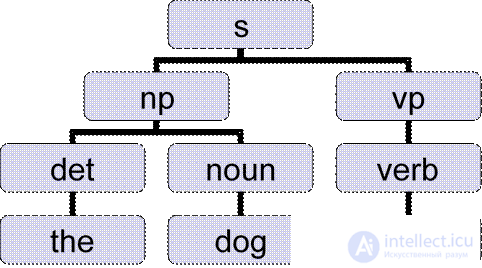
l Build trees on the basis of the sentence, using the existing grammatical rules.
l Example:
(s (np (det the) (noun stranger))
(vp (verb ate)
(np (det the) (noun donut)
(pp (prep with) (np (det a) (noun fork)))))
l Check
l There are ready examples from Pen treebank l Compare with them
l Finding the rules to apply
l Assign probabilities to rules
l Finding the most likely
l sp → np vp | (1.0) |
l vp → verb np | (0.8) |
l vp → verb np np | (0.2) |
l np → det noun | (0.5) |
l np → noun | (0.3) |
l np → det noun noun | (0.15) |
l np → np np | (0.05) |

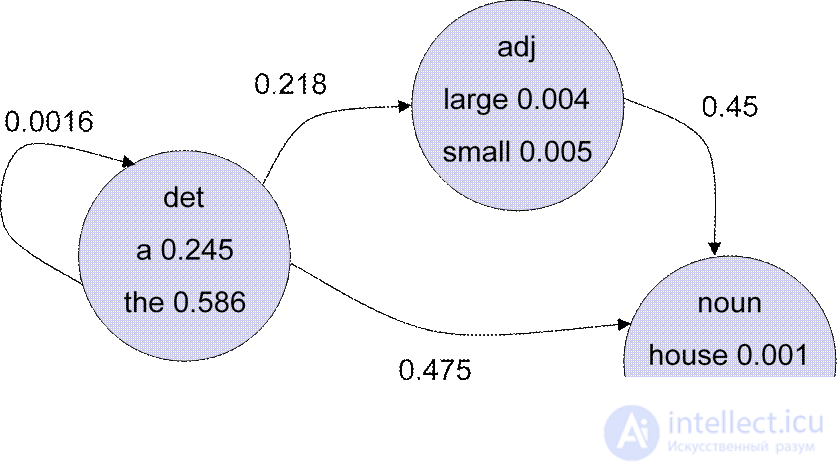
Build your own PCFG. Simple option.
l Take ready Pen treebank
l Read all the trees from it l Read each tree
l Add every new rule.
l P (rule) = number of occurrences divided by total
l Solve the problem of the existence of very rare rules.
l Idea - instead of storing rules, we consider the probabilities that, for example

c
l Let us assign a word (head) to each vertex of the tree characterizing it.
l p (r | h) is the probability that the rule r will be applied for a node with a given h.
l p (h | m, t) is the probability that such h is a vertex child with head = m and has a tag t.
l Example
(S (NP The (ADJP most troublesome) report)
(VP may
(VP be
(NP (NP the August merchandise trade deficit)
(ADJP due (ADVP out) (NP tomorrow)))))
l p (h | m, t) = p (be | may, vp)
l p (r | h) = p (posvp → aux np | be)
l “the August merchandise trade deficit”
l rule = np → det propernoun noun noun noun
Conditioning events | p (“August”) | p (rule) |
Nothing | 2.7 * 10 ^ (- 4) | 3.8 * 10 ^ (- 5) |
Part of speech | 2.8 * 10 ^ (- 3) | 9.4 * 10 ^ (- 5) |
h (c) = “deficit” | 1.9 * 10 ^ (- 1) | 6.3 * 10 ^ (- 3) |

Comments
To leave a comment
Creating question and answer systems
Terms: Creating question and answer systems