Lecture
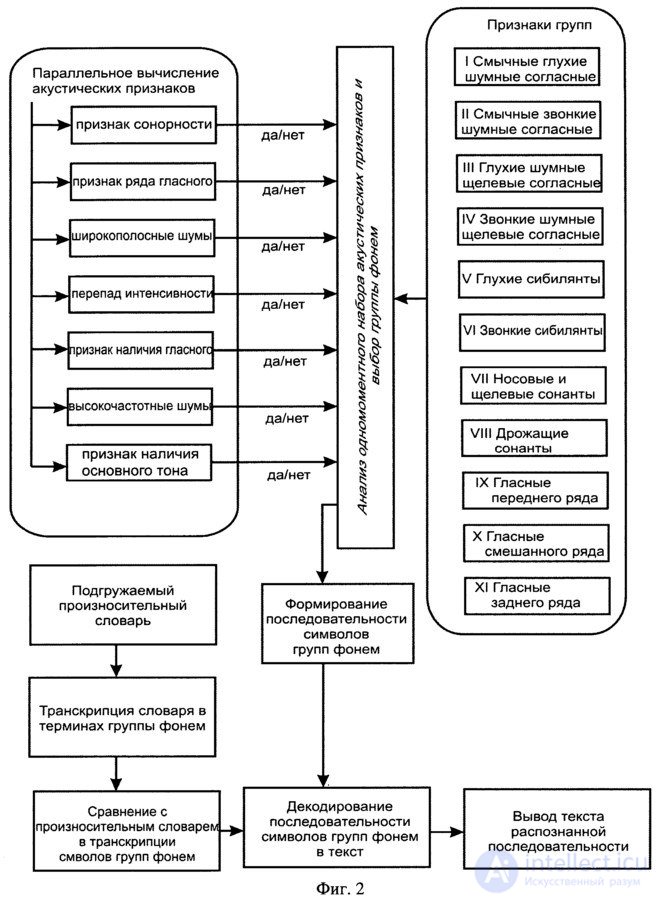
The invention relates to speech recognition technology, i.e. systems and methods for translating an audio signal containing speech into text consisting of words in the lexical and pronunciation vocabulary of the speech recognition system. The technical result is a reduction in the duration and high accuracy of speech recognition. This result is achieved by the use of a system and method of speech recognition, carrying out the reception of a speech signal at the input of the receiving unit; processing of a speech signal by an information processing unit, including its processing by an analog-to-digital converter with a preset sampling frequency and division into segments, spectral analysis of segments of a speech signal and normalization of the spectrum at high frequencies; selection in the normalized spectrum of pauses, noise and sound signals. Next, the presence / absence of acoustic features of the speech signal is determined on the basis of the original speech signal and the normalized spectrum in each segment; the acoustic characteristics of each segment, the conversion of which into a coherent text is carried out by sequential decoding combining groups of symbols combinatorial phoneme sequence based on the vocabulary of the markup symbols phoneme groups.

Comments
To leave a comment
Auto Speech Recognition
Terms: Auto Speech Recognition